整个大活,采集8个代理IP站点,为Python代理池铺路,爬虫120例之第15例
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了整个大活,采集8个代理IP站点,为Python代理池铺路,爬虫120例之第15例相关的知识,希望对你有一定的参考价值。
很多爬虫大佬都会建立自己的,IP 代理池,你想知道 IP 代理池是如何创建的吗?
如果你恰巧有此需求,欢迎阅读本文。
本案例为爬虫 120 例专栏中的一例,顾使用 requests + lxml 进行实现。
从 89IP 网开始
代理 IP 目标网站之一为:https://www.89ip.cn/index_1.html,首先编写随机返回 User-Agent 的函数,也可以将该函数的返回值设置为请求头,即 headers 参数。
def get_headers():
uas = [
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)",
"Mozilla/5.0 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)",
"Baiduspider-image+(+http://www.baidu.com/search/spider.htm)",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 YisouSpider/5.0 Safari/537.36",
"Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)",
"Mozilla/5.0 (compatible; Googlebot-Image/1.0; +http://www.google.com/bot.html)",
"Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)",
"Sogou News Spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0);",
"Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)",
"Sosospider+(+http://help.soso.com/webspider.htm)",
"Mozilla/5.0 (compatible; Yahoo! Slurp China; http://misc.yahoo.com.cn/help.html)"
]
ua = random.choice(uas)
headers = {
"user-agent": ua,
"referer": "https://www.baidu.com"
}
return headers
上述代码中的 uas 变量,使用的是各大搜索引擎的 UA,后续案例将会继续扩展该列表字段,争取成为单独的模块。
列表随机选择一个值,使用 random.choice ,请提前导入 random 模块。
编写 requests 请求函数
提取公用的请求函数,便于后续扩展为多个代理站点采集数据。
def get_html(url):
headers = get_headers()
try:
res = requests.get(url, headers=headers, timeout=5)
return res.text
except Exception as e:
print("请求网址异常", e)
return None
上述代码首先调用 get_headers 函数,获取请求头,之后通过 requests 发起基本请求。
编写 89IP 网解析代码
下面的步骤分为两步,首先编写针对 89IP 网的提取代码,然后再对其进行公共函数提取。
提取部分代码如下
def ip89():
url = "https://www.89ip.cn/index_1.html"
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/text()'
port_xpath = '//tbody/tr/td[2]/text()'
# 待返回的IP与端口列表
ret = []
html = etree.HTML(text)
ips = html.xpath(ip_xpath)
ports = html.xpath(port_xpath)
# 测试,正式运行删除本部分代码
print(ips,ports)
ip_port = zip(ips, ports)
for ip, port in ip_port:
item_dict = {
"ip": ip.strip(),
"port": port.strip()
}
ret.append(item_dict)
return ret
上述代码首先获取网页响应,之后通过 lxml 进行序列化操作,即 etree.HTML(text),然后通过 xpath 语法进行数据提取,最后拼接成一个包含字典项的列表,进行返回。
其中解析部分可以进行提取,所以上述代码可以分割为两个部分。
# 代理IP网站源码获取部分
def ip89():
url = "https://www.89ip.cn/index_1.html"
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/text()'
port_xpath = '//tbody/tr/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
# HTML解析部分
def format_html(text, ip_xpath, port_xpath):
# 待返回的IP与端口列表
ret = []
html = etree.HTML(text)
ips = html.xpath(ip_xpath)
ports = html.xpath(port_xpath)
# 测试,正式运行删除本部分代码
print(ips,ports)
ip_port = zip(ips, ports)
for ip, port in ip_port:
item_dict = {
"ip": ip.strip(), # 防止出现 \\n \\t 等空格类字符
"port": port.strip()
}
ret.append(item_dict)
return ret
测试代码,得到如下结果。
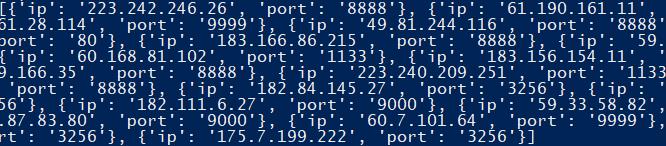
扩展其它代理 IP 地址
在 89IP 代理网代码编写完毕之后,就可以进行其它站点的扩展实现了,各站点扩展如下:
def ip66():
url = "http://www.66ip.cn/1.html"
text = get_html(url)
ip_xpath = '//table/tr[position()>1]/td[1]/text()'
port_xpath = '//table/tr[position()>1]/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
def ip3366():
url = "https://proxy.ip3366.net/free/?action=china&page=1"
text = get_html(url)
