哈希图像相似性识别
Posted KaZaKun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈希图像相似性识别相关的知识,希望对你有一定的参考价值。
题目:根据提供的数据实现一个图片检索类,输入一张图片,展示数据库中最相似的前 n 张照片。
数据资源: 约 4000 张人脸
要点:如何计算图片的相似性;如何实现快速的比对。
注意:图片数据应该只导入内存一次,避免每次检索 都要重新导入图片;实现统计一次检索耗费时间的装饰器;检索应有阈值要求(如相似性大于某值时定义为不相似),当在对应阈值下无检索结果时抛出自定义异常并在上层调用时处理;
一、 代码思路
- 导入图片路径,存储为一个
list - 计算图片的哈希值。 建立字典,存储每张图片的路径及对应的哈希值
- 在主函数中建立
while循环,输入图片路径时开始检索。若输入的图片路径不正确,则输出“图片不存在”。输入q时,退出程序。While循环可以使图片数据只导入内存一次,避免每次检索都要重新导入图片 - 实现统计一次检索耗费时间的装饰器。当两张图片的哈希值的差值小于 20 时,定义为相似 。将相似图片存储在队列中。最后画图,当在对应阈值下的相似照片不足 9 张值,抛出自定义异常。
二、 代码实现
- 导入图片路径,存储为一个
list
import sys
import os
import numpy as np
from heapq import heappush
from heapq import heappop
import matplotlib.pyplot as plt
from PIL import Image
import imagehash
import time
import line_profiler
#load images
def load_images():
imflist=[]
fpath = r'icon'
for root,dirs,files in os.walk(fpath):
for file in files:
if file.find('.ppm')>0:
print(os.path.join(root,file))
imflist.append(os.path.join(root,file))
return imflist
- 计算图片的哈希值。建立字典,存储每张图片的路径及对应的哈希值
def hash_image(flist):
im_hash_map={}
for file in flist:
im = Image.open(file)
im_a_hash = imagehash.average_hash(im)
im_hash_map[file] = im_a_hash
return im_hash_map
- 实现装饰期和图片检索
实现统计一次检索耗费时间的装饰器@profile:安装line_profiler,安装完成后,将有一个“line_profiler”的新模组和一个”kernprof.py”可执行脚本。在想测量执行时间的函数上装饰@profile装饰器,在命令行中输入kernprof.py -l -v func_name。kernprof.py脚本将会在执行的时自动地注入到你的脚本的运行。
-l, --line-by-line Use the line-by-line profiler from the line_profiler module instead of Profile. Implies --builtin.
-v, --view View the results of the profile in addition to saving it.
当两张图片的哈希值的差值小于20 时,定义为相似。将相似图片存储在队列中。最后画图,当在对应阈值下的相似照片不足 9 张值,抛出自定义异常。
@profile
def simi_image(im_hash_map, im):
simi_images=[]
if im in im_hash_map.keys():
for image in im_hash_map:
simi=im_hash_map[image]-im_hash_map[im]
# 哈希值差值小于20时,定义为相似
if simi < 15:
heappush(simi_images,(simi,image))
plt.figure()
plt.subplot(4,3,2)
im=Image.open(im)
plt.imshow(im)
plt.axis('off')
for i in range(4,13):
try:
image=heappop(simi_images)
im=Image.open(image[1])
plt.subplot(4,3,i)
plt.imshow(im)
plt.axis('off')
except:
plt.show()
print("no more similar photos")
plt.show()
else:
print('图片不存在')
- 主函数
def main():
imflist = load_images()
im_hash_map = hash_image(imflist)
im = 1
while im != 'q':
im = input('输入q退出,或输入图片路径:')
if im != 'q':
simi_image(im_hash_map, im)
else:
break
if __name__ == '__main__':
main()

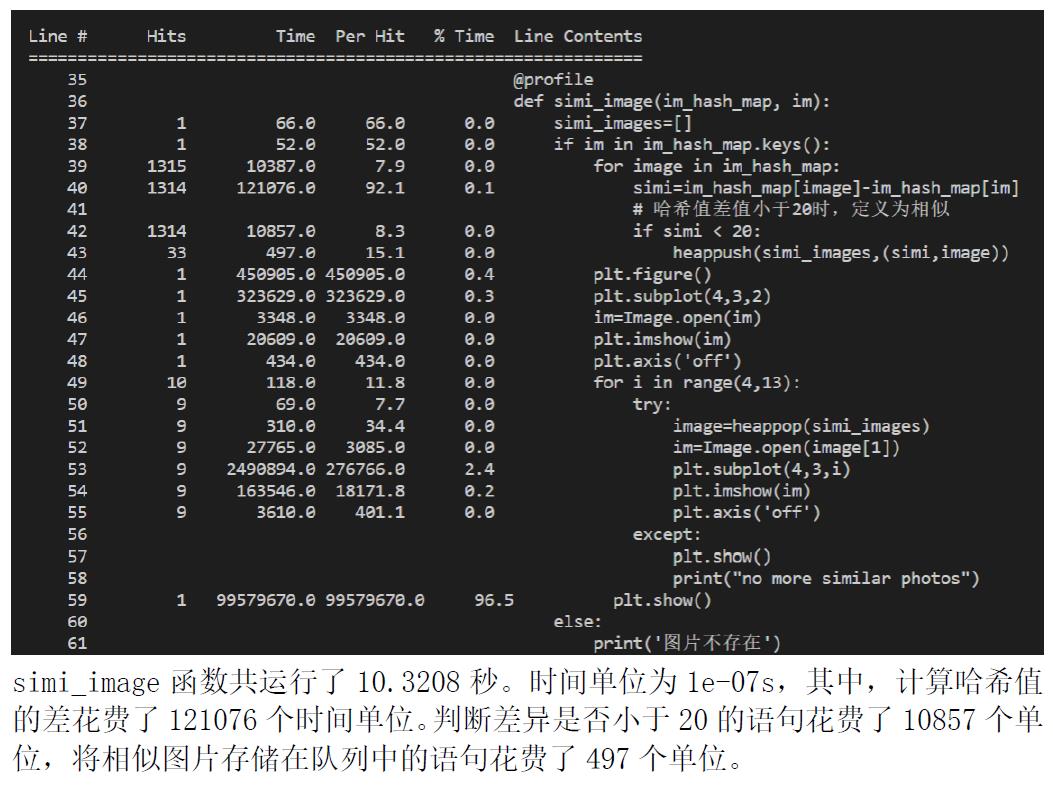

当阈值为15 时,只有 5 张图片满足相似。 计算哈希值差异的语句花费了 121422个时间单位。该函数共运行了 9.2934 秒
以上是关于哈希图像相似性识别的主要内容,如果未能解决你的问题,请参考以下文章