Spark集群安装-基于hadoop集群
Posted 吾仄lo咚锵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark集群安装-基于hadoop集群相关的知识,希望对你有一定的参考价值。

hadoop集群
下载
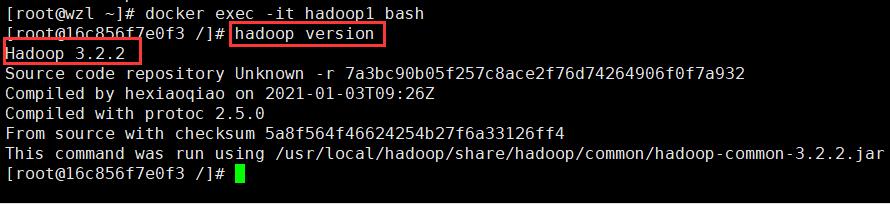
- 首先查看hadoop版本
hadoop version
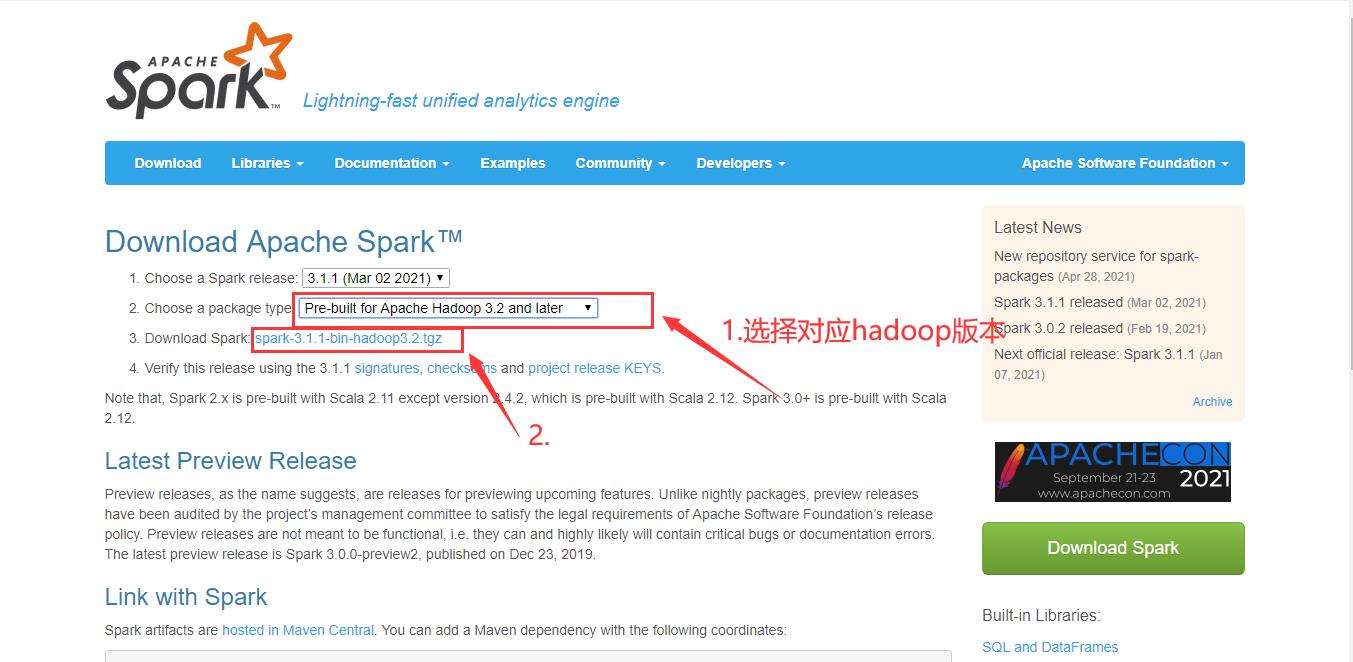
- 下载spark
http://spark.apache.org/downloads.html

cd /usr/local
#yum -y install wget
wget https://mirrors.bfsu.edu.cn/apache/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgz
tar -zxvf spark-3.1.1-bin-hadoop3.2.tgz
mv spark-3.1.1-bin-hadoop3.2 spark

环境配置
vi /etc/profile
export SPARK_HOME=/usr/local/spark
export PATH=...:$SPARK_HOME/bin:$SPARK_HOME/sbin
source /etc/profile

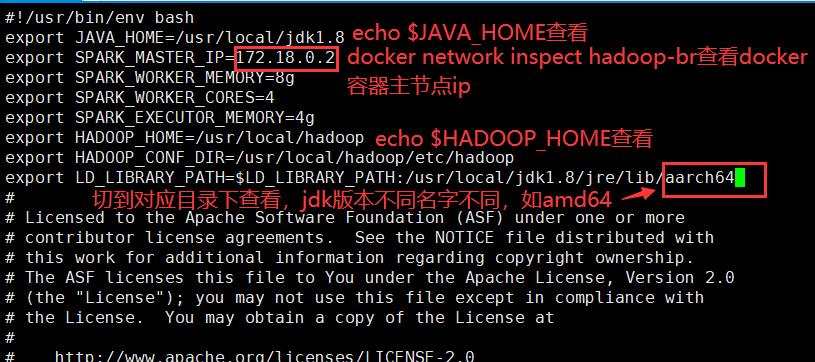
spark-env.sh
cd /usr/local/spark/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
export JAVA_HOME=/usr/local/jdk1.8
export SPARK_MASTER_IP=172.18.0.2
export SPARK_WORKER_MEMORY=2g
export SPARK_WORKER_CORES=4
export SPARK_EXECUTOR_MEMORY=1g
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/jdk1.8/jre/lib/aarch64
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/

