数据导出/迁移(Sqoop技术)
Posted 阳哥赚钱很牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据导出/迁移(Sqoop技术)相关的知识,希望对你有一定的参考价值。
数据导出/迁移的概念
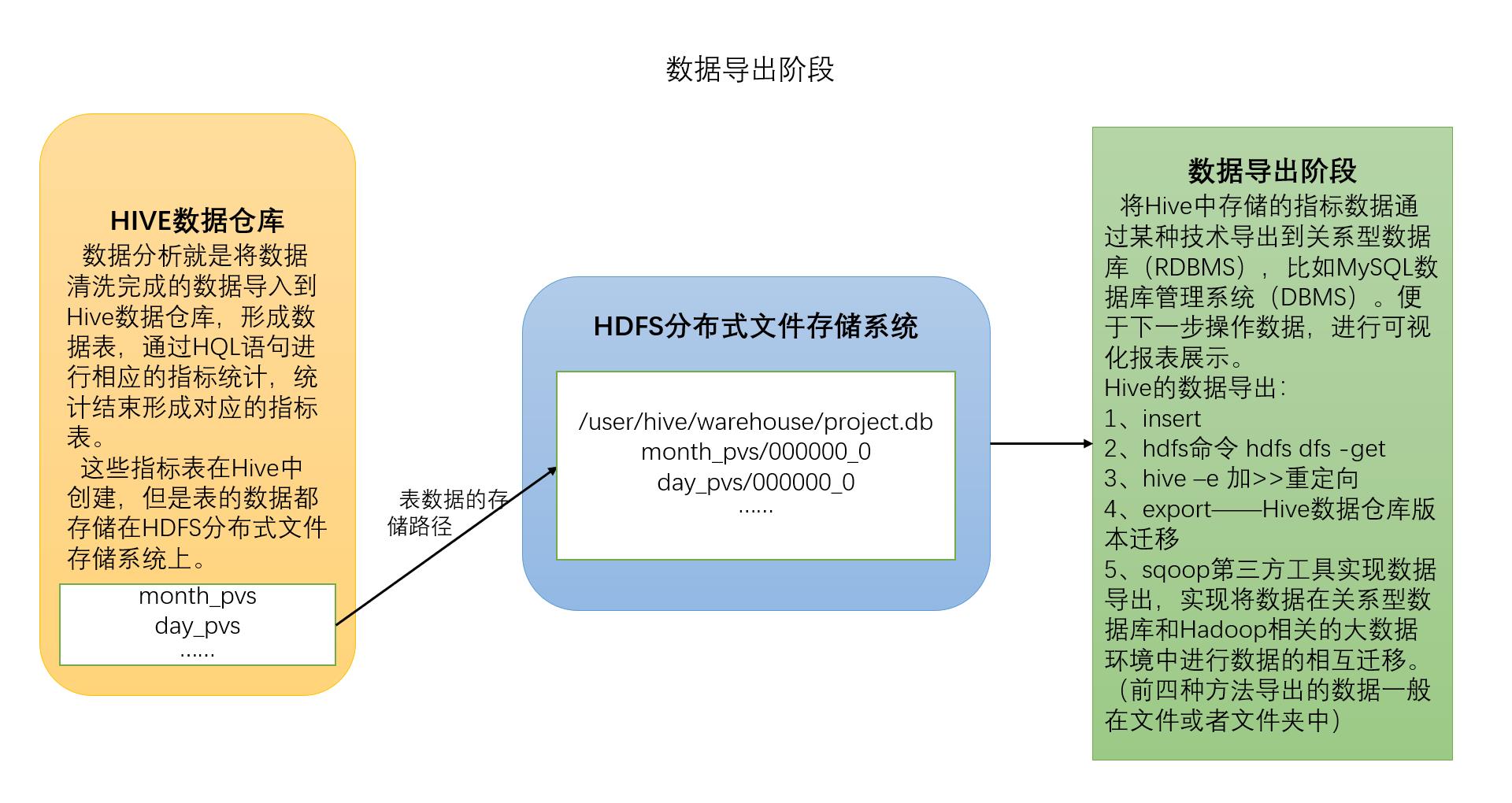
在做数据导出之前,我们看一下已经完成的操作:数据分析阶段将指标统计完成,也将统计完成的指标放到Hive数据表中,并且指标数据存储到HDFS分布式文件存储系统。
指标统计完成之后,我们最终是想将我们的指标数据做成可视化大屏进行展示,Hive中的数据无法、很难直接连接到JavaWeb或者EE技术直接进行数据展示。 因此我们需要将Hive中统计出来的数据指标表迁移到我们的mysql数据库中,由MySQL数据库连接web技术进行可视化展示。
Hive数仓指标表的数据都存储在HDFS分布式文件存储系统,如果想要将Hive的数据导出,有以下几种导出方式:
(1)使用insert命令导出数据到一个目录
(2)HDFS的相关命令:hdfs dfs -get/-move/-copyToLocalFile,将Hive数仓的数据导出到本地的文件中
(3)hive -e 和重定向 >> 命令将数据导出到一个文件中
(4)使用hive自带的export命令导出数据到一个文件夹中(主要做数据仓库的迁移 )
(5)第三方软件技术sqoop技术实现数据迁移,实现将Hive数仓中的数据迁移到MySQL中
数据迁移技术SQOOP
一、SQOOP技术的相关概念
(1) sqoop技术也是apache的顶尖项目,主要是做数据迁移的。
(2)sqoop是将数据在Hadoop和关系型数据库之间的数据传递,基于MapReduce完成。核心是对MR程序的InputFormat和OutputFormat进行定制。
(3)sqoop也是使用命令进行数据的导入和导出的,只不过底层也是会翻译成为MR程序执行。
二、sqoop中两个核心概念
导入:将关系型数据库表数据(比如MySQL)中表数据导入到大数据集群(比如Hive、HBase、HDFS)
导出:将大数据集群的数据(Hive、HBase、HDFS数据)导出到非大数据集群的关系型数据库,比如MySQL
三、SQOOP的安装
sqoop软件是基于Java和Hadoop的,所以必须先把Java和Hadoop软件配置好。
1、首先下载上传解压sqoop、再配置sqoop的相关配置文件。
配置的sqoop配置文件是sqoop-env.sh,重点需要配置Hadoop的相关依赖环境:
export HADOOP_COMMON_HOME=/opt/module/hadoop-2.8.5
export HADOOP_MAPRED_HOME=/opt/module/hadoop-2.8.5
export HIVE_HOME=/opt/module/hive-2.3.8
sqoop可以实现将Hive、HBase中表数据导出到MySQL数据库中,需要sqoop具备连接MySQL的条件——mysql-connector-java-xxxx.jar(需要把此jar包放在sqoop下)
cp /opt/module/hive-2.3.8/lib/mysql-connector-java-5.1.27.jar /opt/module/sqoop-1.4.7/lib/
2、配置sqoop的环境变量(vim /etc/profile)
四、SQOOP的使用
1、检测sqoop是否安装成功
sqoop help
sqoop version
sqoop可以用来查看某个数据库管理系统中有哪些数据库存在
2、sqoop查看MySQL数据库中有哪些数据库存在
sqoop list-databases --connect jdbc:mysql://localhost:3306 --username root --password root
