Learning to Recover 3D Scene Shape from a Single Image
Posted MengYa_Dream
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Learning to Recover 3D Scene Shape from a Single Image相关的知识,希望对你有一定的参考价值。
论文地址 @inproceedings{Wei2021CVPR, title = {Learning to Recover 3D Scene Shape from a Single Image}, author = {Wei Yin and Jianming Zhang and Oliver Wang and Simon Niklaus and Long Mai and Simon Chen and Chunhua Shen}, booktitle = {Proc. IEEE Conf. Comp. Vis. Patt. Recogn. (CVPR)}, year = {2021} }所有相关整理(论文研读、PPT展示、代码实践)均以资源形式上传啦,
时间宝贵,主要以图片形式分享啦
目录
Abstruct
现象:尽管单眼深度估计在野外场景取得了重大突破,但是最新的方法不能够用于准确恢复的3D场景形状
原因:未知的深度位移;可能未知的相机焦距
根源:在混合数据深度预测训练中使用的位移不变重构loss
本文提出:两阶段架构
First:预测图像深度(单眼图像未知比例及偏移)
Second:利用3D点云编码器预测缺失的深度位移和焦距(帮助恢复一个真实的3D场景形状)
本文提出:2个loss
图像级归一化回归损失
基于法线的几何损失
增强在混合数据集上训练的深度预测模型。
研究结果:
在9个看不见的数据集上测试本文的深度模型,并在Zero-shot数据集泛化上展现了最先进的性能。
Introduction
3D场景重建是计算机视觉的基础任务
传统方法:SLAM SfM (基于连续帧或多视图的特征点对应重建三维场景)
但是本文目标:从单张的野外图像重建密集的三维场景形状
因此:在没有多个视图可用的情况下,工作依靠单目深度估计。
但是:现有的单目深度估计方法本身无法如实的恢复准确的三维点云。
RGB → Predicted Depth(correct)→ the 3D scene shape of the point cloud
现象:点云构成的三维场景形状出现显著的畸变
原因:未知的深度位移和焦距
方案:添加恢复的深度位移、恢复的深度转换+焦距
与多视图重建方法不同:
单目深度估计需要利用高水平的场景先验,即实际解决方案-数据驱动方法。
Recent works:
在不同的野外场景数据集(如网络立体图像和立体视频)中训练深度神经网络的结果带来了希望。
但是,不同的训练集给模型训练也带来了挑战:
因为不同摄像机捕捉到的训练数据,其深度估计的图像先验存在显著差异。
因为未知的相机基线和立体后期处理,网络立体图像和视频只能提供一个比例和位移的深度监督。
最新工作:最先进的野外单目深度模型使用各种损失实现尺度和位移不变再训练。
