深入理解Android跨进程通信-Binder机制
Posted 涂程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解Android跨进程通信-Binder机制相关的知识,希望对你有一定的参考价值。
说到binder,很多android开发者会觉得很复杂,因为binder横跨了整个Android系统架构,从framework到kernel,binder无处不在。在日常的面试过程中,binder也是一个绕不开的话题。为啥binder这么重要,跨进程通信方式已经有了管道、socket、共享内存等,为啥Android还要使用binder。今天,我们带着这些问题深入了解下Binder机制。
引子
日常应用
我们平时开发中,可能一些代码反复写了N多次了,所以写起来很流畅,但我们不会注意这些流程。例如:
ActivityA 启动 ActivityB 的过程中,我们通过intent,传递数据,搞定。两个activity可以相互通信了,想过没有,为什么使用intent序列化之后才能传递数据?这里面就涉及到binder,因为AMS和app是两个进程。
我们现在很多大型app都是多进程,而多进程相互之间要通信,就需要binder。一些小企业基本用不到多进程app,而大厂就会涉及到了,例如:微信,微博等 他们都是多进程开发的。多进程有什么好处呢?
首先,系统会给每个app进程分配一个jvm,而这个jvm的大小是系统给定的,当我们一个app的使用内存变大后,内存不够用,就会出现崩溃,而我们使用多进程时,就会给app开辟更多的内存。
其次,多进程开发实现了进程隔离,当一个子进程crash掉后,不会影响主进程。
最后,多进程开发使得进程保活几率提升,一个进程被杀后,其他进程会相互拉。
Binder的优势
linux自带了很多IPC跨进程通信方式(管道,信号量,socket,共享内存),Android为啥还要搞一个binder出来?自然时binder的性能要优于其他方式。
binder只需要拷贝一次。
在性能方面,共享内存 > Binder > socket
在安全方面,Binder 是最安全的,他会给每个app都分配单独的UID,并支持实名和匿名。Socket用的PID,不靠谱。
Binder拷贝一次的流程
