知识点补充(MySQL读写分离分布式事务)
Posted Zephyr丶J
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识点补充(MySQL读写分离分布式事务)相关的知识,希望对你有一定的参考价值。
项目只是一个节点,如果分布式部署该怎么办?多个节点是什么样的?
在这个过程中,常见的优化手段是什么?
mysql读写分离的原理是什么?
mysql实现分布式事务原理是什么?(事务和log)
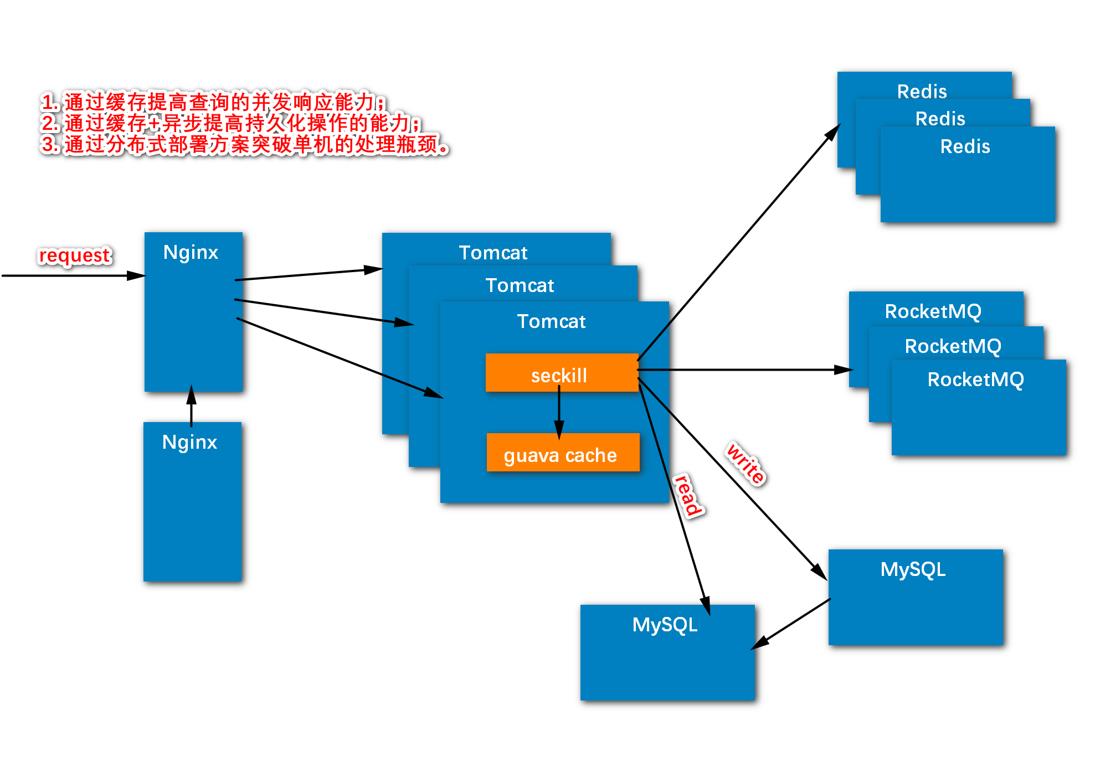
分布式部署
分布式的时候,tomcat有多个,做成一个集群的样子
这里画了3个,每一个都跑着我们的应用,seckill
多个tomcat前端访问哪一个了,通过nginx做负载均衡,做一个请求的分发,可以平均分发,也可以给服务器设置一个权重,权重高的发的多
这样配置有个问题,如果nginx挂了,就都访问不了了,所以nginx可以做集群,或者热备(启用两个nginx),一般热备就可以了;
这两个nginx比如都监听80端口,谁抢到谁就是主服务器,没抢到就可以理解为从服务器;从服务器也在一直运行,从服务器监视主服务器;如果主服务器挂了,马上去抢这个端口,由从服务器来接手这个任务
Tomcat要访问mysql,如果mysql只有一个节点,压力很大,性能不好;尽量不做mysql的分布式部署,因为做了分布式,就要做分布式的事务,因为把一个表的数据分散在多个表里,同步的事情怎么解决,就很麻烦;即便是有多个mysql,我们也会把表中的数据按业务来拆分,比如A用户相关的数据存入a库,B用户相关的数据存入b库,因为我们数据一般都是基于用户发生的,所以在一个库里做事务,就不用分布式事务了;总之,尽量避免分布式事务
如果不可避免?后面提到
MySQL读写分离
读写分离是我有两个mysql节点,一个主一个从,seckill要写入的话往主服务器里写,用一个线程往从服务器同步数据,读数据的话是从从服务器里读
缓存
但是如果并发量很大的话,很多请求都往mysql中写,mysql会崩溃,所以通常在访问mysql之前加一个缓存来提高并发性能
