MySQL———高阶语句(包括排列中位数累加百分比正则存储过程等)
Posted 老张学coding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL———高阶语句(包括排列中位数累加百分比正则存储过程等)相关的知识,希望对你有一定的参考价值。
四、一些对数据的处理方法
create table Total_Sales (Name char(10),Sales int(5));
insert into Total_Sales values ('zhangsan',10);
insert into Total_Sales values ('lisi',15);
insert into Total_Sales values ('wangwu',20);
insert into Total_Sales values ('zhaoliu',40);
insert into Total_Sales values ('sunqi',50);
insert into Total_Sales values ('zhouba',20);
insert into Total_Sales values ('wujiu',30);

4.1、算排名
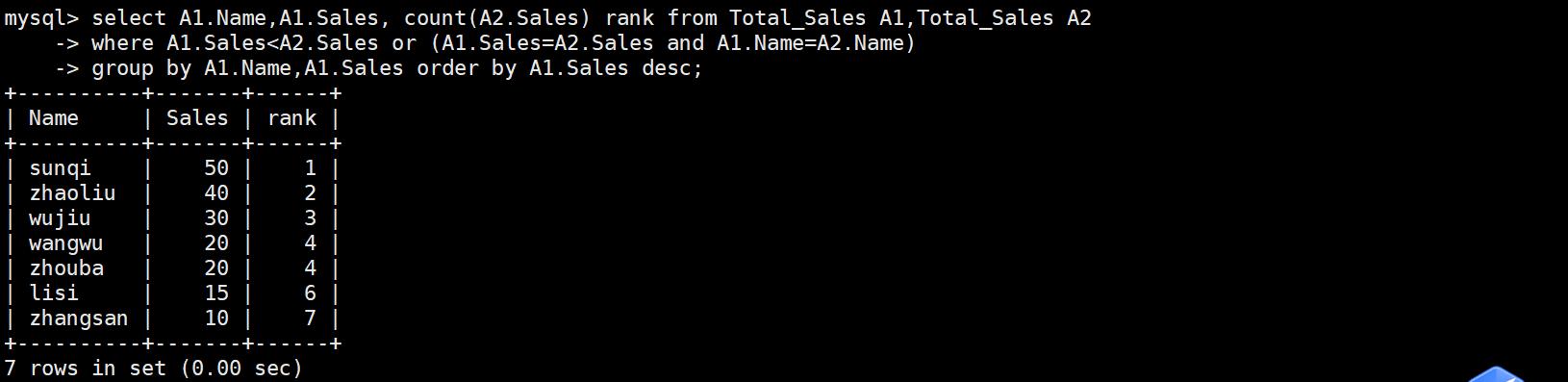
功能:表格自我连结(self join),然后将结果依序列出,算出每一行之前(包含那一行本身)有多少行数
select A1.Name,A1.Sales, count(A2.Sales) Rank from Total_Sales A1,Total_Sales A2
where A1.Sales<A2.Sales or (A1.Sales=A2.Sales and A1.Name=A2.Name)
group by A1.Name,A1.Sales order by A1.Sales desc;
#统计Sales字段的值是比自己本身的值小的以及Sales字段和Name字段都相同的数量,比如zhangsan为6+1=7
4.2、算中位数
