趋势拟合实现分析
Posted 朱雀桥边草
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了趋势拟合实现分析相关的知识,希望对你有一定的参考价值。
现状:Excel的趋势拟合
数分可以用excel对过往数据做趋势拟合,从而对未来做预测,方法是用excel 的LINEST函数获得趋势线公式的参数。
如果采用对数趋势线的话,公式是:
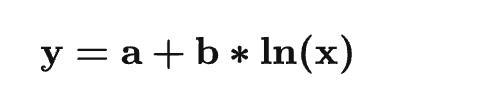
这里:
b 是趋势线的斜率
a 是线性趋势线的截距
将对数趋势线转换为线性趋势线后进行求解:
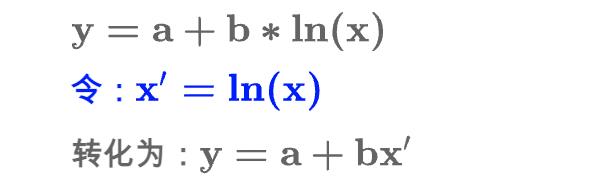
这样使用可以 LINEST 函数求解参数 a,b:
a = INDEX(LINEST(y, x'),2)
b = INDEX(LINEST(y, x'),1)因此:
a: =INDEX(LINEST(y, LN(x)), 1)
b: =INDEX(LINEST(y, LN(x)), 1, 2)
最后 根据示例数据,构建拟合效果可以达到
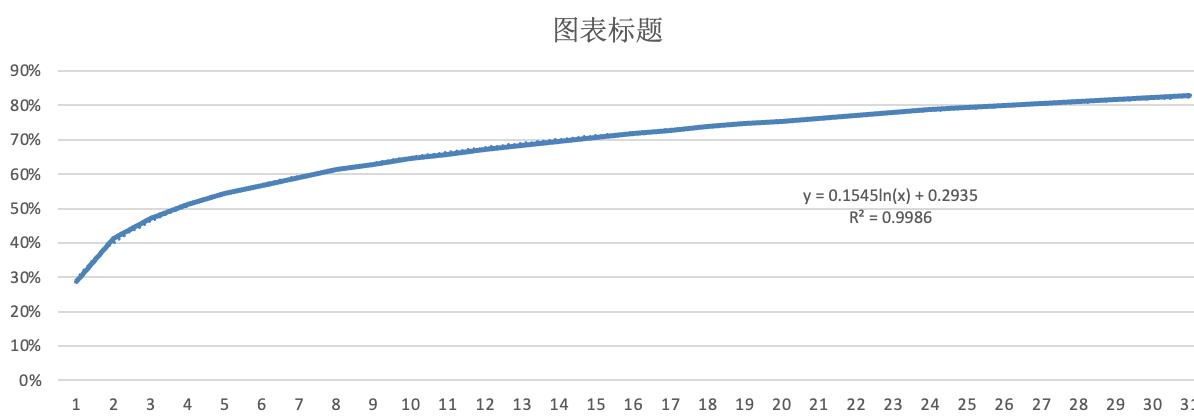
拟合率是非常高的。但数分同学提出,当这种操作,变成一种固定的每日需求后,他们不能每次都把数据搞出来,放在excel 里去做完成这件事,需要一种新的方式去解决这些事情。
问题分析
当这件事给到我们,可能存在两个问题要去解决
趋势线类型如何确认
如何将趋势线落地,并赋能于外部同学。
讨论后,趋势线类型是一个短时间不会变更的事情,更好的是研发来提供不同趋势线类型能力,就像我们换个方式提供了excel的这个功能,由数分通过拟合率或者其他的一些因素 来最终决定如何选取。因此我们将更重的工作放在了第二步。
我们以对数拟合来举例看,把工作可以分成两部分来看
如何保证我们的计算也就是上面公式的截距和斜率的值是正确的
如何将这种能力提供出来
计算截距和斜率
对于java boy ,当提到拟合计算的时候,很容易想到org.apache.commons.math3下面是有提供这类的能力的,翻阅api,我们发现PolynomialCurveFitter 提供了多项式函数拟合计算的能力。问题解法悠然而生。整体实现的方式是

