如何让TCP重传如丝般柔滑
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何让TCP重传如丝般柔滑相关的知识,希望对你有一定的参考价值。
Linux TCP拥塞状态机核心函数tcp_fastretrans_alert过于抢戏了。
在检测到无论是真是假的丢包后,拥塞控制算法能做的事情非常少,即使拥塞控制算法断定这是一次与拥塞无关的丢包甚至根本就没有丢包,拥塞状态机依然要拿回控制权,拥塞控制算法只能等待undo。
为什么不能让拥塞控制算法全权接管包括重传在内的全部TCP拥塞状态机转换?没有为什么,可能就是这块代码现在已经成了一脬屎,无人改得动了吧,Linux之外的其它系统,未必是这个情形,甚至都可以完全无视拥塞控制。
对于Linux TCP,无论拥塞控制算法多么智能,事情总是可能在tcp_fastretrans_alert函数逻辑里面乱套,突然憋住,窗口被打折,拥塞控制就没得玩了。
几年前我尝试重构TCP拥塞状态机转换逻辑,失败了,这片代码耦合性太高,到处粘连,只想砸电脑。如今面对视频流直播频繁卡顿的场景,哪怕不是完全重写,这件事还是要换一种方式去做。
依然周六,写点想法。
在引入fast recovery前,TCP重传完全依靠超时重传,即便在引入fast recovery之后,在它无法被触发时,loss recovery依然作为一种兜底策略存在。
依靠超时兜底,重传没有问题,但是在触发超时重传之前会有一段RTO的延迟,这段空窗期将导致失速,且超时重传过程效率极低,这引入严重的卡顿,对于直播场景,这种体验很差。
抑制卡顿的根本,时刻要有报文可发,不管是新报文,还是已经被标记lost的重传报文,一定要持续发送,不能停,一停顿就会失速。在什么情况下会失速,跌入RTO超时呢?
在TLP和Early Retransmit的支持下,假设一旦发生丢包,总是会进入fast recovery逻辑,问题是,什么情况下fast recovery会停止进而跌入超时呢?
在fast recovery过程中,考虑两个序列号跨度很大的报文被两次ACK以颠倒的顺序被SACK,这会导致reordering增加,进而阻碍报文被标记为lost,这就意味着可能没有报文可重传。如下图所示:
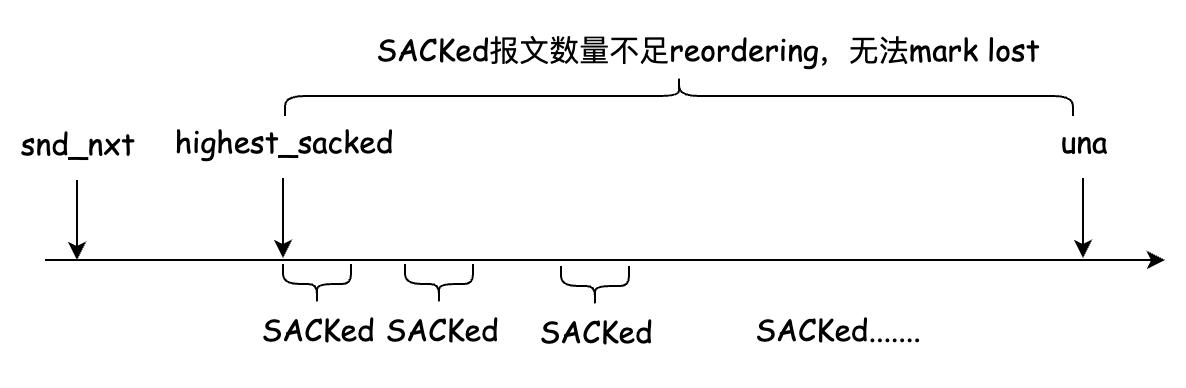
此外,就是loss retransmission,即报文虽然被重传了,但重传报文丢失了,TCP无法相对精确地检测这种情况。
有一种比较low的策略检测loss retransmission,该机制不受reordering的影响。当收到SACK时,会将当前最高被SACK报文之前被重传过的报文重新标记为lost,详情参见tcp_mark_lost_retrans函数。但该机制会带来reordering引入的误判,导致重传率增加。问题的根源在于,SACK无法区分同一个报文的正常传输和重传。
在引入基于时间序的RACK(参考RFC8985)后,这种low策略就不需要了:
Lost retransmission: Consider a flight of three data segments (P1, P2, P3) that are sent; P1 and P2 are dropped. Suppose the transmission of each segment is at least RACK.reo_wnd after the transmission of the previous segment. When P3 is SACKed, RACK will mark P1 and P2 as lost, and they will be retransmitted as R1 and R2. Suppose R1 is lost again but R2 is SACKed; RACK will mark R1 as lost and trigger retransmission again. Again, neither the conventional three-duplicate ACK threshold approach, nor the loss recovery algorithm [RFC6675], nor the Forward Acknowledgment [FACK] algorithm can detect such losses. And such a lost retransmission can happen when TCP is being rate-limited, particularly by token bucket policers with a large bucket depth and low rate limit; in such cases, retransmissions are often lost repeatedly because standard congestion control requires multiple round trips to reduce the rate below the policed rate.