未知的深度比例不会导致任何形状失真(均匀缩放3D场景),但未知的深度位移会造成形状失真。
在测试时,图像的相机焦距可能无法获得,导致3D场景形状的更多失真。
影响:这种场景形状失真是后续任务的关键问题(如三维视图合成和三维摄影等)。
Address these challenges:
提出一个新型的单眼场景形状估计架构=深度预测模块+点云重构模块
深度预测模块:
一个(在现有的混合数据集上训练的)卷积神经网络,将预测深度映射到一个尺度和位移
点云重构模块:
利用点云编码器网络,从场景点云重建的初始猜测——预测位移和焦距调整因素
A key observation:
当操作(从深度图中得到的)点云而不是图像本身时,可以训练模型使用合成的3D数据或(三维激光扫描设备获取的)数据来学习3D场景形状先验。
尽管这些数据源的多样性明显低于互联网图像,但是与图像相比,点云的域差距问题要小得多。
实践表明,点云编码器能很好地推广到看不见的数据集。
Robust model:
提出2个loss:为了在多源混合数据基础上训练一种鲁棒的单目深度预测模型
图像级归一化回归损失(简单有效)
将深度数据转换为标准的尺度-位移-不变空间,以获得更健壮的训练。
成对的表面法线的几何损失
改善预测的深度图的几何形状。
本文贡献总结:
• 一种新颖的野外单目三维场景形状估计框架 。据作者所知,这是该任务中第一个完全数据驱动的方法;
也是第一个利用3D点云神经网络来改进来自深度图的点云结构的方法。
• 一种图像级归一化回归损失和一种成对表面法向回归 损失用于改进在混合多源数据集上训练的单目深度估计模型。

Related Work
Monocular depth estimation in the wild
这项任务最近取得了令人印象深刻的进展。
这些方法的关键特性是哪些数据可以用于训练,以及哪些目标函数对这些数据有意义。
然而,获取不同的数据集度量的地面真实深度是一个挑战。
替代方案:
陈等人为互联网图片收集了不同相对深度注解,而其他方法则建议从互联网上抓取立体图像或视频。
这种不同的数据对于泛化是很重要的,但是由于度量深度是不可用的,所以不能使用直接深度回归损失。
相反,这些方法要么依赖于评估相对深度的排列损失,要么依赖于尺度和位移不变损失的监督。
尺度和位移不变损失的监督:可以产生特别稳健的深度预测,但由于相机模型是未知的,且深度中存在未知的偏移,因此无法从预测的深度图重建3D形状。
本文旨在:从单张野外图像重建三维形状。
3D reconstruction from a single image
一方面;
许多研究都致力于从单一图像中重建不同类型的物体,例如人类[33,汽车、飞机、桌子等。
主要的挑战是如何最好地恢复对象的细节,以及如何在有限的内存中表示它们。
Pixel2Mesh:提出了从单个图像重建三维形状,并用三角形网格表示。
PIFu:提出一种高效记忆的隐式函数来恢复人的高分辨率表面,包括看不见的/被遮挡的区域。
但是,所有这些方法都依赖于特定对象类或实例的学习先验,通常来自3D监督,因此不能用于完整的场景重建。
另一方面:
一些工作已经提出从单张图片重建3D场景架构。
Saxena等人假设整个场景可以被分割成几块,每一块都可以看作是一个小平面。他们预测平面的方向和位置,并将它们拼接在一起来代表场景。
其他工作提出提出利用阴影和轮廓边缘等图像线索进行场景重建。
但是,这些方法使用手工设计的先验和对场景几何的限制性假设。
本文方法:全数据驱动,可应用于广泛的场景。
Camera intrinsic parameter estimation
恢复相机的焦距是三维场景理解的重要组成部分。
传统的方法:利用参考对象,如平面校准网格或消失点,然后使用它们来估计焦距。
其他方法:提出了一种数据驱动的方法,其中CNN从图像中直接恢复野外数据的焦距。
相对的,
本文的点云模块直接在3D中估计焦距,作者认为这比直接在自然图像上操作更容易。
Method
Two-stage单张图像3D形状估计 pipeline,由深度预测模块(DPM)和点云模块(PCM)组成
•DPM和PCM两模块不同数据源上分别训练,在推理过程中相结合。
•DPM模块:RGB图像→depth map (与真实的度量深度图的比例和位移未知)
•PCM模块:扭曲的点云 →利用预测的深度图d和焦距的初始估计f计算 →输出对深度图和焦距的位移调整,以提高重建的3D场景形状的几何形状。
注意:使用点云网络分别预测位移和焦距比例因子。
depth shift ∆d focal length f∙ αf 精确的场景形状重建

Experiments
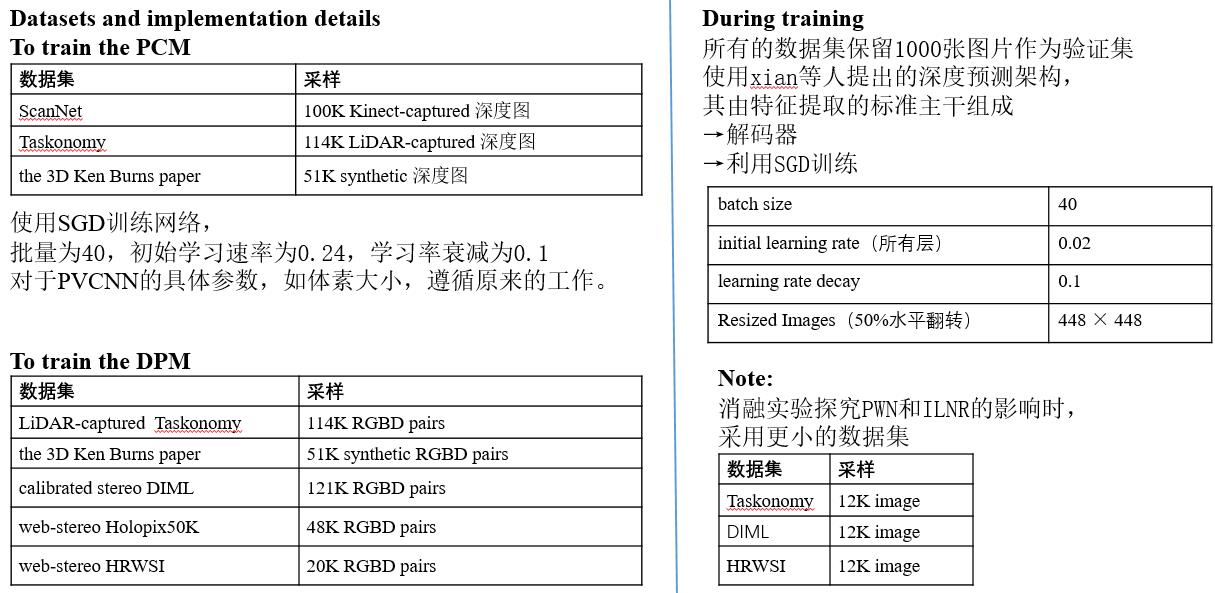

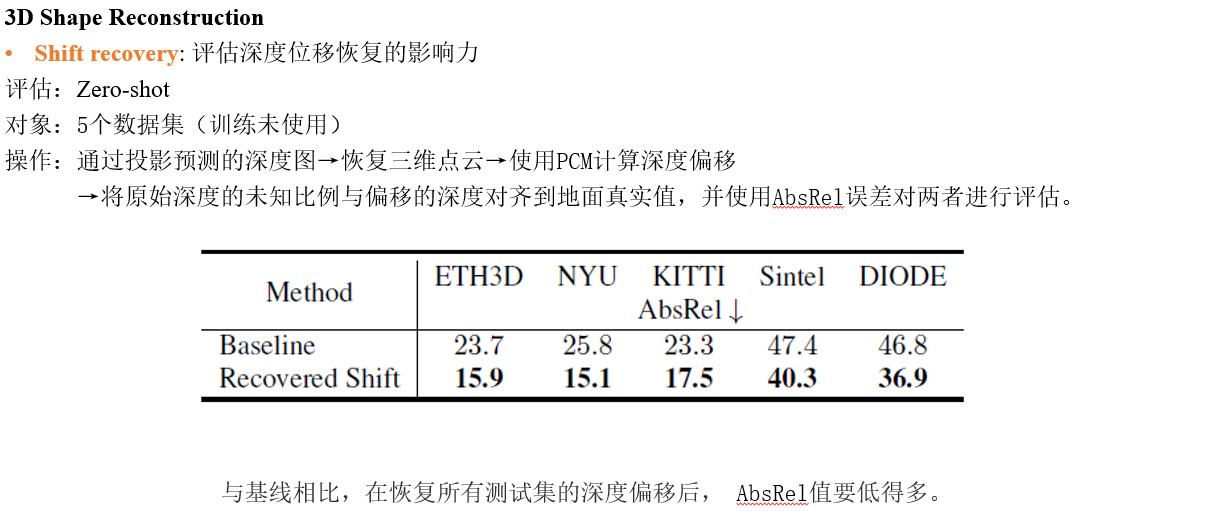