缓存通常有两级缓存,本地缓存,我们项目用的是guava cache,seckill可以先访问这个cache有没有数据,这个缓存和tomcat,和java应用在一起,占用的是jvm的内存,这个内存很稀缺,比较有限,存不了多少数据,比如用户就不适合存放在这个缓冲中
所以有了二级缓存,一般用redis,redis数据类型多,方便,redis也可以做成集群,哨兵模式
所以就变成了先看一级缓存有没有数据,如果没有再看二级缓存,如果没有再看mysql
另外,如果我们的系统有多个子系统,系统多个业务之间有关联,或者说我们需要把两个功能解耦,做拆分,做异步,怎么办?就需要引入消息队列RocketMQ,这样的话性能就会有所提升;就是说我不用在这一刻处理完,延迟一会也可以,这就是异步,这样性能就提高了
(通过缓存+异步提高了持久化,也就是下单操作的能力)
MyBatis也在缓存里,可以替代guava cache吗?
也可以,mybatis也是泡在tomcat里,但是没有guava更灵活,因为mybatis是直接访问mysql,得到的数据直接存储起来了;但是我可能要存的不是表里的数据,而是查到了数据要进行处理加工,把最后整合的结果缓存,这样mybatis就不适合了
MySQL读写分离
读写分离是我有两个mysql节点,一个主一个从,seckill要写入的话往主服务器里写,用一个线程往从服务器同步数据,读数据的话是从从服务器里读
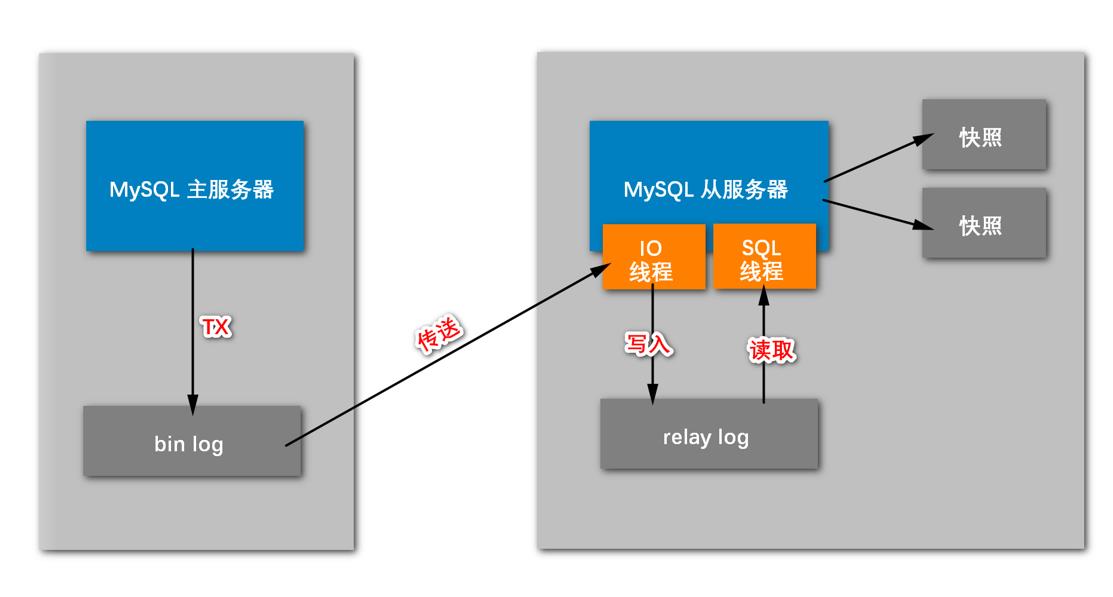
MySQL读写分离其实是基于MySQL主从的架构,主从就是说有两个服务器,两个服务器不会放在一个物理节点上,不会放在一个物理机上;因为俩服务器起到一个备份的作用,如果放到一个机器上,挂了的话,主从就都挂了,一般会放在两个物理机上,如下图:
MySQL主服务器,当它在执行DML语句的时候,它是以事务为单位,存储bin log,一提交事务的时候,bin log就会被更新;主从数据库之间的同步就基于bin log
从服务器就是起到一个备份的作用,避免主服务器硬盘坏了,数据丢了;
