ArrayPool 源码解读之 byte[] 也能池化?
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ArrayPool 源码解读之 byte[] 也能池化?相关的知识,希望对你有一定的参考价值。
一:背景
1. 讲故事
最近在分析一个 dump 的过程中发现其在 gen2 和 LOH 上有不少size较大的free,仔细看了下,这些free生前大多都是模板引擎生成的html片段的byte[]数组,当然这篇我不是来分析dump的,而是来聊一下,当托管堆有很多length较大的 byte[] 数组时,如何让内存利用更高效,如何让gc老先生压力更小。
不知道大家有没有发现在 .netcore 中增加了不少池化对象的东西,比如:ArrayPool,ObjectPool 等等,确实在某些场景下还是特别实用的,所以有必要对其进行较深入的理解。
二:ArrayPool 源码分析
1. 一图胜千言
在我花了将近一个小时的源码阅读之后,我画了一张 ArrayPool 的池化图,所谓:一图在手,天下我有 。
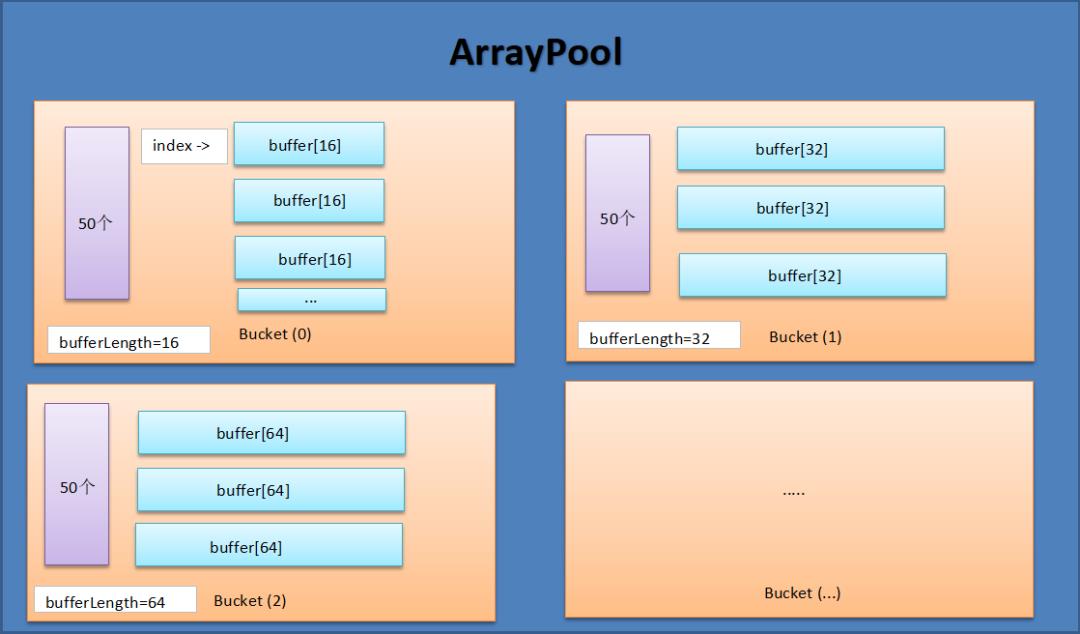
有了这张图,接下来再聊几个概念并配上相应源码,我觉得应该就差不多了。
2. 池化的架构分级是什么样的?
ArrayPool 是由若干个 Bucket 组成, 而 Bucket 又由若干个 buffer[] 数组组成, 有了这个概念之后,再配一下代码。
public abstract class ArrayPool<T>
{
public static ArrayPool<T> Create()
{
return new ConfigurableArrayPool<T>();
}
}
internal sealed class ConfigurableArrayPool<T> : ArrayPool<T>
{
private sealed class Bucket
{
internal readonly int _bufferLength;
private readonly T[][] _buffers;
private int _index;
}
private readonly Bucket[] _buckets; //bucket数组
}
3. 为什么每一个 bucket 里都有 50 个 buffer[]
这个问题很好回答,初始化时做了 maxArraysPerBucket=50 设定,当然你也可以自定义,具体参考如下代码:
internal sealed class ConfigurableArrayPool<T> : ArrayPool<T>
{
internal ConfigurableArrayPool() : this(1048576, 50)
{
}
internal ConfigurableArrayPool(int maxArrayLength, int maxArraysPerBucket)
{
int num = Utilities.SelectBucketIndex(maxArrayLength);
Bucket[] array = new Bucket[num + 1];
for (int i = 0; i < array.Length; i++)
{
array[i] = new Bucket(Utilities.GetMaxSizeForBucket(i), maxArraysPerBucket, id);
}
_buckets = array;
}
}
4. bucket 中 buffer[].length 为什么依次是 16,32,64 ...
