std 源码剖析及 C++ 内存管理
Posted C语言与CPP编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了std 源码剖析及 C++ 内存管理相关的知识,希望对你有一定的参考价值。

大家好,我是唐唐!
本文关于 C++ 内存管理学习笔记自侯捷,上次笔记见 C++ 内存管理(一)。
1.各个标准分配器实现
1.1 VC6.0 malloc
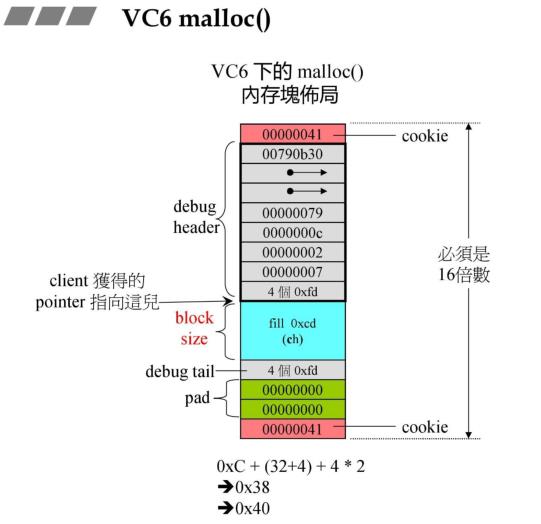
在第一节中提到,malloc 的内存块布局如上,其中 cookie (记录区块大小)小,浪费率高,因为 cookie 始终占 8 字节。cookie 是我们不需要的,如果大量调用 malloc 的话 cookie 总和会增多,这会造成较大的浪费,因此减少 malloc 调用次数,去掉 cookie 总是好的。
1.2 VC6.0标准分配器
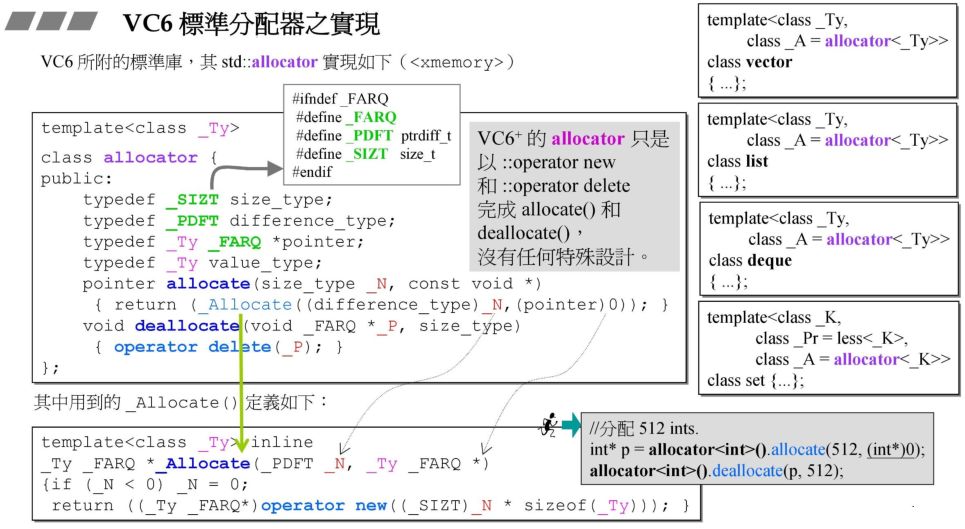
结论:VC6.0 的 allocate() 函数只是对 malloc 的二次封装,并没有做什么很特殊的操作,它是以类型字节长度为单位分配内存的,上图就分配了512个int类型空间。

结论:同 vc6.0。
1.3 G2.9 malloc

GCC 2.9 版本的 allocator 如上图所示,同样这里的 allocator 同前面提到的几个标准分配器一样。
而 g2.9 容器使用的分配器,不是 std::allocator,而是std::alloc。
对于前面提到的 malloc 设计,如果想要优化,可以减少malloc次数,同时减少cookie。而去除 cookie 的先决条件是你的 cookie 大小一致。容器里面的元素是一样的大小,这就满足了先决条件!
分配器的客户不是给你应用程序用,而是给容器用。

1.4 G4.9 malloc
在 GCC 4.9 版本,2.9 版本的 alloc 变成了 __pool_alloc。
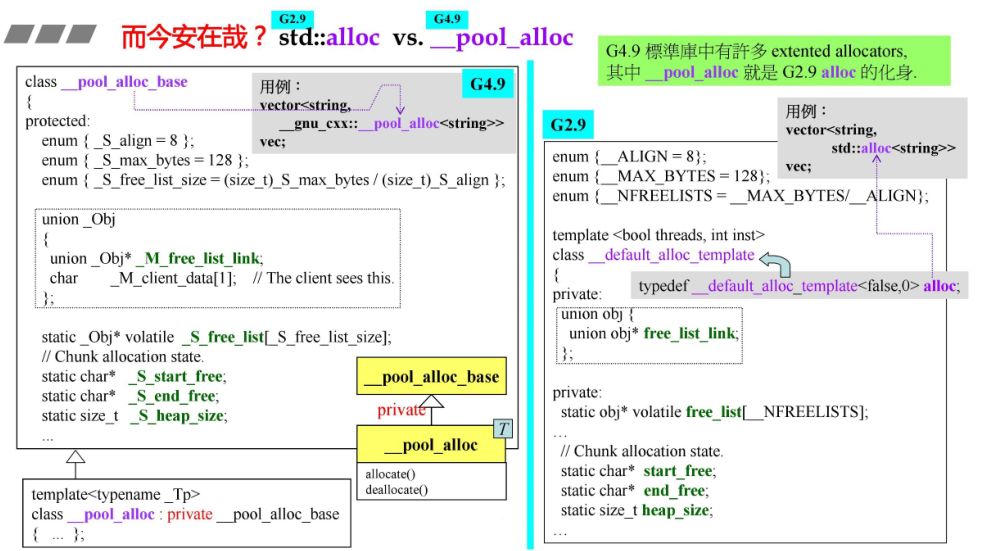
从上面两张图可以对比看出,2.9 版本的 allocate 和 4.9 版本的 __pool_alloc 做的事是一样的,只是修改了变量名和一些细小操作而已。

1.5 G4.9结构
g4.9 的 __pool_alloc 是我们在容器中使用的分配器。而普通的 allocator,则是通过 operator new 与 operator delete 调用 malloca 与 free。其实没有什么特殊设计。

最后,来个测试用例,通过对比 allocator 与 __pool_alloc 来看看连续地址相差字节,来判断是否携带 cookie。
#include <iostream>#include <vector>#include <ext/pool_allocator.h>
using namespace std;
template<typename Alloc>void cookie_test(Alloc alloc, size_t n){ typename Alloc::value_type *p1, *p2, *p3;//需有 typename p1 = alloc.allocate(n); //allocate() and deallocate() 是 non-static, 需以 object 呼叫之. p2 = alloc.allocate(n); p3 = alloc.allocate(n);
cout << "p1= " << p1 << '\\t' << "p2= " << p2 << '\\t' << "p3= " << p3 << '\\n';
alloc.deallocate(p1,sizeof(typename Alloc::value_type)); //需有 typename alloc.deallocate(p2,sizeof(typename Alloc::value_type)); //有些 allocator 對於 2nd argument 的值無所謂 alloc.deallocate(p3,sizeof(typename Alloc::value_type));}
int main(void){ cout << sizeof(__gnu_cxx::__pool_alloc<double>) << endl; vector<int, __gnu_cxx::__pool_alloc<double> > vecPool; cookie_test(__gnu_cxx::__pool_alloc<double>(), 1);
cout << "----------------------" << endl;
cout << sizeof(std::allocator<double>) << endl; vector<int, std::allocator<double> > vecPool2; cookie_test(std::allocator<double>(), 1);
return 0;}
输出:
1p1= 0x5557fc0f1280p2= 0x5557fc0f1288p3= 0x5557fc0f1290----------------------1p1= 0x5557fc0f13d0p2= 0x5557fc0f13f0p3= 0x5557fc0f1410
可以发现容器使用的 __pool_alloc 后,连续地址相差 8 字节,而一个 double 类型变量的大小也是 8 个字节,说明这连续几块内存之间是不带 cookie 的(即使这几块内存在物理上也是不连续的)。而后面那个则相差更多(相差 32 字节,携带了 cookie )。
2.std::alloc
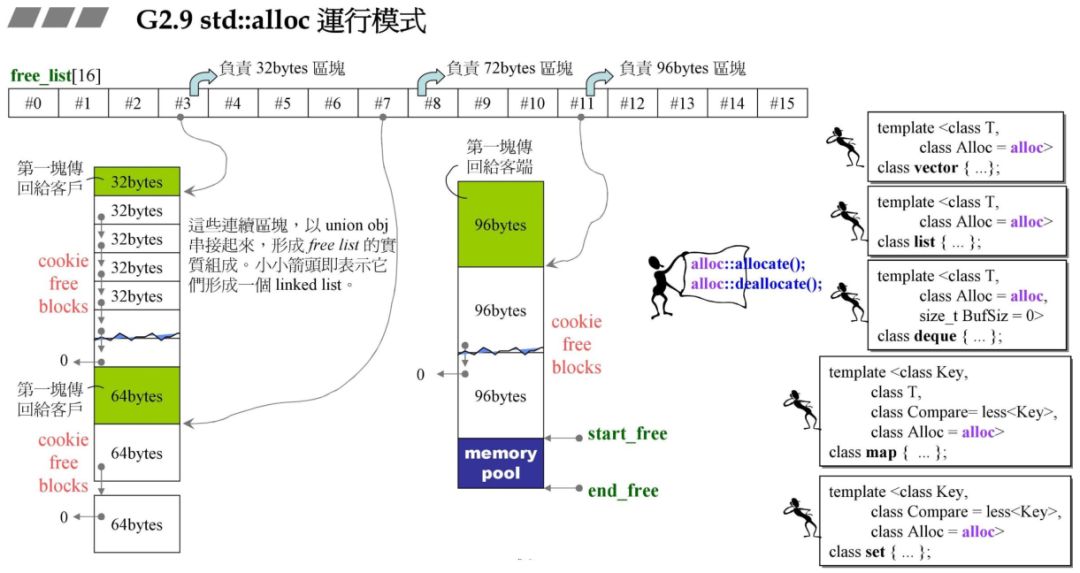
2.1 G2.9 运作模式
G2.9 std::alloc 运作模式使用一个 16 个携带指针头的数组来管理内存链表,而我们上一章只是用了一条链表。数组不同的元素管理不同的区块,每个元素之间相差 8 字节,例如 #3 号元素负责管理 32bytes 为一小块的链表。
途中 pool 就是战备池( start_free 与 end_free 中间部分),所以总是把分配的东西放到战备池中,再从战备池挖适当的空间到链表来。这样构思,代码写起来特别漂亮。
假设现在用户需要 32 字节的内存,std::allloc 先申请一块区间,为 32*20*2 大小,用一条链表管理,然后让数组的#3链表指针管理这条链表。接着讲该以 32 为一个单元的链表的中的一个单元( 32 字节)分给用户。(对应图中绿色部分).