最终得到的coeff 是多项式系数,也就是我们要的截距和斜率
我们要做的就是,把样本数据填充进obs就可以了,因为是对数,要进行一个对数计算ln()。

最终可以得到
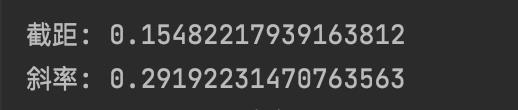
可以确定,和excel中算出来的数据是一致的。这个问题也得到了解决
能力提供
截距和斜率可以计算出来了,问题的核心也就完全突破,如何把这种能力提供出来,就是接下来最重要的问题了,这种能力的提供有以下几个方面关注点
目标使用人群:数据分析
提供计算能力不参与决策
可以在sql脚本中执行
可输入多条数据,产出特定输出
根据这几个关注点,解决方案也就清晰了,我们需要产出粒度适中的自定义的函数。保证功能单一的前提的下,也要帮助数据分析同学使用简单。
最终我们决定提供N个函数,我们这里选取两个函数会在下面做具体分析
mz_roi:根据样本数据计算截距和斜率
pre_roi:根据截距和斜率产出趋势线公式,对未来N天数据进行预测
用户自定义函数
用户自定义函数(UDF)是一个允许用户扩展的强大的功能。用户可以使用Java编写自己的UDF,一旦将用户自定义函数加入到用户会话中,它们就将和内置的函数一样使用,甚至可以提供联机帮助。Hive具有多种类型的用户自定义函数,每一种都会针对输入数据执行特定“一类”的转换过程。
在ETL处理中,一个处理过程可能包含多个处理步骤。Hive语言具有多种方式来将上一步骤的输入通过管道传递给下一个步骤,然后在一个查询中产生众多输出。用户同样可以针对一些特定的处理过程编写自定义函数。如果没有这个功能,那么一个处理过程可能就需要包含一个MapReduce步骤或者需要将数据转移到另一个系统中来实现这些改变。因此,Hive提供了用户自定义函数(UDF),UDF是在Hive查询产生的相同的task进程中执行的,因此它们可以高效地执行。
自定义函数分类
用户自定义函数类别分为以下三种
UDF(User-Defined-Function):一进一出
UDAF(User-Defined Aggregation Function)聚合函数,多进一出,类似于:count/max/min
UDTF(User-Defined Table-Generating Functions)一进多出,如 lateral view explore()
分析我们要做的mz_roi和pre_roi,很明显是UDAF 和 UDTF;
mz_roi的实现
实现分析
根据样本数据计算截距和斜率,这是一个多进一出的功能,很明显的聚合函数,因此我们需要做一个标准的UDAF函数。
UDAF开发主要涉及到以下两个抽象类:
/**
Resolver很简单,要覆盖实现下面方法,该方法会根据sql传人的参数数据格式指定调用哪个Evaluator进行处理。
**/
org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver
/**
UDAF逻辑处理主要发生在Evaluator中,要实现该抽象类的几个方法。
**/
org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator为了更好理解上述抽象类的API,要记住hive只是mapreduce函数,只不过hive已经帮助我们写好并隐藏mapreduce,向上提供简洁的sql函数,所以我们要结合Mapper、Combiner与Reducer来帮助我们理解这个函数。要记住在hadoop集群中有若干台机器,在不同的机器上Mapper与Reducer任务独立运行。
所以大体上来说,这个UDAF函数读取数据(mapper),聚集一堆mapper输出到部分聚集结果(combiner),并且最终创建一个最终的聚集结果(reducer)。因为我们跨域多个combiner进行聚集,所以我们需要保存部分聚集结果。
在理解Evaluator之前,必须先理解objectInspector接口与GenericUDAFEvaluator中的内部类Model。
Model
public static enum Mode
/**