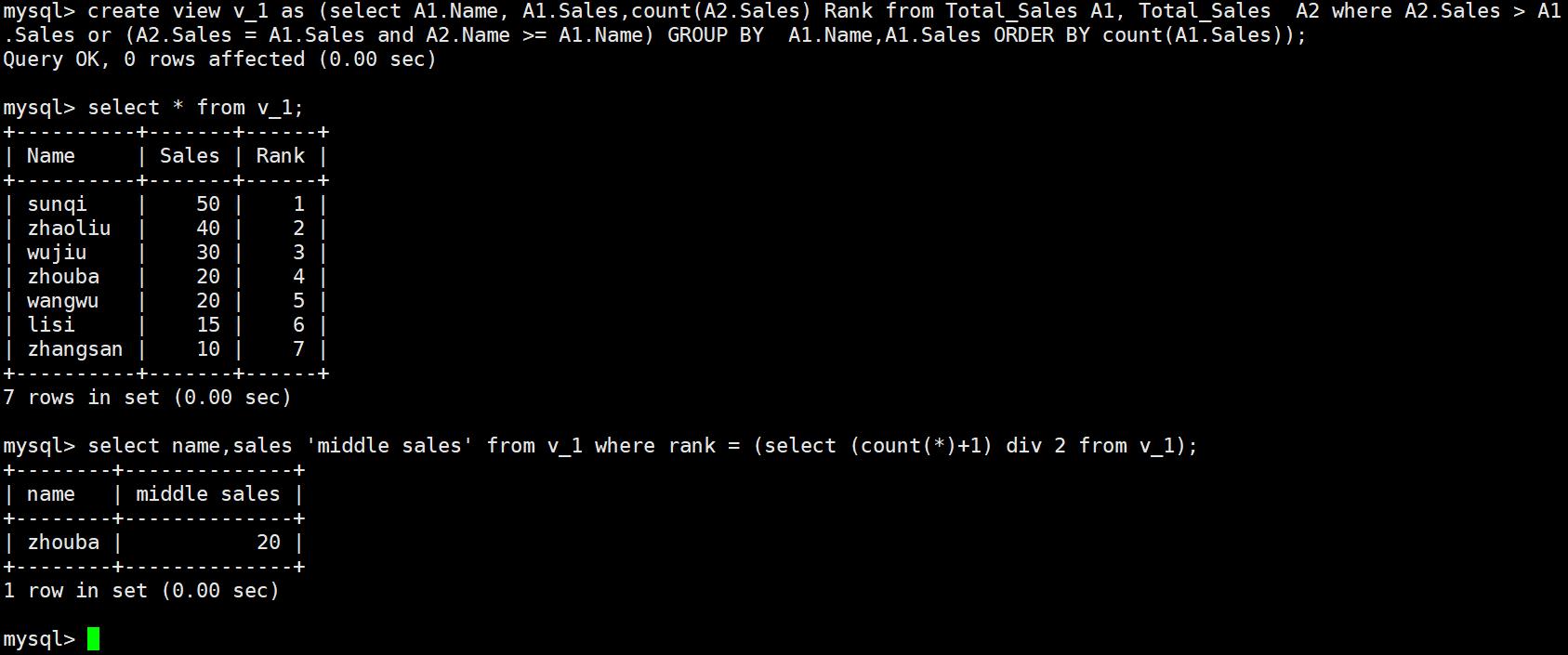
#每个派生表必须有自己的别名,所以A3必须要有
select Name,Sales middle from (select A1.Name,A1.Sales,count(A2.Sales) rank from Total_Sales A1,Total_Sales A2 where A1.Sales < A2.Sales or (A1.Sales=A2.Sales and A1.Name>=A2.Name) group by A1.Name,A1.Sales order by A1.Sales desc) A3
where A3.rank=(select (count(*)+1) div 2 from Total_Sales);
#div是mysql中算出商的方式

1.我们先把排名表创建一个视图
create view v_1 as (select A1.Name, A1.Sales,count(A2.Salees) Rank from Total_Sales A1, Total_Sales A2 where A2.Sales > A1.Sales or (A2.Sales = A1.Sales and A2.Name >= A1.Name) GROUP BY A1.Name,A1.Sales ORDER BY count(A1.Sales));
2.然后查询中位数的那行数据,这边我们要用到where判断语句结合count(*)得出行数+1之后除以2即可
select name,sales 'middle sales' from v_1 where rank = (select (count(*)+1) div 2 from v_1);
#div是mysql中算出商的方式
4.3、算累计总计
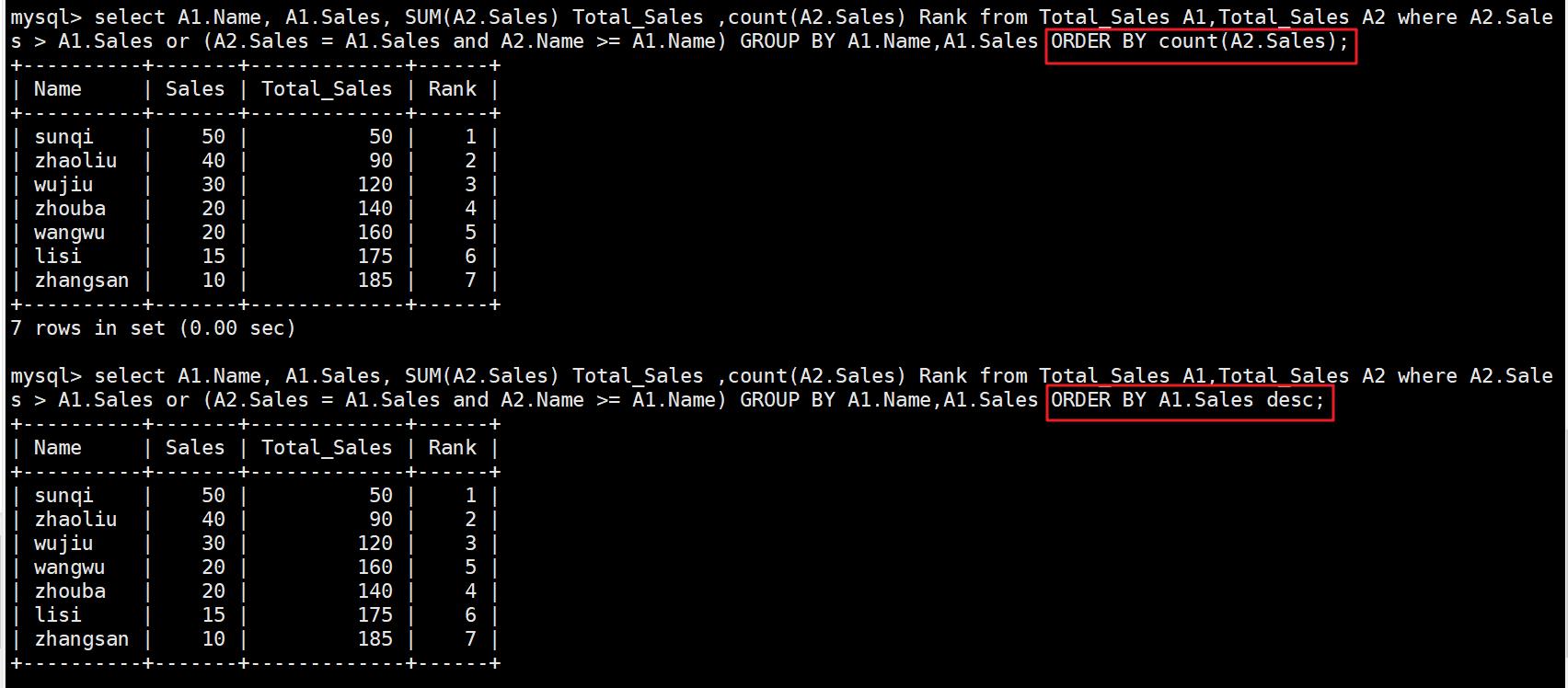
作用:表格自我连结(self join),然后将结果依序列出,算出每一行之前(包含那一行本身)的总和