为什么是 32*20*2?
前面 32*20 空间是分配给用户的,但是后面的 32*20 空间是预留的,如图所示,如果这时用户需要一个 64 字节的空间,那么剩下的 32*20 空间将变成 64*10,然后将其中 64 字节分配给用户,而不用再一次地构建链表和申请空间。其中 20 是开发团队设计的一个值。
如果该链表组维护的链表最大的一个小块为 128byte,但是用户申请内存块超过了 128byte,那么 std::alloc 将调用 malloc 给用户分配空间,然后该块将带上 cookie头和尾。
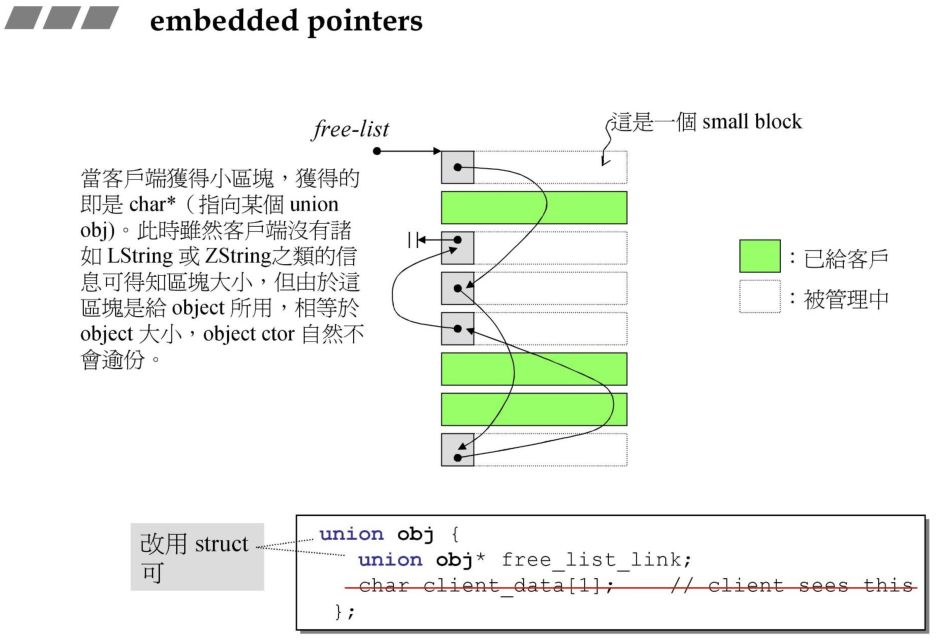
前面一节提到内存管理的核心设计:嵌入式指针.在真正的商业级的内存分配器中,一般都会使用嵌入式指针,将每一个小块的前四个字节用作指针连接下一块可用的内存块。这样不需要多分配额外空间,就可以完成任务。
2.2 std::alloc运行过程
申请32bytes图
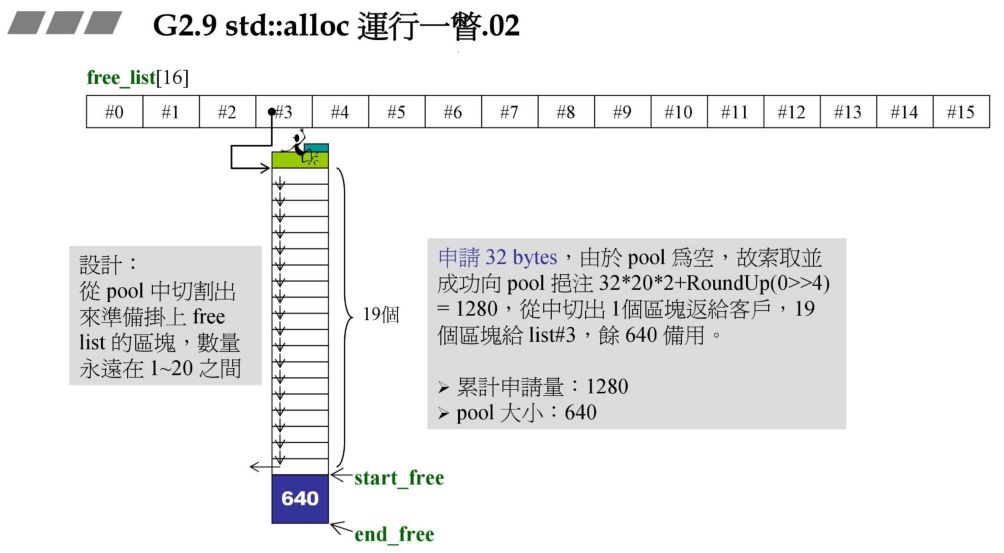
32 字节对应 #3 指针所指向的链表,此时由于战备池为空,故向战备池中充值 32*20*2+RoundUp(0>>4=1280) ,从中切出一块返回给客户,剩余 19 块,累计申请量有 1280 字节,战备池有 640 字节.
RoundUp 实现 8 字节对齐.例如传入 13,传出的就是 16. 0>>4 表示右移 4 位,每次除以 16.
申请 64bytes 图
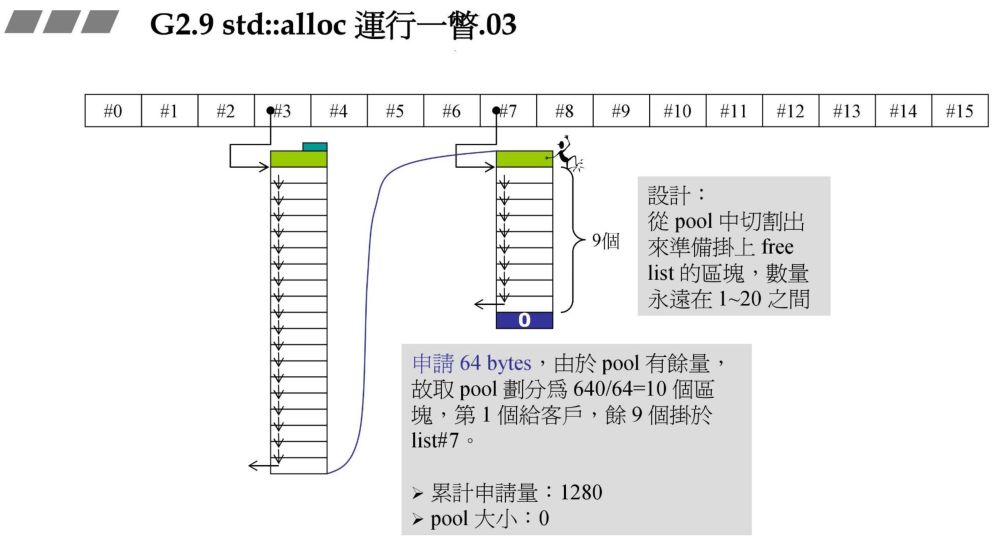
上次的战备池有 640 字节,下次的分配就会从战备池中取,这次申请 64 字节,对应到#7链表指针,此时使用战备池中的字节做区块,可以得到 10 个,从中切出一块返回给用户,剩余 9,此时累计申请量:1280 ,战备池大小此时为 0。
申请 96bytes 图
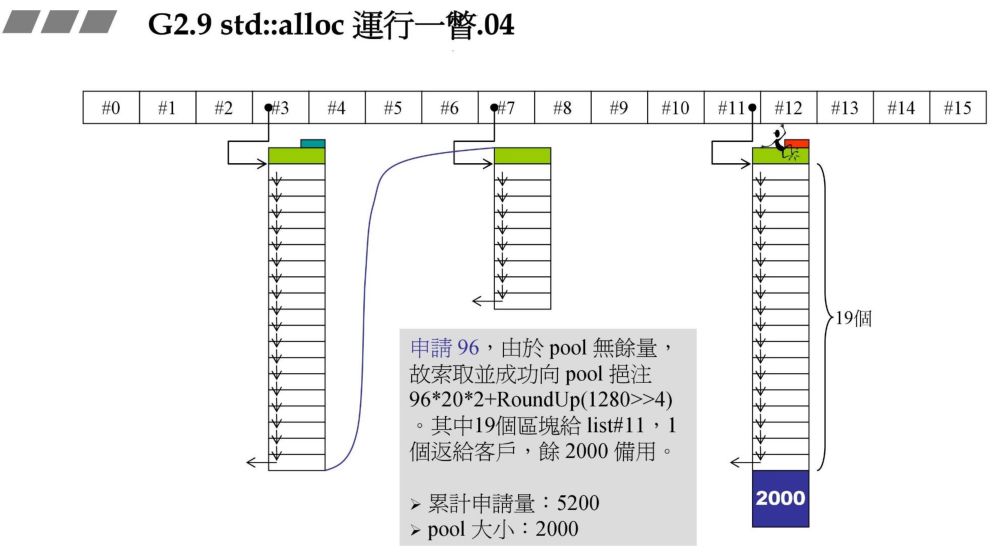
由于战备池中没有余量,此时向战备池中注入96*20*2+RoundUp(1280>>4) 其余原理同上。
后面的申请图同上原理。
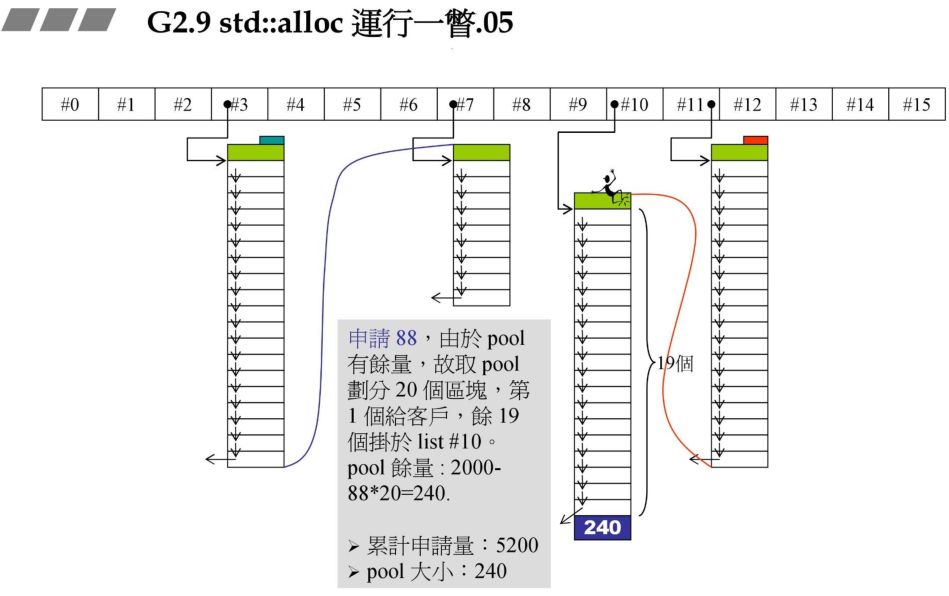
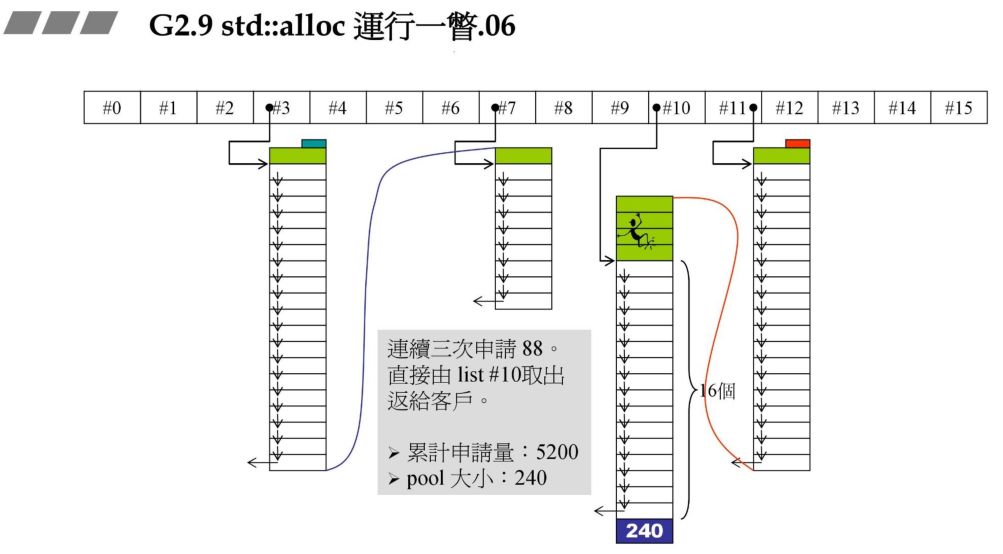
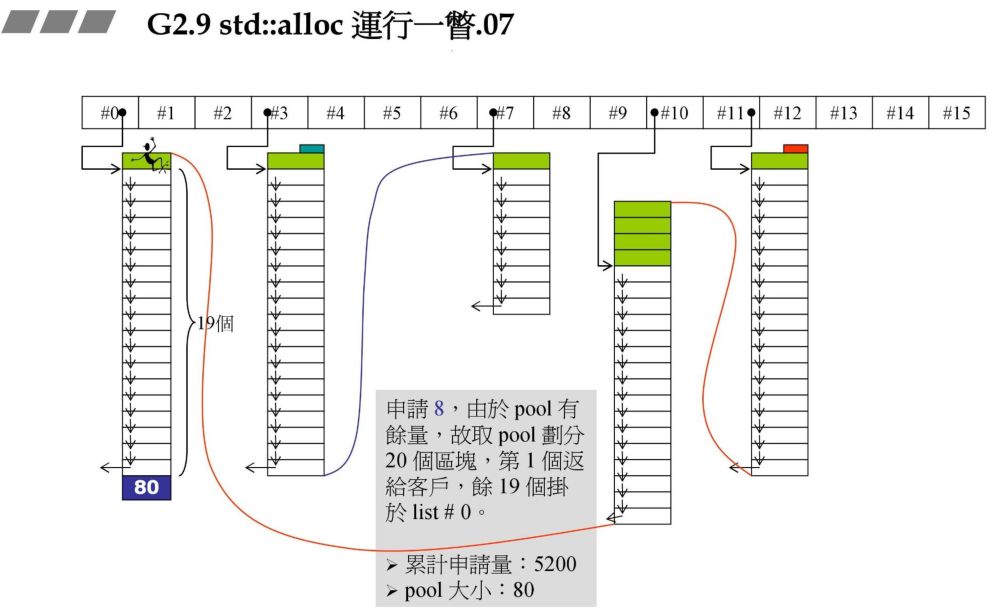
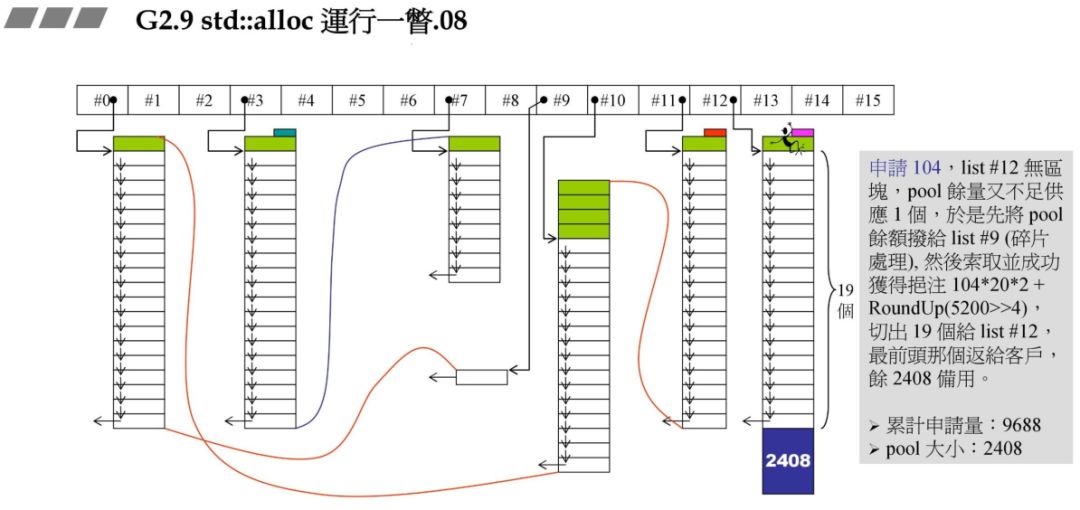
