《Learning optical flow from still images》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Learning optical flow from still images》论文笔记相关的知识,希望对你有一定的参考价值。
主页:home page
参考代码:depthstillation
1. 概述
导读:在这篇文章中提出了一个生成光流训练数据的策略,用以弥补真实光流训练数据的不足。文章的策略首先使用单目深度估计网络(MiDas或MeGaDepth)生成单张图像的深度估计结果。对于光流估计所需的另外一个视图图像,文章通过采样生成相机内参、平移矩阵、旋转矩阵、相机焦距、双目基线的方式,在给预测深度基础上使用双目视觉映射关系生成另外一个视图的图像,并且可以对应获取该图像对的光流。在生成另外一个视图的图像过程中使用优化策略解决了映射过程中的occlusion和collision问题。此外,还通过实例分割模型引入实例的运动,因而综合多种因素扩充数据场景。进而使用该策略生成的光流训练数据去监督光流网络(RAFT或PWC-Net),并取得了泛化能力很强的光流估计网络。
文章给出的另外一个视图图像的生成pipeline见下图所示:
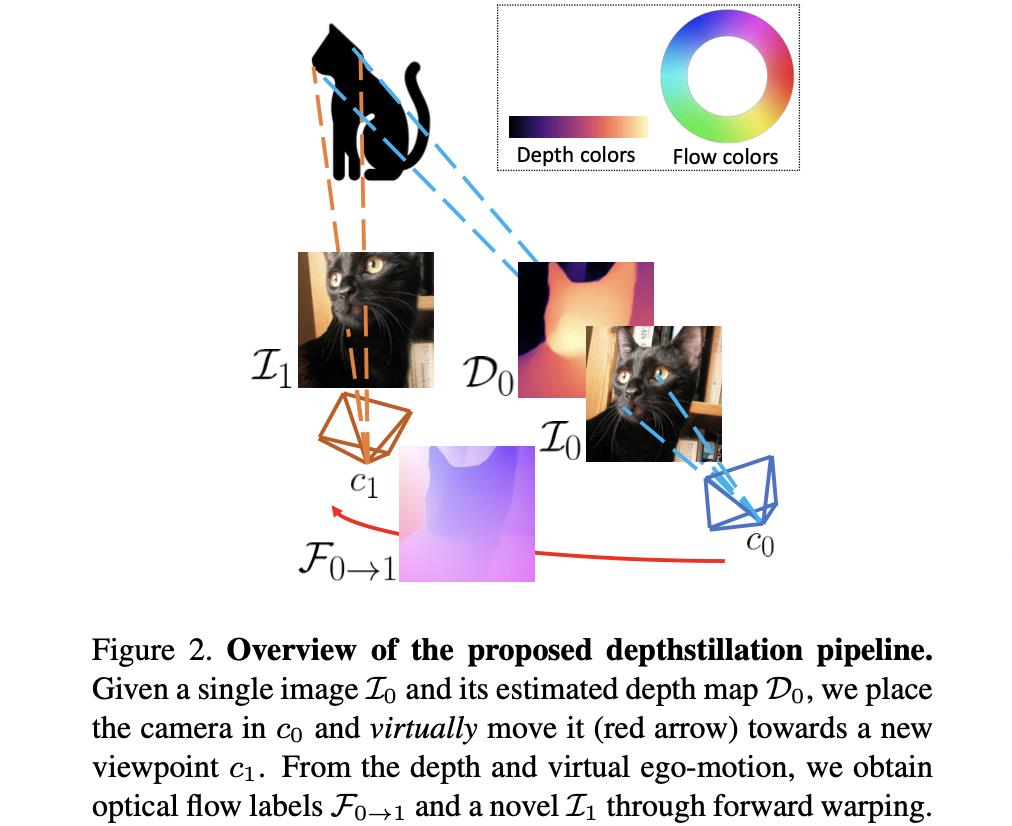
按照上图中给出的流程可以将光流的生成过程归纳为如下几个步骤:
- 1)对于给定图像 I 0 I_0 I0使用单目深度估计网络估计出深度结果 D 0 D_0 D0,之后根据预测深度在采样出来的相机内参数下转换到相机坐标下,这里观察的视角记为 c 0 c_0 c0;
- 2)通过采样平移旋转变换参数,之后经过warp得到另外一个视角 c 1 c_1 c1下的图像 I 1 I_1 I1。在上述的过程中会对occlusion和collision问题采取不同的策略解决,同时为了增加场景的多样性,使用实例分割模型增加了对图像中物体的运动增广,从而模拟实际场景,极大提升数据多样性;
- 3)通过两个视角 c 0 c_0 c0和 c 1 c_1 c1下像素的相对差异得到两张图对应的光流标注 F 0 → 1 F_{0\\rightarrow1} F0→1。
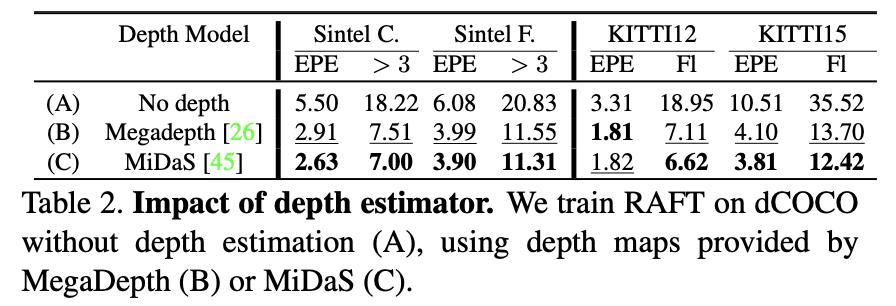
其中单目深度估计网络对性能的影响见下表:
下面展示的是文章的方法从原图输入到最后光流结果和另外一个视角图像的前后对比例子:

2. pipeline构建
2.1 准备工作
给定图像
I
0
I_0
I0,使用单目深度估计网络得到其深度估计结果
D
0
D_0
D0,也就是:
D
0
=
Φ
(
I
0
)
D_0=\\Phi(I_0)
D0=Φ(I0)
在上述过程中得到深度估计结果一般会在边界处呈现较为平滑,对此文章中通过双边滤波的形式对其进行保边滤波,值得注意的是文章的滤波算法在其中添加了一些深度不连续的处理逻辑,具体可以参考下面的这个函数:
