大数据Spark实时搜索日志实时分析
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Spark实时搜索日志实时分析相关的知识,希望对你有一定的参考价值。
目录
1 业务场景
百度搜索风云榜(http://top.baidu.com/)以数亿网民的单日搜索行为作为数据基础,以搜索关键词为统计对象建立权威全面的各类关键词排行榜,以榜单形式向用户呈现基于百度海量搜索数据的排行信息,线上覆盖十余个行业类别,一百多个榜单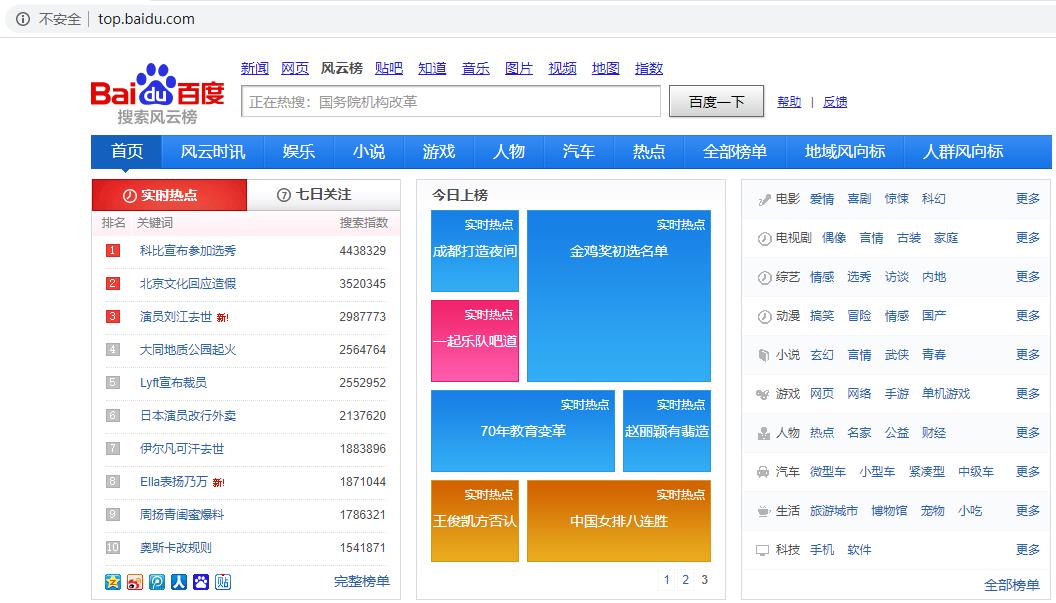
在【热点榜单】中,可以看到依据搜索关键词实时统计各种维度热点,下图展示【实时热点】。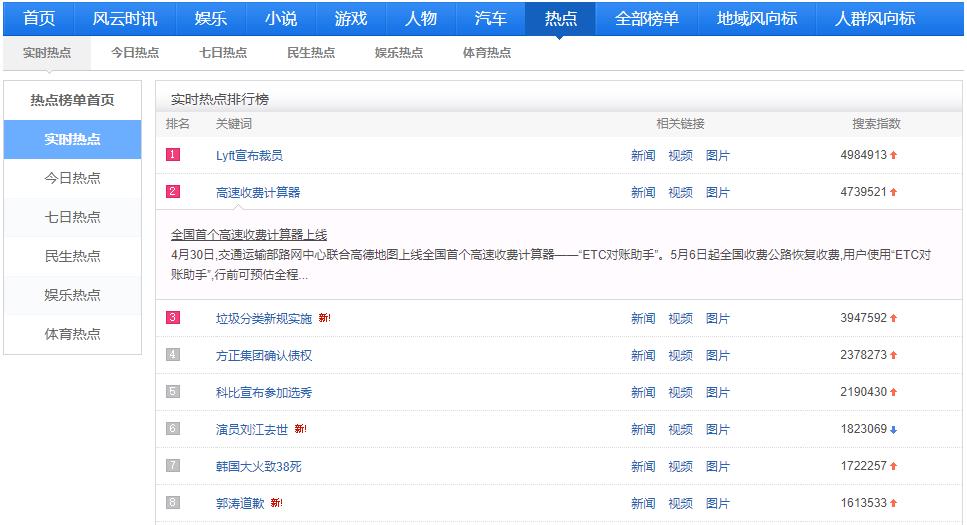
仿【百度搜索风云榜】对用户使用百度搜索时日志进行分析:【百度搜索日志实时分析】,主要业务需求如下三个方面: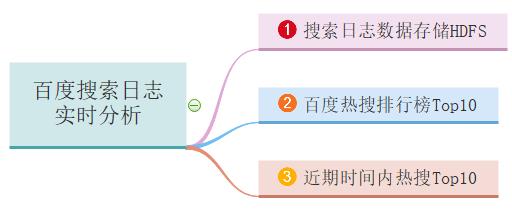
- 业务一:搜索日志数据存储HDFS,实时对日志数据进行ETL提取转换,存储HDFS文件系统;
- 业务二:百度热搜排行榜Top10,累加统计所有用户搜索词次数,获取Top10搜索词及次数;
- 业务三:近期时间内热搜Top10,统计最近一段时间范围(比如,最近半个小时或最近2个小时)
内用户搜索词次数,获取Top10搜索词及次数;
开发Maven Project中目录结构如下所示:
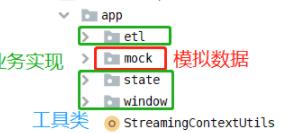
2 初始化环境
编程实现业务之前,首先编写程序模拟产生用户使用百度搜索产生日志数据和创建工具类StreamingContextUtils提供StreamingContext对象与从Kafka接收数据方法。
2.1 创建 Topic
启动Kafka Broker服务,创建Topic【search-log-topic】,命令如下所示:
# 1. 启动Zookeeper 服务
zookeeper-daemon.sh start
# 2. 启动Kafka 服务
kafka-daemon.sh start
# 3. Create Topic
kafka-topics.sh --create --topic search-log-topic \\
--partitions 3 --replication-factor 1 --zookeeper node1.oldlut.cn:2181/kafka200
# List Topics
kafka-topics.sh --list --zookeeper node1.oldlut.cn:2181/kafka200
# Producer
kafka-console-producer.sh --topic search-log-topic --broker-list node1.oldlut.cn:9092
# Consumer
kafka-console-consumer.sh --topic search-log-topic \\
--bootstrap-server node1.oldlut.cn:9092 --from-beginning
2.2 模拟日志数据
模拟用户搜索日志数据,字段信息封装到CaseClass样例类【SearchLog】类,代码如下:
package cn.oldlut.spark.app.mock
/**
* 用户百度搜索时日志数据封装样例类CaseClass
* <p>
*
* @param sessionId 会话ID
* @param ip IP地址
* @param datetime 搜索日期时间
* @param keyword 搜索关键词
*/
case class SearchLog(
sessionId: String, //
ip: String, //
datetime: String, //
keyword: String //
) {
override def toString: String = s"$sessionId,$ip,$datetime,$keyword"
}
`` `
模拟产生搜索日志数据类 【 MockSearchLogs 】 具体代码如下 :
`` `
package cn.oldlut.spark.app.mock
import java.util.{Properties, UUID}
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import scala.util.Random