整个Linux系统分为用户空间和内核空间 用户空间的资源是独立的 内核空间的资源是共享的。

可以看到,binder通过mmap技术,将内核空间的虚拟地址和server端的虚拟地址映射到同一块物理内存上,而这块物理内存的大小是由server端决定的。
mmap
Linux通过将一个虚拟内存区域与磁盘上的对象关联起来,以初始化 这个虚拟内存区域的内容,这个过程称为内存映射(memory mapping)。
对文件进行mmap,会在进程的虚拟内存分配地址空间,创建映射关系。 实现这样的映射关系后,就可以采用指针的方式读写操作这一段内存,而系统会自动回写到对应的文件磁盘上
Binder框架
要想搞明白binder的底层实现,必须搞懂整个binder框架。
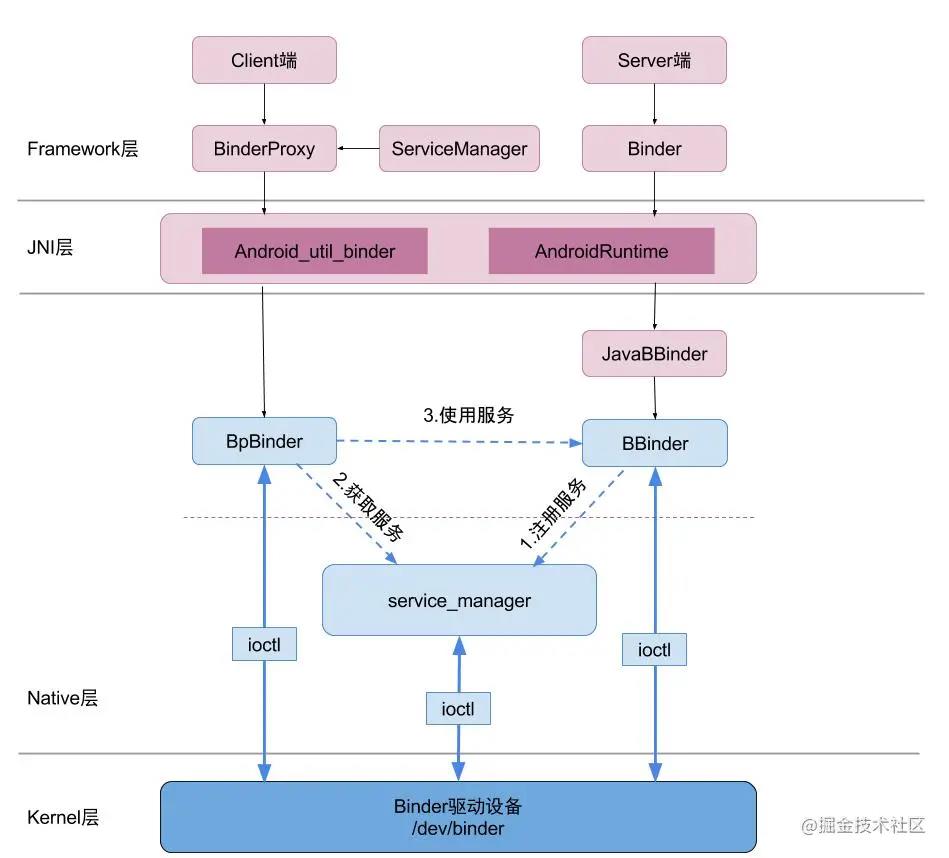
这张图就是整个binder的框架结构,从framework到kernel,经历了jni和native的跨越。
接下来我们从下往上依次分析binder的整个过程。
binder源码解析
Kernel层
我们先看下binder驱动的流程图:
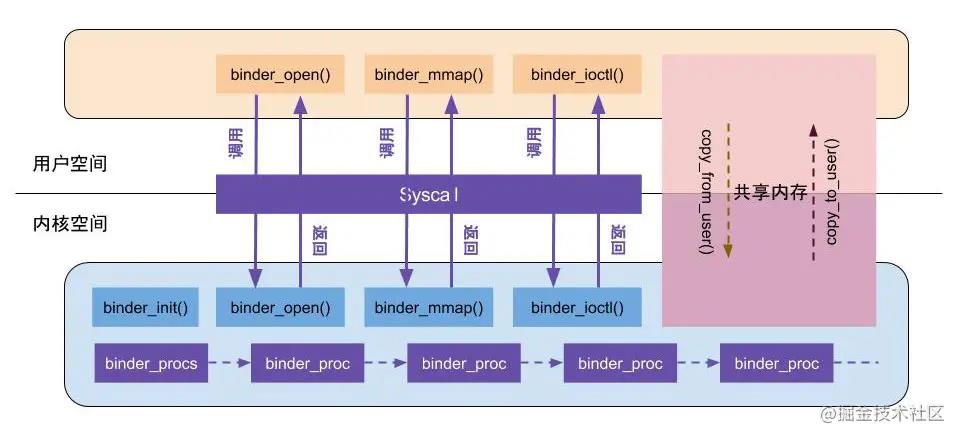
从上图可以看到binder驱动最重要的四个方法:binder_init()、binder_open()、binder_mmap()、binder_ioctl(). 接下来我们依次分析这四个方法,看他们做了哪些事情。
1. binder_init()
static int __init binder_init(void)
{
int ret;
char *device_name, *device_names;
struct binder_device *device;
struct hlist_node *tmp;
// 首先创建名字为“binder”的单线程工作队列。
binder_deferred_workqueue = create_singlethread_workqueue("binder");
if (!binder_deferred_workqueue)
return -ENOMEM;
...
/*
* Copy the module_parameter string, because we don't want to
* tokenize it in-place.
