肝了一夜,一文说清BIONIOAIO不同IO模型演进之路
Posted 慕枫技术笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了肝了一夜,一文说清BIONIOAIO不同IO模型演进之路相关的知识,希望对你有一定的参考价值。
引言
Netty作为高性能的网络通信框架,它是IO模型演变过程中的产物。Netty以Java NIO为基础,是一种基于异步事件驱动的网络通信应用框架,Netty用以快速开发高性能、高可靠的网络服务器和客户端程序,很多开源框架都选择Netty作为其网络通信模块。本文主要通过分析IO模型的优化演进之路,比较不同IO模型的异同,让大家对于Java IO模型有着更加深刻的理解,我想这也是Netty如何实现高性能网络通信理解的重要基础。话不多说,我们赶紧发车了。
PS:文末有是彩蛋哦!
IO模型
1、什么是IO
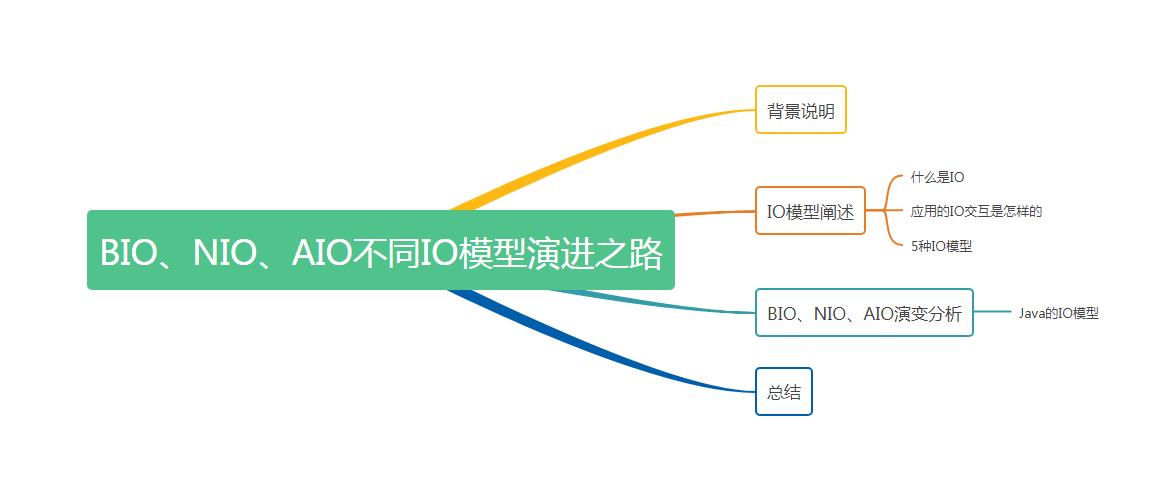
在阐述BIO、NIO、AIO之前,我们先来看下到底什么是IO模型。我们都知道无论是程序还是平台,它们的功能高度抽象之后其实可以描述为这样一个过程,即为通过外部条件以及数据的输入,经过程序或者平台的处理产生了新的输出,IO模型实际上就是描述了计算机世界中的输入和输出过程的模式。
对于计算机来说,其键盘以及鼠标等就是输入设备,显示器以及磁盘等就是输出设备。举个栗子,如果我们在计算机上写一篇设计文档并进行保存,实际就是通过键盘对计算机进行了数据输入,完成设计文档后将其保存输出到了计算机的磁盘上。
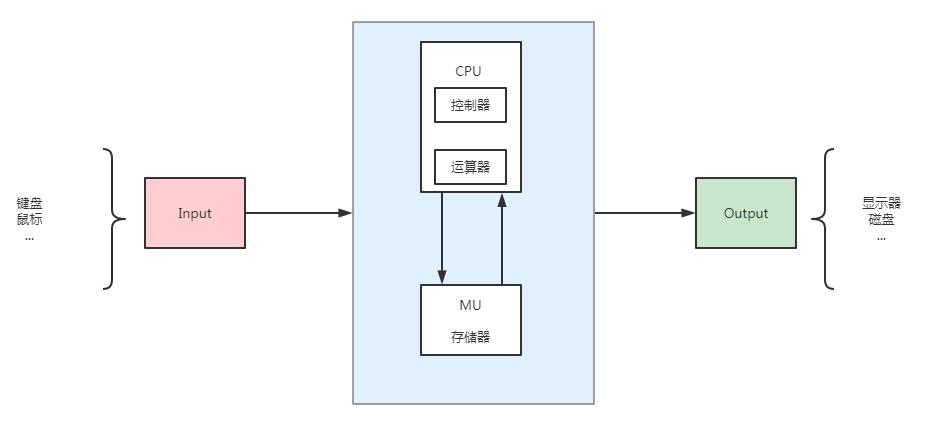
上图中的IO描述,即为著名的计算机冯诺依曼体系,它大致描述了外部设备与计算机的IO交互过程。
2、应用程序IO交互
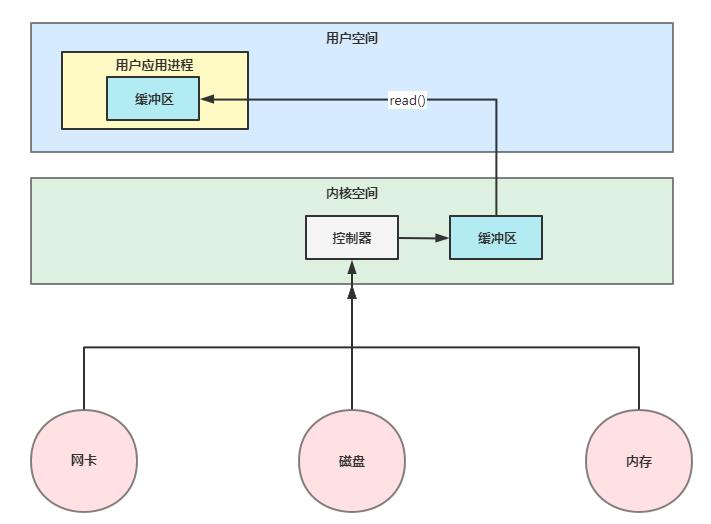
