10行代码集2000张美女图,Python爬虫120例,再上征途
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了10行代码集2000张美女图,Python爬虫120例,再上征途相关的知识,希望对你有一定的参考价值。
《Python 爬虫 120 例》专栏简介
Python 爬虫 100 例教程,编写自 2018-07-30 到 2020-10-28,将近 800 天,至今依旧是 Python 爬虫领域畅销专栏之一。
但随着时间的变化,Python 爬虫 100 例中部分抓取目标网站,地址已经失效,是时候进行迭代升级啦。
2021 年 5 月 21 日,升级版 Python 爬虫 120 例上线啦。
更新内容如下:
- 更新频率更快,上次 800 天完成 100 例,这次 300 天完成 120 例;
- 更新所有目标网站;
- 更新最新框架;
Python 爬虫的整体技术思想是不会发生变化的,所以你依旧可以购买原专栏进行学习。
购买与预览地址为 https://dream.blog.csdn.net/category_9280209.html。
专栏更新频率为每周 2~3 篇内容,内容从浅入深,专栏由大龄程序员 擦哥 撰写。
一切的起点,10 行代码集美女
前奏篇
正式编写爬虫学习前,以下内容先搞定:
- 能安装 Python 环境,例如安装 3.5 版本,可以切换为其他版本;
- 能熟练开发工具,例如 VSCode,PyCharm;
- 能熟练 Python 第三方库;
- 能运行 Python 脚本文件,能输出 hello world。
有以上技能,就可以放心大胆的购买本专栏进行学习。
截止 2021 年 5 月 20 日 Python 最新版本,官网版本为 3.9.5 版本,你可以直接使用该版本,也可以使用任意 3.0 以上版本。
目标数据源分析
本次待抓取的目标地址为:
http://www.netbian.com/mei/index.htm

抓取目标:
抓取该网站的图片,目标 2000 张。
用到的 Python 框架为:
requests 库、re 模块
其它技术栈补充:
正则表达式
目标网站地址规则:
- http://www.netbian.com/mei/index.htm
- http://www.netbian.com/mei/index_2.htm
- http://www.netbian.com/mei/index_3.htm
结论,列表页规则为 http://www.netbian.com/mei/index_{页码}.htm。
数据范围
- 累计 164 页;
- 每页 20 条数据。
图片所在标签与页面地址
图片所在标签位置代码如下:
<li><a href="/desk/23397.htm" title="陆萱萱 白色衬衫 裙子 职业装 美女模特壁纸 更新时间:2021-04-11" target="_blank"><img src="http://img.netbian.com/file/2021/0411/small30caf1465200926b08db3893c6f35f6c1618152842.jpg" alt="陆萱萱 白色衬衫 裙子 职业装 美女模特壁纸"><b>陆萱萱 白色衬衫 裙子 职业装 美女模特壁纸</b></a></li>
页面地址为 /desk/23397.htm。
整理需求如下
- 生成所有列表页 URL 地址;
- 遍历列表页 URL 地址,并获取图片详情页地址;
- 进入详情页获取大图;
- 保存图片;
- 得到 2000 张图片之后,开始欣赏。
代码实现时间
提前安装完毕 requests 模块,使用 pip install requests 即可,如果访问失败,切换国内 pip 源。
留个课后小作业,如何设置全局的 pip 源。
代码结构如下:
import requests
# 抓取函数
def main():
pass
# 解析函数
def format():
pass
# 存储函数
def save_image():
pass
if __name__ == '__main__':
main()
先实现 10 行代码抓美女图,举个例子,在正式开始前,需要略微了解一些前端知识与正则表达式知识。
例如通过开发者工具查看网页,得到图片素材都在 <div class="list"> 和 <div class="page"> 这两个标签中,首先要做的就是拆解字符串,取出目标数据部分。

通过 requests 对网页源码进行获取,代码如下。
# 抓取函数
def main():