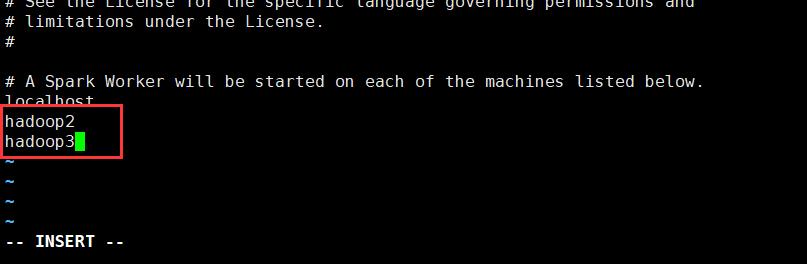
集群配置
cd /usr/local/spark/conf
cp workers.template workers
vi workers
#添加从节点:
hadoop2
hadoop3

将主节点配置同步给从节点
scp -r /usr/local/spark/ hadoop2:/usr/local/
scp -r /usr/local/spark/ hadoop3:/usr/local/
测试
#记得先启动hadoop集群
#/usr/local/hadoop/sbin/./start-all.sh
cd /usr/local/spark/sbin #切到spark目录/sbin下
./start-all.sh
cd /usr/local/spark/bin #如果内存不够可以关闭一个从节点再试试
./run-example SparkPi 2>&1 | grep "Pi is"

cd /usr/local/spark/bin
./spark-shell

开启防火墙端口8080并映射转发到docker容器
#exit #退出docker容器
systemctl start firewalld
firewall-cmd --add-port=8080/tcp --permanent #开启8080端口
firewall-cmd --add-forward-port=port=8080:proto=tcp:toaddr=172.18.0.2:toport=8080 --permanent
firewall-cmd --add-masquerade --permanent #端口映射
firewall-cmd --reload #重新加载
firewall-cmd --list-ports
# firewall-cmd --zone=public --remove-port=80/tcp --permanent 关闭8080端口
公网ip:8080
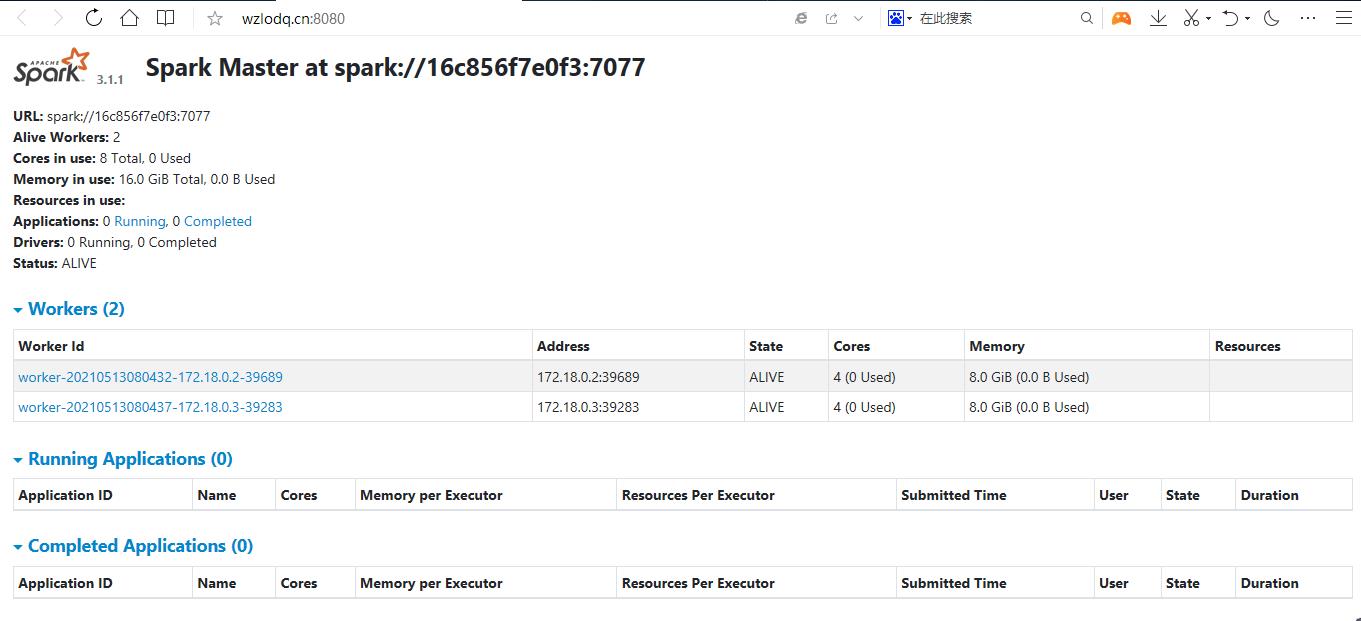
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤
以上是关于Spark集群安装-基于hadoop集群的主要内容,如果未能解决你的问题,请参考以下文章