上文中我们介绍了计算机与外部设备交互的大致过程,那么我们的应用程序是如何进行IO交互的呢?我们平时编写的代码不会独立的存在,它总是被部署在linux服务器或者各种容器中,应用程序在服务器或者容器中启动后再对外提供服务。因此网络请求数据首先需要和计算机进行交互,才会被交由到对应的程序去进行后续的业务处理。
在Linux的世界中,文件是用来描述Linux世界的,目录文件、套接字等都是文件。那文件又是什么鬼呢?文件实际就是二进制流,二进制流就是人类世界与计算机世界进行交互的数据媒介。应用从流中读取数据即为read操作,当把流中的数据进行写入的时候就是write操作。但是linux系统又是如何区分不同类型的文件呢?实际是通过文件描述符(File Descriptor)来进行区分,文件描述符其实就是个整数,这个整数实际是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。所以对这个整数的操作、就是对这个文件(流)的操作。
就拿网络连接来说,我们创建一个网络socket,通过系统调用(socket调用)会返回一个文件描述符(某个整数),那么后续对socket的操作就会转化为对这个描述符的操作,主要涉及的操作包括accept调用、read调用以及 write调用。这里所说的各种调用就是程序通过Linux内核与计算机进行交互。那么问题又来了,这个计算机内核又是什么鬼。(PS:关于内核不是本文的重点,这里就简单和大家说明下)
//socket函数
socket(PF_INET6,SOCK_STREAM,IPPROTO_IP)
但是实际上应用程序并不是直接从计算机中的网卡中获取数据,也就是说大家编写的程序并不是直接操作计算机的底层硬件。
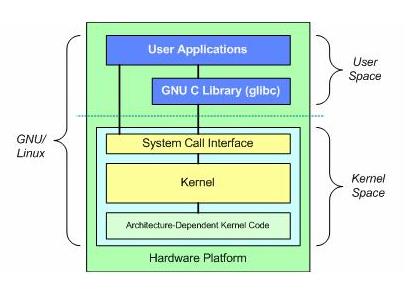
如上图所示,在Linux的结构体系中,用户的应用程序都是通过Linux Kernel内核来操作计算机硬件。那么为什么应用程序不能直接与底层硬件进行交互还需要在中间再加一层内核呢?主要有以下几点考虑。
(1)计算机资源统一管理
Linux内核的作用就是进程调度管理,同时对cpu、内存等系统资源进行统一管理。因此内核管理的都是系统极其敏感的资源,采用内核制是为了实现系统的网络通信,用户管理,文件系统等安全稳定的进程管理,避免用户应用程序破坏系统数据。