# bilateral_filter.py#L13
def sparse_bilateral_filtering(
depth,
image,
filter_size,
sigma_r=0.5,
sigma_s=4.0,
depth_threshold=0.04,
HR=False,
mask=None,
gsHR=True,
edge_id=None,
num_iter=None,
num_gs_iter=None,
)
得到深度之后,通过设定或是采样得到相机内参矩阵
K
K
K可以将图像
I
0
I_0
I0映射到相机坐标下,其视角为
c
0
c_0
c0。那么同样的可以通过采样的方式得到视角
c
0
c_0
c0到视角
c
1
c_1
c1的旋转平移矩阵,也就是
T
0
→
1
=
(
R
1
∣
t
1
)
T_{0\\rightarrow1}=(R_1|t_1)
T0→1=(R1∣t1),那么接下来就可以根据坐标映射关系得到另外一个视图下的图像
I
1
I_1
I1。那么对于其中的每个像素,其变换的过程可以描述为:
p
1
=
K
T
0
→
1
D
0
(
p
0
)
K
−
1
p
0
p_1=KT_{0\\rightarrow1}D_0(p_0)K^{-1}p_0
p1=KT0→1D0(p0)K−1p0
然而,在上述的变换过程中会存在如下的两个问题:
- 1)collision:也就是 I 1 I_1 I1中的某个像素经过映射之后,在图像 I 0 I_0 I0存在多个对应的像素;
- 2)occlusion:也就是 I 1 I_1 I1中的某个像素经过映射之后,在图像 I 0 I_0 I0找不到对应的像素,也就呈现出孔洞(holes)现象;
2.2 collision和occlusion解决策略
collision问题处理:
在collition问题处理中将那些
I
1
I_1
I1中像素在
I
0
I_0
I0存在存在多个对应关系的像素标记为1,从而构建一个二值collision掩膜
M
M
M。那么这么多的对应像素怎么选择呢?文章是选择在
c
1
c_1
c1视角下深度最小的那个像素。
occlusion问题处理:

通过在图像
I
0
I_0
I0和图像
I
1
I_1
I1上进行映射,统计那些在
I
0
I_0
I0上找不到的点,这些点也就没有信息进行填充,如图3中的(a)图。这里将这些点标注为0,则可以得到二值孔洞矩阵
H
H
H,也就是下图中的图3中的(b)图。文章针对这种孔洞的处理方式也很简单,就是采用inpainting策略。经过修补之后得到图3中的(c)图。但是在一些前景拉伸的情况下会存在颜色填充存在问题的情况,见图3中(a)图头发区域,对此经过分析这些artifacts常常存在于非collition像素被collision区域包围的情况下,对此根据之前collision二值矩阵
M
M
M的性质,也就是为0的像素被为1的像素包围了,则可以采用形态学膨胀(
M
′
M^{'}
M′)的方式去获取这些像素,也就是:
P
=
(
M
′
=
=
M
)