从服务器数据从哪来,不是主服务器实时传递的,这样会影响性能;而是写到日志里,然后从服务器去向日志要,所以从服务器有一个机制是从日志中读数据
从服务器经常起到被读取的作用(主服务器写,从服务器读),所以从服务器要承受被读取的压力,又要读取bin log,一个线程做的话就很麻烦,所以有两个核心的线程,一个是IO线程,一个是SQL线程,IO线程就是读binlog,把数据同步过来,SQL线程就是用户从这里读数据,可以并发的
所以IO线程就会以一定的频率去读bin log,所以需要数据的传送。IO线程读到bin log,写入到从服务器的一个日志里,这个日志叫relay log(中继日志);
如果外部要读数据,会走SQL线程,SQL线程会从relay log中读取想要的数据。
从服务器往往还负责另一个件事,就是生成快照,快照就是这一瞬间硬盘中数据的形态,相当于做一个备份,可以有多个快照;
为什么让从服务器做快照呢?因为有可能有这样的情况,假设今天这个主服务器管理员有点二,向服务器执行了一个错误的东西,把一些数据破坏了,而且规模很大;或者被攻击了,数据被破坏了;这时候有从服务器的快照机制,可以基于快照来恢复数据;所以从服务器快照是为了在主服务器发生错误的时候,进行恢复数据的
总之,读写分离的架构是建立在主从模式之上,而主从模式是基于两个log来实现的,从服务器有两个线程来解决对应的问题
分布式事务
如果mysql读写分离不够用怎么办,扛不住并发怎么办,我们得做分布式,分布式我们可以按业务拆分数据,使得一类业务的数据在一个库里,避免了分布式事务;如果有特殊情况没法这样拆分,不可避免的需要分布式事务,怎么办?
在一些特殊情况下,真的不可避免做分布式事务;例如跨行转账,这两个银行是两家企业,数据库都可能不一样,所以必须是分布式事务,分布式事务有时候在交易场景里是不可避免的,一定要解决
所以分布式事务不是说统一数据库前提下,是可以跨数据库的,只要数据库支持分布式事务,可以编织在一起,做类似于跨行转账的事情
分布式事务和RocketMQ事务型消息,本质上是类似的;
解决分布式事务的核心就是用两阶段提交,怎么两阶段提交呢?