select A1.Name, A1.Sales, SUM(A2.Sales) Total_Sales ,count(A2.Sales) Rank from Total_Sales A1,Total_Sales A2 where A2.Sales > A1.Sales or (A2.Sales = A1.Sales and A2.Name >= A1.Name) GROUP BY A1.Name,A1.Sales ORDER BY A1.Sales desc;
#count(A2.Sales) 或者A1.Sales desc相同的结果
#只要添加一个sum函数即可,就能到每行都能累加
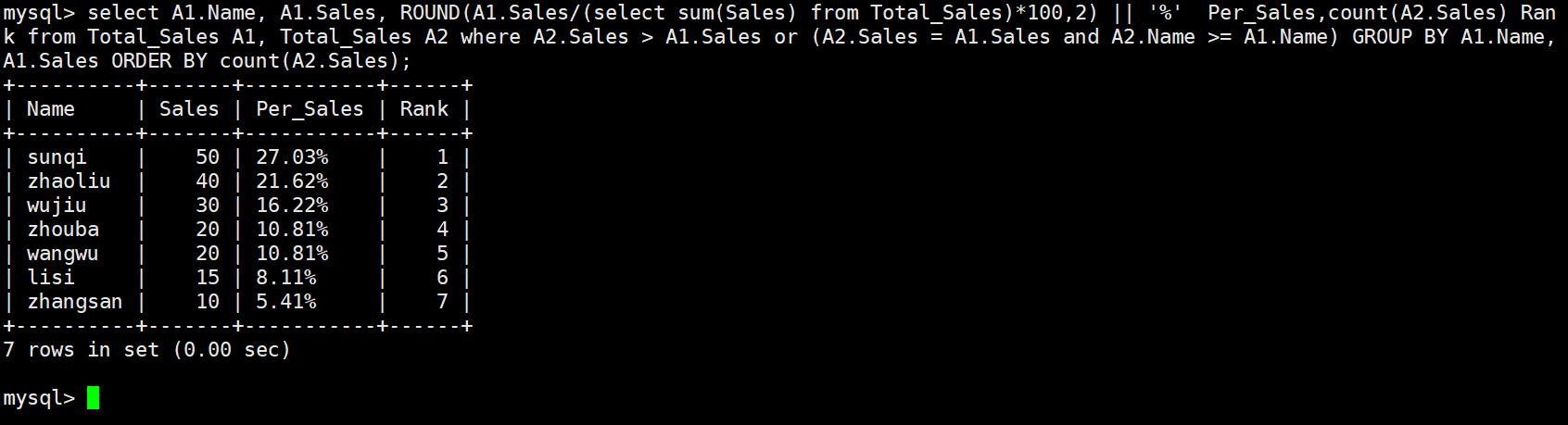
4.4、算各行份额占总额的百分比
select A1.Name, A1.Sales, ROUND(A1.Sales/(select sum(Sales) from Total_Sales)*100,2) || '%' Per_Sales,count(A2.Sales) Rank from Total_Sales A1, Total_Sales A2 where A2.Sales > A1.Sales or (A2.Sales = A1.Sales and A2.Name >= A1.Name) GROUP BY A1.Name,A1.Sales ORDER BY count(A2.Sales);
#添加一个round函数,函数中当前行的份额除以总份额
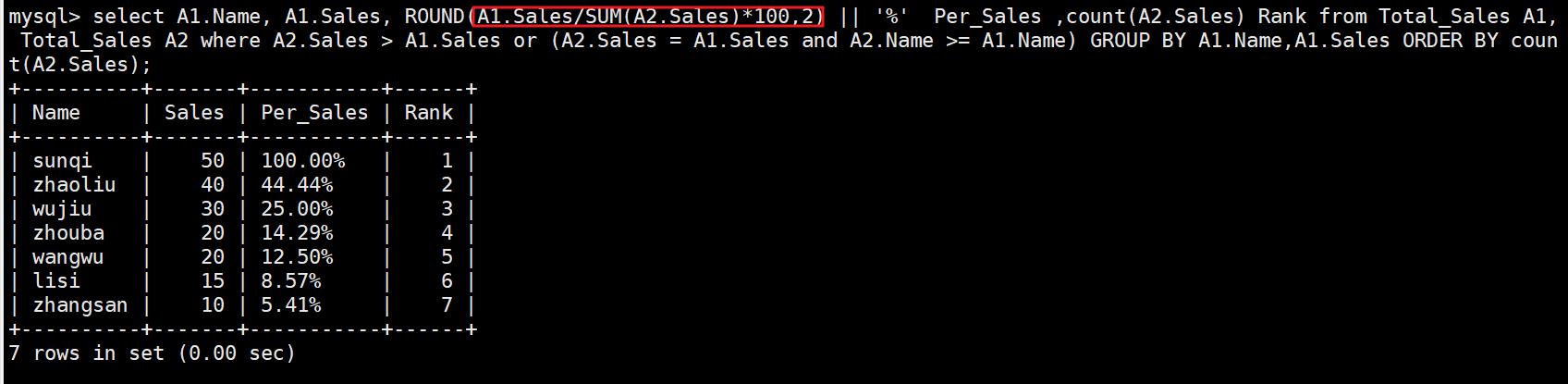
4.5、算各行份额占当前行累加总份额的百分比
select A1.Name, A1.Sales, ROUND(A1.Sales/SUM(A2.Sales)*100,2) || '%' Per_Sales ,count(A2.Sales) Rank from Total_Sales A1, Total_Sales A2 where A2.Sales > A1.Sales or (A2.Sales = A1.Sales and A2.Name >= A1.Name) GROUP BY A1.Name,A1.Sales ORDER BY count(A2.Sales);