url = "http://www.netbian.com/mei/index.htm"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
res = requests.get(url=url, headers=headers, timeout=5)
res.encoding = "GBK"
print(res.text)
使用 requests 模块的 get 方法即可获取网页数据,其中的参数分别是请求地址,请求头,等待时间。
请求头字段中的 User-Agent,可以先使用我提供给你的内容,也可以通过开发者工具,进行获取。
在数据返回 Response 对象之后,通过 res.encoding="GBK" 设置了数据编码,该值可以从网页源码中获取到。
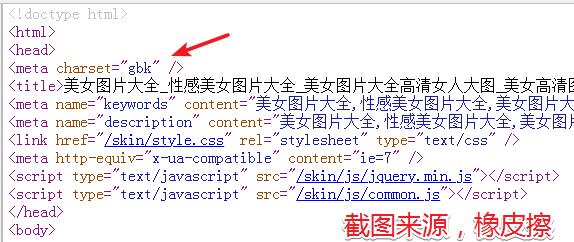
请求到数据源码,即开始解析数据,如果使用正则表达式,建议先对目标数据进行一些简单的裁剪工作。
裁剪字符串是 Python 中比较常规的操作了,直接编写代码即可实现。
用到的还是上文已经提及的两个字符串。
# 解析函数
def format(text):
# 处理字符串
div_html = '<div class="list">'
page_html = '<div class="page">'
start = text.find(div_html) + len(div_html)
end = text.find(page_html)
origin_text = text[start:end]
最终得到的 origin_text 就是我们的目标文本。
通过 re 模块解析目标文本
上文返回的目标文本如下所示,本小节的目标就是获取到图片详情页地址。
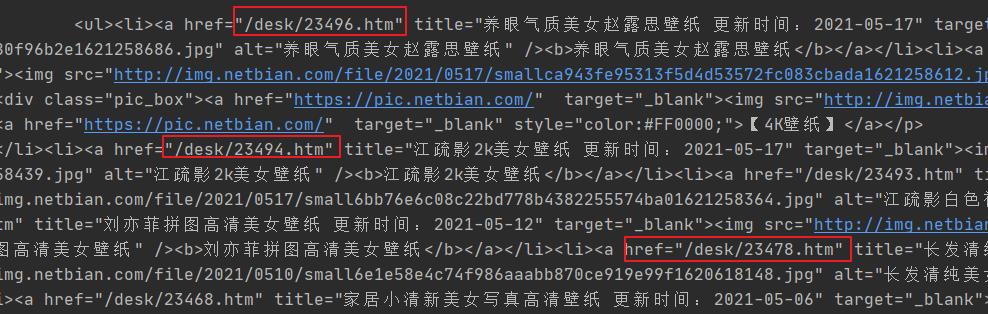
使用的技术是 re 模块,当然需要配合正则表达式进行使用,对于正则表达式,可以跟随橡皮擦一点点的接触。
# 解析函数
def format(text):
# 处理字符串
div_html = '<div class="list">'
page_html = '<div class="page">'
start = text.find(div_html) + len(div_html)
end = text.find(page_html)
origin_text = text[start:end]
pattern = re.compile('href="(.*?)"')
hrefs = pattern.findall(origin_text)
print(hrefs)
其中 re.compile 方法中传递的就是正则表达式,它是一种检索字符串特定内容的语法结构。
例如
.:表示除换行符(\\n、\\r)之外的任何单个字符;*:表示匹配前面的子表达式零次或多次;?:当该字符紧跟在任何一个其他限制符 (*,+,?,{n},{n,},{n,m}) 后面时,匹配模式是非贪婪的,非贪婪就是减少匹配;():分组提取用。
有这些知识之后,在回到代码中去看实现。
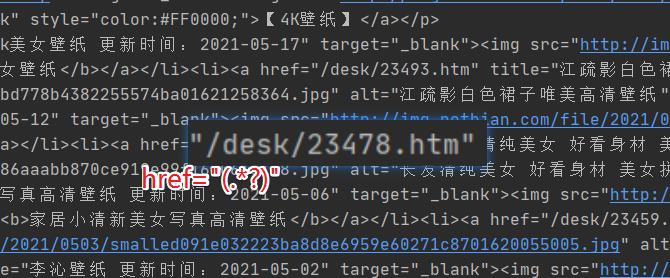
假设存在一个字符串:href="/desk/23478.htm",使用 href="(.*?)" 可以将其中的 /desk/23478.htm 匹配出来,括号的作用也是为了后续方便提取。
最后输出内容如下图所示。

清洗爬取结果
其中存在部分链接地址不正确,需要从列表中进行去除,本步骤使用列表生成器即可完成任务。
pattern = re.compile('href="(.*?)"')
hrefs = pattern.findall(origin_text)
hrefs = [i for i in hrefs if i.find("desk")>0]
print(hrefs)
抓取内页数据
获取到列表页地址之后,就可以对图片内页数据进行获取了,这里用到的技术与前文逻辑一致。
# 解析函数
def format(text, headers):
# 处理字符串
div_html = '<div class="list">'
page_html = '<div class="page">'
start = text.find(div_html) + len(div_html)
end = text.find(page_html)
origin_text = text[start:end]
pattern = re.compile('href="(.*?)"')