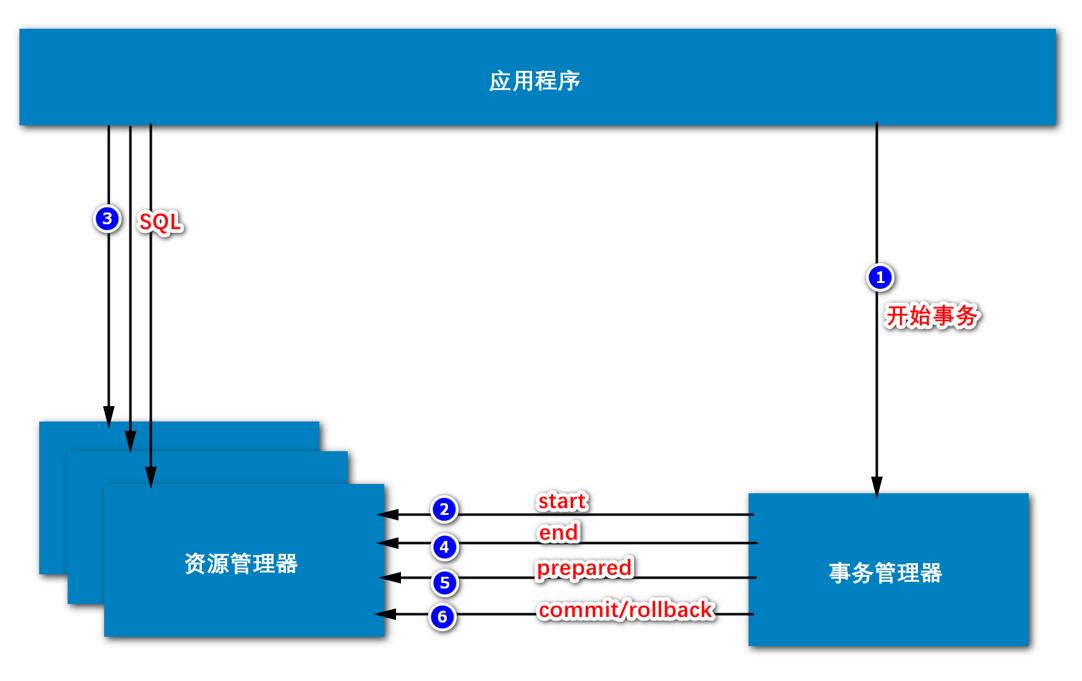
有三个角色,一个是资源管理器(支持分布式事务的数据库,在分布式事务下叫资源管理器;为什么叫资源管理器,因为有可能不是数据库,可能是消息中间件,其实也是这个原理);资源管理器之间是不能交互,做分布式事务的,需要有一个管理者,协调者,它是事务管理器;事务管理器是连接M有SQL服务器的客户端;还得有一个需求方,在什么需求下做分布式事务,也就是应用程序
实现分布式事务,由应用程序发起,不是访问最终的数据库,而是先跟事务管理器打招呼:现在有一个业务,实现分布式事务,分布式事务下,在三个数据库里做DML操作
所以第一步,通知事务管理器,开始事务;
第二步这个事务管理器会协调它们,向每一个资源管理器发一个命令start,表示要开始事务了;
第三步,这个应用程序就会依次向三个数据库里做DML操作,执行结束(注意没有commit),会告诉事务管理器,执行完了
第四步,这时,事务管理器会依次向三个数据库发送命令end,表示结束;通过start和end记录了在这个时间范围内,这三个数据库都执行了什么东西,都记录下来;
记下来以后,开始提交事务;这三个数据库的sql要做到原子性,要么全成功,要么全失败;刚刚第三步没有提交,这个提交的事情由事务管理器来协调,它是用两阶段的方式做提交,最终保证一致性的
第五步,事务管理器再发送一个命令prepared,询问数据库准备好了吗,能不能提交;这三个数据库检查一下SQL语句执行完了吗,执行完了就意味着可以提交了;如果可以提交就给事务管理器一个反馈,进入下一个环节;如果有一个数据库不能提交,就拒绝,回滚
第六步,向所有的库发送commit或者rollback;什么时候发commit,什么时候rollback呢,当第五步返回结果都准备好了就commit,有一个不行就rollback
最终在事务管理器的协调之下,就做到了同步
但是有问题?第一,事务管理器挂了怎么办?第二?如果第六步传达消息的时候,有可能没有传到某一个服务器上,丢包的情况,这种情况怎么办?
如果挂了,sql执行了,没提交,数据没生效,和丢包的情况是类似的,这个机制不能百分之百保证真的同步好了
如果rollback了,会重新开始操作吗?默认没有,这种问题需要通过应用层加一个重试机制,每隔一段时间去检查一下数据库,数据状态是不是提交的,数据有没有变化;或者在事务管理器这方面去每隔一段时间检查一下有没有提交,有没有回滚,事务有没有结束,如果没有结束,应该怎么样,再发送命令
检查是否挂掉,ping检测
注意,刚刚说的是外部的分布式事务,mysql内部也有分布式事务!!!