(2)底层硬件调用统一封装
试想一下,如果没有内核这层系统进程,那么每个用户应用程序和硬件交互的时候都需要自己实现对应的硬件驱动。这样的设计很难让人接受,按照面向对象的设计思想,硬件的管理统一由Kernel内核负责,Kernel向下管理所有的硬件设备,向上提供给用户进程统一的系统调用,方便应用程序可以像程序调用一样进行系统硬件交互。
3、5种IO模型
(1)阻塞型IO
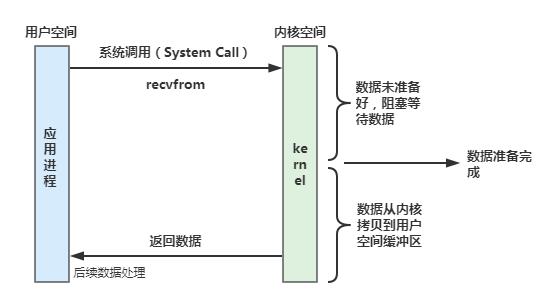
当用户应用进程发起系统调用之后,在内核数据没有准备好的情况下,调用一直处于阻塞状态,直到内核准备好数据后,将数据从内核态拷贝到用户态,用户应用进程获取到数据后,本次调用才算完成。就好比你是外卖小哥,你到商家去取餐,商家的外卖还没有准备好,所以你只能在取餐的地方一直等待着,直到商家将做好的外卖准备好,你才能拿了外卖去送餐。
(2)非阻塞型IO
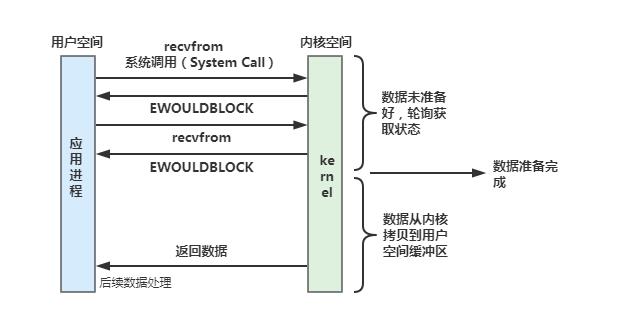
非阻塞IO式基于轮询机制的IO模型,应用进程不断轮询检查内核数据是否准备好,如果没有则返回EWOULDBLOCK,进程继续发起recvfrom调用,此时应用可以去处理其他业务。当内核数据准备好后,将内核数据拷贝至用户空间。这个过程就好比外卖小哥在等待取餐的时候不断问商家外卖做好了没(这个外卖小哥比较着急,送餐时间比较临近了),每隔30s问一次,直到外卖做好送到。
(3)多路复用IO
Linux主要提供了select、poll以及epoll等多路复用I/O的实现方式,为什么会有三个实现呢?实际上他们的出现都是有时间顺序的,后者的出现都是为了解决前者在使用中出现的问题。
在实际场景中,后端服务器接收大量的socket连接,IO多路复用是实际是使用了内核提供的实现函数,在实现函数中有一个参数是文件描述符集合,对这些文件描述符(FD)进行循环监听,当某个文件描述符(FD)就绪时,就对这个文件描述符进行处理。