/**
* 模拟产生用户使用百度搜索引擎时,搜索查询日志数据,包含字段为:
* uid, ip, search_datetime, search_keyword
*/
object MockSearchLogs {
def main(args: Array[String]): Unit = {
// 搜索关键词,直接到百度热搜榜获取即可
val keywords: Array[String] = Array("罗志祥", "谭卓疑", "当当网", "裸海蝶", "张建国")
// 发送Kafka Topic
val props = new Properties()
props.put("bootstrap.servers", "node1.oldlut.cn:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
val producer = new KafkaProducer[String, String](props)
val random: Random = new Random()
while (true) {
// 随机产生一条搜索查询日志
val searchLog: SearchLog = SearchLog(
getUserId(), //
getRandomIp(), //
getCurrentDateTime(), //
keywords(random.nextInt(keywords.length)) //
)
println(searchLog.toString)
Thread.sleep(10 + random.nextInt(100))
val record = new ProducerRecord[String, String]("search-log-topic", searchLog.toString)
producer.send(record)
}
// 关闭连接
producer.close()
}
/**
* 随机生成用户SessionId
*/
def getUserId(): String = {
val uuid: String = UUID.randomUUID().toString
uuid.replaceAll("-", "").substring(16)
}
/**
* 获取当前日期时间,格式为yyyyMMddHHmmssSSS
*/
def getCurrentDateTime(): String = {
val format = FastDateFormat.getInstance("yyyyMMddHHmmssSSS")
val nowDateTime: Long = System.currentTimeMillis()
format.format(nowDateTime)
}
/**
* 获取随机IP地址
*/
def getRandomIp(): String = {
// ip范围
val range: Array[(Int, Int)] = Array(
(607649792, 608174079), //36.56.0.0-36.63.255.255
(1038614528, 1039007743), //61.232.0.0-61.237.255.255
(1783627776, 1784676351), //106.80.0.0-106.95.255.255
(2035023872, 2035154943), //121.76.0.0-121.77.255.255
(2078801920, 2079064063), //123.232.0.0-123.235.255.255
(-1950089216, -1948778497), //139.196.0.0-139.215.255.255
(-1425539072, -1425014785), //171.8.0.0-171.15.255.255
(-1236271104, -1235419137), //182.80.0.0-182.92.255.255
(-770113536, -768606209), //210.25.0.0-210.47.255.255
(-569376768, -564133889) //222.16.0.0-222.95.255.255
)
// 随机数:IP地址范围下标
val random = new Random()
val index = random.nextInt(10)
