Yolov5-Pytorch版-Windows下训练自己的数据集,内含voc批量转yolo方法。(自称宇宙超级巨详细步骤)
Posted 璐璐不坚强
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Yolov5-Pytorch版-Windows下训练自己的数据集,内含voc批量转yolo方法。(自称宇宙超级巨详细步骤)相关的知识,希望对你有一定的参考价值。
Yolov5-Pytorch版-Windows下训练自己的数据集(自称宇宙超级巨详细步骤)
一.准备数据集
由于默认情况下输出的是VOC数据集,说人话就是说你标完生成的是.xml格式的文件。但是我们训练要用的是yolo的.txt格式,所以接下来讲述两种方法训练数据集。
1.在labelimg下直接生成yolo的.txt格式

将默认生成VOC文件改为yolo,再进行标注,最后你标注生成的就是.txt格式的文件,训练就可以直接用了,见下图。很简单吧,我学长和我说的时候我都傻了,那我们为什么要费死劲搞什么xml,然后训练还不能直接用,烦死人了!!!那如果你和我一样已经标注完了并且数据集超级无敌巨多的话,咱们就接着往下看吧,看看是怎么转换的呢。

2.Pytorch版批量.xml格式转yolo的.txt格式
建议最好准备两个yolov5文件,一个命名为yolov5专门跑程序,另一个设置成yolov5-master专门用来转换。
-
设置文件夹
在data文件夹下新建这三个文件夹,其中Annotations下存放.xml文件,images下存放图片,并在ImageSets里面新建一个Main文件夹。到此准备工作已完成。(在跑完ss.py时会在Main文件夹下生成train.txt和test.txt,跑完voc_labels.py会在data文件夹下生成labels,所以别着急我们慢慢来!)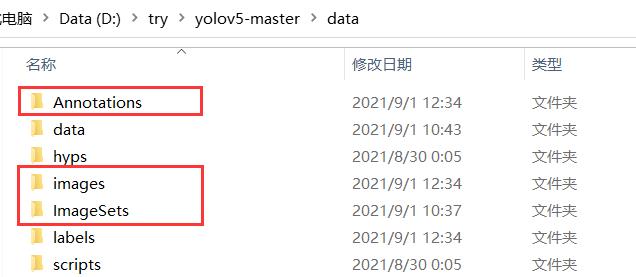
-
ss.py生成train.txt和test.py
ss.py是我随便起的,在大家自己能记住的前提下随便起名字。代码如下,如果和我文件夹设置的名称一样,大家直接复制执行就ok。执行后你会发现Main文件夹下生成train.txt和test.txt就是正确的。
import os
import random
trainval_percent = 0.2 # 可自行进行调节
train_percent = 1
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
# ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
# fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\\n'
if i in trainval:
# ftrainval.write(name)
if i in train:
ftest.write(name)
# else:
# fval.write(name)
else:
ftrain.write(name)
# ftrainval.close()
ftrain.close()
# fval.close()
ftest.close()
- voc_labels.py生成标签
这里只需改一个地方就是自己训练的类别名称,剩下保持不动执行就会生成标签文件labels,到此格式转换完结!
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test']
classes = ['scallop'] # 自己训练的类别
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\\n' % (image_id))
convert_annotation(image_id)
list_file.close()
3.数据集制作
数据集我们只要图片以及对应生成的labels
数据集随意新建在哪里都可以。
首先我们新建一个datesets文件夹,在里面新建train和val两个文件夹。
在train和val下分别新建images和labels两个文件夹,其中images放入图片,labels放入我们标注的标签。
如果你和我一样是转化得到的txt文件,你就可以直接复制生成的labels文件夹到train和val下,不知我说没说清楚。