P=(M^{'}==M)
P=(M′==M)
其中那些有概率存在问题的像素就会被标记为0,那么可以得到新的occlusion二值掩膜:
H
′
=
H
⋅
P
H^{'}=H\\cdot P
H′=H⋅P
也就是图3中的(d)图,那么同样适用inpainting之后得到最后的效果图(d)。
occlution部分的处理逻辑可以参考:
# depthstillation.py#L256
# Call forward warping routine (C code)
warp( c_void_p(img.numpy().ctypes.data), c_void_p(safe_x[0].numpy().ctypes.data), c_void_p(safe_y[0].numpy().ctypes.data), c_void_p(z1.reshape(-1).numpy().ctypes.data), c_void_p(warped_arr.ctypes.data), c_int(h), c_int(w))
warped_arr = warped_arr.reshape(1,h,w,5).astype(np.uint8)
# Warped image
im1_raw = warped_arr[0,:,:,0:3]
# Validity mask H
masks["H"] = warped_arr[0,:,:,3:4]
# Collision mask M
masks["M"] = warped_arr[0,:,:,4:5]
# Keep all pixels that are invalid (H) or collide (M)
masks["M"] = 1-(masks["M"]==masks["H"]).astype(np.uint8)
# Dilated collision mask M'
kernel = np.ones((3,3),np.uint8)
masks["M'"] = cv2.dilate(masks["M"],kernel,iterations = 1)
masks["P"] = (np.expand_dims(masks["M'"], -1) == masks["M"]).astype(np.uint8)
# Final mask P
masks["H'"] = masks["H"]*masks["P"]
2.3 实例目标运动增广
为了增加数据的多样型和光流估计模型的鲁棒性,文章使用实例分割模型
Ω
\\Omega
Ω对图像进行检测,则得到
N
N
N个实例结果:
∏
=
{
∏
i
,
i
∈
[
1
,
N
]
}
=
Ω
(
I
0
)
\\prod=\\{\\prod_i,i\\in[1,N]\\}=\\Omega(I_0)
∏={i∏,i∈[1,N]}=Ω(I0)
但是在实际的过程中会根据实例的面积选择前
n
n
n个面积最大的实例进行运算。对于每个实例会采取不同的旋转平移变换参数
π
i
\\pi_i
πi进行变换,则不像素点之间的对应关系可以描述为: