sqlldr加载19c pdb最佳实践
Posted P10ZHUO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sqlldr加载19c pdb最佳实践相关的知识,希望对你有一定的参考价值。
sqlldr加载19c pdb最佳实践
背景
sqlldr历史悠久,从oracle 7开始提供数据加载得功能。那么在高本版,甚至19c上面sqlldr还能否使用哪?
某客户就有这种需求,经常需要把excel里面的数据导入到数据库表里面,那么sqlldr就成为不二之选。下面看下具体的使用和注意事项。
sqlldr帮助文件
[oracle@oracle11g ~]$ sqlldr
SQL*Loader: Release 11.2.0.4.0 - Production on Mon Aug 30 12:55:16 2021
Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
Usage: SQLLDR keyword=value [,keyword=value,...]
Valid Keywords:
userid -- ORACLE username/password oracle用户名/密码
control -- control file name 控制文件名
log -- log file name 日志文件名
bad -- bad file name 错误文件名
data -- data file name 数据文件名
discard -- discard file name 废弃文件名
discardmax -- number of discards to allow (Default all) 允许废弃的文件的数目(默认全部)
skip -- number of logical records to skip (Default 0) 要跳过的逻辑记录的数目(默认0)
load -- number of logical records to load (Default all) 要加载的逻辑记录的数目(默认全部)
errors -- number of errors to allow (Default 50)允许的错误的数目(默认50)
rows -- number of rows in conventional path bind array or between direct path data saves (Default: Conventional path 64, Direct path all) 常规路径绑定数组中或直接路径保存数据间的行数(常规路径默认64,直接路径默认全部)
bindsize -- size of conventional path bind array in bytes (Default 256000) 常规路径绑定绑定数组的大小(默认256000,单位字节,256K)
silent -- suppress messages during run (header,feedback,errors,discards,partitions)运行过程中隐藏信息(标题,反馈,错误,废弃,分区)
direct -- use direct path (Default FALSE)使用直接路径(默认false)
parfile -- parameter file: name of file that contains parameter specifications参数文件:包含参数说明的文件的名称
parallel -- do parallel load (Default FALSE)执行并行加载(默认false)
file -- file to allocate extents from 要从以下对象中分配区的文件
skip_unusable_indexes -- disallow/allow unusable indexes or index partitions (Default FALSE)不允许/允许使用无用的索引(默认false)
skip_index_maintenance -- do not maintain indexes, mark affected indexes as unusable (Default FALSE)不维护索引,将受到影响的索引标记为失效(默认false)
commit_discontinued -- commit loaded rows when load is discontinued (Default FALSE)
readsize -- size of read buffer (Default 1048576)
external_table -- use external table for load; NOT_USED, GENERATE_ONLY, EXECUTE (Default NOT_USED)
columnarrayrows -- number of rows for direct path column array (Default 5000)
streamsize -- size of direct path stream buffer in bytes (Default 256000)直接路径流缓冲区的大小(默认25600,单位字节)
multithreading -- use multithreading in direct path 在直接路径中使用多线程
resumable -- enable or disable resumable for current session (Default FALSE)
resumable_name -- text string to help identify resumable statement
resumable_timeout -- wait time (in seconds) for RESUMABLE (Default 7200)
date_cache -- size (in entries) of date conversion cache (Default 1000)
no_index_errors -- abort load on any index errors (Default FALSE)
PLEASE NOTE: Command-line parameters may be specified either by
position or by keywords. An example of the former case is 'sqlldr
scott/tiger foo'; an example of the latter is 'sqlldr control=foo
userid=scott/tiger'. One may specify parameters by position before
but not after parameters specified by keywords. For example,
'sqlldr scott/tiger control=foo logfile=log' is allowed, but
'sqlldr scott/tiger control=foo log' is not, eve
n though the
position of the parameter ‘log’ is correct.
sqlldr结构
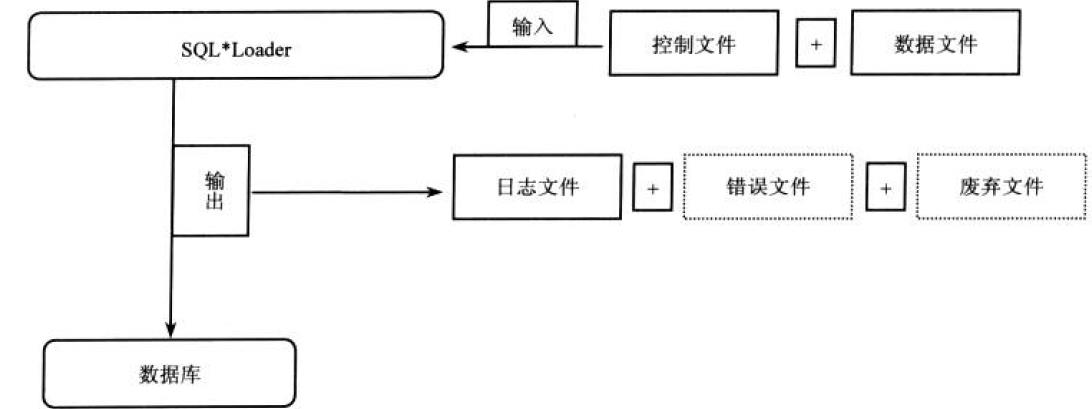
sqlldr–数据文件
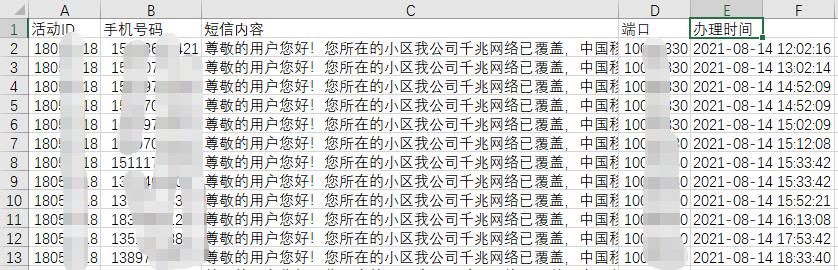
一般会导出一个excel文件,或者csv文件,类似如下:

其中的内容如下:
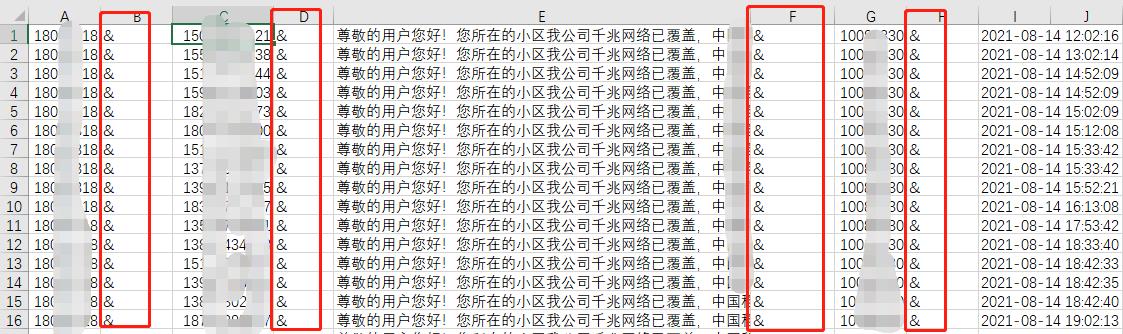
为了后面的控制文件好些,一般插入个分隔符,如下:
然后保存为txt文件,保存的时候要注意,如下格式:
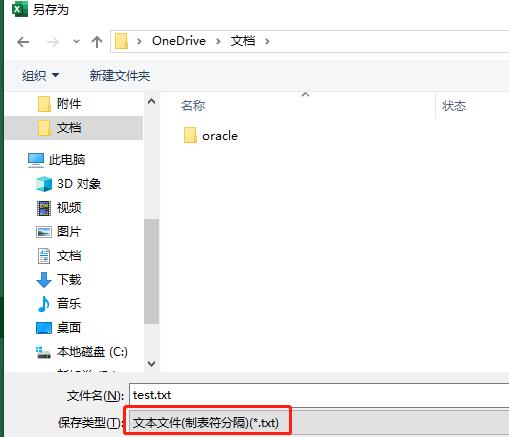
不能保存为Unicode文本,那样会乱码。
然后把这个txt文件上传到服务器即可,分隔符为自定义的&。
也可以直接让他导出为txt文件,省去前面步骤。
sqlldr–控制文件
LOAD DATA
INFILE '/home/oracle/t1.txt'
TRUNCATE INTO TABLE zhuo.t1
FIELDS TERMINATED BY '&' OPTIONALLY ENCLOSED BY '"'
trailing nullcols
(id,
phone,
message,
port,
created date 'yyyy-mm-dd hh24:mi:ss'
)
解析:
1、最上面那部分是标准语法,控制文件一般都以此开头LOAD DATA。
2、中间部分
INFILE:表示数据文件位置,如果值为*,表示数据就在控制文件中。单独的数据文件,写具体的路径即可。
INTO TABLE tbl_name:tbl_name即数据要加载到的目标表,该表在你执行sqlldr命令之前必须已经创建。
INTO前有好几个参数:
INSERT:向表中插入数据,表必须为空,如果不为空的话,执行sqlldr就会报错,默认也是insert参数。
APPEND:向表中追加数据,不管表重是否有数据。
REPLACE:替换表中数据,相当于先delete表中全部数据,然后再INSERT。
TRUNCATE:类似REPLACE,只不过这里不是用DELETE方式删除表中数据,而是通过TRUNCATE的方式删除,然后再INSERT。
3、FILEDS TERMINATED BY ‘&’,当然也可以换成其他的。
OPTIONALLY ENCLOSED BY ‘"’,待加载的数据中包含分隔符怎么办?参数指名定界符,此处为双引号。然待加载的数据里面有双引号,不会消失。
4、(id,phone,。。。)要插入的表的列名,这里需要注意的是列名要与表中列名完全相同,列的顺序可以与表重列顺序不同,但是必须与数据部分的列一一对应。
sqlldr加载数据
初始化环境
连接pdb,默认监听里面就会有pdb的服务名,直接使用连接即可。
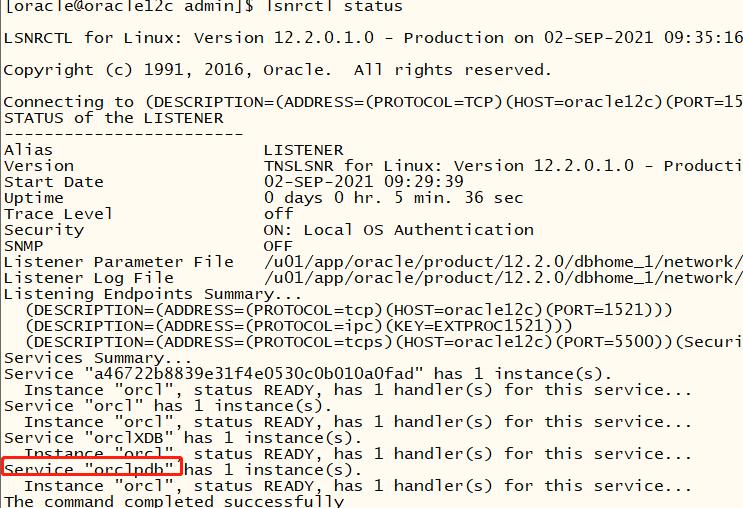
添加客户端连接串:
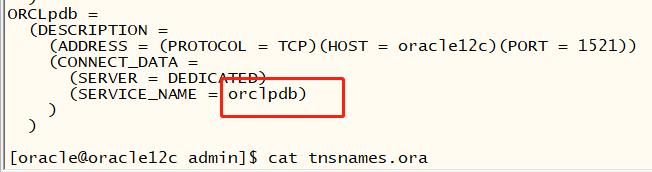
直接连接:
[oracle@oracle12c admin]$ sqlplus sys/oracle@orclpdb as sysdba
SQL*Plus: Release 12.2.0.1.0 Production on Thu Sep 2 09:43:39 2021
Copyright (c) 1982, 2016, Oracle. All rights reserved.
Connected to:
Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production
SQL> show pdbs;
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
3 ORCLPDB READ WRITE NO
SQL> show con_name;
CON_NAME
------------------------------
ORCLPDB
SQL> show user;
USER is "SYS"
SQL> conn zhuo/zhuo@orclpdb
Connected.
SQL> show user;
USER is "ZHUO"
SQL> show con_name;
CON_NAME
------------------------------
ORCLPDB
创建目标表:
SQL> create table t1(id varchar2(10),phone varchar2(11),message varchar2(500),port varchar2(10),created date);
Table create
SQL> create index idx_phone on t1(phone);
Index created.
执行导入
创建控制文件如下:
[oracle@oracle12c ~]$ cat t1.ctl
LOAD DATA
INFILE '/home/oracle/t1.txt'
TRUNCATE INTO TABLE zhuo.t1
FIELDS TERMINATED BY '&' OPTIONALLY ENCLOSED BY '"'
trailing nullcols
(id,
phone,
message,
port,
created date 'yyyy-mm-dd hh24:mi:ss'
)
这里注意,对于created列,我们指定了日期格式,并进行了转换,这个格式一定要与数据文件中日期格式相符,不然日期格式转换时会报错并导致数据加载失败。报错:ORA-01843: not a valid month
意思就是源文件的日期格式为:2021-08-14 12:02:16。那么后面的转化格式要一致,为’yyyy-mm-dd hh24:mi:ss’。而不能是’yyyymmdd hh24:mi:ss’
date类型的也可以这样写,意思就是直接在控制文件中转化:created "to_date(:created,‘yyyy-mm-dd hh24:mi:ss’)"
控制文件可以为:
LOAD DATA
INFILE '/home/oracle/test.txt'
TRUNCATE INTO TABLE zhuo.t1
FIELDS TERMINATED BY '&' OPTIONALLY ENCLOSED BY '"'
trailing nullcols
(id,
phone,
message,
port,
created "to_date(:created,'yyyy-mm-dd hh24:mi:ss')"
)
执行加载:
sqlldr userid=system/oracle@orclpdb control=/home/oracle/t1.ctl log=/home/oracle/t1.log
加载报错,日志里面有如下报错:
Record 1: Rejected - Error on table ZHUO.T1, column MESSAGE.
Field in data file exceeds maximum length
Record 2: Rejected - Error on table ZHUO.T1, column MESSAGE.
Field in data file exceeds maximum length
Record 3: Rejected - Error on table ZHUO.T1, column MESSAGE.
Field in data file exceeds maximum length
Record 4: Rejected - Error on table ZHUO.T1, column MESSAGE.
Field in data file exceeds maximum length
。。。。
Record 50: Rejected - Error on table ZHUO.T1, column MESSAGE.
Field in data file exceeds maximum length
Record 51: Rejected - Error on table ZHUO.T1, column MESSAGE.
Field in data file exceeds maximum length
出问题的是message列,message列都是类似 “尊敬的用户您好!您所在的小区我公司千兆网络已覆盖,中国移动诚邀您体验移动千兆品质宽带,体验期三个月,开通后立即生效,体验期内不收取任何费用,到期后业务自动退订。如需订购请回复Y,不回复或者回复其他内容默认不订购。详询10086。【中国移动】”这种116个汉字的。过长。相当于clob字段,但是此处定义的varchar2.对于类似lob的过长字段,oracle也有方法,修改ctl文件:
LOAD DATA
INFILE '/home/oracle/test.txt'
TRUNCATE INTO TABLE zhuo.t1
FIELDS TERMINATED BY '&' OPTIONALLY ENCLOSED BY '"'
trailing nullcols
(id,
phone,
message char(1000),
port,
created date 'yyyy-mm-dd hh24:mi:ss'
)
注意这里message显式指定char(1000),因为oracle默认所有输入字段都是char(255),如果不显示指定类型和长度,一旦加载列的实际长度超出255,则数据加载就会报错:filed in data file exceeds maximum length.
再次加载正常。
验证如下:
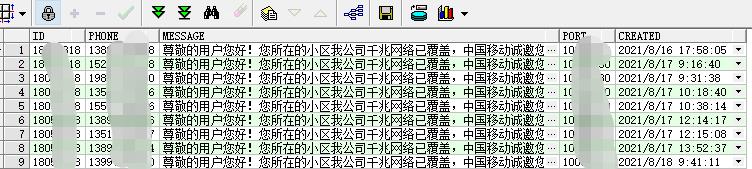
有时候查询的PL/SQL里面的汉字,是乱码的,需要windows设置环境变量:
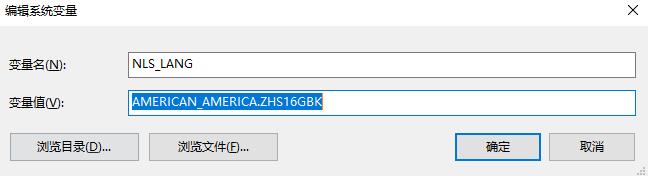
重启pl/sql,再次查询即可。
对于这种clob字段,还有另外一种方法,就是表定义的时候
SQL> drop table t1 purge;
Table dropped.
SQL> create table t1(id varchar2(10),phone varchar2(11),message clob,port varchar2(10),created date);
Table created.