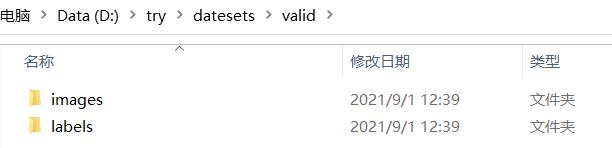
注:这里面valid和val一样不影响,但是我看我学长写的是valid我就紧跟随!
二.Yolov5实现训练
1.修改两个.yaml文件
1.在data文件夹下新建一个yaml文件,随便起名,他的作用和coco.yaml一个道理。说人话就是没有他训练就找不到数据集位置,也就是说他是一个存放输入数据的入口地址的文件。
train: D:/try/datesets/train/images #路径改成自己的
val: D:/try/datesets/valid/images #路径改成自己的
nc: 1
names: ['scallop']
2.在model文件夹下修改yolov5s.yaml文件
这里就把类别数改了就可以,其余的不要动。
nc: 1 # 类别数
2.修改train.py文件
如果怕错就把data/data.yaml内个data.yaml文件名改成自己设的就可以了!
parser.add_argument('--epochs', type=int, default=200) # 训练的epoch
parser.add_argument('--batch-size', type=int, default=16) # batch_size 显卡垃圾的话,就调小点
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='*.cfg path')
parser.add_argument('--data', type=str, default='data/data.yaml', help='*.data path') #这里需要改成你之前自己在data下新建的内个yaml文件
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='train,test sizes')
3.执行train.py
打开Terminal执行代码:
python train.py --img 640 --batch 8 --epoch 300 --data ./data/data.yaml --cfg ./models/yolov5s.yaml --weights weights/yolov5s.pt
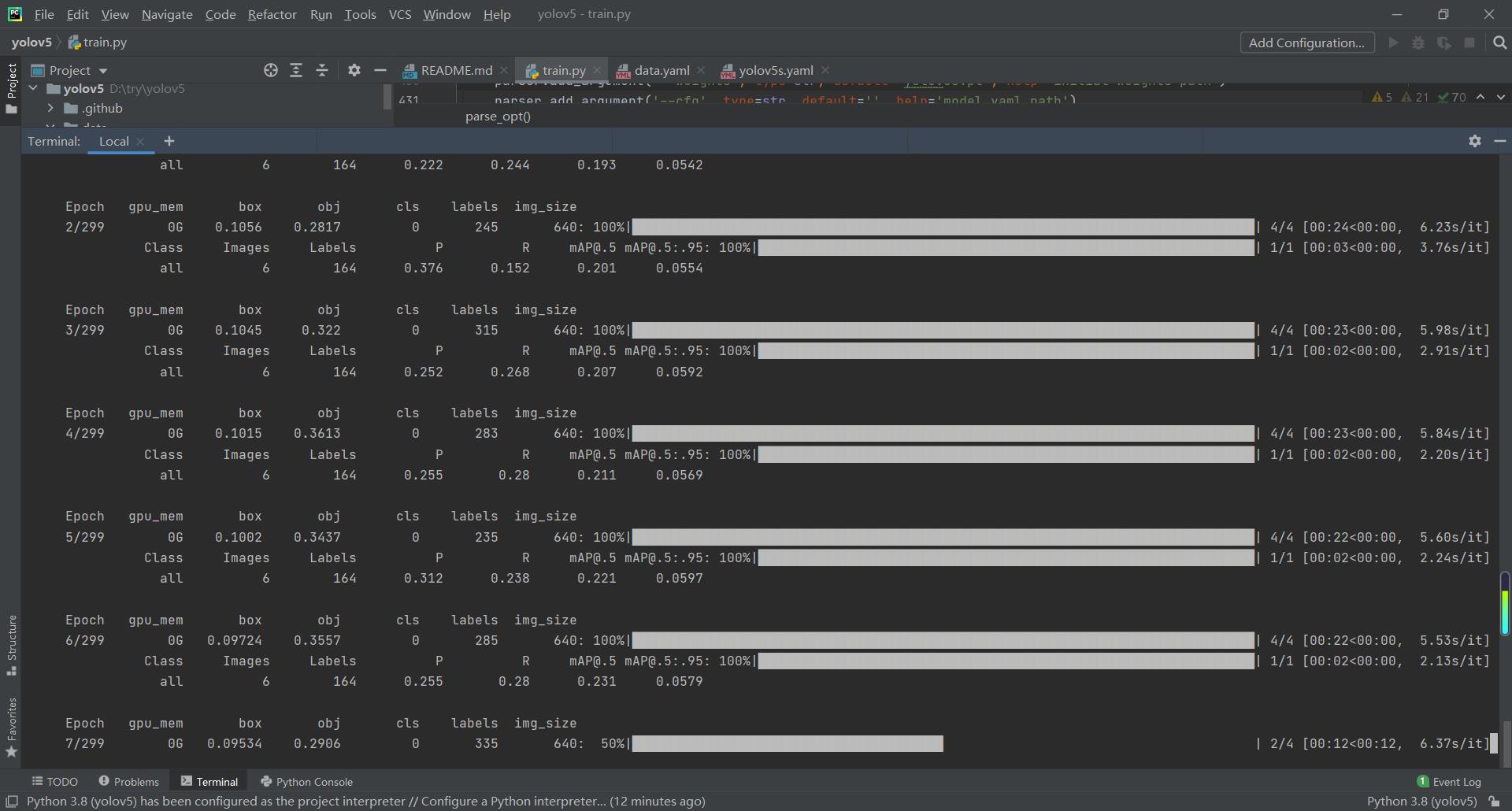
注意代码中文件的路径是否正确
注意命令中文件的路径是否正确
注意文件的名称是否与代码和命令中的对应,例data不是date,datesets不是datasets!!!
注意不该改的代码不要动,坏了咱赔不起!!!
注意不要随便乱删空格,尤其的包含路径的空格!!!
到此.xml格式批量转yolo的.txt格式以及yolov5在Pytorch下实现训练圆满结束!
欢迎小伙伴们在评论区对我进行错误更正,你要是对,我必改并称你为大哥!
以上是关于Yolov5-Pytorch版-Windows下训练自己的数据集,内含voc批量转yolo方法。(自称宇宙超级巨详细步骤)的主要内容,如果未能解决你的问题,请参考以下文章