爬虫学习笔记(二十三)—— Appium+Mitmproxy
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习笔记(二十三)—— Appium+Mitmproxy相关的知识,希望对你有一定的参考价值。
文章目录
一、工具
1.1、手机投屏工具
- scrcpy投屏演示
- usb连接电脑
- cmd中 scrcpy启动投屏工具
- 下载地址:https://github.com/Genymobile/scrcpy/releases
- 使用方法:https://blog.csdn.net/was172/article/details/99705855
1.2、fiddler、mitmproxy和APPium
- fiddler抓包
- 模拟器/手机与电脑同一网络
- 设置手机代理,安装证书
- 打开fiddler
- mitmproxy抓取数据
- 模拟器/手机与电脑同一网络
- 设置手机代理,安装证书
- mitm命令开启工具
- appium手机自动化
- usb连接电脑
- 开发者模式
- usb调试打开
二、案例:火山急速版视频抓取
2.1、视频链接
以下有两种方式可以找到我们需要的视频的url:
1、Fiddler抓包:

JSON数据中找到video里面的download_url或url_list,这个字段下面有我们需要的视频下载url
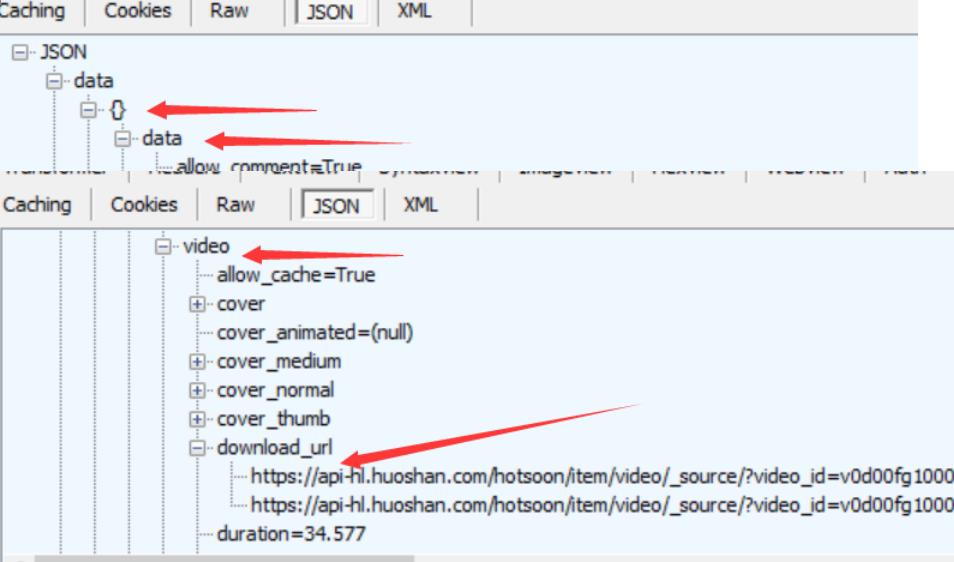
2、mitmproxy
mitmproxy抓包时在response标签往下滚动可以找到show full content选项,显示完整的响应体


这两种方式都可以对模拟器中的请求进行抓取,注意要在模拟器网络中选择相对应的端口号,例如在我的电脑环境中,使用fiddler抓包端口号是8888,使用mitmproxy抓包端口号是8080
2.2、代码实现
2.2.1、Appium自动化翻页
1、建立连接
from appium import webdriver
import time
desired_caps = {
'platformName': 'android', #被测的手机是安卓
'platformVersion': '7.1.2', #手机安卓版本
'deviceName': 'BieYa', #设备名,安卓手机可以随意填写
'appPackage': 'com.ss.android.ugc.livelite', #启动APP package名称 shell用查看app应用名
'appActivity': 'com.ss.android.ugc.live.main.MainActivity', #启动Activity名称
'unicodeKeyboard': True, #使用自带输入法,输入中文是填true
'resetKeyboard': True, #执行完程序恢复原来输入法 经常来不及执行需要手动恢复
'noReset': True, #不要重置APP 重要参数 务必填True
'newCommandTimeout': 6000, #固定写
'automationName': 'UiAutomator2'
}
#连接APPium Server,初始化自动环境 建立连接,根据参数建立连接 安装
driver = webdriver.Remote('http://127.0.0.1:4723/wd/hub',desired_caps)
#设置缺省等待时间
driver.implicitly_wait(5)
2、滑动界面
def swipUp(driver,t=1500):
'''向上滑动屏幕'''
size = driver.get_window_size()
x = size['width']*0.5 #x坐标
y_start = size['height']*0.75 #起始点y坐标
y_end = size['height']*0.25 #终点y坐标
driver.swipe(x,y_start,x,y_end,t)
while True:
swip = input('是否滑动屏幕(y/n)?')
if swip == 'y':
for i in range(5):
swipUp(driver)
else:
break
driver.quit()
2.2.2、mitmproxy提取视频url
提取视频url放入文本中
from mitmproxy import http
import re
import redis
redisconn = redis.StrictRedis(
host='127.0.0.1',
port='6379',
db=0
)
def response(flow: http.HTTPFlow):
'''获取视频url'''
# "share_title": "「熊熊轻奢男装」
if flow.request.url.startswith('https://hotsoon-hl.snssdk.com') and '/hotsoon/feed/' in flow.request.path and 'vquality=normal&watermark' in flow.request.path:
#获取视频title
titles = re.findall(b'"share_title":"「(.*?)」',flow.response.content)
titles = [t.decode() for t in titles]
# #获取视频的url
video_urls = re.findall(rb'"download_url":\\["(.*?)",',flow.response.content)
video_urls = [u.decode().replace('\\\\u0026', '&') for u in video_urls]
title_video = list(zip(titles,video_urls))
print(title_video)
#存进redis数据库
if title_video:
redisconn.hmset('title_video',title_video)
2.2.3、下载视频
import os
import requests
import time
import redis
redisconn = redis.StrictRedis(
host='127.0.0.1',
port='6379',
db=0
)
count = 0
def get_urls():
video_dict = {}
keys = redisconn.hkeys('title_video')
for title,video_url in keys:
video_dict[title] = video_url
return video_dict
def get_video(video_dict):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
for title,video_url in video_dict.items():
res = requests.get(video_url,headers=headers,verify=False)
global count
count+=1
print(f'[{count}] 正在下载视频')
if not os.path.exists('video'):
os.mkdir('video')
filename = 'video/'+title+'.mp4'
try:
with open(filename,'wb') as f:
f.write(res.content)
except:
pass
while True:
time.sleep(5)
video_dict = get_urls()
if not video_dict:
break
get_video(video_dict)
以上是关于爬虫学习笔记(二十三)—— Appium+Mitmproxy的主要内容,如果未能解决你的问题,请参考以下文章