list-databases代表查看所有数据库,connect代表连接哪个数据库,username代表连接数据库的用户名,password代表连接数据库密码。
这个命令执行成功的前提条件是:你已经将对应数据库的驱动jar包放到了sqoop的lib目录下。
五、sqoop实现将MySQL数据导入到Hive数据仓库
【注意】需要将hive的相关jar包放到sqoop环境下
cp /opt/module/hive-2.3.8/lib/hive-common-2.3.8.jar /opt/module/sqoop-1.4.7/lib/
将MySQL中test数据库下的test表数据导入到Hive数据仓库中。
sqoop import #导入
--connect jdbc:mysql://localhost:3306/test # 连接MySQL的那个数据库
--username root #连接MySQL的用户名
--password root #连接MySQL的密码
--table test # 指定MySQL要向Hive数据仓库导入当前数据下那张数据表的数据
--num-mappers 1 # 将导入任务转成MR程序运行 需要一个Map任务
--hive-import # 将数据导入到hive数仓
--fields-terminated-by "\\t" #指定hive数仓导入完成之后表字段之间分隔符
--hive-overwrite # 表中有数据 覆盖写
--hive-table 数据库名.表名 # 导入到Hive的那个表中 表可以不存在 会自动创建
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root --table test --num-mappers 1 --hive-import --fields-terminated-by "\\t" --hive-overwrite --hive-table 数据库名.表名
将MySQL表中数据导入到Hive数仓的时候,hive数据仓库中表可以不用提前存在,会自动创建。
六、sqoop实现将Hive/HDFS数据导入到MySQL数据表中
sqoop的导入分为:将数据导入到HDFS和将数据导入到Hive数仓,或者其他。每种导入方式不一样。
sqoop的导出只有一种命令,就是将Hive/HDFS数据导出到Mysql中。因为hive存储的表数据也在HDFS上存储着,所以HDFS的导出和Hive的导出命令一致的。
案例:实现项目功能,将age_pvs的数据导出到MySQL数据库中。
将MySQL数据导入到hive表中,hive表可以不用提前存在,但是如果要将Hive数据表的数据导入到MySQL中,那么MySQL中对应的表必须提前存在,并且和hive表结构保持一致。
导出命令:
sqoop export # 导出数据
--connect jdbc:mysql://localhost:3306/project #连接MySQL数据库
--username root #连接用户名
--password 123456 #连接密码
--table staff # 导入到MySQL的那张表中
--num-mappers 1 #转成一个MR任务运行
--export-dir /user/hive/warehouse/staff_hive #hive数据表数据在HDFS上对应的路径
--input-fields-terminated-by "\\t" #hive表字段和字段之间的分隔符
sqoop的另外一种导出方式:
vim一个xxx.opt文件,然后将sqoop导出命令放到文件中。注意:sqoop关键字需要删除、而且参数和参数值需要分行写
使用 sqoop --options-file xxx.opt
sqoop实现数据迁移(导入、导出)主要是将迁移操作转换成为MR程序去运行,在表现形式上,就是将MR程序的InputFormat和OutputFormat进行重写或者自定义。
以上是关于数据导出/迁移(Sqoop技术)的主要内容,如果未能解决你的问题,请参考以下文章