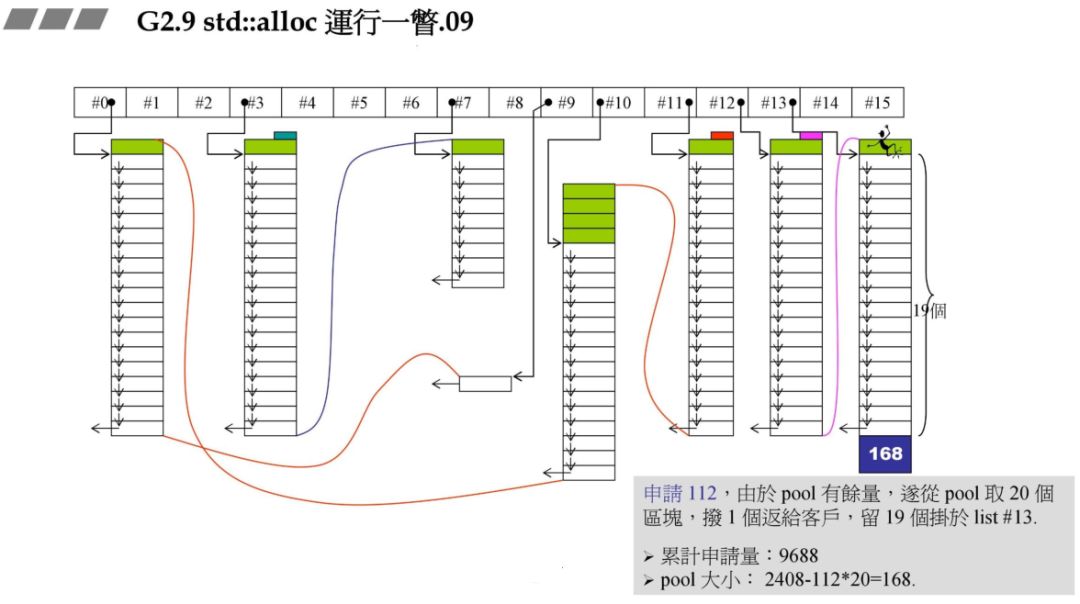
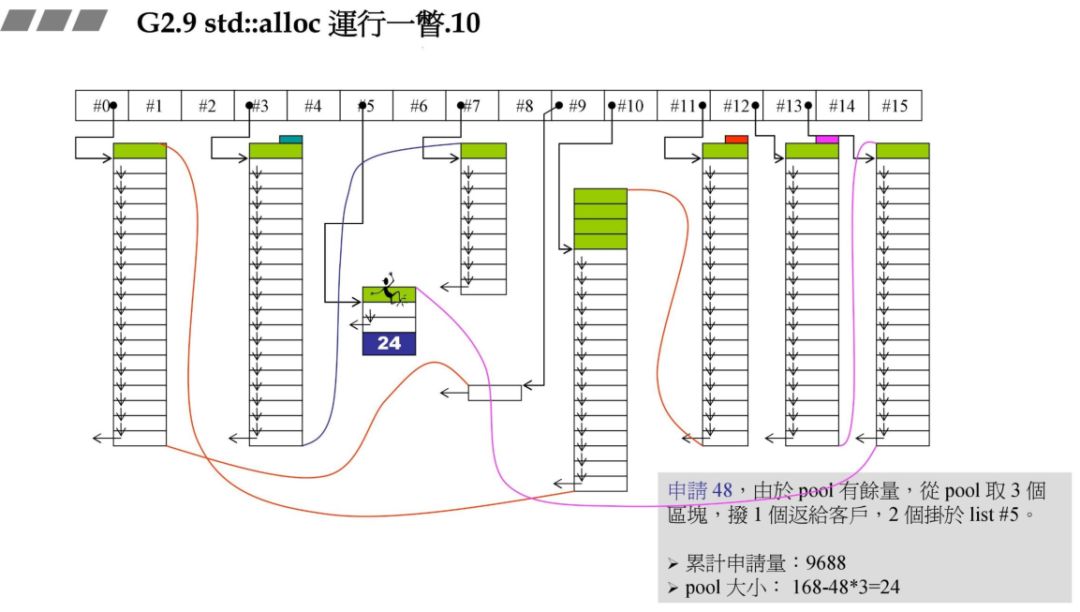
战备池不够了,碎片状态如何处理:
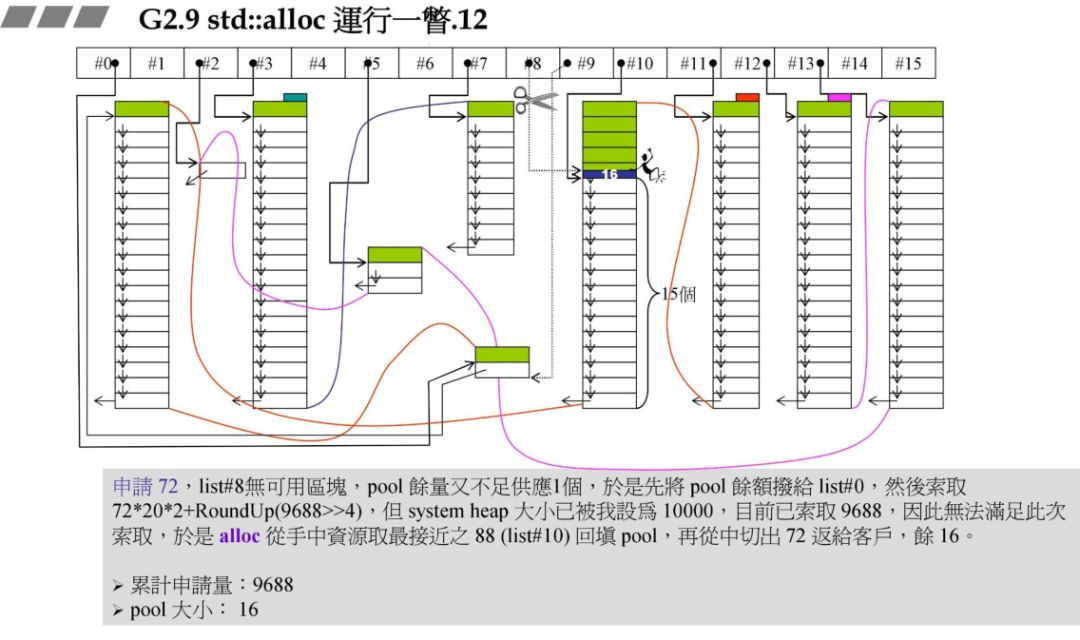
在前面的战备池中还有 24 字节,此时需要 72 字节,战备池中 1 个区块都不能够满足,因此要先解决 24 区字节碎片,再重新往 #8 中充值。
碎片处理,24 字节对应的是 #2,那么把刚才的 24 字节块拉到 #2 即可。
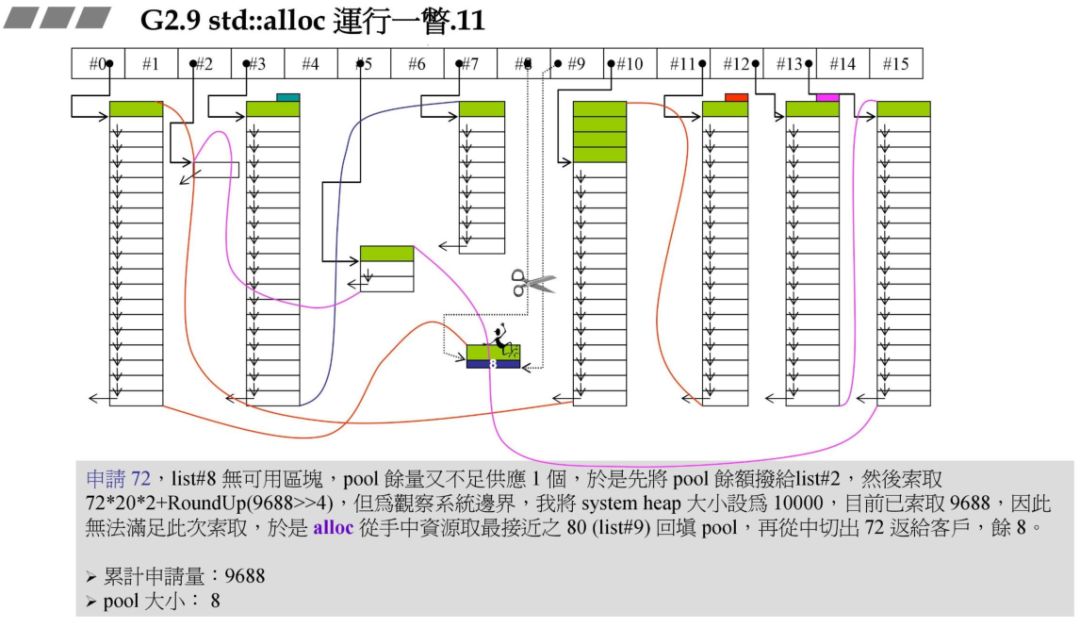
此时要重新往 #8 中充值,同事此时假设系统的 heap 大小为 10000,此时分配的72*20*2+RoundUp(9688>>4 再加上之前的累计申请量,更新后就超过了 10000,资源不够了,那此时就需要从后面最近的链表元素借。在上一个图中我们发现 #9 满足,此时 80 - 72=8,也就是战备池为 8。切除了 72 返回给用户。
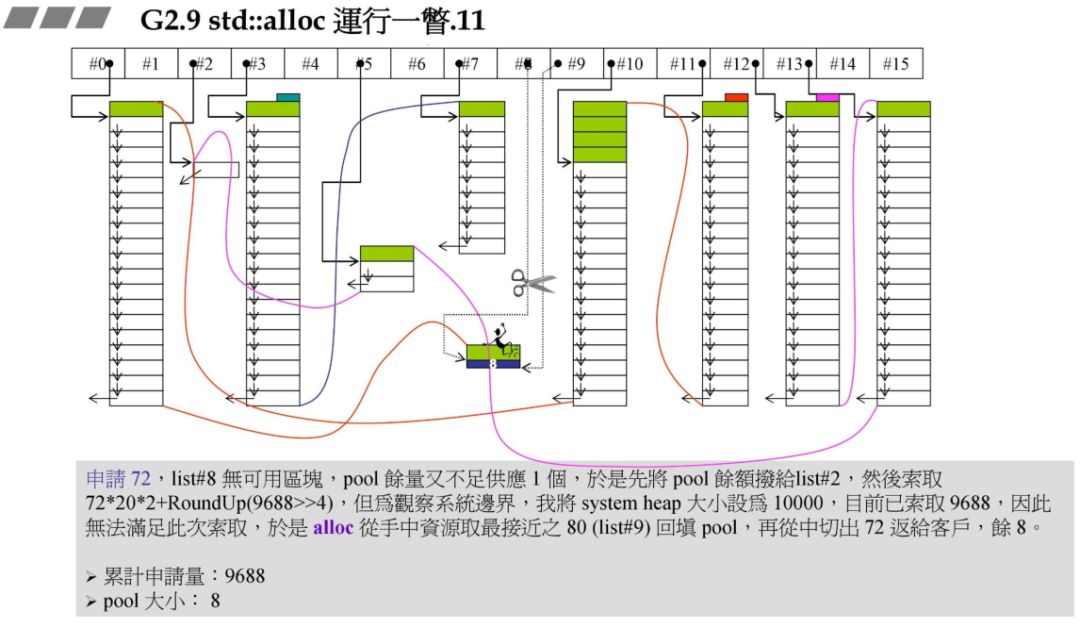
再申请 72 字节原理结合了碎片处理与上面的资源限制处理:
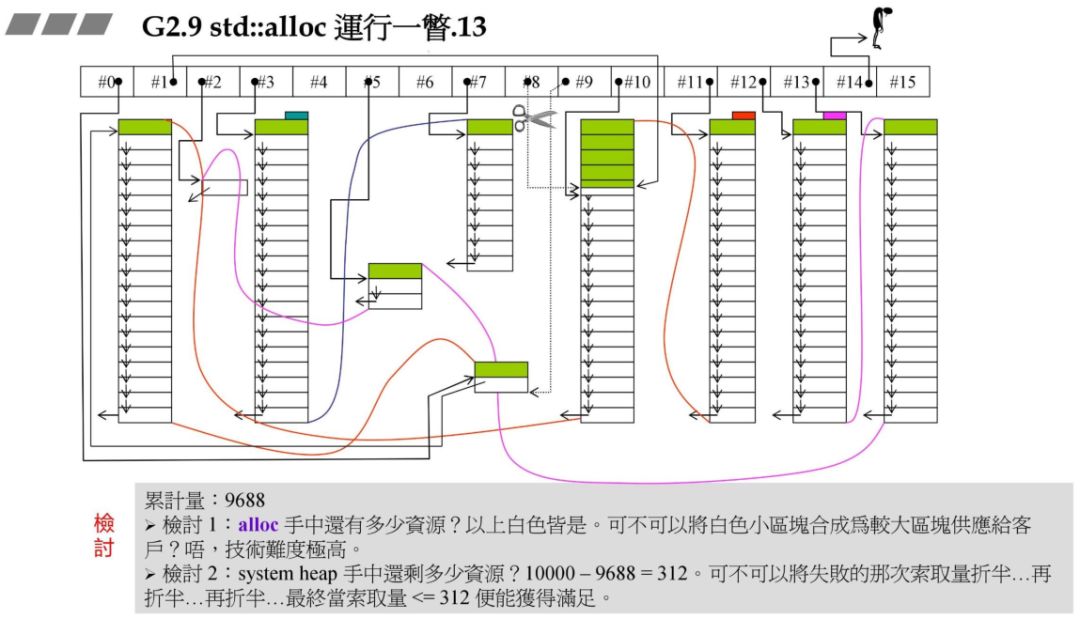
此时申请 120 字节,对应 #14,根据上述原理,此时已经山穷水尽!

山穷水尽了,怎么办,此时给出了两种办法,但是在 GCC 中没有采纳任何作法!
3.std::allloc 源码剖析
3.1 G2.9 与 G4.9 简要对比
侯老师的 ppt 讲解源码是 G2.9,这里我将以 G4.9 自学方式对比课上 G2.9 内容。
在 G2.9 中有 std::alloc 的第一级分配器与第二级分配器,在 G4.9 中只有前面的第二级分配器,因此侯老师在讲解过程中先从第二级分配器讲解,只提及第一级分配器中的设计注意点,下面一起来学习。
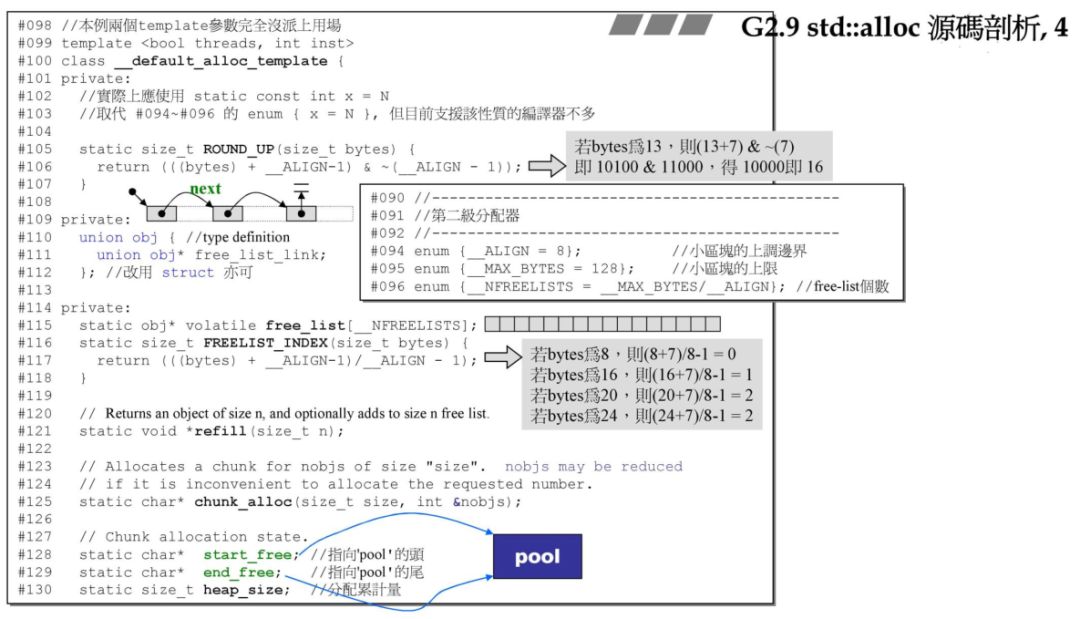
上面是 G2.9 的源码,其中分配器为 __default_alloc_template,一开始默认使用的分配器,在该类中定义了 ROUND_UP 函数,用来将申请内存数量做 8 字节对齐。
定义了 union free_list_link,嵌入式指针,在上一章中我们构建的一个小的分配器中也定义了该联合体,作用类似,该联合体只有一个成员,因此可以使用 struct 代替。
free_list 是一个有 16个obj* 元素的数组,在前面讲过,GCC 2.9 的分配器用一个16 字节数组管理 16 条链表,free_list 便是该管理数组。
refill 和 chunk_alloc 在后面再介绍。start_free 和 end_free 分别指向该内存池的头和尾。中间管理的就是战备池!
这一块对应到 G4.9 中,代码如下:
class __pool_alloc_base{protected:
enum { _S_align = 8 }; enum { _S_max_bytes = 128 }; enum { _S_free_list_size = (size_t)_S_max_bytes / (size_t)_S_align };
union _Obj{union _Obj* _M_free_list_link;char _M_client_data[1]; // The client sees this.};
static _Obj* volatile _S_free_list[_S_free_list_size];
// Chunk allocation state. static char* _S_start_free; static char* _S_end_free; static size_t _S_heap_size;
size_t _M_round_up(size_t __bytes){ return ((__bytes + (size_t)_S_align - 1) & ~((size_t)_S_align - 1)); }
_GLIBCXX_CONST _Obj* volatile* _M_get_free_list(size_t __bytes) throw ();
// Returns an object of size __n, and optionally adds to size __n // free list. void* _M_refill(size_t __n);
// Allocates a chunk for nobjs of size size. nobjs may be reduced // if it is inconvenient to allocate the requested number. char* _M_allocate_chunk(size_t __n, int& __nobjs);};
这个代码在
https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/include/ext/pool_allocator.h
中可以找到,同时可以下载 gcc4.9 版本源码,到 include 里面查找!
除了这一块代码,发现还有 FREELIST_INDEX 代码没有找到对应的,我们再继续扒一下源码:
__pool_alloc_base::_M_get_free_list(size_t __bytes) throw (){ size_t __i = ((__bytes + (size_t)_S_align - 1) / (size_t)_S_align - 1); return _S_free_list + __i;}
可在:
https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/src/c%2B%2B98/pool_allocator.cc
中找到源码实现.对比发现 __i 与上述的 FREELIST_INDEX 相同,但是返回前面加了个 _S_free_list。实际上在 G2.9 中的 alloc 函数中可以找到对应代码,在 G4.9 中把 G2.9中 的这一块进行了封装而已。
分配过程每次分配一大块内存,存到一个 free list 中,下次 client 若再有相同大小的内存要求,就直接从这个 free list 中划出,内存释放时,则直接回收到对应的 free list 中。
为了管理的方便,实际分配的大小都被调整为 8 的倍数,所以有 16 个 free lists,分别为 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128 bytes。例如需要 20 bytes,将会被自动调整为 24 bytes。如果超过了128字节,则需要通过malloc进行分配。
为了节省内存使用,使用 union 结构,这个设计很巧妙,每一个元素(内存区域对象)即可以当作下一个元素的指针,例如后面代码中的 result -> _M_free_list_link,也可以当作该元素的值,例如 *__my_free_list。整个 free lists 的结构便是一串使用后者的元素构成的节点,每个节点的值是使用前者构成的单向链表的首地址。
对比两个版本,可以发现代码这个内存池的头文件,基本没有什么变化,设计大同小异,仅仅函数名称发生了变化!
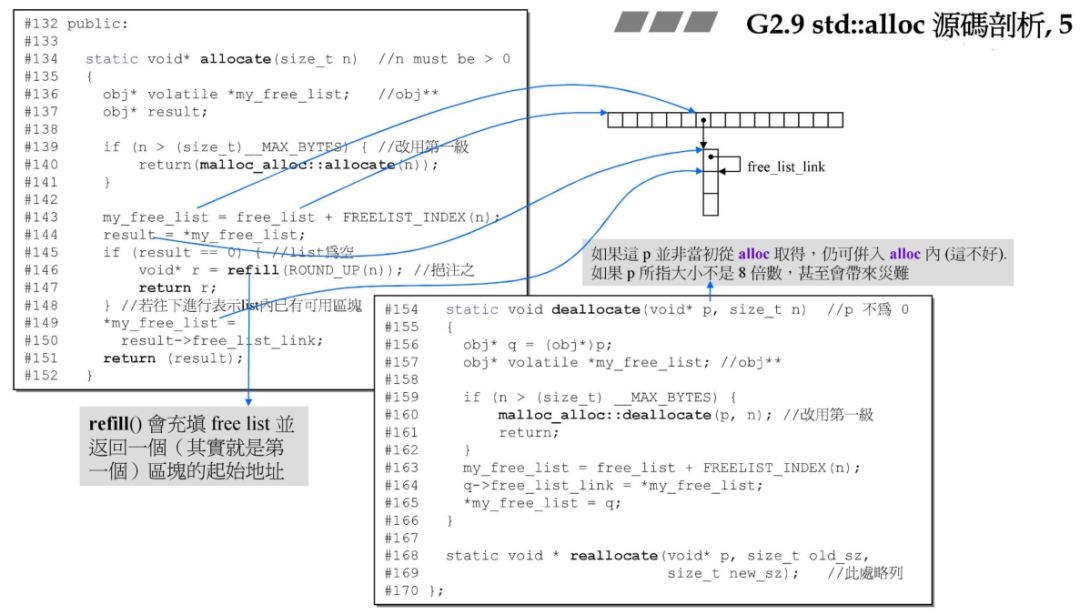
在 G2.9 中的 alloc 与 delloc 还是在 default_alloc_template 类中,而 G4.9 中,则是在 pool_alloc_base 的基类:__pool_alloc 中,一些核心的实现如下:
template<typename _Tp>class __pool_alloc : private __pool_alloc_base{......... pointer allocate(size_type __n, const void* = 0);
void deallocate(pointer __p, size_type __n); };
template<typename _Tp>_Tp*__pool_alloc<_Tp>::allocate(size_type __n, const void*){ pointer __ret = 0; if (__builtin_expect(__n != 0, true)) { if (__n > this->max_size()) std::__throw_bad_alloc();
const size_t __bytes = __n * sizeof(_Tp); if (__bytes > size_t(_S_max_bytes) || _S_force_new > 0) __ret = static_cast<_Tp*>(::operator new(__bytes)); else { _Obj* volatile* __free_list = _M_get_free_list(__bytes); _Obj* __restrict__ __result = *__free_list; if (__builtin_expect(__result == 0, 0)) __ret = static_cast<_Tp*>(_M_refill(_M_round_up(__bytes))); else { *__free_list = __result->_M_free_list_link; __ret = reinterpret_cast<_Tp*>(__result); } if (__ret == 0) std::__throw_bad_alloc(); } } return __ret;}
template<typename _Tp>void__pool_alloc<_Tp>::deallocate(pointer __p, size_type __n){ if (__builtin_expect(__n != 0 && __p != 0, true)) { const size_t __bytes = __n * sizeof(_Tp); if (__bytes > static_cast<size_t>(_S_max_bytes) || _S_force_new > 0) ::operator delete(__p); else { _Obj* volatile* __free_list = _M_get_free_list(__bytes); _Obj* __q = reinterpret_cast<_Obj*>(__p); __q ->_M_free_list_link = *__free_list; *__free_list = __q; } }}
下面来深入分析这两个函数。
3.2 allocate函数
先来看 allocate 函数:
G2.9 分析与 G4. 9分析:在函数的一开始便定义了:
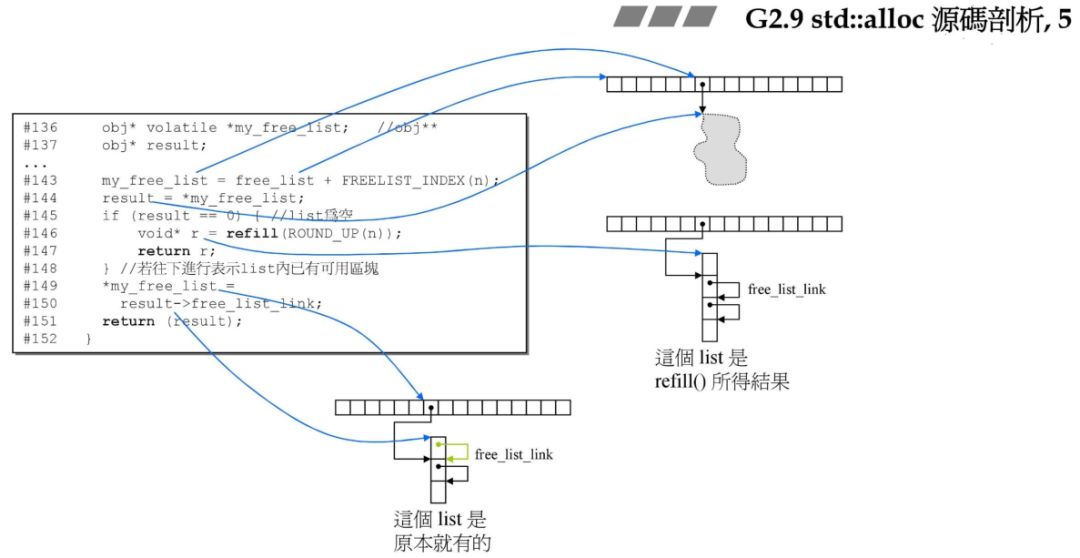
obj* volatile *my_free_list;
结合上图右侧的链表图和上上一张图片内容,my_free_list (对应到 G4.9 就是_free_list) 指向的是 free_list 中 16 个元素中的任何一个,*my_free_list 则取出 free_list 某元素中的值,该值指向一条分配内存的链表。所以 my_free_list 要定义为二级指针。result 则保存分配给用户的一块内存的地址。对应到 G4.9 就是 _ret。
在 G2.9 中前面提到有一级与二级分配器,在这里体现就是:
if (n > (size_t)__MAX_BYTES) { return(malloc_alloc::allocate(n));}
if 成立就调用一级分配器,底层用 malloc 进行分配,而二级则是 if 不成立的情况.
检查用户申请内存块大小,如果大于 __MAX_BYTES(128) 那么将调用malloc_alloc::allocate(),这便是第一级分配器,这在后面分析。
对应到 4.9 中就是:
if (__bytes > size_t(_S_max_bytes) || _S_force_new > 0) __ret = static_cast<_Tp*>(::operator new(__bytes));
在第一节中我们提到 operator new 底层就是 malloc,所以这两个版本没有什么区别。
G4.9 中的 _S_force_new 是一个int类型,与互斥锁相关,可暂时以不用管。
现在假设用户申请内存小于 128 字节,那么将根据用户申请内存大小分配对应的内存,由于内存池使用 free_list 链表管理的,每个 free_lis t链表元素管理不同的内存块大小,这在前面介绍过了。
于是在 G2.9 中:
my_free_list = free_list + FREELIST_INDEX(n);
对应到 G4.9 中就是:
_Obj* volatile* __free_list = _M_get_free_list(__bytes);
定位到该内存块的位置,这时 my_free_list 指向的是管理该内存块的空间的地址,使用 *my_free_list 便可以取到该内存块的地址:
result = *my_free_list;
对应到 G4.9 就是:
_Obj* __restrict__ __result = *__free_list;
然后判断 result 是否为空:
if (result == 0) { void* r = refill(ROUND_UP(n)); return r;}
如果为空,说明对应的 0-128 字节中的某链表(result 指向的链表)没有内存,需要进行充值!