val ipNumber: Int = range(index)._1 + random.nextInt(range(index)._2 - range(index)._1)
//println(s"ipNumber = ${ipNumber}")
// 转换Int类型IP地址为IPv4格式
number2IpString(ipNumber)
}
/**
* 将Int类型IPv4地址转换为字符串类型
*/
def number2IpString(ip: Int): String = {
val buffer: Array[Int] = new Array[Int](4)
buffer(0) = (ip >> 24) & 0xff
buffer(1) = (ip >> 16) & 0xff
buffer(2) = (ip >> 8) & 0xff
buffer(3) = ip & 0xff
// 返回IPv4地址
buffer.mkString(".")
}
}
运行应用程序,源源不断产生日志数据,发送至Kafka(同时在控制台打印),截图如下: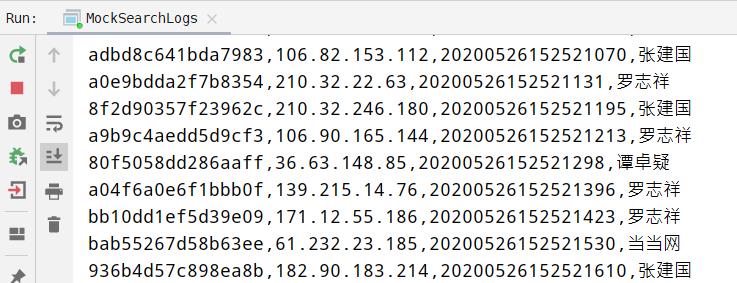
2.3 StreamingContextUtils 工具类
所有SparkStreaming应用都需要构建StreamingContext实例对象,并且从采用New KafkaConsumer API消费Kafka数据,编写工具类【StreamingContextUtils】,提供两个方法:
- 方法一:getStreamingContext,获取StreamingContext实例对象

- 方法二:consumerKafka,消费Kafka Topic中数据

具体代码如下:
package cn.oldlut.spark.app
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 工具类提供:构建流式应用上下文StreamingContext实例对象和从Kafka Topic消费数据
*/
object StreamingContextUtils {
/**
* 获取StreamingContext实例,传递批处理时间间隔
*
* @param batchInterval 批处理时间间隔,单位为秒
*/
def getStreamingContext(clazz: Class[_], batchInterval: Int): StreamingContext = {
// i. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(clazz.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// 设置Kryo序列化
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array(classOf[ConsumerRecord[String, String]]))
// ii.创建流式上下文对象, 传递SparkConf对象和时间间隔
val context = new StreamingContext(sparkConf, Seconds(batchInterval))
// iii. 返回
context
}
/**
* 从指定的Kafka Topic中消费数据,默认从最新偏移量(largest)开始消费
*
* @param ssc StreamingContext实例对象
* @param topicName 消费Kafka中Topic名称
*/
def consumerKafka(ssc: StreamingContext, topicName: String): DStream[ConsumerRecord[String, String]] = {
// i.位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// ii.读取哪些Topic数据
val topics = Array(topicName)
// iii.消费Kafka 数据配置参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1.oldlut.cn:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group_id_streaming_0001",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// iv.消费数据策略