#把分母改为SUM(A2.Sales)即可
五:补充:空值(NULL)与无值(’’)的区别
区别:
- 无值长度为0,不占空间;而NULL值的长度为null,占用空间
- is null 或者is not null 用来判断是不是空值,无法判断是不是无值
- 无值使用“=”或者“<>”来处理.<>代表不等于
- count()计算时,NULL会被忽略,无值会加入计算
5.1、实验验证
select length(null),length(''),length('1');
①查看无值以及空值所占空间

② 判断空值以及null值
select * from City;
select * from City where name is null;
select * from City where name is not null;

③ 判断无值
select * from City where name = '';
select * from City where name <> '';

④通过查看行数查看空值以及无值
#查看行数包括null和无值
select count(*) from City ;
#查看行数,包括无值,但不包括空值
select count(name) from City ;

六、正则表达式
6.1、常用的正则表达式:
| 正则表达式 | 说明 | 实例 |
|---|---|---|
| ^ | 匹配文本的开始字符 | |
| $ | 匹配文本的结束字符 | |
| . | 匹配任何单个字符 | |
| * | 匹配零个或多个在它前面的字符 | |
| + | 匹配前面的字符1次或多次 | |
| 字符串 | 匹配包含指定的字符串 | |
| p1|p2 | 匹配 p1 或 p2 | |
| […] | 匹配字符集合中的任意一个字符 | |
| [^…] | 匹配不在括号中的任何字符 | |
| {n} | 匹配前面的字符串n次 | |
| {n,m} | 匹配前面的字符串至少n次,至多m次 |
6.2、语法
语法说明:regexp
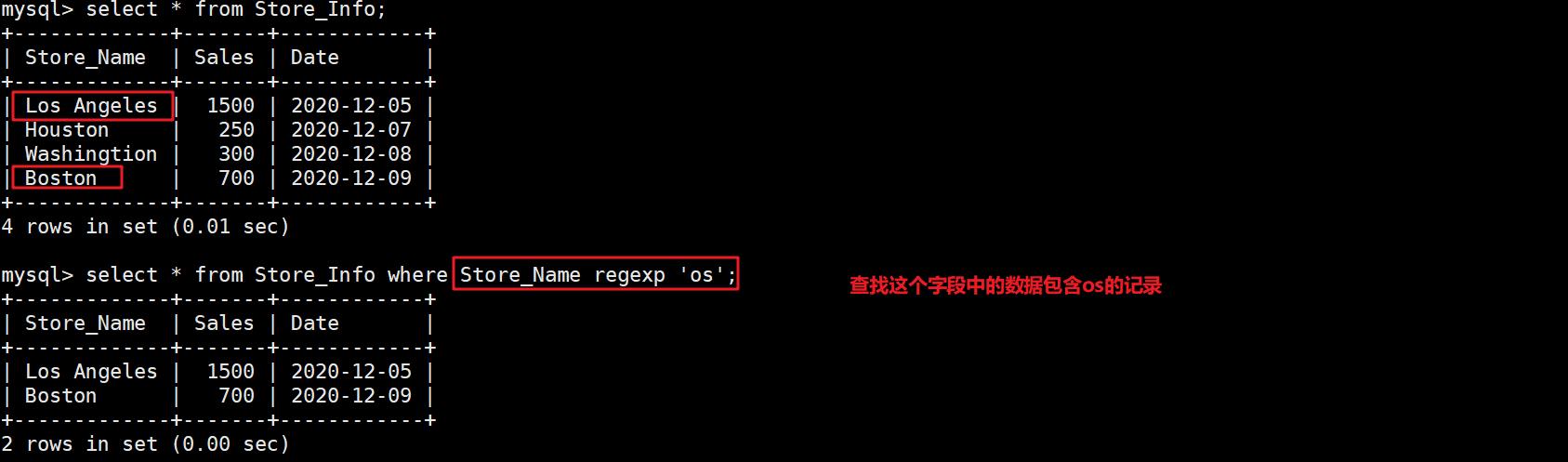