显然RACK应对lost retransmission更加顺滑,除非链路彻底中断或者RACK的reorder window大到一个srtt,不然不会出现无包可发的情况。
我们知道BBR是基于pacing rate的,若不是有RACK加持提供不间断的报文,它将很容易失速,BBR将无法实至名归。
来看另一种失速场景,在一些丢失的报文被标记为lost之前,DSACK的undo逻辑将连接从fast recovey状态拉回到disorder状态后无报文可发,如下图所示:
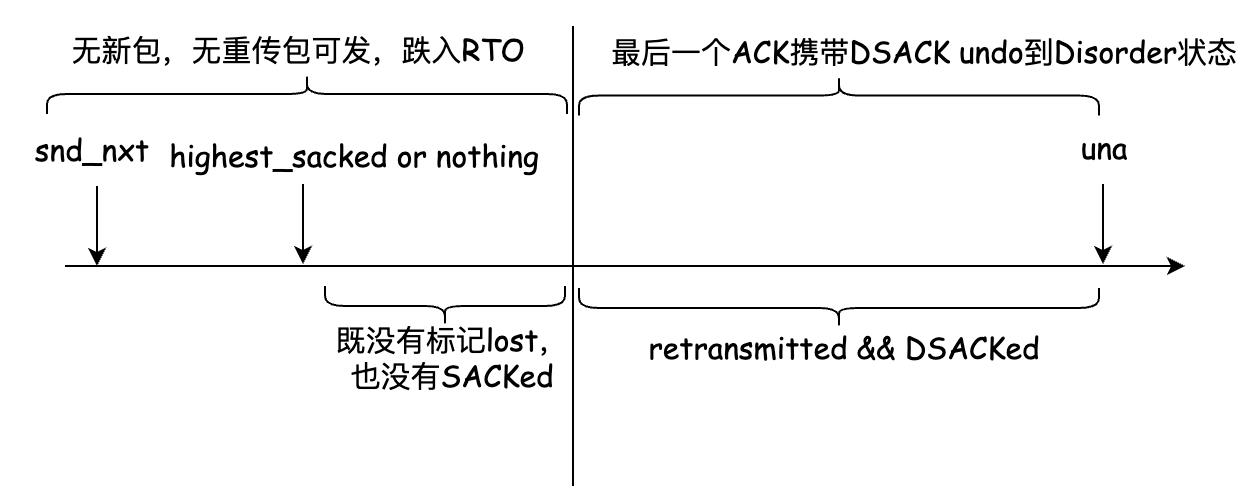
RACK似乎不受这个问题的影响,因为每发送一个报文均会被纳入一个时间序队列,无论是新报文还是重传报文。即便是一个DSACK造成了undo,它依然会导致后发送的报文先被SACK,被RACK机制继续标记lost,避免了失速,RACK是在一个时间序上连续标记lost的。如下图所示:
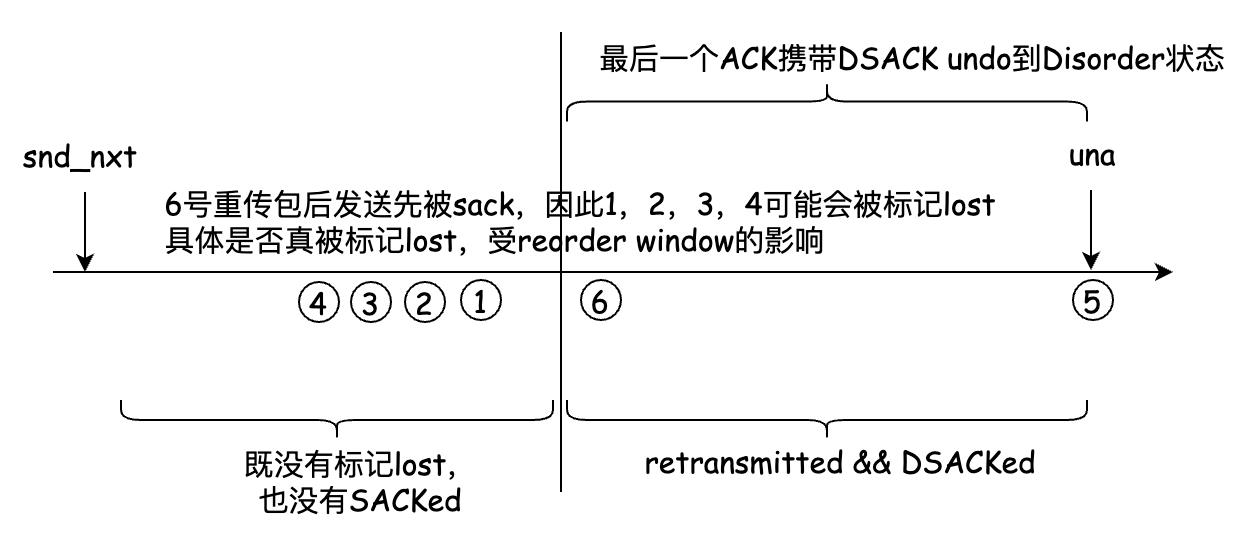
Linux TCP的tcp_fastretrans_alert实现有问题,导致RACK未竟全功,但这个问题最近被解决了:
https://git.kernel.org/pub/scm/linux/kernel/git/netdev/net-next.git/commit/?id=a29cb6914681a55667436a9eb7a42e28da8cf387
唯一影响RACK机制标记lost的因素似乎仅来自DSACK导致RACK的reorder window变大,进而阻碍报文被标记lost导致失速。
针对这个问题,最近的两个patch使该问题得到有效的抑制:
https://git.kernel.org/pub/scm/linux/kernel/git/netdev/net-next.git/commit/?id=63f367d9de77b30f58722c1be9e334fb0f5f342d
https://git.kernel.org/pub/scm/linux/kernel/git/netdev/net-next.git/commit/?id=a657db0350bb8f568897835b6189c84a89f13292
回到最开始的问题,真的还需要RTO超时兜底吗?由于端到端序列号空间里的大戏异常繁复,没人会料到到底会发生什么,兜底仍然必要,问题是如果非要兜底,为什么不用TLP呢?
既然已经在fast recovery状态,那么TCP拥塞控制机制已经感知到了拥塞并为缓解拥塞做出了反应,比如降窗,执行inflight守恒等,这是一种和RTO超时平等的甚至更优的策略,fast recovery提前发现了丢包并且可以更快地重传。
理论上,在fast recovery重传可以重传的最后一个报文后,启用TLP是合理的。假设链路从物理上断开了,如果fast recovery无能为力,RTO超时后的loss recovery又能多做些什么呢?
