一文速览机器学习的类别(Python代码)
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文速览机器学习的类别(Python代码)相关的知识,希望对你有一定的参考价值。


作者:泳鱼
来源:算法进阶
机器学习按照学习数据经验的不同,即训练数据的标签信息的差异,可以分为:
*监督学习(supervised learning)
*非监督学习(unsupervised learning)
*半监督学习(semi- supervised learning)
*强化学习(reinforcement learning)。
机器学习类别
监督学习
监督学习是机器学习中应用最广泛及成熟的,它是从有标签的数据样本(x,y)中,学习如何关联x到正确的y。这过程就像是模型在给定题目的已知条件(特征x),参考着答案(标签y)学习,借助标签y的监督纠正,模型通过算法不断调整自身参数以达到学习目标。
监督学习常用的模型有:线性回归、朴素贝叶斯、K最近邻、逻辑回归、支持向量机、神经网络、决策树、集成学习(如LightGBM)等。按照应用场景,以模型预测结果Y的取值有限或者无限的,可再进一步分为分类或者回归模型。
分类模型:
分类模型是处理预测结果取值有限的分类任务。如下示例通过逻辑回归分类模型,根据温湿度、风速等情况去预测是否会下雨。
逻辑回归简介
逻辑回归虽然名字有带“回归”,但其实它是一种广义线性的分类模型,由于模型简单和高效,在实际中应用非常广泛。
逻辑回归模型结构可以视为双层的神经网络(如图4.5)。模型输入x,通过神经元激活函数f(f为sigmoid函数)将输入非线性转换至0~1的取值输出,最终学习的模型决策函数为Y=sigmoid(wx + b)。其中模型参数w即对应各特征(x1, x2, x3...)的权重(w1,w2,w3...),b模型参数代表着偏置项,Y为预测结果(0~1范围)。
模型的学习目标为极小化交叉熵损失函数。模型的优化算法常用梯度下降算法去迭代求解损失函数的极小值,得到较优的模型参数。
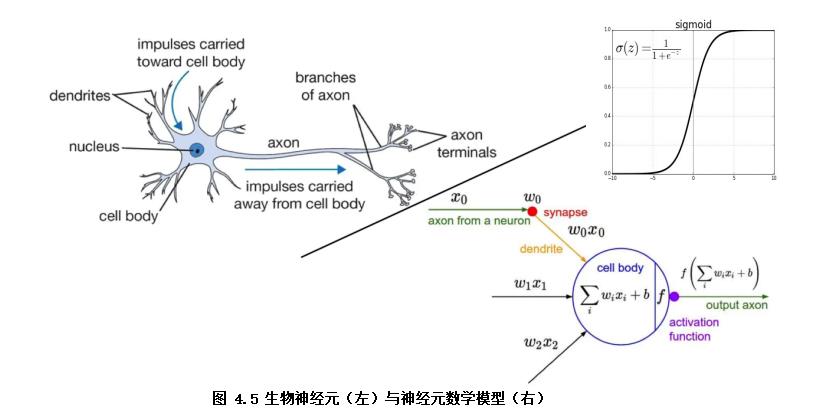
代码示例
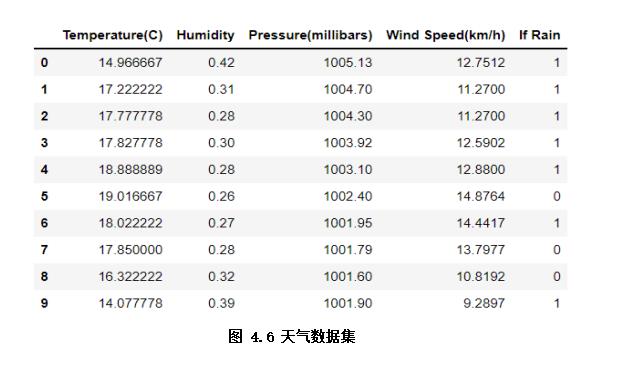
示例所用天气数据集是简单的天气情况记录数据,包括室外温湿度、风速、是否下雨等,在分类任务中,我们以是否下雨作为标签,其他为特征(如图4.6)
import pandas as pd # 导入pandas库
weather_df = pd.read_csv('./data/weather.csv') # 加载天气数据集
weather_df.head(10) # 显示数据的前10行
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
x = weather_df.drop('If Rain', axis=1) # 特征x
y = weather_df['If Rain'] # 标签y
lr = LogisticRegression()
lr.fit(x, y) # 模型训练
print("前10个样本预测结果:", lr.predict(x[0:10]) ) # 模型预测前10个样本并输出结果
以训练的模型输出前10个样本预测结果为:[1 1 1 1 1 1 0 1 1 1],对比实际前10个样本的标签:[1 1 1 1 1 0 1 0 0 1],预测准确率并不高。在后面章节我们会具体介绍如何评估模型的预测效果,以及进一步优化模型效果。
回归模型