select 字段 from 表格 where 字段 regexp {模式};
select * from Store_Info where Store_Name regexp 'os';
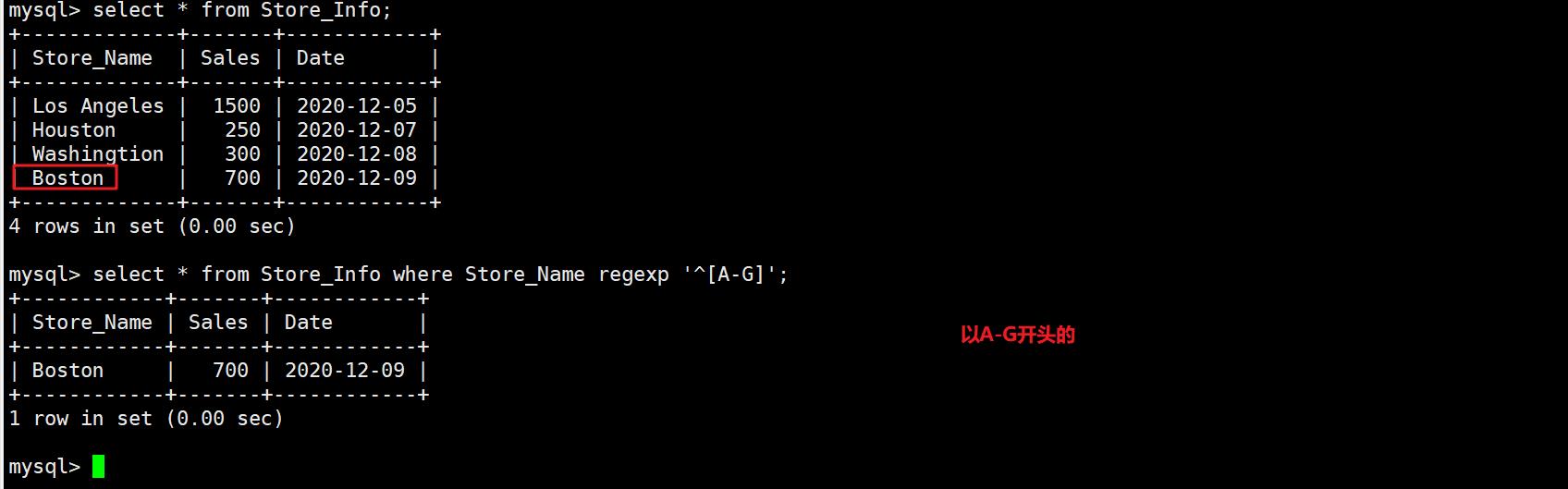
select * from Store_Info where Store_Name regexp '^[A-G]';
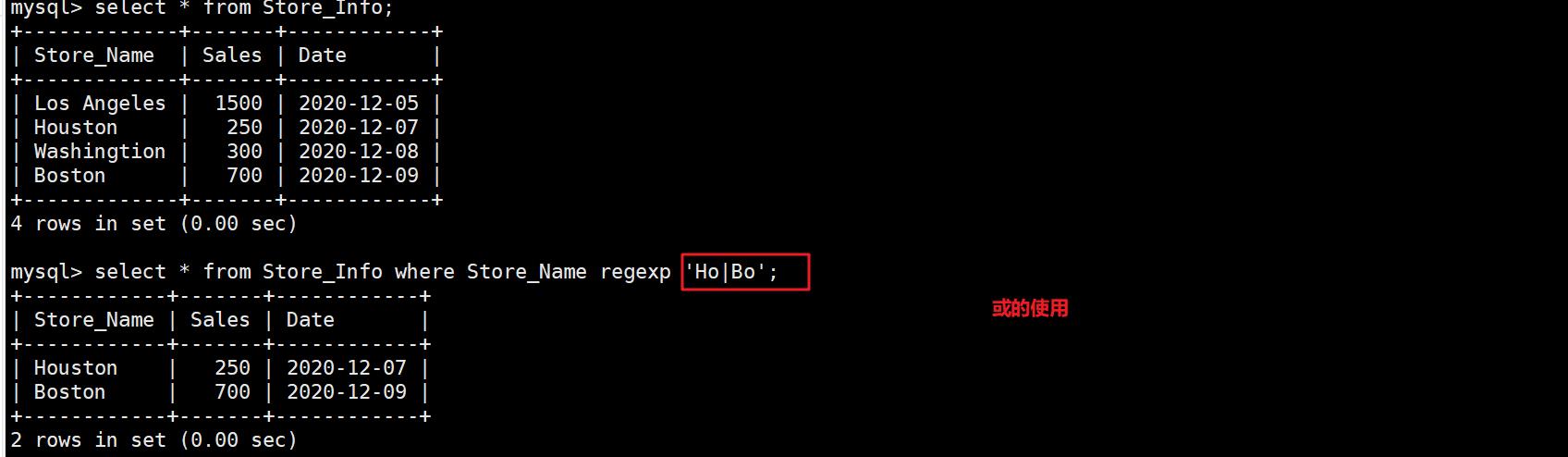
select * from Store_Info where Store_Name regexp 'Ho|Bo';
七、存储过程
7.1、存储过程简介
- MysQL数据库存储过程是一组为了完成特定功能的SQL语句的集合
- 存储过程这个功能是从5.0版本才开始支持的,它可以加快数据库的处理速度,增强数据库在实际应用中的灵活性
- 存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可
- 操作数据库的传统SQL语句在执行时需要先编译,然后再去执行,跟存储过程一对比,明显存储过程在执行上速度更快,效率更高
7.2、存储过程优点
- 执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
- SQL语句加上控制语句的集合,灵活性高
- 在服务器端存储,客户端调用时,降低网络负载
- 可多次重复被调用,可随时修改,不影响客户端调用
- 可完成所有的数据库操作,也可控制数据库的信息访问权限
7.3、存储过程的运用
7.3.1、不带参数
1.创建存储过程
delimiter $$ #将语句的结束符号从分号;临时修改,以防出问题,可以自定义
create procedure proc() #创建存储过程,过程名proc,不带参数
begin #过程体以关键字BEGIN开始
select * from 表格 where 条件语句; #过程体语句
end $$ #过程体以关键字END结尾
delimiter ; #将语句的结束符号恢复为分号
