Doris--简单使用
Posted 宝哥大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Doris--简单使用相关的知识,希望对你有一定的参考价值。
一、数据表的创建与数据导入
1.1、创建表
1.1.1、单分区
CREATE TABLE table1
(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0' -- 聚合模型, value column 使用sum聚合
)
AGGREGATE KEY(siteid, citycode, username) -- 聚合模型
DISTRIBUTED BY HASH(siteid) BUCKETS 10 -- 分桶
PROPERTIES("replication_num" = "1"); -- 测试使用, 单个副本
1.1.2、多分区
CREATE TABLE table2
(
event_day DATE,
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, siteid, citycode, username)
PARTITION BY RANGE(event_day) -- 分区
(
PARTITION p201706 VALUES LESS THAN ('2017-07-01'),
PARTITION p201707 VALUES LESS THAN ('2017-08-01'),
PARTITION p201708 VALUES LESS THAN ('2017-09-01')
)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");
1.2、数据导入
此处仅用于测试导入数据
insert into table1 values \\
("1","1","jim","2"), \\
("2","1","grace","2"), \\
("3","2","tom","2"), \\
("4","3","bush","3"), \\
("5","3","helen","3");
insert into table2 values \\
("2017-07-03","1","1","jim","2"),\\
("2017-07-05","2","1","grace","2"),\\
("2017-07-12","3","2","tom","2"),\\
("2017-07-15","4","3","bush","3"),\\
("2017-07-12","5","3","helen","3");
二、数据查询
doris 兼容 mysql 协议, 查询基本一致
2.1、Join 查询
> SELECT SUM(table1.pv) FROM table1 JOIN table2 WHERE table1.siteid = table2.siteid;
+--------------------+
| sum(`table1`.`pv`) |
+--------------------+
| 14 |
+--------------------+
1 row in set (0.01 sec)
2.2、子查询
> SELECT SUM(pv) FROM table2 WHERE siteid IN (SELECT siteid FROM table1 WHERE siteid > 2);
+-----------+
| sum(`pv`) |
+-----------+
| 8 |
+-----------+
1 row in set (0.04 sec)
三、表结构变更
使用 ALTER TABLE COLUMN 命令可以修改表的 Schema,包括如下修改:
- 增加列
- 删除列
- 修改列类型
- 改变列顺序
以下通过使用示例说明表结构变更:
3.1、新增列
-- 新增一列 uv,类型为 BIGINT,聚合类型为 SUM,默认值为 0:
ALTER TABLE table1 ADD COLUMN uv BIGINT SUM DEFAULT '0' after pv;
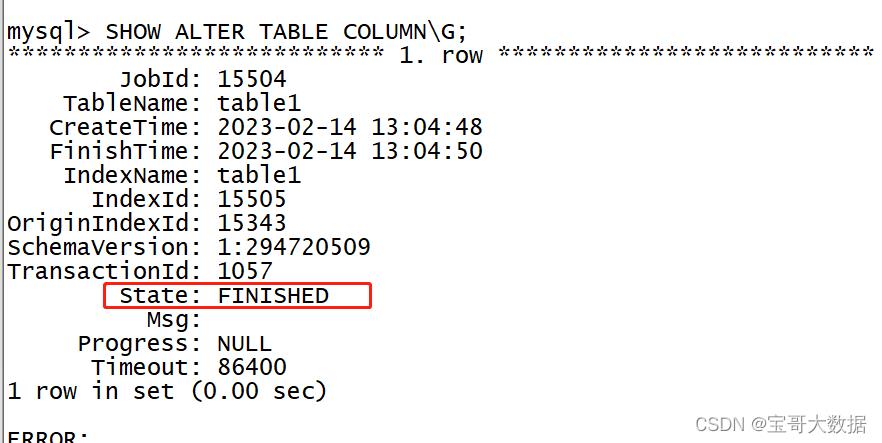
提交成功后,可以通过以下命令查看作业进度:
SHOW ALTER TABLE COLUMN;
当作业状态为 FINISHED,则表示作业完成。新的 Schema 已生效。
可以使用以下命令取消当前正在执行的作业:
CANCEL ALTER TABLE COLUMN FROM table1;
四、Rollup
ROLLUP 在多维分析中是“上卷”的意思,即将数据按某种指定的粒度(更粗粒度)进行进一步聚合。
4.1、Rollup 创建
Rollup 可以理解为 Table 的一个物化索引结构。物化 是因为其数据在物理上独立存储,而 索引 的意思是,Rollup可以调整列顺序以增加前缀索引的命中率,也可以减少key列以增加数据的聚合度。
对于 table1 明细数据是 siteid, citycode, username 三者构成一组 key,从而对 pv 字段进行聚合;如果业务方经常有看城市 pv 总量的需求,可以建立一个只有 citycode, pv 的rollup。
ALTER TABLE table1 ADD ROLLUP rollup_city(citycode, pv);
提交成功后,可以通过以下命令查看作业进度:
SHOW ALTER TABLE ROLLUP;
当作业状态为 FINISHED,则表示作业完成。
Rollup 建立之后,查询不需要指定 Rollup 进行查询。还是指定原有表进行查询即可。程序会自动判断是否应该使用 Rollup。是否命中 Rollup可以通过 EXPLAIN your_sql; 命令进行查看。

4.2、Rollup 与 三个数据模型的查询
4.2.1、Aggregate 和 Unique 模型中的 ROLLUP
因为 Unique 只是 Aggregate 模型的一个特例,所以不加以区别。
聚合模型 中 rollup的使用 和上面的一致, 为了更粗粒度的聚合,减少数据的扫描。
4.2.2、Duplicate 模型中的 ROLLUP
因为 Duplicate 模型没有聚合的语意。所以该模型中的 ROLLUP,已经失去了“上卷”这一层含义。而仅仅是作为调整列顺序,以命中前缀索引的作用,加快查询。
五、物化视图
物化视图是一种以空间换时间的数据分析加速技术。Doris 支持在基础表之上建立物化视图。比如可以在明细数据模型的表上建立基于部分列的聚合视图,这样可以同时满足对明细数据和聚合数据的快速查询。
同时,Doris 能够自动保证物化视图和基础表的数据一致性,并且在查询时自动匹配合适的物化视图,极大降低用户的数据维护成本,为用户提供一个一致且透明的查询加速体验。
关于物化视图的具体介绍,可参阅 物化视图
5.1、物化视图 VS Rollup
在没有物化视图功能之前,用户一般都是使用 Rollup 功能通过预聚合方式提升查询效率的。但是 Rollup 具有一定的局限性,他不能基于明细模型做预聚合。
物化视图则在覆盖了 Rollup 的功能的同时,还能支持更丰富的聚合函数(Rollup只能使用和创建表时一致的聚合函数)。所以物化视图其实是 Rollup 的一个超集。
也就是说,之前 ALTER TABLE ADD ROLLUP 语法支持的功能现在均可以通过 CREATE MATERIALIZED VIEW 实现。
以上是关于Doris--简单使用的主要内容,如果未能解决你的问题,请参考以下文章