当fast recovery过程中出现无包可发的失速状态时,此时需要的是一个起搏机制,而不是兜底策略。任何TCP实现均需要ACK反馈来起搏的,如果因为没有收到ACK而失速,起搏一下即可,似乎没有必要进入超时后的loss recovery状态,代价太大了。
我做了一个简单的试验,来模拟上述的TCP起搏器,保证TCP ACK时钟连续:
- fast recovery过程中启用的timer不用RTO,而用TLP作为timeout。
- 进入RTO超时处理时,如果是fast recovery前n次(暂定n为1)进来的,则不进入loss状态,只是重传重传队列第一个包,即una。
- 在RTO超时处理函数里reset掉reordering以及RACK的reorder window steps。
diff --git a/include/net/inet_connection_sock.h b/include/net/inet_connection_sock.h
index 3c8c59471bc1..51448607ecd4 100644
--- a/include/net/inet_connection_sock.h
+++ b/include/net/inet_connection_sock.h
@@ -102,6 +102,7 @@ struct inet_connection_sock {
icsk_ca_initialized:1,
icsk_ca_setsockopt:1,
icsk_ca_dst_locked:1;
+ __u8 icsk_ca_pacemaking_cnt;
__u8 icsk_retransmits;
__u8 icsk_pending;
__u8 icsk_backoff;
diff --git a/net/ipv4/tcp_input.c b/net/ipv4/tcp_input.c
index 69a545db80d2..326957f7939a 100644
--- a/net/ipv4/tcp_input.c
+++ b/net/ipv4/tcp_input.c
@@ -2740,6 +2740,7 @@ EXPORT_SYMBOL(tcp_simple_retransmit);
void tcp_enter_recovery(struct sock *sk, bool ece_ack)
{
struct tcp_sock *tp = tcp_sk(sk);
+ struct inet_connection_sock *icsk = inet_csk(sk);
int mib_idx;
if (tcp_is_reno(tp))
@@ -2757,6 +2758,7 @@ void tcp_enter_recovery(struct sock *sk, bool ece_ack)
tp->prior_ssthresh = tcp_current_ssthresh(sk);
tcp_init_cwnd_reduction(sk);
}
+ icsk->icsk_ca_pacemaking_cnt = 0;
tcp_set_ca_state(sk, TCP_CA_Recovery);
}
@@ -2940,6 +2942,7 @@ static void tcp_fastretrans_alert(struct sock *sk, const u32 prior_snd_una,
/* E. Process state. */
switch (icsk->icsk_ca_state) {
case TCP_CA_Recovery:
+ icsk->icsk_ca_pacemaking_cnt = 0;
if (!(flag & FLAG_SND_UNA_ADVANCED)) {
if (tcp_is_reno(tp))
tcp_add_reno_sack(sk, num_dupack, ece_ack);
diff --git a/net/ipv4/tcp_output.c b/net/ipv4/tcp_output.c
index fbf140a770d8..3300f1720742 100644
--- a/net/ipv4/tcp_output.c
+++ b/net/ipv4/tcp_output.c
@@ -3352,10 +3352,27 @@ void tcp_xmit_retransmit_queue(struct sock *sk)
rearm_timer = true;
}
- if (rearm_timer)
+ if (rearm_timer) {
+ u32 timeout, rto_delta_us;
+
+ if (tp->srtt_us) {
+ timeout = usecs_to_jiffies(tp->srtt_us >> 2);
+ if (tp->packets_out == 1)
+ timeout += TCP_RTO_MIN;
+ else
+ timeout += TCP_TIMEOUT_MIN;
+ } else {
+ timeout = TCP_TIMEOUT_INIT;
+ }
+
+ rto_delta_us = tcp_rto_delta_us(sk); /* How far in future is RTO? */
+ if (rto_delta_us > 0)
+ timeout = min_t(u32, timeout, usecs_to_jiffies(rto_delta_us));
+
tcp_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
- inet_csk(sk)->icsk_rto,
+ timeout,
TCP_RTO_MAX);
+ }
}
/* We allow to exceed memory limits for FIN packets to expedite
diff --git a/net/ipv4/tcp_timer.c b/net/ipv4/tcp_timer.c
index 4ef08079ccfa..2da62f0ea21c 100644
--- a/net/ipv4/tcp_timer.c
+++ b/net/ipv4/tcp_timer.c
@@ -533,7 +533,14 @@ void tcp_retransmit_timer(struct sock *sk)
__NET_INC_STATS(sock_net(sk), mib_idx);
}
- tcp_enter_loss(sk);
+ if (icsk->icsk_ca_state != TCP_CA_Recovery || icsk->icsk_ca_pacemaking_cnt)
+ tcp_enter_loss(sk);
+ else {
+ tp->reordering = min_t(unsigned int, tp->reordering,
+ net->ipv4.sysctl_tcp_reordering);
+ tp->rack.reo_wnd_steps = 1;
+ icsk->icsk_ca_pacemaking_cnt ++;
+ }
icsk->icsk_retransmits++;
if (tcp_retransmit_skb(sk, tcp_rtx_queue_head(sk), 1) > 0) {
如果TLP的超时时间后起搏无效,大概率RTO超时后也救不了,此时还能做什么?最快意的方式并不是期待超时重传。与其死命重传,不如干脆断开TCP连接重连,除非所有可达的路由失效或者网线断了,事情大概率就会变得好起来。
浙江温州皮鞋湿,下雨进水不会胖。
以上是关于如何让TCP重传如丝般柔滑的主要内容,如果未能解决你的问题,请参考以下文章