2.调用存储过程
call proc;
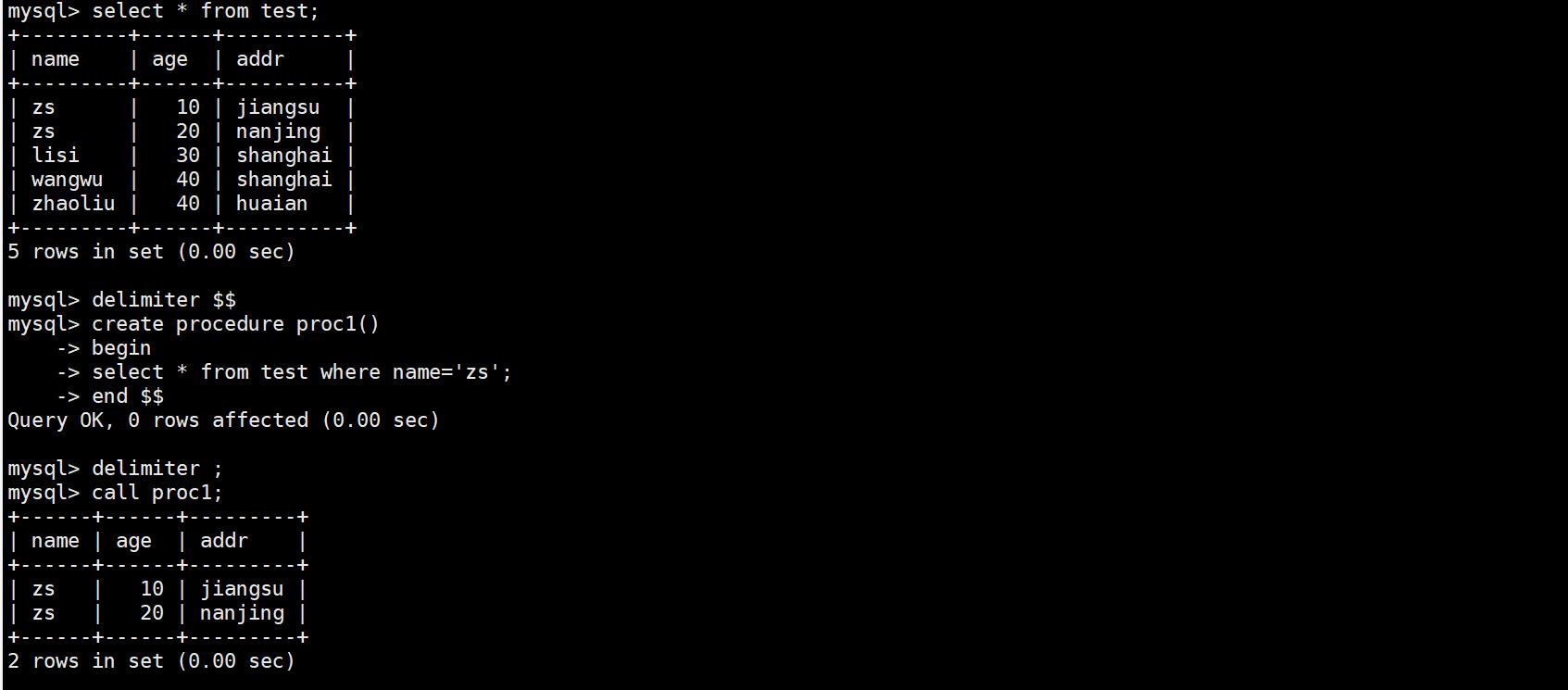
3.查看存储过程
show create procedure [数据库.] 存储过程名; #查看某个储存过程的具体信息
show create procedure proc\\G
show procedure status [like '%proc%'] \\G
① 实例操作:创建存储过程,调用存储过程
mysql> select * from test;
+---------+------+----------+
| name | age | addr |
+---------+------+----------+
| zs | 10 | jiangsu |
| zs | 20 | nanjing |
| lisi | 30 | shanghai |
| wangwu | 40 | shanghai |
| zhaoliu | 40 | huaian |
+---------+------+----------+
mysql>delimiter $$
mysql> create procedure proc1()
-> begin
-> select * from test where name='zs';
-> end
Query OK, 0 rows affected (0.00 sec)
mysql> delimiter ;
mysql> call proc1;
+------+------+---------+
| name | age | addr |
+------+------+---------+
| zs | 10 | jiangsu |
| zs | 20 | nanjing |
+------+------+---------+
②查看存储过程
show create procedure [数据库.] 存储过程名; #查看某个储存过程的具体信息
show create procedure proc\\G ;
show procedure status [like '%proc%'] \\G ;
③删除存储过程
drop procedure if exists 存储过程名; #仅在存在删除,不加if exists ,如果不存在,则会报错

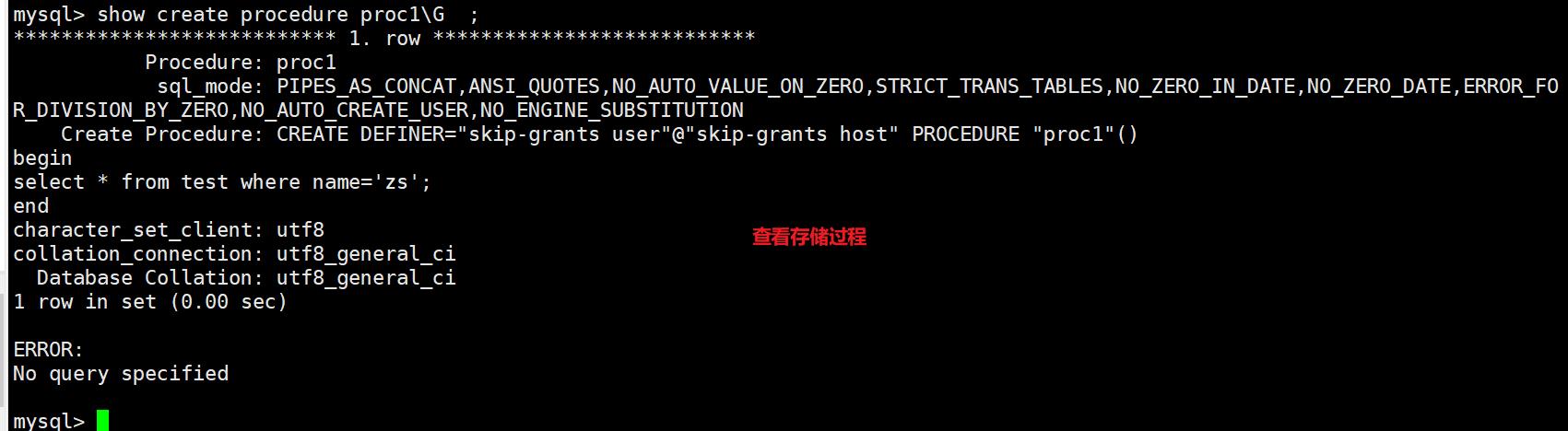
7.3.2、带参数
- .输入参数:in 表示调用者向过程传入值(传入值可以是字面量或变量)
- 输出参数:out 表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
- 输入/输出参数:inout ,即表示调用者向过程传入值,又表示过程向调用者传入值(只能是变量)
delimiter $$
create procedure proc(in 参数 字段类型) #形参
begin
select * from 表格 where 条件语句; #过程体语句
end $$
delimiter ;
call proc('数据'); #实参
mysql> delimiter $$
mysql> create procedure proc2(in new_age int)
-> begin
-> select * from test where age=new_age;
-> end $$
Query OK, 0 rows affected (0.00 sec)
mysql> delimiter ;
mysql> call proc2(40);
+---------+------+----------+
| name | age | addr |
+---------+------+----------+
| wangwu | 40 | shanghai |
| zhaoliu | 40 | huaian |
+---------+------+----------+
7.4、存储控制语句
①条件语句if…end if
#条件语句
delimiter $$
create procedure proc3(in a int) #参数a
begin
declare b int; #参数b与上面参数a类型一致
set b=a*2; #参数b与参数a之间的条件语句