回归模型是处理预测结果取值无限的回归任务。如下代码示例通过线性回归模型,以室外湿度为标签,根据温度、风力、下雨等情况预测室外湿度。
线性回归简介
线性回归模型前提假设是y和x呈线性关系,输入x,模型决策函数为Y=wx+b。模型的学习目标为极小化均方误差损失函数。模型的优化算法常用最小二乘法求解最优的模型参数。
代码示例
from sklearn.linear_model import LinearRegression #导入线性回归模型
x = weather_df.drop('Humidity', axis=1) # 特征x
y = weather_df['Humidity'] # 标签y
linear = LinearRegression()
linear.fit(x, y) # 模型训练
print("前10个样本预测结果:", linear.predict(x[0:10]) ) # 模型预测前10个样本并输出结果
非监督学习
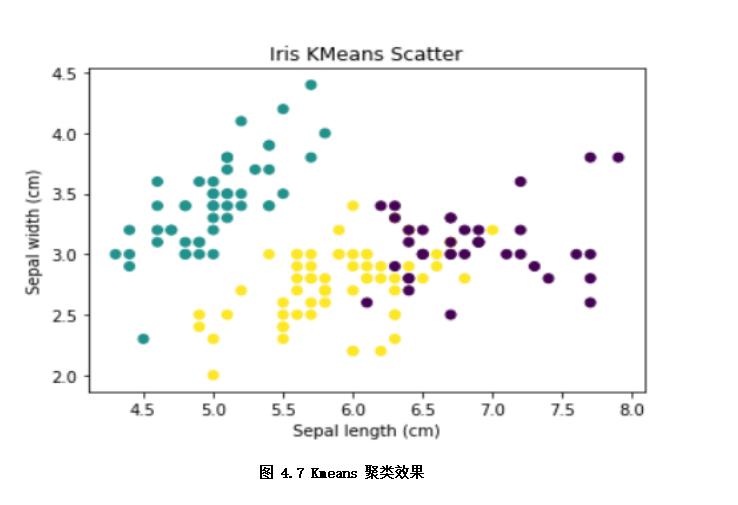
非监督学习也是机器学习中应用较广泛的,是从无标注的数据(x)中,学习数据的内在规律。这个过程就像模型在没有人提供参考答案(y),完全通过自己琢磨题目的知识点,对知识点进行归纳、总结。按照应用场景,非监督学习可以分为聚类,特征降维和关联分析等方法。如下示例通过Kmeans聚类划分出不同品种的iris鸢尾花样本。
Kmeans聚类简介
代码示例
from sklearn.datasets import load_iris # 数据集
from sklearn.cluster import KMeans # Kmeans模型
import matplotlib.pyplot as plt # plt画图
lris_df = datasets.load_iris() # 加载iris鸢尾花数据集,数据集有150条样本,分三类的iris品种
x = lris_df.data
k = 3 # 聚类出k个簇类, 已知数据集有三类品种, 设定为3
model = KMeans(n_clusters=k)
model.fit(x) # 训练模型
print("前10个样本聚类结果:",model.predict(x[0:10]) ) # 模型预测前10个样本并输出聚类结果:[1 1 1 1 1 1 1 1 1 1]
# 样本的聚类效果以散点图展示
x_axis = lris_df.data[:,0] # 以iris花的sepal length (cm)特征作为x轴
y_axis = lris_df.data[:,1] # 以iris花的sepal width (cm)特征作为y轴
plt.scatter(x_axis, y_axis, c=model.predict(x)) # 分标签颜色展示聚类效果
plt.xlabel('Sepal length (cm)')#设定x轴注释
plt.ylabel('Sepal width (cm)')#设定y轴注释
plt.title('Iris KMeans Scatter')
plt.show() # 如图4.7聚类效果
半监督学习
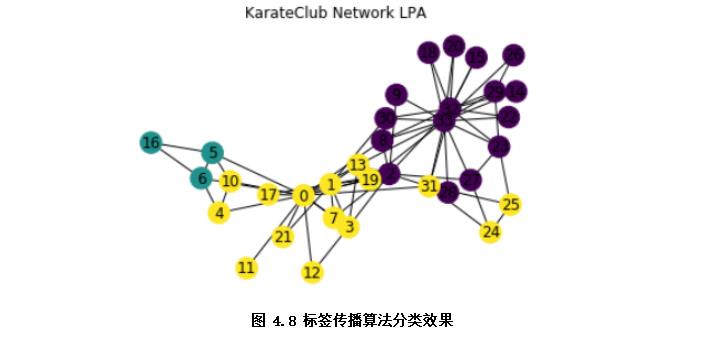
半监督学习是介于传统监督学习和无监督学习之间(如图4.8),其思想是在有标签样本数量较少的情况下,以一定的假设前提在模型训练中引入无标签样本,以充分捕捉数据整体潜在分布,改善如传统无监督学习过程盲目性、监督学习在训练样本不足导致的学习效果不佳的问题。按照应用场景,半监督学习可以分为聚类,分类及回归等方法。如下示例通过基于图的半监督算法——标签传播算法分类俱乐部成员。