ip_xpath = '//td[@data-title="IP"]/text()'
port_xpath = '//td[@data-title="PORT"]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
def ip_huan():
url = "https://ip.ihuan.me/?page=b97827cc"
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/a/text()'
port_xpath = '//tbody/tr/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
def ip_kuai():
url = "https://www.kuaidaili.com/free/inha/2/"
text = get_html(url)
ip_xpath = '//td[@data-title="IP"]/text()'
port_xpath = '//td[@data-title="PORT"]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
def ip_jiangxi():
url = "https://ip.jiangxianli.com/?page=1"
text = get_html(url)
ip_xpath = '//tbody/tr[position()!=7]/td[1]/text()'
port_xpath = '//tbody/tr[position()!=7]/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
def ip_kaixin():
url = "http://www.kxdaili.com/dailiip/1/1.html"
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/text()'
port_xpath = '//tbody/tr/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
可以看到,进行公共方法提取之后,各个站点之间的代码都十分相似,上述内容都是只提取了一页数据,扩展到其它页面,在后文实现,在这之前,需要先处理一个特殊的站点:http://www.nimadaili.com/putong/1/。
该代理站点与上述站点存在差异,即 IP 与端口在一个 td 单元格中,如下图所示: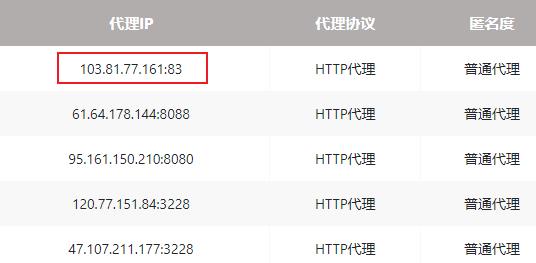
需要针对该网站提供一个特殊的解析函数,如下所示,在代码中通过字符串分割进行 IP 与端口号的提取。
def ip_nima():
url = "http://www.nimadaili.com/putong/1/"
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/text()'
ret = format_html_ext(text, ip_xpath)
print(ret)
# 扩展HTML解析函数
def format_html_ext(text, ip_xpath):
# 待返回的IP与端口列表
ret = []
html = etree.HTML(text)
ips = html.xpath(ip_xpath)
print(ips)
for ip in ips:
item_dict = {
"ip": ip.split(":")[0],
"port": ip.split(":")[1]
}
ret.append(item_dict)
return ret
获取到的 IP 进行验证
获取到的 IP 进行可用性验证,并将可用 IP 存储到文件中。
检测方式有两种,代码分别如下:
import telnetlib
# 代理检测函数
def check_ip_port(ip_port):
for item in ip_port:
ip = item["ip"]
port = item["port"]
try:
tn = telnetlib.Telnet(ip, port=port,timeout=2)
except:
print('[-] ip:{}:{}'.format(ip,port))
else:
print('[+] ip:{}:{}'.format(ip,port))
with open('ipporxy.txt','a') as f:
f.write(ip+':'+port+'\\n')
print("阶段性检测完毕")
def check_proxy(ip_port):
for item in ip_port:
ip = item["ip"]
port = item["port"]
url = 'https://api.ipify.org/?format=json'
proxies= {
"http":"http://{}:{}".format(ip,port),
"https":"https://{}:{}".format(ip,port),
}
try:
res = requests.get(url, proxies=proxies, timeout=3).json()
if 'ip' in res:
print(res['ip'])
except Exception as e:
print(e)
第一种是通过 telnetlib 模块的 Telnet 方法实现,第二种通过请求固定地址实现。
扩大 IP 检索量
上述所有的 IP 检测都是针对一页数据实现,接下来修改为多页数据。依旧拿 89IP 举例。
在该函数参数中新增加一个 pagesize 变量,然后使用循环实现即可。
def ip89(pagesize):
url_format = "https://www.89ip.cn/index_{}.html"
for page in range(1,pagesize+1):
url = url_format.format(page)
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/text()'
port_xpath = '//tbody/tr/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
# 检测代理是否可用
check_ip_port(ret)
# check_proxy(ret)
此时代码运行得到如下结果:
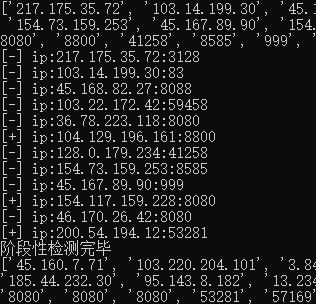
上述代码,当 IP 可用时,已经对 IP 进行了存储。
with open('ipporxy.txt','a') as f:
f.write(ip+':'+port+'\\n')
评论时间
代码下载地址:https://codechina.csdn.net/hihell/python120,可否给个 Star。
来都来了,不发个评论,点个赞吗?
今天是持续写作的第 192 / 200 天。
可以关注我,点赞我、评论我、收藏我啦。
更多精彩
以上是关于整个大活,采集8个代理IP站点,为Python代理池铺路,爬虫120例之第15例的主要内容,如果未能解决你的问题,请参考以下文章