内部分布式事务主要是解决InnoDB引擎和bin log间的连带关系,这个场景主要发生在读写分离的时候
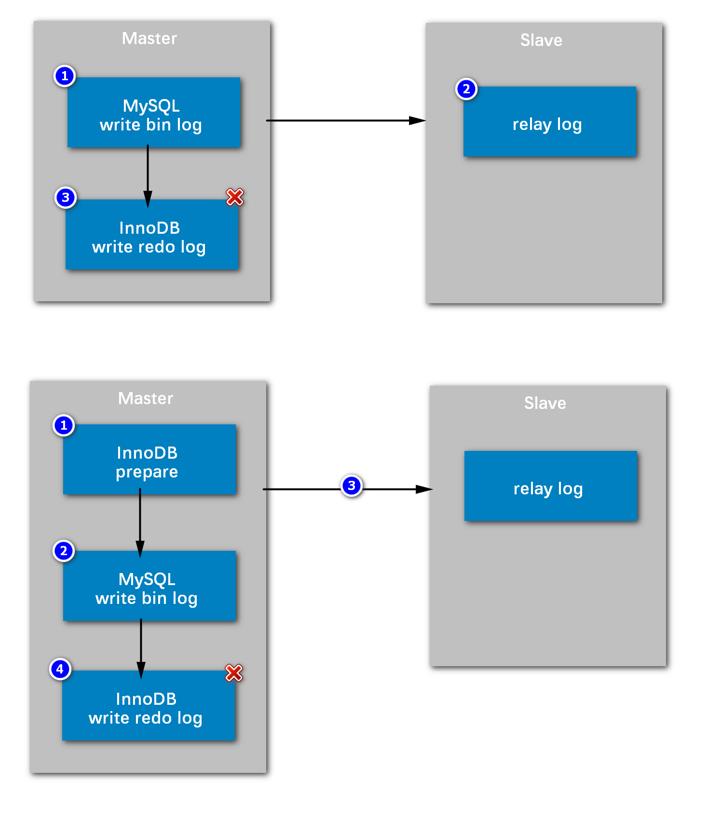
主服务器Master,从服务器是Slave,它们之间的同步是通过中继日志(relay log)来做的
mysql需要把数据写到bin log,从服务器读bin log;但是这里有问题:
比如第一步,mysql写了数据到bin log;
第二步,从服务器把bin log的数据读取,写到中继日志里;
第三步,InnoDB引擎为了持久性会写redo log,这个redo log是commit以后存储的
这时,需要写bin log 和redo log,这两件事应该是有事务保障的,不能说bin log写了,redo log没有了,或者反过来,这样会有问题
假设这里写redo log的时候失败了,redo log 和bin log就不同步了,所以内部的分布式事务,是解决bin log 和redo log不同步的问题,所以它们要需要保证事务,就要用到分布式事务,
为什么是分布式事务?redo log是InnoDB引擎的行为,bin log是数据库层面的行为,这是两个不同的模块之间的行为,所以它们之间的同步需要做分布式事务;这个是在mysql之内做的事情,所以叫内部分布式事务
那怎么解决?关键还是两阶段提交
第一步,InnoDB先prepare,表示存数据之间先记录一下,我要开始存数据了,打个标记
然后再去写bin log,第三步,bin log 可能被同步;第四步,才会写redo log;
如果写redo log失败了,没有关系,因为之前prepare了,表示要写redo log了,但是检查发现没有写成功,那么就可以从bin log恢复,可以找回,即如果没有写redo log可以被感知到;如果没有prepare这一步,没有打开始的标记,数据丢了是不知道的,redo log就不能保证持久性了
这个逻辑叫做内部分布式事务,解决的是binlog和redolog同步的问题,它们是不同的层面,InnoDB和数据库层面要保证一致的问题的解决方案
三阶段提交就是再加一层检查的机制,分布式事务做少要做到两阶段提交
以上是关于知识点补充(MySQL读写分离分布式事务)的主要内容,如果未能解决你的问题,请参考以下文章