下面我们分别看下select、poll以及epoll这三个实现函数的实现原理:
select:
select是操作系统的提供的内核系统调用函数,通过它可以将一组FD传给操作系统,操作系统对这组FD进行遍历,当存在FD处于数据就绪状态后,将其全部返回给调用方,这样应用程序就可以对已经就绪的IO流进行处理了。
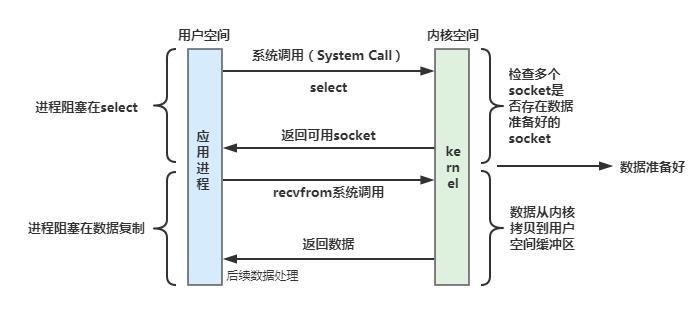
select在使用过程中存在一些问题:
(1)select最多只能监听1024个连接,支持的连接数较少;
(2)select并不会只返回就绪的FD,而是需要用户进程自己一个一个进行遍历找到就绪的FD;
(3)用户进程在调用select时,都需要将FD集合从用户态拷贝到内核态,当FD较多时资源开销相对较大。
poll:
poll机制实际与select机制区别不大,只是poll机制去除掉了监听连接数1024的限制。
epoll:
epoll解决了select以及poll机制的大部分问题,主要体现在以下几个方面:
(1)FD发现的变化:内核不再通过轮询遍历的方式找到就绪的FD,而是通过异步IO事件唤醒的方式,当socket有事件发生时,通过回调函数将就绪的FD加入到就绪事件链表中,从而避免了轮询扫描FD集合;
(2)FD返回的变化:内核将已经就绪的FD返回给用户,用户应用程序不需要自己再遍历找到就绪的FD;
(3)FD拷贝的变化:epoll和内核共享同一块内存,这块内存中保存的就是那些已经可读或者可写的的文件描述符集合,这样就减少了内核和程序的内存拷贝开销。
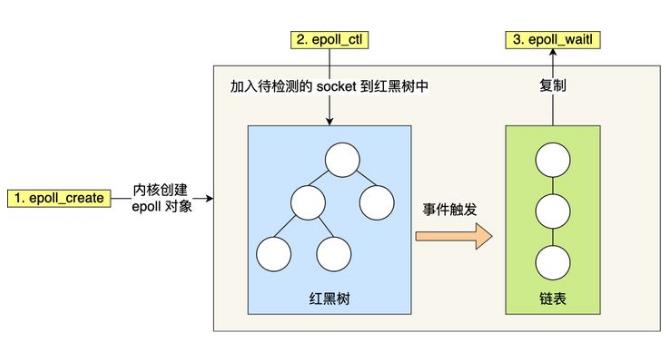
(该图片来自于网络)
(4)信号驱动IO
系统存在一个信号捕捉函数,该信号捕捉函数与socket存在关联关系,在用户进程发起sigaction调用之后,用户进程可以去处理其他的业务流程。当内核将数据准备好之后,用户进程会接收到一个SIGIO信号,然后用户进程中断当前的任务发起recvfrom调用从内核读取数据到用户空间再进行数据处理。
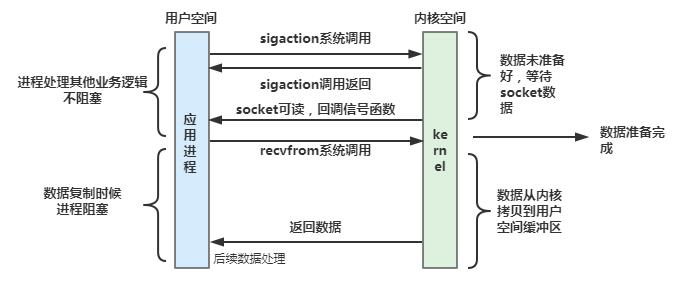