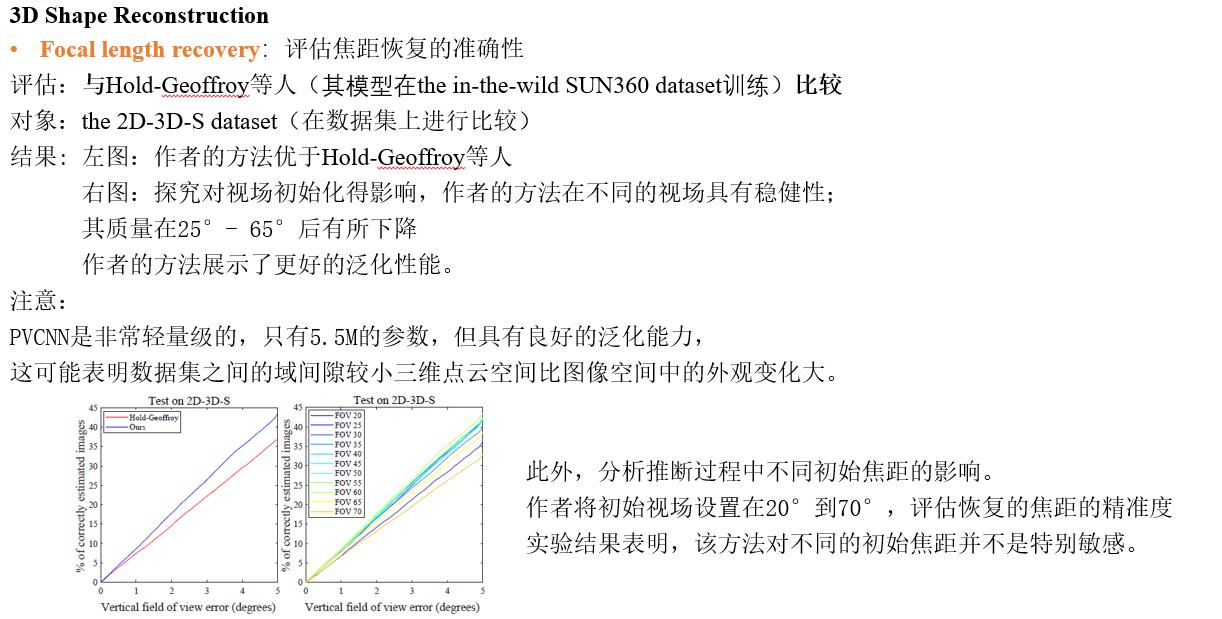


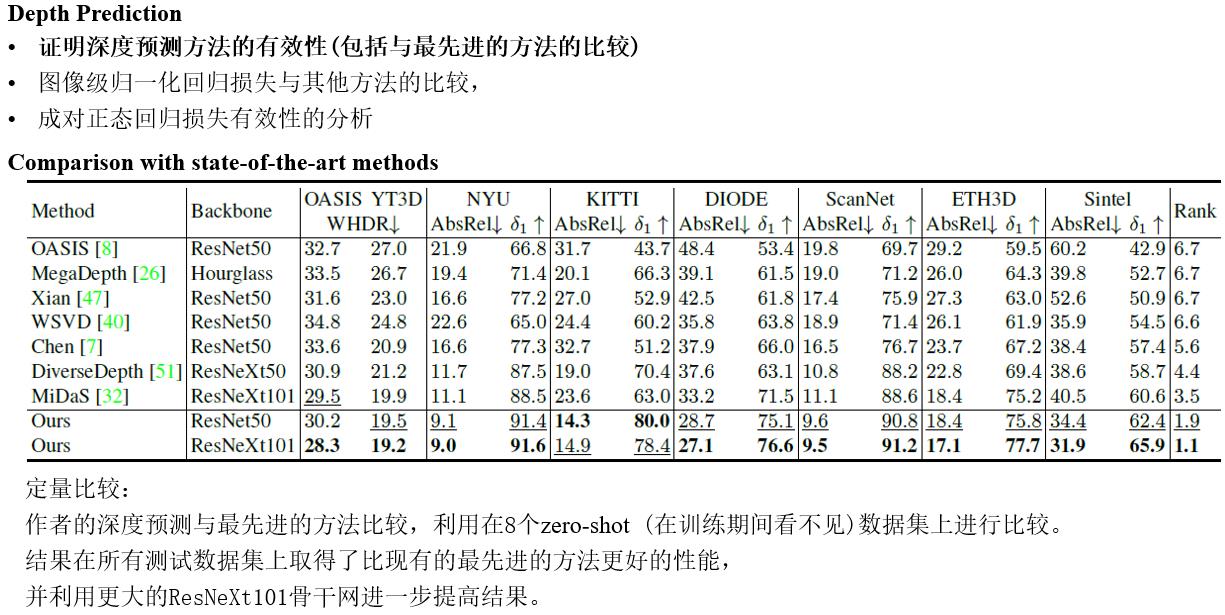

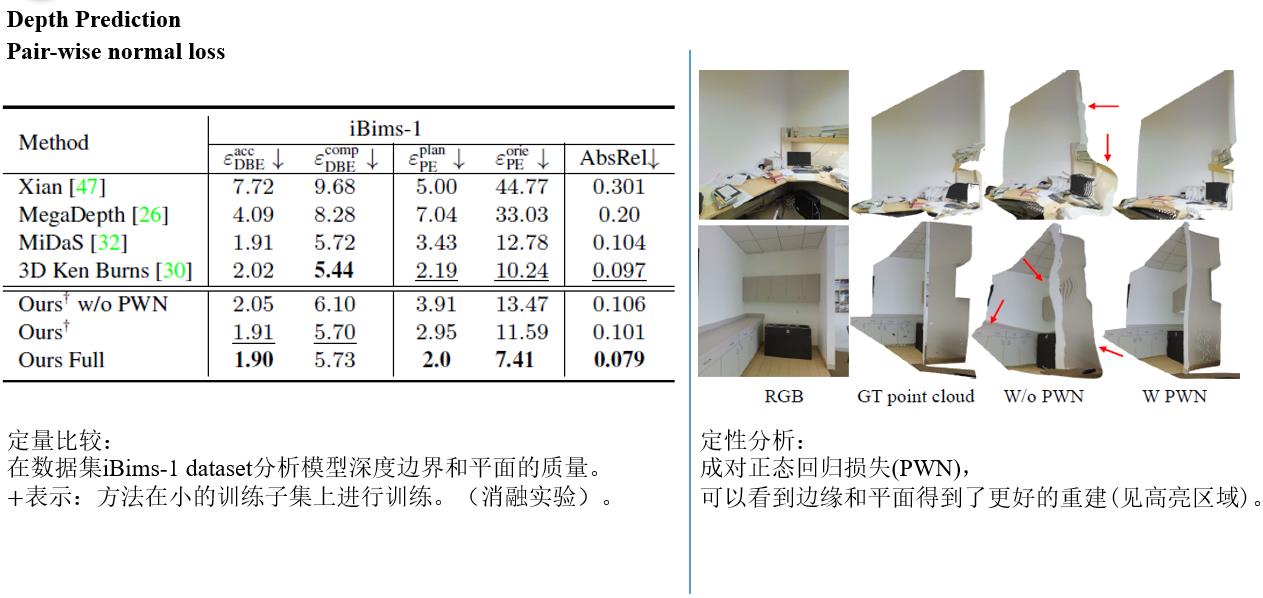
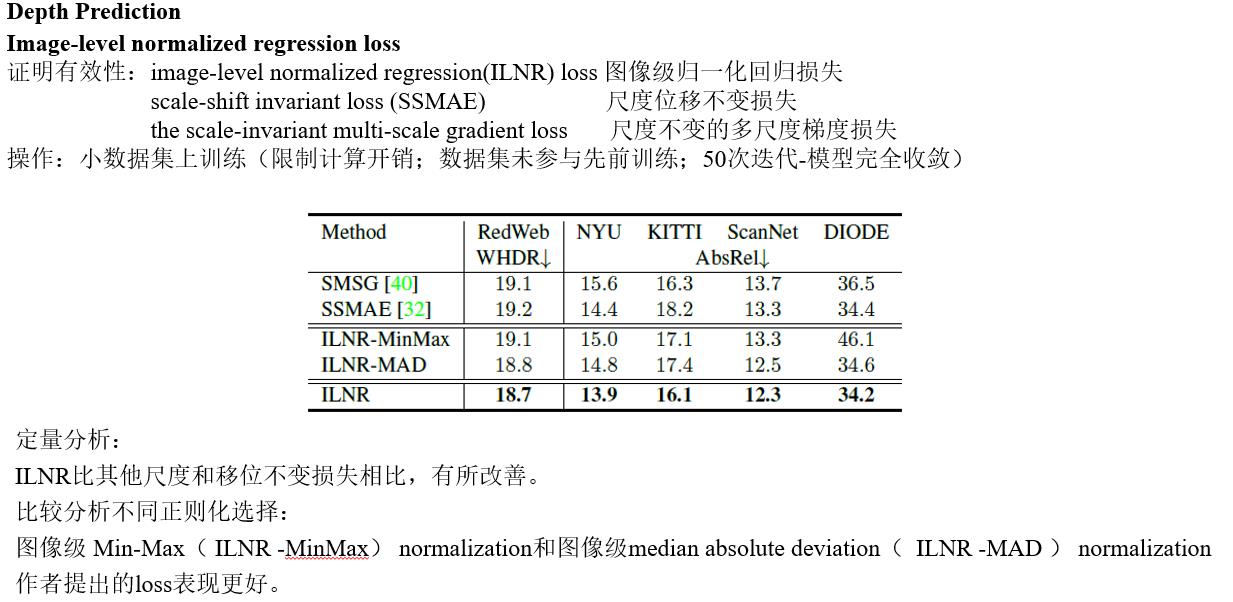
Discussion
Limitations:
• 当场景没有足够的几何线索时, PCM 模块无法恢复准确的焦距和深度位移如:整张图像大部分为墙或天空
• 本文方法 的准确性也会随着从非常见视角 ( 例如,自上而下 ) 或极端焦距拍摄的图像而降低 。更加多样化的3D训练数据可以解决这些失败案例。
• 本文方法 没有对来自 相机径向畸变 的影响进行建模,因此在严重的径向畸变情况下,重建的场景形状会发生畸变 。研究如何利用PCM恢复径向畸变参数将是一个未来研究方向。
Conclusion
在作者所知范围内,其提出的方案:首例由全数据驱动的方法从单目图像重建三维场景形状
作者提出使用点云网络在已知全局深度偏移和焦距的数据集上训练,旨在恢复移动和焦距进而用于三维重建。
这种方法显示出很强的泛化能力,作者认为它可能对基于深度的相关任务有帮助。
大量的实验证明了作者的场景形状重建方法的有效性和对未知数据的推广能力。
笔者主要学习深度部分,因此仅对一阶段深度 进行实践探究啦,效果如图

以上是关于Learning to Recover 3D Scene Shape from a Single Image的主要内容,如果未能解决你的问题,请参考以下文章