对应到 G4.9 中就是:
if (__builtin_expect(__result == 0, 0)) __ret = static_cast<_Tp*>(_M_refill(_M_round_up(__bytes)));
可以发现原理一样,就是名字换了而已,前面返回的是 r,这里将结果存储到了__ret,最后做返回。
那如果情况正常,需要将该链表中下一个可以使用的空间设置为当前分配给用户空间指向的下一个、在逻辑上连续的空间,最后将result返回给用户:
这里做两个动作:
返回用户区块
移动链表区块指向
*my_free_list = result->free_list_link;return (result);
对应到 G4.9 中就是
*__free_list = __result->_M_free_list_link;__ret = reinterpret_cast<_Tp*>(__result);
前面的代码对应的图解如下:
3.3 deallocate函数
接着就是释放内存函数:
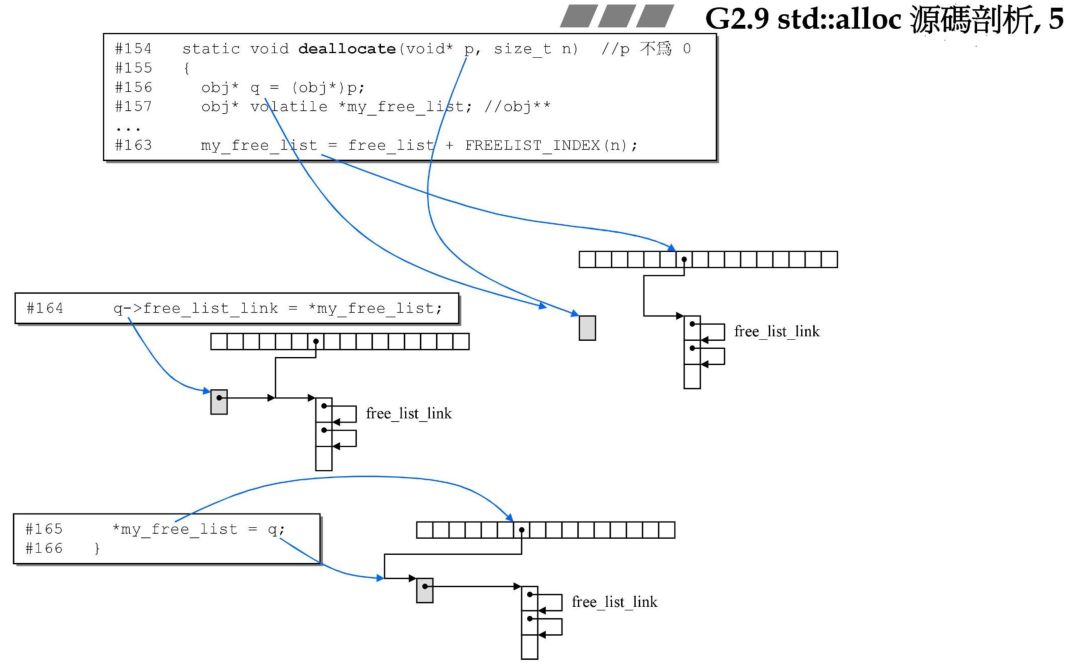
static void deallocate(void *p, size_t n) //p may not be 0{ obj* q = (obj*)p; obj* volatile *my_free_list; //obj** my_free_list;
if (n > (size_t) __MAX_BYTES) { malloc_alloc::deallocate(p, n); return; } my_free_list = free_list + FREELIST_INDEX(n); q->free_list_link = *my_free_list; *my_free_list = q;}
上面是 G2.9 代码,完成工作不难理解,找到需要释放内存的那块空间的地址,进行链表的头插法即可,G4.9 同样道理。
在 allocate 中我们知道一级分配器是 malloc 分配,二级分配器是 free_list 管理,所以释放内存的时候,需要做判断,根据不同分配器来做不同处理,大于 128 字节,直接free释放掉,小于 128 字节,回收到 free_list 中。
对应到 G4.9 中我们知道没有一级分配器,而在 allocate 中是 operator new,底层是 malloc,同样采用 free 释放内存,对应的就是 operator delete,小于 128 字节,也是回收到 free_list 中。
template<typename _Tp>void __pool_alloc<_Tp>::deallocate(pointer __p, size_type __n){ if (__builtin_expect(__n != 0 && __p != 0, true)) { const size_t __bytes = __n * sizeof(_Tp); if (__bytes > static_cast<size_t>(_S_max_bytes) || _S_force_new > 0) ::operator delete(__p); else { _Obj* volatile* __free_list = _M_get_free_list(__bytes); _Obj* __q = reinterpret_cast<_Obj*>(__p); __q ->_M_free_list_link = *__free_list; *__free_list = __q; } }}
上述理解图:
G2.9 中的一级分配器图示:

在最后,第一级分配器叫做:
typedef __malloc_alloc_template<0> malloc_alloc;
在第一级分配器中就是分配调用 malloc,释放调用 free。其中有一个难点就是set_malloc_handler,这个函数设置的是内存分配不够情况下的错误处理函数,这个需要交给用户来管理,首先保存先前的处理函数,然后再将新的处理函数f赋值给 __malloc_alloc_oom_handler,然后返回旧的错误处理函数,这也在下一张图片中会介绍:
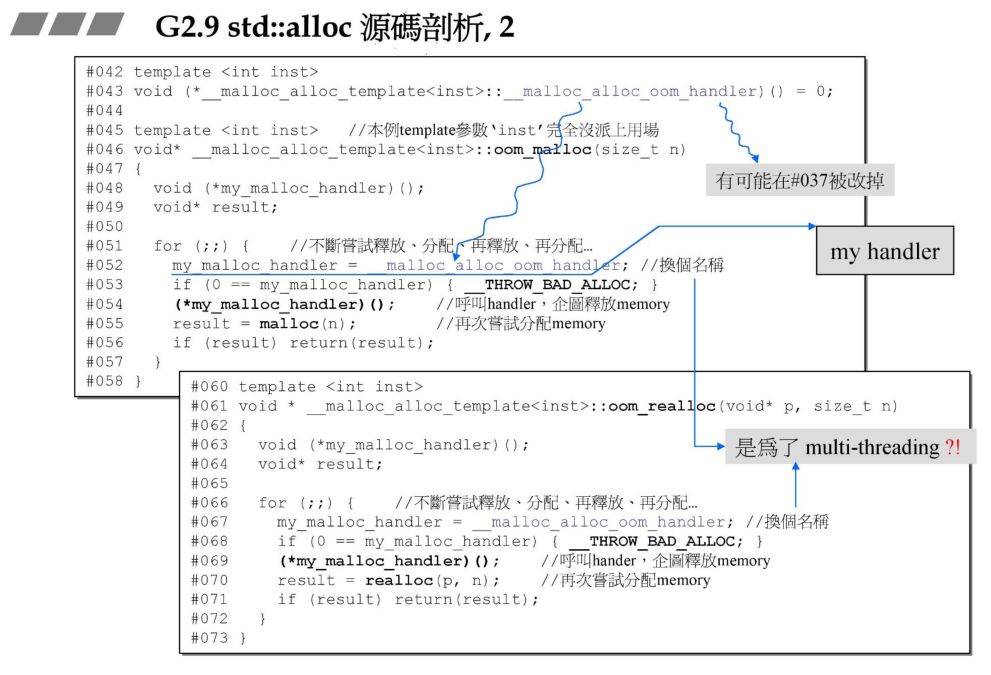
可以看到 oom_malloc 函数内部做的事:该函数不断调用__malloc_alloc_oom_handler 和 malloc 函数,直到内存分配成功才返回。oom_realloc 也是如此.
3.4 chunk_alloc函数
到这里还剩两个函数,一个是前面的充值函数 refill,一个是块分配函数 chunk_alloc 函数。
我们先来看 chunk_alloc 函数:
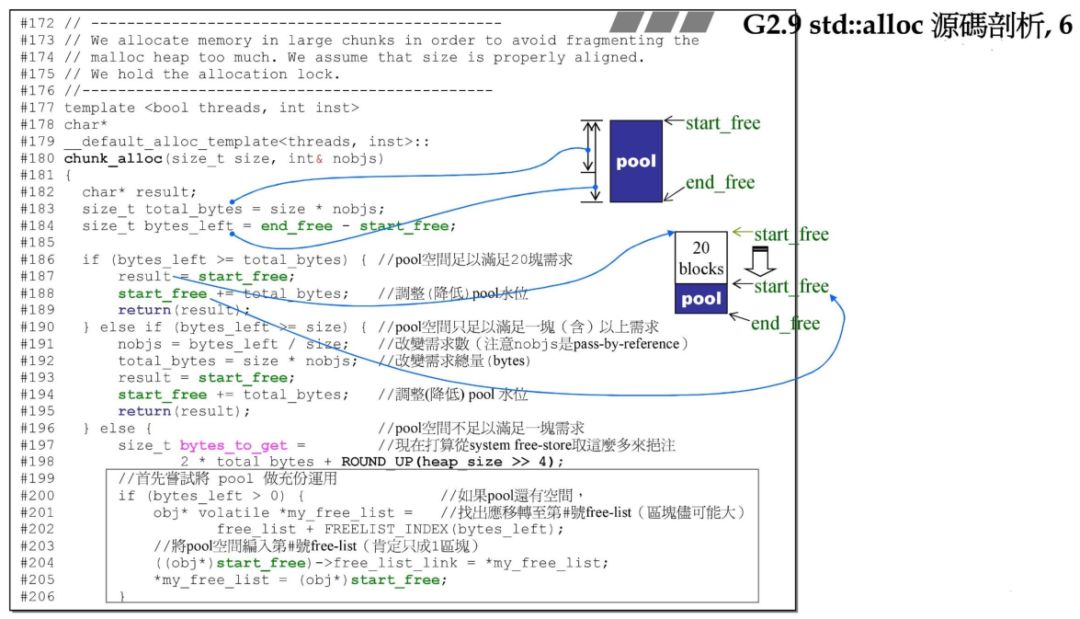
上图是 G2.9 源码,对应的 G4.9 源码实现在:
https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/src/c%2B%2B98/pool_allocator.cc
函数一开始计算了一些需要的值:
char* result;size_t total_bytes = size * nobjs;size_t bytes_left = end_free - start_free;
对应的 G4.9 就是:
char* __result;size_t __total_bytes = __n * __nobjs;size_t __bytes_left = _S_end_free - _S_start_free;
完成累计总量与战备池量的计算!