(5)异步IO
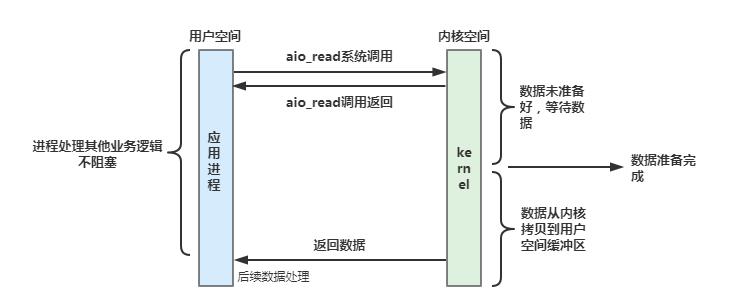
所谓异步IO模型,就是用户进程发起系统调用之后,不管内核对应的请求数据是否准备好,都不会阻塞当前进程,立即返回后进程可以继续处理其他的业务。当内核准备好数据之后,系统会从内核复制数据到用户空间,然后通过信号通知用户进程进行数据读取处理。
Java中的IO模型
上文中我们阐述了Linux本身存在的几种IO模型,那么对应到Java程序世界中,Java也有对应的IO模型,分别是BIO、NIO以及AIO三种IO模型。它们都提供了和IO有关的API,这些API实际也是依赖系统层面的IO完成数据处理的,因此Java的IO模型,实际就是对系统层面IO模型的封装。接下来我们来一起看下Java的这几种IO模型。
BIO
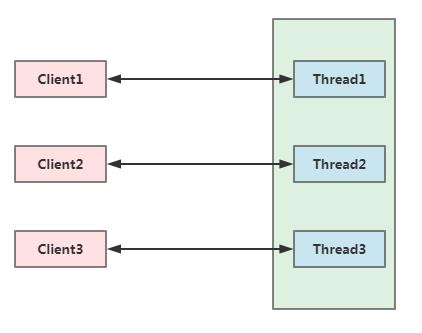
BIO即为Blocking IO,顾名思义就是阻塞型IO模型,当用户进程向服务端发起请求后,一定等到服务端处理完成有数据返回给用户,用户进程才完成一次IO操作,否则就会阻塞住,像个痴心汉傻傻的一直等待数据返回,当数据完成返回后用户线程才会解除block状态,因此在整个数据读取过程中会发生阻塞。
另外从下图我们可以看出来,每一个客户端连接,服务端都有对应的处理线程来处理对应的请求。还是以餐厅吃饭的例子,你到餐厅去吃饭,假如每来一个消费者,餐厅都用一个服务员来接待直到消费者吃饱喝足走出餐厅,那么这个餐厅得配置多少个服务员才合适?这么多服务员,餐厅的老板估计得赔的内裤都没了。
因此在网络连接不多的情况下,BIO还能发回作用。但是当连接数上来后,比如几十万甚至上百万连接,BIO模型的IO交互就显得心有余而力不足了。当连接数不断攀高时,BIO模型的IO交互方式存在以下几种弊端。
(1)频繁创建和销毁大量的线程会消耗系统资源给服务器造成巨大的压力;
(2)另外大量的处理线程会占用过多的JVM内存,你的程序不要干其他事情了,都被大量连接线程给占满了;
(3)实际上线程的上下文切换成本也是很高的。
基于BIO模型在处理大量连接时存在上述的问题,因此我们需要一种更加高效的线程模型来应对几十万甚至上百万的客户端连接。
NIO
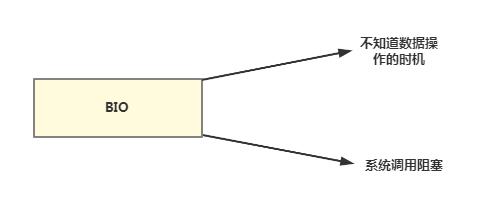
通过上文的分析,由于在BIO模型下,Java中在进行IO操作时候是没办法知道什么时候可以读数据或者什么时候可以写数据,BIO又是一个实在孩子因此没有什么好的办法只能在哪里傻等着。由于socket的读写操作不能进行中断,因此当有新的连接到来时,只能不断创建新的线程来处理,从而导致存在性能问题。
那么如何解决这个问题呢?我们都知道问题的根源就是BIO模型中我们不知道数据的读取与写入的时机,才导致的阻塞等待,那么如果我们能够知道数据读写的时机,是不是就不用傻傻的等着响应,也不用再创建新的线程来处理连接了。
为了提升IO交互效率,避免阻塞傻等的情况发生。Java 1.4中引入了NIO,对于NIO来说,有人称之为Non-blocking IO,但是我更愿意称之为New IO。因为它是一种基于IO多路复用的IO模型,而不是简单的同步非阻塞的IO模型。所谓IO多路复用指的就是用同一个线程处理大量连接,多路指的就是大量连接,复用指的就是使用一个线程来进行处理。
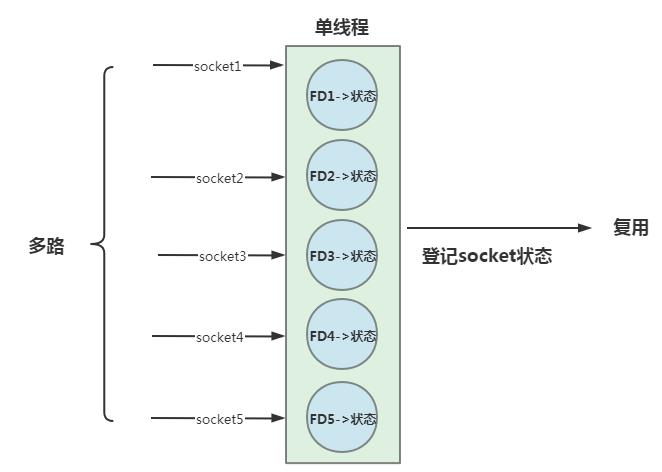
那我们先来看看同步非阻塞模型有什么问题,NIO 的读写以及接受方法在等待数据就绪阶段都是非阻塞的。如上文中的描述,同步非阻塞模式下应用进程不断向内核发起调用,询问内核数据完成准备。相对于同步阻塞模型有了一定的优化,通过不断轮询数据是否准备好,避免了调用阻塞。但是由于应用不断进行系统IO调用,在此过程中十分消耗CPU,因此还有进一步优化的空间。此时就该IO多路复用模型上场一展拳脚了,而Java的NIO正是借助于此实现了IO性能的提升。(这里以epoll机制来进行说明)
Java NIO基于通道和缓冲区的形式来处理流数据,借助于Linux操作系统的epoll机制,多路复用器selector就会不断进行轮询,当某个channel的事件(读事件,写事件,连接事件等等)准备就绪的时候,就是会找到这个channel对应的SelectionKey,去做相应的操作,进行数据的读写操作。
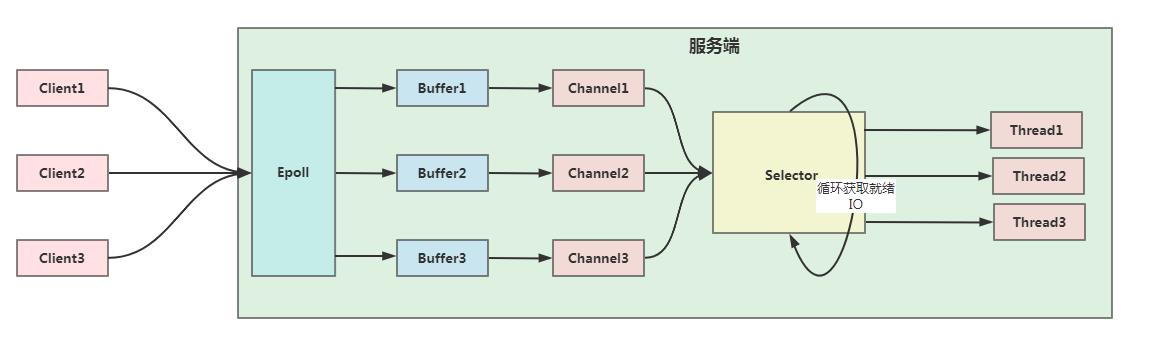
AIO
所谓AIO(Asynchronous IO)就是NIO第二代,它是在Java 7中引入的,是一种异步IO模型。异步IO模型是基于事件和回调机制实现的,当应用发起调用请求之后会直接返回不会阻塞在那里,当后台进行数据处理完成后,操作系统便会通知对应的线程来进行后续的数据处理。
从效率上来看,AIO 无疑是最高的,然而,美中不足的是目前作为广大服务器使用的系统 linux 对 AIO 的支持还不完善,导致我们还不能愉快的使用 AIO 这项技术,Netty实际也是使用过AIO技术,但是实际并没有带来很大的性能提升,目前还是基于Java NIO实现的。
总结
本文主要从计算机IO交互出发,分别给大家介绍了什么是IO模型以及常见的五种IO模型,介绍了这几种IO模型的优缺点,从系统优化演进的角度分析了Java BIO、NIO以及AIO演化之路。从设计者的角度分析Java BIO存在的不足。我们再来回顾下整个演进过程的脉络。
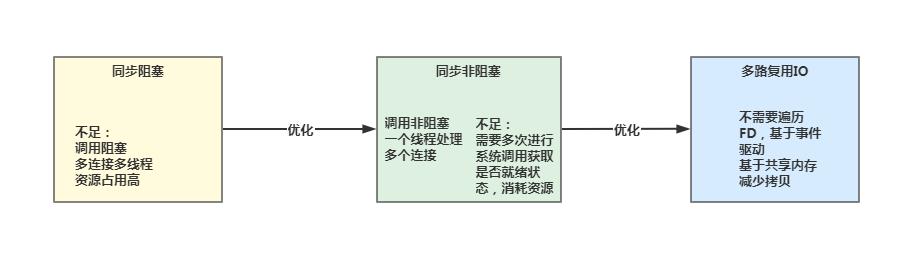
在后续的文章中,笔者将继续带大家深入研究的Netty作为高性能网络通信框架的奇妙之处,敬请期待哦。
我是慕枫,感谢各位小伙伴点赞、收藏和评论,文章持续更新,我们下期再见!
真正的大师永远怀着一颗学徒的心
微信搜索:慕枫技术笔记,优质文章持续更新,我们有学习打卡的群可以拉你进,一起努力冲击大厂,另外有很多学习以及面试的材料提供给大家。
几乎全新的键盘,自己就用了两次,有朋友送了另外的键盘,本来打算在咸鱼上卖掉的,后来想想不如在我的公众号以及CSDN粉丝中抽一位直接送了,没有套路,全国包邮送,快来领取秋天的第一个雷蛇键盘吧。


以上是关于肝了一夜,一文说清BIONIOAIO不同IO模型演进之路的主要内容,如果未能解决你的问题,请参考以下文章