*/
device_names = kzalloc(strlen(binder_devices_param) + 1, GFP_KERNEL);
if (!device_names) {
ret = -ENOMEM;
goto err_alloc_device_names_failed;
}
strcpy(device_names, binder_devices_param);
while ((device_name = strsep(&device_names, ","))) {
ret = init_binder_device(device_name);
if (ret)
goto err_init_binder_device_failed;
}
return ret;
err_init_binder_device_failed:
hlist_for_each_entry_safe(device, tmp, &binder_devices, hlist) {
misc_deregister(&device->miscdev);
hlist_del(&device->hlist);
kfree(device);
}
err_alloc_device_names_failed:
debugfs_remove_recursive(binder_debugfs_dir_entry_root);
destroy_workqueue(binder_deferred_workqueue);
return ret;
}
static int __init init_binder_device(const char *name)
{
int ret;
struct binder_device *binder_device;
//分配内存
binder_device = kzalloc(sizeof(*binder_device), GFP_KERNEL);
if (!binder_device)
return -ENOMEM;
// 初始化binder设备
binder_device->miscdev.fops = &binder_fops;
binder_device->miscdev.minor = MISC_DYNAMIC_MINOR;
binder_device->miscdev.name = name;
binder_device->context.binder_context_mgr_uid = INVALID_UID;
binder_device->context.name = name;
ret = misc_register(&binder_device->miscdev);
if (ret < 0) {
kfree(binder_device);
return ret;
}
hlist_add_head(&binder_device->hlist, &binder_devices);
return ret;
}
-
为binder设备分配内存。
-
初始化设备
-
将binder设备加入binder_devices链表
2. binder_open()
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
struct binder_device *binder_dev;
binder_debug(BINDER_DEBUG_OPEN_CLOSE, "binder_open: %d:%d\\n",
current->group_leader->pid, current->pid);
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL)
return -ENOMEM;
get_task_struct(current);
proc->tsk = current;
INIT_LIST_HEAD(&proc->todo);
init_waitqueue_head(&proc->wait);
proc->default_priority = task_nice(current);
binder_dev = container_of(filp->private_data, struct binder_device,
miscdev);
proc->context = &binder_dev->context;
binder_lock(__func__);
binder_stats_created(BINDER_STAT_PROC);
hlist_add_head(&proc->proc_node, &binder_procs);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
filp->private_data = proc;
binder_unlock(__func__);
if (binder_debugfs_dir_entry_proc) {
char strbuf[11];
snprintf(strbuf, sizeof(strbuf), "%u", proc->pid);
/*
* proc debug entries are shared between contexts, so
* this will fail if the process tries to open the driver
* again with a different context. The priting code will
* anyway print all contexts that a given PID has, so this
* is not a problem.
*/
proc->debugfs_entry = debugfs_create_file(strbuf, S_IRUGO,
binder_debugfs_dir_entry_proc,
(void *)(unsigned long)proc->pid,
&binder_proc_fops);
}
return 0;
}
-
初始化binder_proc对象,binder_proc这个结构体就是用来保存binder进程的信息。
-
将当前进程信息保存在proc里
-
filp->private_data = proc;
-
添加到binder_procs链表中
3. binder_mmap()
static int binder_mmap(struct file *filp, struct vm_area_struct *vma) /* 进程的虚拟内存 */
{
int ret;
struct vm_struct *area; /* 内核的虚拟内存 */
struct binder_proc *proc = filp->private_data;
const char *failure_string;
struct binder_buffer *buffer;
if (proc->tsk != current)
return -EINVAL;
// 大小不能超过4M 4M----驱动给定的
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
binder_debug(BINDER_DEBUG_OPEN_CLOSE,
"binder_mmap: %d %lx-%lx (%ld K) vma %lx pagep %lx\\n",
proc->pid, vma->vm_start, vma->vm_end,
(vma->vm_end - vma->vm_start) / SZ_1K, vma->vm_flags,
(unsigned long)pgprot_val(vma->vm_page_prot));
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) {
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
}
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
mutex_lock(&binder_mmap_lock);
if (proc->buffer) {
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
proc->buffer = area->addr;
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
#ifdef CONFIG_CPU_CACHE_VIPT
if (cache_is_vipt_aliasing()) {
while (CACHE_COLOUR((vma->vm_start ^ (uint32_t)proc->buffer))) {
pr_info("binder_mmap: %d %lx-%lx maps %p bad alignment\\n", proc->pid, vma->vm_start, vma->vm_end, proc->buffer);
vma->vm_start += PAGE_SIZE;
}
}
#endif
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
binder_insert_free_buffer(proc, buffer);
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
/*pr_info("binder_mmap: %d %lx-%lx maps %p\\n",
proc->pid, vma->vm_start, vma->vm_end, proc->buffer);*/
return 0;
err_alloc_small_buf_failed:
kfree(proc->pages);
proc->pages = NULL;
err_alloc_pages_failed:
mutex_lock(&binder_mmap_lock);
vfree(proc->buffer);
proc->buffer = NULL;
err_get_vm_area_failed:
err_already_mapped:
mutex_unlock(&binder_mmap_lock);
err_bad_arg:
pr_err("binder_mmap: %d %lx-%lx %s failed %d\\n",
proc->pid, vma->vm_start, vma->vm_end, failure_string, ret);
return ret;
}
-
通过用户空间的虚拟内存大小,分配一块内核的虚拟内存
-
分配一块物理内存 ------4KB
-
把这块物理内存分别映射到用户空间的虚拟内存 和 内核的虚拟内存
4. binder_ioctl()
读写操作 BINDER_WRITE_READ
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
/*pr_info("binder_ioctl: %d:%d %x %lx\\n",
proc->pid, current->pid, cmd, arg);*/
trace_binder_ioctl(cmd, arg);
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret)
goto err_unlocked;
binder_lock(__func__);
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
switch (cmd) {
case BINDER_WRITE_READ:
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
case BINDER_SET_MAX_THREADS:
if (copy_from_user(&proc->max_threads, ubuf, sizeof(proc->max_threads))) {
ret = -EINVAL;
goto err;
}
break;
case BINDER_SET_CONTEXT_MGR:
ret = binder_ioctl_set_ctx_mgr(filp);
if (ret)
goto err;
break;
case BINDER_THREAD_EXIT:
binder_debug(BINDER_DEBUG_THREADS, "%d:%d exit\\n",
proc->pid, thread->pid);
binder_free_thread(proc, thread);
thread = NULL;
break;
case BINDER_VERSION: {
struct binder_version __user *ver = ubuf;
if (size != sizeof(struct binder_version)) {
ret = -EINVAL;
goto err;
}
if (put_user(BINDER_CURRENT_PROTOCOL_VERSION,
&ver->protocol_version)) {
ret = -EINVAL;
goto err;
}
break;
}
default:
ret = -EINVAL;
goto err;
}
ret = 0;
err:
if (thread)
thread->looper &= ~BINDER_LOOPER_STATE_NEED_RETURN;
binder_unlock(__func__);
wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret && ret != -ERESTARTSYS)
pr_info("%d:%d ioctl %x %lx returned %d\\n", proc->pid, current->pid, cmd, arg, ret);
err_unlocked:
trace_binder_ioctl_done(ret);
return ret;
}
-
进入休眠,直到中断唤醒
-
根据当前进程的pid, 从binder_proc中查找binder_thread,如果当前线程已经加入到proc的线程队列,则直接返回;如果不存在binder_thread,则创建binder_thread,并将其添加到当前的proc。
-
进行binder的读写操作
-
首先将用户空间数据ubuf拷贝到bwr中。
-
当写缓存中有数据,则执行binder写操作
-
当读缓存中有数据,则执行binder读操作
-
进程todo队列不为空,则唤醒该队列中的线程
-
把内核空间数据bwr拷贝到ubuf
-
JNI层
我们知道,native层的binder要想和framework层通信,首先得通过jni注册,这个注册在zygote进程启动时,通过app_main.cpp中的main方法。
frameworks/base/cmds/app_process/app_main.cpp
// 186
int main(int argc, char* const argv[])
// 248 将zygote标志位置为true。
if (strcmp(arg, "--zygote") == 0) {
zygote = true;
}
// 306 运行AndroidRuntime.cpp的start方法
if (zygote) {
runtime.start("com.android.internal.os.ZygoteInit", args, zygote);
}
然后调用startReg方法来完成jni方法的注册。
static int register_jni_procs(const RegJNIRec array[], size_t count, JNIEnv* env)
{
//循环注册jni方法
for (size_t i = 0; i < count; i++) {
if (array[i].mProc(env) < 0) {
#ifndef NDEBUG
ALOGD("----------!!! %s failed to load\\n", array[i].mName);
#endif
return -1;
}
}
return 0;
}
static const RegJNIRec gRegJNI[] = {
...
REG_JNI(register_android_os_Binder),
...
};
可以看到,register_android_os_Binder 这个是binder的jni方法,我们进入看下:
代码路径在:frameworks/base/core/jni/android_util_Binder.cpp
int register_android_os_Binder(JNIEnv* env)
{
if (int_register_android_os_Binder(env) < 0)
return -1;
if (int_register_android_os_BinderInternal(env) < 0)
return -1;
if (int_register_android_os_BinderProxy(env) < 0)
return -1;
jclass clazz = FindClassOrDie(env, "android/util/Log");
gLogOffsets.mClass = MakeGlobalRefOrDie(env, clazz);
gLogOffsets.mLogE = GetStaticMethodIDOrDie(env, clazz, "e",
"(Ljava/lang/String;Ljava/lang/String;Ljava/lang/Throwable;)I");
clazz = FindClassOrDie(env, "android/os/ParcelFileDescriptor");
gParcelFileDescriptorOffsets.mClass = MakeGlobalRefOrDie(env, clazz);
gParcelFileDescriptorOffsets.mConstructor = GetMethodIDOrDie(env, clazz, "<init>",
"(Ljava/io/FileDescriptor;)V");
clazz = FindClassOrDie(env, "android/os/StrictMode");
gStrictModeCallbackOffsets.mClass = MakeGlobalRefOrDie(env, clazz);
gStrictModeCallbackOffsets.mCallback = GetStaticMethodIDOrDie(env, clazz,
"onBinderStrictModePolicyChange", "(I)V");
return 0;
}
这里分为三个阶段:
1.int_register_android_os_Binder
const char* const kBinderPathName = "android/os/Binder";
static int int_register_android_os_Binder(JNIEnv* env)
{
jclass clazz = FindClassOrDie(env, kBinderPathName);
gBinderOffsets.mClass = MakeGlobalRefOrDie(env, clazz);
gBinderOffsets.mExecTransact = GetMethodIDOrDie(env, clazz, "execTransact", "(IJJI)Z");
gBinderOffsets.mObject = GetFieldIDOrDie(env, clazz, "mObject", "J");
return RegisterMethodsOrDie(
env, kBinderPathName,
gBinderMethods, NELEM(gBinderMethods));
}
-
通过kBinderPathName查找文件,此时的文件是:“android/os/Binder”,返回class对象。
-
通过gBinderOffsets结构体,保存Java层Binder类的信息,为JNI层访问Java层提供通道。
-
通过RegisterMethodsOrDie,将为gBinderMethods数组完成映射关系,从而为Java层访问JNI层提供通道。
2.int_register_android_os_BinderInternal
const char* const kBinderInternalPathName = "com/android/internal/os/BinderInternal";
static int int_register_android_os_BinderInternal(JNIEnv* env)
{
jclass clazz = FindClassOrDie(env, kBinderInternalPathName);
gBinderInternalOffsets.mClass = MakeGlobalRefOrDie(env, clazz);
gBinderInternalOffsets.mForceGc = GetStaticMethodIDOrDie(env, clazz, "forceBinderGc", "()V");
return RegisterMethodsOrDie(
env, kBinderInternalPathName,
gBinderInternalMethods, NELEM(gBinderInternalMethods));
}
-
通过kBinderInternalPathName查找文件,返回class对象
-
通过gBinderInternalOffsets结构体,保存java层binder类的信息,为JNI层访问Java层提供通道
-
通过RegisterMethodsOrDie,为gBinderInternalMethods数组完成映射关系,从而为Java层访问JNI层提供通道
3. int_register_android_os_BinderProxy
const char* const kBinderProxyPathName = "android/os/BinderProxy";
static int int_register_android_os_BinderProxy(JNIEnv* env)
{
jclass clazz = FindClassOrDie(env, "java/lang/Error");
gErrorOffsets.mClass = MakeGlobalRefOrDie(env, clazz);
clazz = FindClassOrDie(env, kBinderProxyPathName);
gBinderProxyOffsets.mClass = MakeGlobalRefOrDie(env, clazz);
gBinderProxyOffsets.mConstructor = GetMethodIDOrDie(env, clazz, "<init>", "()V");
gBinderProxyOffsets.mSendDeathNotice = GetStaticMethodIDOrDie(env, clazz, "sendDeathNotice",
"(Landroid/os/IBinder$DeathRecipient;)V");
gBinderProxyOffsets.mObject = GetFieldIDOrDie(env, clazz, "mObject", "J");
gBinderProxyOffsets.mSelf = GetFieldIDOrDie(env, clazz, "mSelf",
"Ljava/lang/ref/WeakReference;");
gBinderProxyOffsets.mOrgue = GetFieldIDOrDie(env, clazz, "mOrgue", "J");
clazz = FindClassOrDie(env, "java/lang/Class");
gClassOffsets.mGetName = GetMethodIDOrDie(env, clazz, "getName", "()Ljava/lang/String;");
return RegisterMethodsOrDie(
env, kBinderProxyPathName,
gBinderProxyMethods, NELEM(gBinderProxyMethods));
}
-
通过kBinderProxyPathName查找文件,返回class对象
-
通过gBinderProxyOffsets结构体,保存Java层binder类的信息,为JNI层访问java层提供通道。
-
通过RegisterMethodsOrDie,为gBinderProxyMethods数组完成映射关系,从而为java层访问JNI层提供通道
Native层
ServiceManager服务的注册
service_manager就是一个大管家,负责管理各种服务,包括系统服务(AMS、PMS等)。service_manage的handle = 0。启动servicemanager通过解析init.rc,进入service_manager.c的main方法
int main(int argc, char **argv)
{
struct binder_state *bs;
// 打开binder驱动,申请128KB字节大小的内存空间,进行内存映射
bs = binder_open(128*1024);
if (!bs) {
ALOGE("failed to open binder driver\\n");
return -1;
}
// 设置servicemanager为binder大管家
if (binder_become_context_manager(bs)) {
ALOGE("cannot become context manager (%s)\\n", strerror(errno));
return -1;
}
...
// 进行无限循环,处理client发来的请求
binder_loop(bs, svcmgr_handler);
return 0;
}
上面的main方法 我们可以看到,SM的注册主要分为三个步骤:
-
打开驱动 内存映射,设置内存大小为128kb (ServiceManager服务的大小)
-
设置servicemanager为大管家
-
开启监听 不断轮询
首先,先看下他是如何将servicemanager设置为大管家的。进入代码:
int binder_become_context_manager(struct binder_state *bs)
{
return ioctl(bs->fd, BINDER_SET_CONTEXT_MGR, 0);
}
static int binder_ioctl_set_ctx_mgr(struct file *filp)
{
...
// 创建SM实体 node
context->binder_context_mgr_node = binder_new_node(proc, 0, 0);
...
return ret;
}
static struct binder_node *binder_new_node(struct binder_proc *proc,
binder_uintptr_t ptr,
binder_uintptr_t cookie)
{
struct rb_node **p = &proc->nodes.rb_node;
struct rb_node *parent = NULL;
struct binder_node *node;
while (*p) {
parent = *p;
node = rb_entry(parent, struct binder_node, rb_node);
if (ptr < node->ptr)
p = &(*p)->rb_left;
else if (ptr > node->ptr)
p = &(*p)->rb_right;
else
return NULL;
}
// 申请内存 创建node对象
node = kzalloc(sizeof(*node), GFP_KERNEL);
if (node == NULL)
return NULL;
binder_stats_created(BINDER_STAT_NODE);
rb_link_node(&node->rb_node, parent, p);
rb_insert_color(&node->rb_node, &proc->nodes);
node->debug_id = ++binder_last_id;
node->proc = proc;
node->ptr = ptr;
node->cookie = cookie;
node->work.type = BINDER_WORK_NODE;
INIT_LIST_HEAD(&node->work.entry);
INIT_LIST_HEAD(&node->async_todo);
binder_debug(BINDER_DEBUG_INTERNAL_REFS,
"%d:%d node %d u%016llx c%016llx created\\n",
proc->pid, current->pid, node->debug_id,
(u64)node->ptr, (u64)node->cookie);
return node;
}
-
创建binder_node结构体对象
-
proc -> binder_node
-
创建 work 和 todo ====》类似 messageQueue
其次,看SM如何进入loop等待状态:这里很关键的一个命令:BC_ENTER_LOOPE命令
void binder_loop(struct binder_state *bs, binder_handler func)
{
int res;
struct binder_write_read bwr;
uint32_t readbuf[32];
// 1.将bwr结构体初始化为0
bwr.write_size = 0;
bwr.write_consumed = 0;
bwr.write_buffer = 0;
readbuf[0] = BC_ENTER_LOOPER;
// 2.设置线程的状态为loop状态
binder_write(bs, readbuf, sizeof(uint32_t));
for (;;) {
// 3. read_size 不为0, 进入binder_thread_read
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
/* 不断地 binder读数据,没有数据会进入休眠状态 */
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
ALOGE("binder_loop: ioctl failed (%s)\\n", strerror(errno));
break;
}
res = binder_parse(bs, 0, (uintptr_t) readbuf, bwr.read_consumed, func);
if (res == 0) {
ALOGE("binder_loop: unexpected reply?!\\n");
break;
}
if (res < 0) {
ALOGE("binder_loop: io error %d %s\\n", res, strerror(errno));
break;
}
}
}
void binder_loop(struct binder_state *bs, binder_handler func)
{
int res;
struct binder_write_read bwr;
uint32_t readbuf[32];
// 1.将bwr结构体初始化为0
bwr.write_size = 0;
bwr.write_consumed = 0;
bwr.write_buffer = 0;
readbuf[0] = BC_ENTER_LOOPER;
// 2.设置线程的状态为loop状态
binder_write(bs, readbuf, sizeof(uint32_t));
for (;;) {
// 3. read_size 不为0, 进入binder_thread_read
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
/* 不断地 binder读数据,没有数据会进入休眠状态 */
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
ALOGE("binder_loop: ioctl failed (%s)\\n", strerror(errno));
break;
}
res = binder_parse(bs, 0, (uintptr_t) readbuf, bwr.read_consumed, func);
if (res == 0) {
ALOGE("binder_loop: unexpected reply?!\\n");
break;
}
if (res < 0) {
ALOGE("binder_loop: io error %d %s\\n", res, strerror(errno));
break;
}
}
}
- 进入kernel层的binder.c, 通过BINDER_WRITE_READ命令,调用
binder_ioctl_write_read函数, 前面我们判断了write_buffer是有值的,所以执行binder_thread_write。
在binder_thread_write里
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
struct binder_context *context = proc->context;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error == BR_OK) {
/* 获取命令,即 BC_ENTER_LOOPER */
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
...
switch (cmd) {
...
case BC_ENTER_LOOPER:
binder_debug(BINDER_DEBUG_THREADS,
"%d:%d BC_ENTER_LOOPER\\n",
proc->pid, thread->pid);
if (thread->looper & BINDER_LOOPER_STATE_REGISTERED) {
thread->looper |= BINDER_LOOPER_STATE_INVALID;
binder_user_error("%d:%d ERROR: BC_ENTER_LOOPER called after BC_REGISTER_LOOPER\\n",
proc->pid, thread->pid);
}
/* 设置线程loop状态为循环状态 */
thread->looper |= BINDER_LOOPER_STATE_ENTERED;
break;
...
}
}
- 此时,第一步已经完成,就是写入了线程的loop状态,再回到binder_loop函数中,进入for循环,将read_size赋值了,read_size 不为0, 进入binder_thread_read,再看这个函数
static int binder_thread_read(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed, int non_block)
{
...
if (*consumed == 0) {
/* 设置命令为BR_NOOP */
if (put_user(BR_NOOP, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
}
retry:
/* wait_for_proc_work为true */
wait_for_proc_work = thread->transaction_stack == NULL &&
list_empty(&thread->todo);
...
/* 准备就绪的线程数 + 1 */
if (wait_for_proc_work)
proc->ready_threads++;
...
if (non_block) { /* 非阻塞操作,servicemanager是阻塞的,所以进入else */
if (!binder_has_proc_work(proc, thread))
ret = -EAGAIN;
} else
ret = wait_event_freezable_exclusive(proc->wait, binder_has_proc_work(proc, thread));
}
总结大致做了以下工作:
-
写入状态Loop
-
去读数据:binder_thread_read:ret = wait_event_freezable_exclusive(proc->wait, binder_has_proc_work(proc, thread)); 进入等待
此时,servicemanager已经注册完成,准备就绪了。
整体流程图如下:

ServiceManager服务的获取
获取ServiceManager是通过defaultServiceManager()方法来完成的。
sp<IServiceManager> defaultServiceManager()
{
/* 单例模式,如果不为空,直接返回 */
if (gDefaultServiceManager != NULL) return gDefaultServiceManager;
{
AutoMutex _l(gDefaultServiceManagerLock);
while (gDefaultServiceManager == NULL) {
/* 这里分三步走 */
gDefaultServiceManager = interface_cast<IServiceManager>(
ProcessState::self()->getContextObject(NULL));
if (gDefaultServiceManager == NULL)
sleep(1);
}
}
return gDefaultServiceManager;
}
1. ProcessState::self()
sp<ProcessState> ProcessState::self()
{
Mutex::Autolock _l(gProcessMutex);
/* 单例模式 */
if (gProcess != NULL) {
return gProcess;
}
gProcess = new ProcessState;
return gProcess;
}
这一步很简单,就是实例化ProcessState对象。
: mDriverFD(open_driver())
, mVMStart(MAP_FAILED)
, mThreadCountLock(PTHREAD_MUTEX_INITIALIZER)
, mThreadCountDecrement(PTHREAD_COND_INITIALIZER)
, mExecutingThreadsCount(0)
, mMaxThreads(DEFAULT_MAX_BINDER_THREADS)
, mManagesContexts(false)
, mBinderContextCheckFunc(NULL)
, mBinderContextUserData(NULL)
, mThreadPoolStarted(false)
, mThreadPoolSeq(1)
{
if (mDriverFD >=以上是关于深入理解Android跨进程通信-Binder机制的主要内容,如果未能解决你的问题,请参考以下文章