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe(
topics, kafkaParams
)
// v.采用新消费者API获取数据,类似于Direct方式
val kafkaDStream: DStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, locationStrategy, consumerStrategy
)
// vi.返回DStream
kafkaDStream
}
}
3 实时数据ETL存储
实时从Kafka Topic消费数据,提取ip地址字段,调用【ip2Region】库解析为省份和城市,存储到HDFS文件中,设置批处理时间间隔BatchInterval为10秒,完整代码如下:
package cn.oldlut.spark.app.etl
import cn.oldlut.spark.app.StreamingContextUtils
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
import org.lionsoul.ip2region.{DataBlock, DbConfig, DbSearcher}
/**
* 实时消费Kafka Topic数据,经过ETL(过滤、转换)后,保存至HDFS文件系统中,BatchInterval为:10s
*/
object StreamingETLHdfs {
def main(args: Array[String]): Unit = {
// 1. 获取StreamingContext实例对象
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, 10)
// 2. 从Kafka消费数据,使用Kafka New Consumer API
val kafkaDStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils
.consumerKafka(ssc, "search-log-topic")
// 3. 数据ETL:过滤不合格数据及转换IP地址为省份和城市,并存储HDFS上
kafkaDStream.foreachRDD { (rdd, time) =>
// i. message不为null,且分割为4个字段
val kafkaRDD: RDD[ConsumerRecord[String, String]] = rdd.filter { record =>
val message: String = record.value()
null != message && message.trim.split(",").length == 4
}
// ii. 解析IP地址
val etlRDD: RDD[String] = kafkaRDD.mapPartitions { iter =>
// 创建DbSearcher对象,针对每个分区创建一个,并不是每条数据创建一个
val dbSearcher = new DbSearcher(new DbConfig(), "dataset/ip2region.db")
iter.map { record =>
val Array(_, ip, _, _) = record.value().split(",")
// 依据IP地址解析
val dataBlock: DataBlock = dbSearcher.btreeSearch(ip)
val region: String = dataBlock.getRegion
val Array(_, _, province, city, _) = region.split("\\\\|")
// 组合字符串
s"${record.value()},$province,$city"
}
}
// iii. 保存至文件
val savePath = s"datas/streaming/etl/search-log-${time.milliseconds}"
if (!etlRDD.isEmpty()) {
etlRDD.coalesce(1).saveAsTextFile(savePath)
}
}
// 4.启动流式应用,一直运行,直到程序手动关闭或异常终止
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
运行模拟日志数据程序和ETL应用程序,查看实时数据ETL后保存文件,截图如下: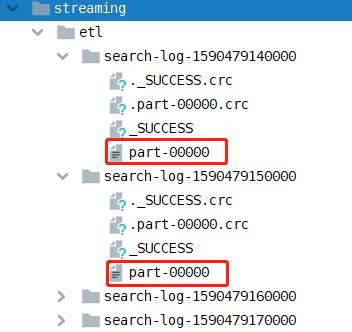
4 实时状态更新统计
实 时 累 加 统 计 用 户 各 个 搜 索 词 出 现 的 次 数 , 在 SparkStreaming 中 提 供 函 数【updateStateByKey】实现累加统计,Spark 1.6提供【mapWithState】函数状态统计,性能更好,实际应用中也推荐使用。
4.1 updateStateByKey 函数
状态更新函数【updateStateByKey】表示依据Key更新状态,要求DStream中数据类型为【Key/Value】对二元组,函数声明如下:

将每批次数据状态,按照Key与以前状态,使用定义函数【updateFunc】进行更新,示意图如下: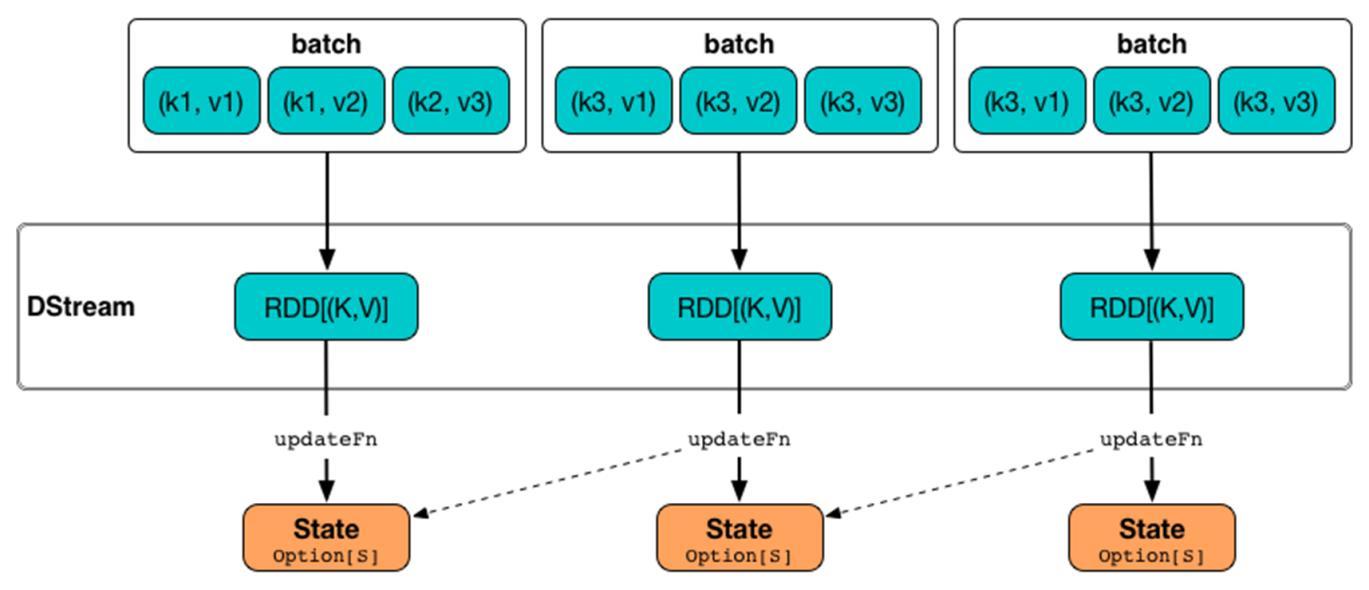
文档: http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#updatestatebykey-operation
针对搜索词词频统计WordCount,状态更新逻辑示意图如下: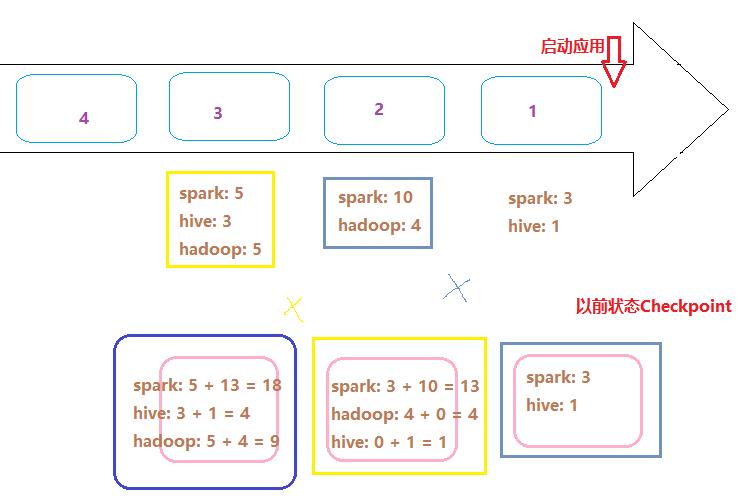
以前的状态数据,保存到Checkpoint检查点目录中,所以在代码中需要设置Checkpoint检查点目录:
完整演示代码如下:
package cn.oldlut.spark.app.state
import cn.oldlut.spark.app.StreamingContextUtils
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
/**
* 实时消费Kafka Topic数据,累加统计各个搜索词的搜索次数,实现百度搜索风云榜
*/
object StreamingUpdateState {
def main(args: Array[String]): Unit = {
// 1. 获取StreamingContext实例对象
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, 5)
// TODO: 设置检查点目录
ssc.checkpoint(s"datas/streaming/state-${System.nanoTime()}")
// 2. 从Kafka消费数据,使用Kafka New Consumer API
val kafkaDStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils
.consumerKafka(ssc, "search-log-topic")
// 3. 对每批次的数据进行搜索词次数统计
val reduceDStream: DStream[(String, Int)] = kafkaDStream.transform { rdd =>
val reduceRDD = rdd
// 过滤不合格的数据
.filter { record =>
val message: String = record.value()
null != message && message.trim.split(",").length == 4
}
// 提取搜索词,转换数据为二元组,表示每个搜索词出现一次
.map { record =>
val keyword: String = record.value().trim.split(",").last
keyword -> 1
}
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item) // TODO: 先聚合,再更新,优化
reduceRDD // 返回
}
/*
def updateStateByKey[S: ClassTag](
// 状态更新函数
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)]
第一个参数:Seq[V]
表示的是相同Key的所有Value值
第二个参数:Option[S]
表示的是Key的以前状态,可能有值Some,可能没值None以上是关于大数据Spark实时搜索日志实时分析的主要内容,如果未能解决你的问题,请参考以下文章