控制文件:
LOAD DATA
CHARACTERSET 'ZHS16GBK'
INFILE '/home/oracle/test.txt'
TRUNCATE INTO TABLE zhuo.t1
FIELDS TERMINATED BY '&' OPTIONALLY ENCLOSED BY '"'
trailing nullcols
(id,
phone,
message_file filler char,
message lobfile(message_file),
port,
created "to_date(:created,'yyyy-mm-dd hh24:mi:ss')"
)
主要是这两行:
message_file filler char,
message lobfile(message_file),
filler是loader的保留字,表示message_file是变量而不是字段名,filler char表示是字符串变量,为后面的lobfile使用
lobfile是loader的函数,表示该字段的值从lobfile取得
TERMINATED BY EOF 表示每行的每个lob字段都来自一个独立的文件
加载成功。
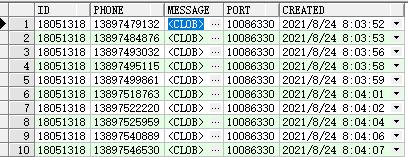
中文汉字乱码
两种解决方法:
1、设置NLS_LANG
$ export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
$ sqlldr userid=system/oracle@orclpdb control=/home/oracle/t1.ctl log=/home/oracle/t1.log
2、在控制文件设置字符集参数
CHARACTERSET ‘ZHS16GBK’ 或 CHARACTERSET ‘UTF8’,根据数据库实际情况设置数据库字符集。
LOAD DATA
CHARACTERSET 'ZHS16GBK'
INFILE '/home/oracle/test.txt'
TRUNCATE INTO TABLE zhuo.t1
FIELDS TERMINATED BY '&' OPTIONALLY ENCLOSED BY '"'
trailing nullcols
(id,
phone,
message char(1000),
port,
created "to_date(:created,'yyyy-mm-dd hh24:mi:ss')"
)
注意CHARACTERSET位置,只能在load之后,infile之前。要不然会报错,如下:
SQL*Loader-350: Syntax error at line 3.
Expecting keyword INTO, found keyword characterset.
CHARACTERSET ‘ZHS16GBK’
^
还有一些选项
OPTIONS (skip=1,rows=128) – sqlldr 命令显示的选项可以写到这里边来,skip=1 用来跳过数据中的第一行
如,控制文件写为:
OPTIONS (skip=1,rows=128,direct=true,streamsize=10485760 date_cache=5000)
LOAD DATA
CHARACTERSET 'ZHS16GBK'
INFILE '/home/oracle/test.txt'
TRUNCATE INTO TABLE zhuo.t1
FIELDS TERMINATED BY '&' OPTIONALLY ENCLOSED BY '"'
trailing nullcols
(id,
phone,
message char(1000),
port,
created "to_date(:created,'yyyy-mm-dd hh24:mi:ss')"
)
那么导入的时候,可以省略写为:
sqlldr userid=system/oracle@orclpdb control=/home/oracle/t1.ctl log=/home/oracle/t1.log
提升加载速度
主要可以提升速度的参数:
rows
bindsize
direct:相对于常规路径加载,直接路径加载,一次性加载
streamsize:直接路径加载默认读取全部记录,因此不需要设置rows参数,读取到的数据处理后存入流缓存区,即streamsize。才参数默认值256K,这里加大到10MB。
date_cache :该参数指定一个转换后日期格式的缓存区,以条为单位,默认值1000条,即保存1000条转换后的日期格式,由于我们要导入的数据中有日期列,因此加大该参数值到5000,以降低日期转换操作带来的开销。
$ sqlldr userid=system/oracle@orclpdb control=/home/oracle/t1.ctl log=/home/oracle/t1.log direct=true streamsize=10485760 date_cache=5000
总结
1、控制文件中的列是可以做转化和运算的,如;
created position(17:20)
created(*) char(9)
created filter position(17:20)
created “to_date(:created,‘yyyy-mm-dd hh24:mi:ss’)”
message char(1000)
2、sqlldr一般流程:
1)格式化待加载文件,去掉空格了,添加分隔符了,生成txt了。
2)要插入的表必须已经存在,换句话说,必须先建好表,然后才能通过sqlldr向其加载数据。主要流程就是:创建目标表,创建ctl文件,执行加载。
SQL> create table t1(id varchar2(10),phone varchar2(11),message varchar2(500),port varchar2(10),created date);
3)创建控制文件
针对本次加载,控制文件最优如下:
LOAD DATA
CHARACTERSET 'ZHS16GBK'
INFILE '/home/oracle/test.txt'
TRUNCATE INTO TABLE zhuo.t1
FIELDS TERMINATED BY '&' OPTIONALLY ENCLOSED BY '"'
trailing nullcols
(id,
phone,
message char(1000),
port,
created "to_date(:created,'yyyy-mm-dd hh24:mi:ss')"
)
以后可以按照此模板更改。里面的字段需要做灵活处理。特别是日期型,和汉字的varchar2类型。
4)加载:
$ sqlldr userid=system/oracle@orclpdb control=/home/oracle/t1.ctl log=/home/oracle/t1.log direct=true streamsize=10485760 date_cache=5000
参考
https://www.cnblogs.com/kerrycode/p/5034585.html
以上是关于sqlldr加载19c pdb最佳实践的主要内容,如果未能解决你的问题,请参考以下文章