hrefs = pattern.findall(origin_text)
hrefs = [i for i in hrefs if i.find("desk") > 0]
for href in hrefs:
url = f"http://www.netbian.com{href}"
res = requests.get(url=url, headers=headers, timeout=5)
res.encoding = "GBK"
format_detail(res.text)
break
在第一次循环中增加了 break,跳出循环,format_detail 函数用于格式化内页数据,依旧采用格式化字符串的形式进行。
由于每页只有一张图片是目标数据,故使用的是 re.search 进行检索,同时调用该对象的 group 方法对数据进行提取。
发现重复代码了,稍后进行优化。
def format_detail(text):
# 处理字符串
div_html = '<div class="pic">'
page_html = '<div class="pic-down">'
start = text.find(div_html) + len(div_html)
end = text.find(page_html)
origin_text = text[start:end]
pattern = re.compile('src="(.*?)"')
image_src = pattern.search(origin_text).group(1)
# 保存图片
save_image(image_src)
保存图片部分,需要提前导入 time 模块,对图片进行重命名。
使用 requests.get 方法直接请求图片地址,调用响应对象的 content 属性,获取二进制流,然后使用 f.write 存储成图片。
# 存储函数
def save_image(image_src):
res = requests.get(url=image_src, timeout=5)
content = res.content
with open(f"{str(time.time())}.jpg", "wb") as f:
f.write(content)
得到的第一张图片,贴到博客中记录。

优化代码
将代码重复逻辑进行提取,封装成公用函数,最终整理之后的代码如下:
import requests
import re
import time
# 请求函数
def request_get(url, ret_type="text", timeout=5, encoding="GBK"):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
res = requests.get(url=url, headers=headers, timeout=timeout)
res.encoding = encoding
if ret_type == "text":
return res.text
elif ret_type == "image":
return res.content
# 抓取函数
def main():
url = "http://www.netbian.com/mei/index.htm"
text = request_get(url)
format(text)
# 解析函数
def format(text):
origin_text = split_str(text, '<div class="list">', '<div class="page">')
pattern = re.compile('href="(.*?)"')
hrefs = pattern.findall(origin_text)
hrefs = [i for i in hrefs if i.find("desk") > 0]
for href in hrefs:
url = f"http://www.netbian.com{href}"
print(f"正在下载:{url}")
text = request_get(url)
format_detail(text)
def split_str(text, s_html, e_html):
start = text.find(s_html) + len(e_html)
end = text.find(e_html)
origin_text = text[start:end]
return origin_text
def format_detail(text):
origin_text = split_str(text, '<div class="pic">', '<div class="pic-down">')
pattern = re.compile('src="(.*?)"')
image_src = pattern.search(origin_text).group(1)
# 保存图片
save_image(image_src)
# 存储函数
def save_image(image_src):
content = request_get(image_src, "image")
with open(f"{str(time.time())}.jpg", "wb") as f:
f.write(content)
print("图片保存成功")
if __name__ == '__main__':
main()
运行代码,得到下图所示运行效果。
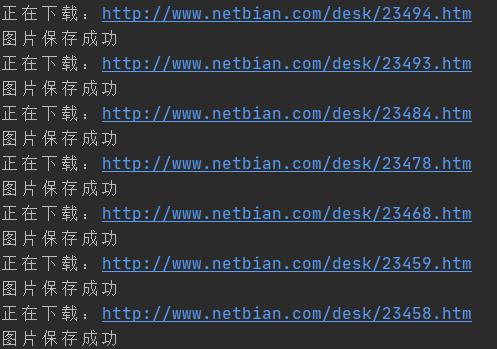
目标 2000 张
20 张图片的爬取已经得到,下面目标 2000 张,初学阶段按照这种简单的方式抓取即可。
这一步需要改造的就是 main 函数:
# 抓取函数
def main():
urls = [f"http://www.netbian.com/mei/index_{i}.htm" for i in range(2, 201)]
url = "http://www.netbian.com/mei/index.htm"
urls.insert(0, url)
for url in urls:
print("抓取列表页地址为:", url)
text = request_get(url)
format(text)
完整代码下载地址:https://codechina.csdn.net/hihell/python120
2000 图片下载地址:
抽奖环节
只要评论数过50
随机抽取一名幸运读者
奖励39.9元爬虫100例专栏 1 折购买券一份,只需3.99元
今天是持续写作的第 155 / 200 天。
求点赞、求评论、求收藏。
以上是关于10行代码集2000张美女图,Python爬虫120例,再上征途的主要内容,如果未能解决你的问题,请参考以下文章
5000张高清壁纸大图(手机用),用Python在法律的边缘又试探了一把
5000张高清壁纸大图(手机用),用Python在法律的边缘又试探了一把