result 指向分配给用户的内存,total_bytes 为需要分配的内存块的大小,bytes_left 则是当前战备池中剩余的空间大小。
然后判断如果战备池剩余的内存大小多余需要分配的内存块大小,那么将内存池的首地址 start_free 直接赋值给 result,然后将 start_free 指针下移 total_bytes 距离,将当下的 result~start_free 之间的空间返回给用户。
if (bytes_left >= total_bytes) { result = start_free; start_free += total_bytes; return(result);}
对应到 G4.9 就是:
if (__bytes_left >= __total_bytes){ __result = _S_start_free; _S_start_free += __total_bytes; return __result ;}
当然,如果 bytes_left 比 total_bytes小,但是却比 size 大,这意味着不能直接分配 size * nobjs 大小内存给用户,那么可以先看看内存池当下的空间能分配多少个 size 大小的块给用户,然后将该块分配给用户,start_free 指针移动 total_bytes 长度。
else if (bytes_left >= size) { nobjs = bytes_left / size; total_bytes = size * nobjs; result = start_free; start_free += total_bytes; return(result);}
对应到 G4.9 就是:
else if (__bytes_left >= __n){ __nobjs = (int)(__bytes_left / __n); __total_bytes = __n * __nobjs; __result = _S_start_free; _S_start_free += __total_bytes; return __result;}
紧接着就是内存池中有没有多余的内存,有的话,就是碎片,处理工作为:
if (bytes_left > 0) { obj* volatile *my_free_list = free_list + FREELIST_INDEX(bytes_left);
((obj*)start_free)->free_list_link = *my_free_list; *my_free_list = (obj*)start_free;}
对应的 G4.9 就是:
// Try to make use of the left-over piece.if (__bytes_left > 0){ _Obj* volatile* __free_list = _M_get_free_list(__bytes_left); ((_Obj*)(void*)_S_start_free)->_M_free_list_link = *__free_list; *__free_list = (_Obj*)(void*)_S_start_free;}
然后就是不断地获取内存块,将这些内存块不断切割用链表连接起来,递归这些过程:
size_t bytes_to_get = 2 * total_bytes + ROUND_UP(heap_size >> 4);start_free = (char*)malloc(bytes_to_get); if (0 == start_free) { int i; obj* volatile *my_free_list, *p;
//Try to make do with what we have. That can't //hurt. We do not try smaller requests, since that tends //to result in disaster on multi-process machines. for (i = size; i <= __MAX_BYTES; i += __ALIGN) { my_free_list = free_list + FREELIST_INDEX(i); p = *my_free_list; if (0 != p) { *my_free_list = p -> free_list_link; start_free = (char*)p; end_free = start_free + i; return(chunk_alloc(size, nobjs)); //Any leftover piece will eventually make it to the //right free list. } } end_free = 0; //In case of exception. start_free = (char*)malloc_alloc::allocate(bytes_to_get); //This should either throw an exception or //remedy the situation. Thus we assume it //succeeded.} heap_size += bytes_to_get; end_free = start_free + bytes_to_get; return(chunk_alloc(size, nobjs));
对应的 G4.9 就是:
size_t __bytes_to_get = (2 * __total_bytes + _M_round_up(_S_heap_size >> 4));__try{ _S_start_free = static_cast<char*>(::operator new(__bytes_to_get));}__catch(const std::bad_alloc&){ // Try to make do with what we have. That can't hurt. We // do not try smaller requests, since that tends to result // in disaster on multi-process machines. size_t __i = __n; for (; __i <= (size_t) _S_max_bytes; __i += (size_t) _S_align) { _Obj* volatile* __free_list = _M_get_free_list(__i); _Obj* __p = *__free_list; if (__p != 0) { *__free_list = __p->_M_free_list_link; _S_start_free = (char*)__p; _S_end_free = _S_start_free + __i; return _M_allocate_chunk(__n, __nobjs); // Any leftover piece will eventually make it to the // right free list. } } // What we have wasn't enough. Rethrow. _S_start_free = _S_end_free = 0; // We have no chunk. __throw_exception_again;}_S_heap_size += __bytes_to_get;_S_end_free = _S_start_free + __bytes_to_get;return _M_allocate_chunk(__n, __nobjs);
3.5 refill函数

就是前面提到了32*20*2与累积量,战备池中剩余量计算函数,不断为战备池充值。
对应到 G4.9 就是:
void*__pool_alloc_base::_M_refill(size_t __n){ int __nobjs = 20; char* __chunk = _M_allocate_chunk(__n, __nobjs); _Obj* volatile* __free_list; _Obj* __result; _Obj* __current_obj; _Obj* __next_obj;
if (__nobjs == 1) return __chunk; __free_list = _M_get_free_list(__n);
// Build free list in chunk. __result = (_Obj*)(void*)__chunk; *__free_list = __next_obj = (_Obj*)(void*)(__chunk + __n); for (int __i = 1; ; __i++) { __current_obj = __next_obj; __next_obj = (_Obj*)(void*)((char*)__next_obj + __n); if (__nobjs - 1 == __i) { __current_obj->_M_free_list_link = 0; break; } else __current_obj->_M_free_list_link = __next_obj; } return __result;}
源码见:
https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/src/c%2B%2B98/pool_allocator.cc
4. std::alloc概念大整理
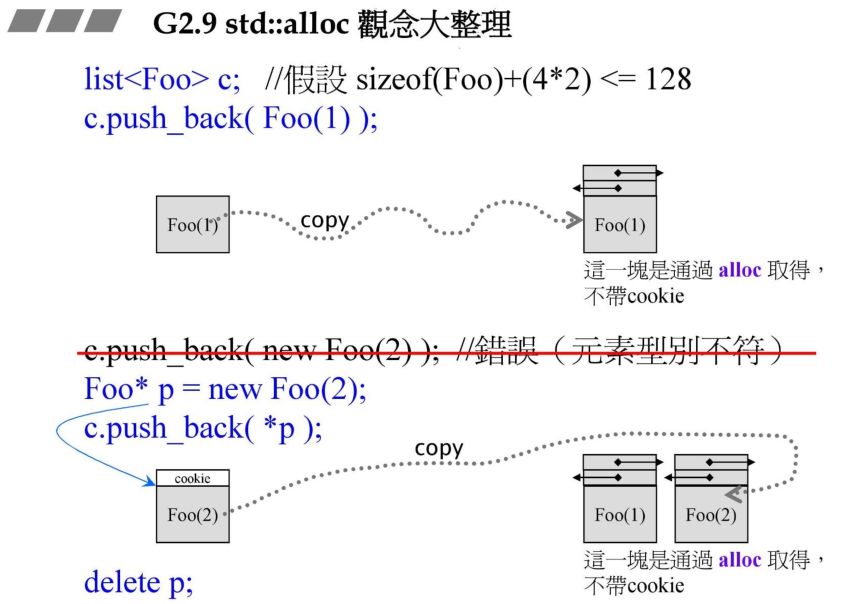
这里第一个是采用 list 容器,容器内会调用 alloc 的 allocate 进行分配,由于小于 128 字节,会在 heap 上得到不带 cookie 的内存,再把这一块内存放进栈中。
同样的下面采用 new 关键字,底层调用 malloc,这样得到就是带 cookie,然后在放进栈中。
5.std::alloc批斗大会
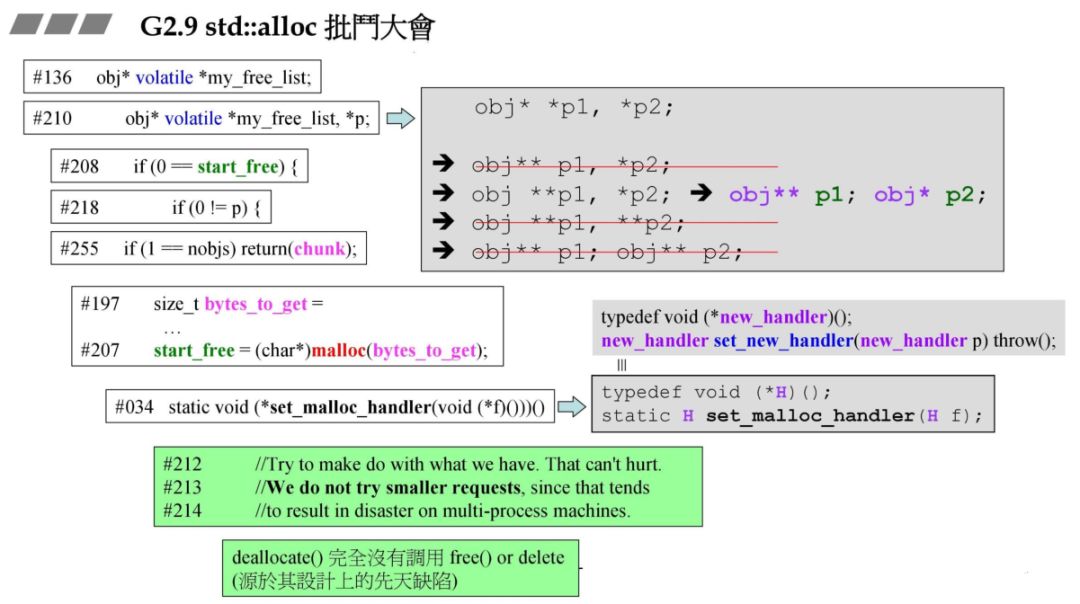
这里谈到了几种不好的设计:
obj* *_free_list,*p容易使人误解为指针的指针,实际上只等价于右边的定义,_free_list是指针的指针,而p则是指针。malloc 分配,不可重载,可以采用 operator new 来替代。
static void 一大堆函数指针嵌套太难理解。
值得学习的地方
if 判断将值放在变量前面,这样可以避免少写等号,编译器不报错问题。
6.C 实现
最后,由于 G2.9 的代码变量基本是 static,所以非常容易转为 C,侯老师给出了设计:

以上是关于std 源码剖析及 C++ 内存管理的主要内容,如果未能解决你的问题,请参考以下文章
MYSQL深潜 - 剖析Performance Schema内存管理
MySQL深潜|剖析Performance Schema内存管理