标签传播算法简介
标签传播算法(LPA)是基于图的半监督学习分类算法,基本思路是在所有样本组成的图网络中,从已标记的节点标签信息来预测未标记的节点标签。
首先利用样本间的关系(可以是样本客观关系,或者利用相似度函数计算样本间的关系)建立完全图模型。
接着向图中加入已标记的标签信息(或无),无标签节点是用一个随机的唯一的标签初始化。
将一个节点的标签设置为该节点的相邻节点中出现频率最高的标签,重复迭代,直到标签不变即算法收敛。
代码示例
该示例的数据集空手道俱乐部是一个被广泛使用的社交网络,其中的节点代表空手道俱乐部的成员,边代表成员之间的相互关系。
import networkx as nx # 导入networkx图网络库
import matplotlib.pyplot as plt
from networkx.algorithms import community # 图社区算法
G=nx.karate_club_graph() # 加载美国空手道俱乐部图数据
#注: 本例未使用已标记信息, 严格来说是半监督算法的无监督应用案例
lpa = community.label_propagation_communities(G) # 运行标签传播算法
community_index = {n: i for i, com in enumerate(lpa) for n in com} # 各标签对应的节点
node_color = [community_index[n] for n in G] # 以标签作为节点颜色
pos = nx.spring_layout(G) # 节点的布局为spring型
nx.draw_networkx_labels(G, pos) # 节点序号
nx.draw(G, pos, node_color=node_color) # 分标签颜色展示图网络
plt.title(' Karate_club network LPA')
plt.show() #展示分类效果,不同颜色为不同类别
强化学习
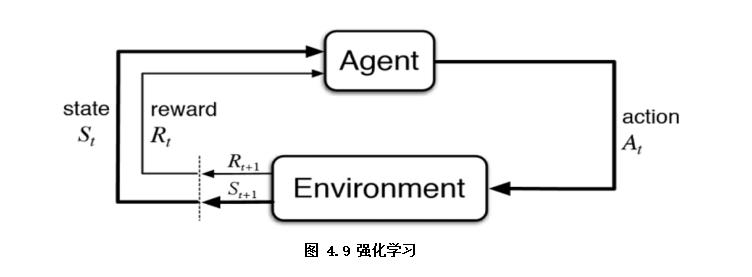
强化学习从某种程度可以看作是有延迟标签信息的监督学习(如图4.9),是指智能体Agent在环境Environment中采取一种行为action,环境将其转换为一次回报reward和一种状态表示state,随后反馈给智能体的学习过程。本书中对强化学习仅做简单介绍,有兴趣可以自行扩展。


9月11日,面基技术大佬,相约腾讯北京总部,立即扫码报名
往
期
回
顾
技术
福利
技术
资讯

分享

点收藏

点点赞

点在看
以上是关于一文速览机器学习的类别(Python代码)的主要内容,如果未能解决你的问题,请参考以下文章