if b>=25 then
update 表格 set 修改字段数据 where 条件语句;
else
update 表格 set 修改字段数据 where 条件语句;
end if ;
end $$
delimiter ;
call proc3 (参数a具体值);
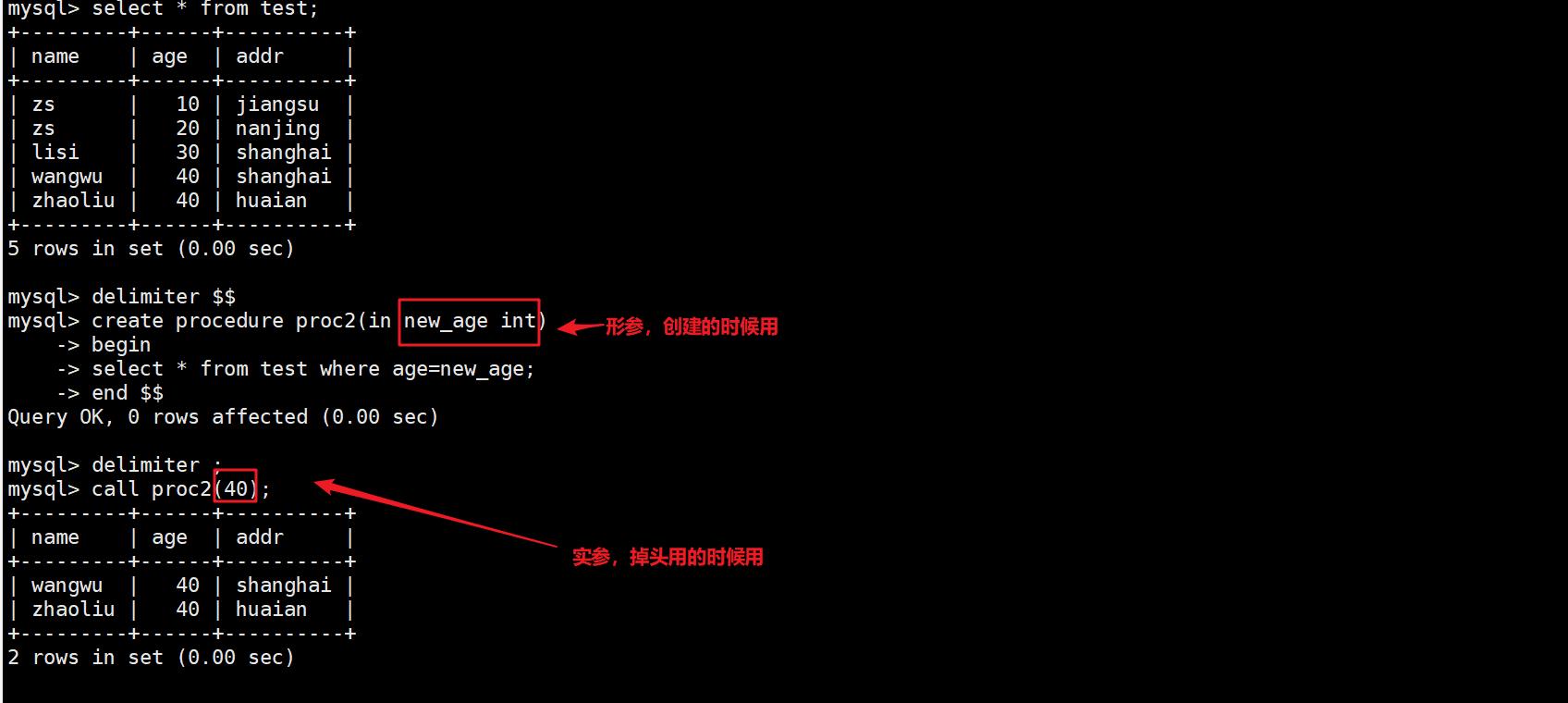
操作:
create table test2 (id int(10));
insert into test2 values (10);
#条件语句
delimiter $$
create procedure proc3(in pro int)
begin
declare var int;
set var=pro*2;
if var>=10 then
update test2 set id=id+1 ;
else
update test2 set id=id-1;
end if ;
end $$
delimiter ;
call proc3 (6);
②循环语句while…end while
delimiter $$
create procedure proc4()
begin
declare a int;
set a=0;
while a<6 do
update 表格 set 修改字段数据 where 条件语句;
set a=a+1;
end while;
end $$
delimiter ;
call proc4;
操作:
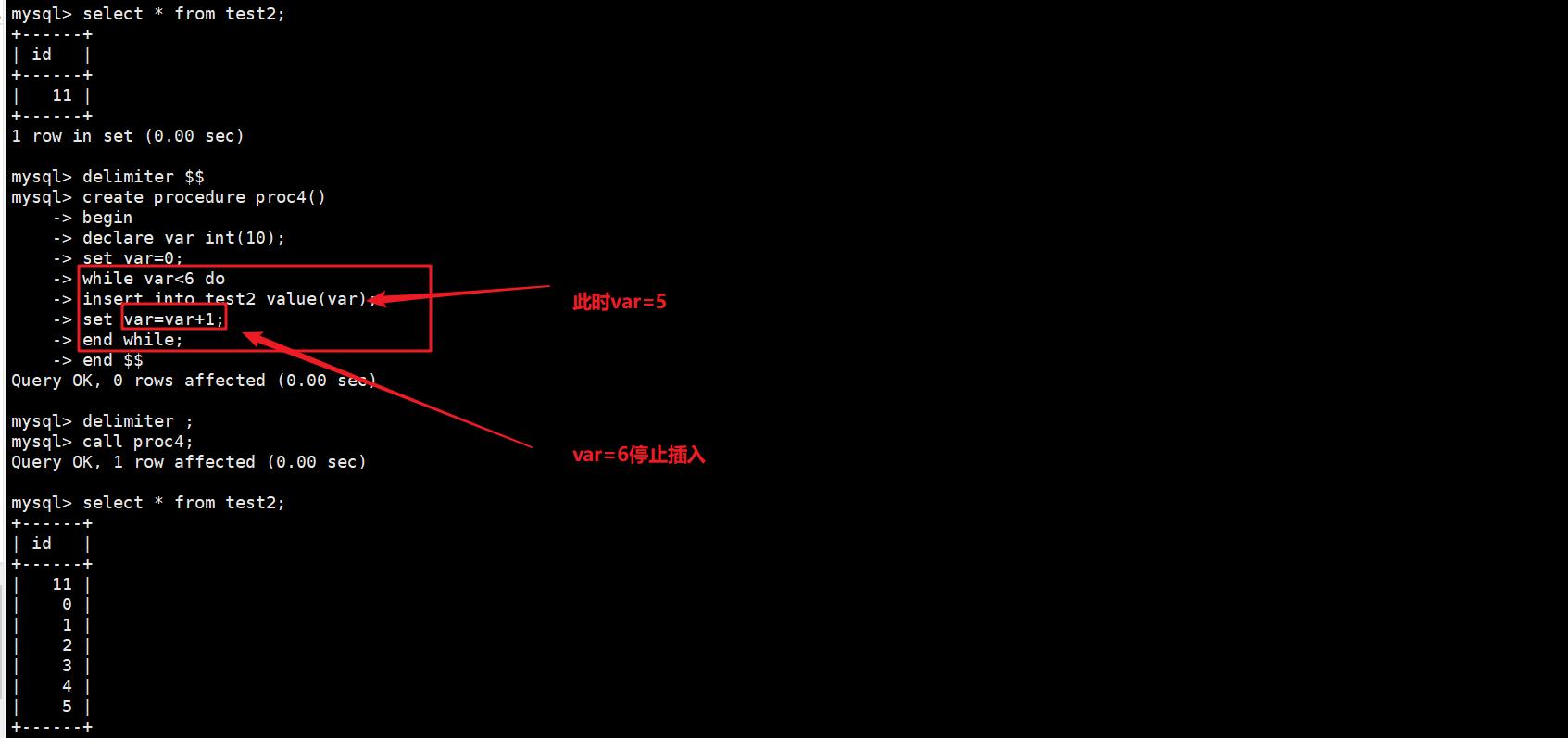
delimiter $$
create procedure proc4()
begin
declare var int(10);
set var=0;
while var<6 do
insert into test2 value(var);
set var=var+1;
end while;
end $$
delimiter ;
call proc4;
以上是关于MySQL———高阶语句(包括排列中位数累加百分比正则存储过程等)的主要内容,如果未能解决你的问题,请参考以下文章