框架做了默认假定,第一个bucket中的 buffer[].length=16, 后续 bucket 中的 buffer[].length 都是 x2 累计,涉及到代码就是 GetMaxSizeForBucket() 方法,参考如下:
internal ConfigurableArrayPool(int maxArrayLength, int maxArraysPerBucket)
{
Bucket[] array = new Bucket[num + 1];
for (int i = 0; i < array.Length; i++)
{
array[i] = new Bucket(Utilities.GetMaxSizeForBucket(i), maxArraysPerBucket, id);
}
}
internal static int GetMaxSizeForBucket(int binIndex)
{
return 16 << binIndex;
}
5. 初始化时 bucket 到底有多少个?
其实在上图中我也没有给出 bucket 到底有多少个,那到底是多少个呢????????????? ,当我阅读完源码之后,这算法还挺有意思的。
先说一下结果吧,默认 17 个 bucket,你肯定会好奇怎么算的?先说下两个变量:
maxArrayLength=1048576 = 2的20次方
buffer.length= 16 = 2的4次方
最后的算法就是取次方的差值:bucket[].length= 20 - 4 + 1 = 17,换句话说最后一个 bucket 下的 buffer[].length=1048576,详细代码请参考 SelectBucketIndex() 方法。
internal sealed class ConfigurableArrayPool<T> : ArrayPool<T>
{
internal ConfigurableArrayPool(): this(1048576, 50)
{ }
internal ConfigurableArrayPool(int maxArrayLength, int maxArraysPerBucket)
{
int num = Utilities.SelectBucketIndex(maxArrayLength);
Bucket[] array = new Bucket[num + 1];
for (int i = 0; i < array.Length; i++)
{
array[i] = new Bucket(Utilities.GetMaxSizeForBucket(i), maxArraysPerBucket, id);
}
_buckets = array;
}
internal static int SelectBucketIndex(int bufferSize)
{
return BitOperations.Log2((uint)(bufferSize - 1) | 0xFu) - 3;
}
}
到这里我相信你对 ArrayPool 的池化架构思路已经搞明白了,接下来看下如何申请和归还 buffer[]。
三:如何申请和归还
既然 buffer[] 做了颗粒化,那就应该好借好还,反应到代码上就是 Rent() 和 Return() 方法,为了方便理解,上代码说话:
class Program
{
static void Main(string[] args)
{
var arrayPool = ArrayPool<int>.Create();
var bytes = arrayPool.Rent(10);
for (int i = 0; i < bytes.Length; i++) bytes[i] = 10;
arrayPool.Return(bytes);
Console.ReadLine();
}
}


有了代码和图之后,再稍微捋一下流程。
从 ArrayPool 中借一个
byte[10]大小的数组,为了节省内存,先不备货,临时生成一个byte[].size=16的数组出来,简化后的代码如下,参考if (flag)处:
internal T[] Rent()
{
T[][] buffers = _buffers;
T[] array = null;
bool lockTaken = false;
bool flag = false;
try
{
if (_index < buffers.Length)
{
array = buffers[_index];
buffers[_index++] = null;
flag = array == null;
}
}
if (flag)
{
array = new T[_bufferLength];
}
return array;
}
这里有一个坑,那就是你以为借了 byte[10],现实给你的是 byte[16],这里稍微注意一下。
当用 ArrayPool.Return 归还
byte[16]时, 很明显看到它落到了第一个bucket的第一个buffer[]上,参考如下简化后的代码:
internal void Return(T[] array)
{
if (_index != 0)
{
_buffers[--_index] = array;
}
}
这里也有一个值得注意的坑,那就是还回去的 byte[16] 里面的数据默认是不会清掉的,从上面的代码也是可以看出来的,要想做清理,需要在 Return 方法中指定 clearArray=true,参考如下代码:
public override void Return(T[] array, bool clearArray = false)
{
int num = Utilities.SelectBucketIndex(array.Length);
if (num < _buckets.Length)
{
if (clearArray)
{
Array.Clear(array, 0, array.Length);
}
_buckets[num].Return(array);
}
}
四:总结
学习这其中的 池化架构 思想,对平时项目开发还是能提供一些灵感的,其次对那些一次性使用 byte[] 的场景,用池化是个非常不错的方法,这也是我对朋友dump分析后提出的一个优化思路。
END
工作中的你,是否已遇到 ...
1. CPU爆高
2. 内存暴涨
3. 资源泄漏
4. 崩溃死锁
5. 程序呆滞
等紧急事件,全公司都指望着你能解决... 危难时刻才能展现你的技术价值,作为专注于.NET高级调试的技术博主,欢迎微信搜索: 一线码农聊技术,免费协助你分析Dump文件,希望我能将你的踩坑经验分享给更多的人。

以上是关于ArrayPool 源码解读之 byte[] 也能池化?的主要内容,如果未能解决你的问题,请参考以下文章
ElasticSearchEs 源码之 AsyncSearchMaintenanceService 源码解读
ElasticSearchEs 源码之 CacheService 源码解读
ElasticSearchEs 源码之 CcrRestoreSourceService 源码解读