* PARTIAL1: 这个是mapreduce的map阶段:从原始数据到部分数据聚合
* 将会调用iterate()和terminatePartial()
*/
PARTIAL1,
/**
* PARTIAL2: 这个是mapreduce的map端的Combiner阶段,负责在map端合并map的数据::从部分数据聚合到部分数据聚合:
* 将会调用merge() 和 terminatePartial()
*/
PARTIAL2,
/**
* FINAL: mapreduce的reduce阶段:从部分数据的聚合到完全聚合
* 将会调用merge()和terminate()
*/
FINAL,
/**
* COMPLETE: 如果出现了这个阶段,表示mapreduce只有map,没有reduce,所以map端就直接出结果了:从原始数据直接到完全聚合
* 将会调用 iterate()和terminate()
*/
COMPLETE
一般情况下,完整的UDAF逻辑是一个mapreduce过程,如果有mapper和reducer,就会经历PARTIAL1(mapper),FINAL(reducer),如果还有combiner,那就会经历PARTIAL1(mapper),PARTIAL2(combiner),FINAL(reducer)。
而有一些情况下的mapreduce,只有mapper,而没有reducer,所以就会只有COMPLETE阶段,这个阶段直接输入原始数据,出结果。
GenericUDAFEvaluator的方法
// 确定各个阶段输入输出参数的数据格式ObjectInspectors
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException;
// 保存数据聚集结果的类
abstract AggregationBuffer getNewAggregationBuffer() throws HiveException;
// 重置聚集结果
public void reset(AggregationBuffer agg) throws HiveException;
// map阶段,迭代处理输入sql传过来的列数据
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException;
// map与combiner结束返回结果,得到部分数据聚集结果
public Object terminatePartial(AggregationBuffer agg) throws HiveException;
// combiner合并map返回的结果,还有reducer合并mapper或combiner返回的结果。
public void merge(AggregationBuffer agg, Object partial) throws HiveException;
// reducer阶段,输出最终结果
public Object terminate(AggregationBuffer agg) throws HiveException;具体实现
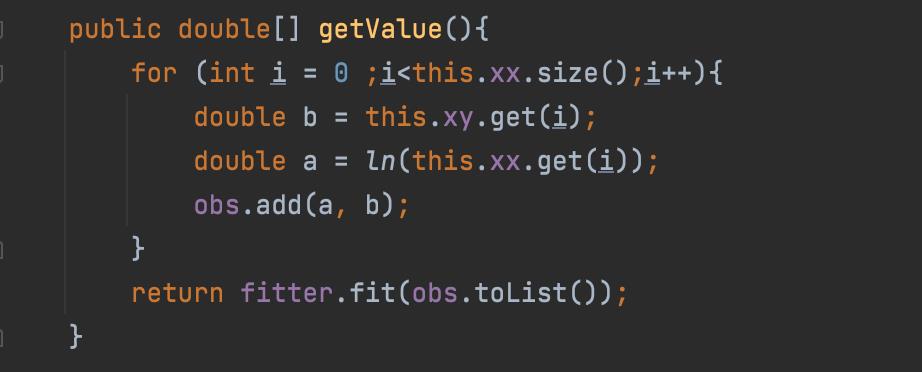
在我们的函数中,我们要做的就是读取样本数据最终汇总结果;
整体的思路就是在mapper阶段,获取所有的数据列表,在最终reducer阶段调用我们计算结果
AggregationBuffer部分代码

Evaluator中的iterate,记录所有的样本数据

最终reducer阶段,进行截距和斜率的最终计算。
代码开发完后,打成jar包,传到服务器中,执行
add jar hdfs://*********/roi_udf.jar;
create temporary function mz_roi as 'com.*****.MzRoi';在hue中直接使用,同时也符合预期

pre_roi的实现
根据截距和斜率产出趋势线公式,对未来N天roi进行预测,这个就是一个典型的udtf 的实现,根据截距,斜率和N天的输入,产出N条预测数据。
UDTF 的实现就比较简单了
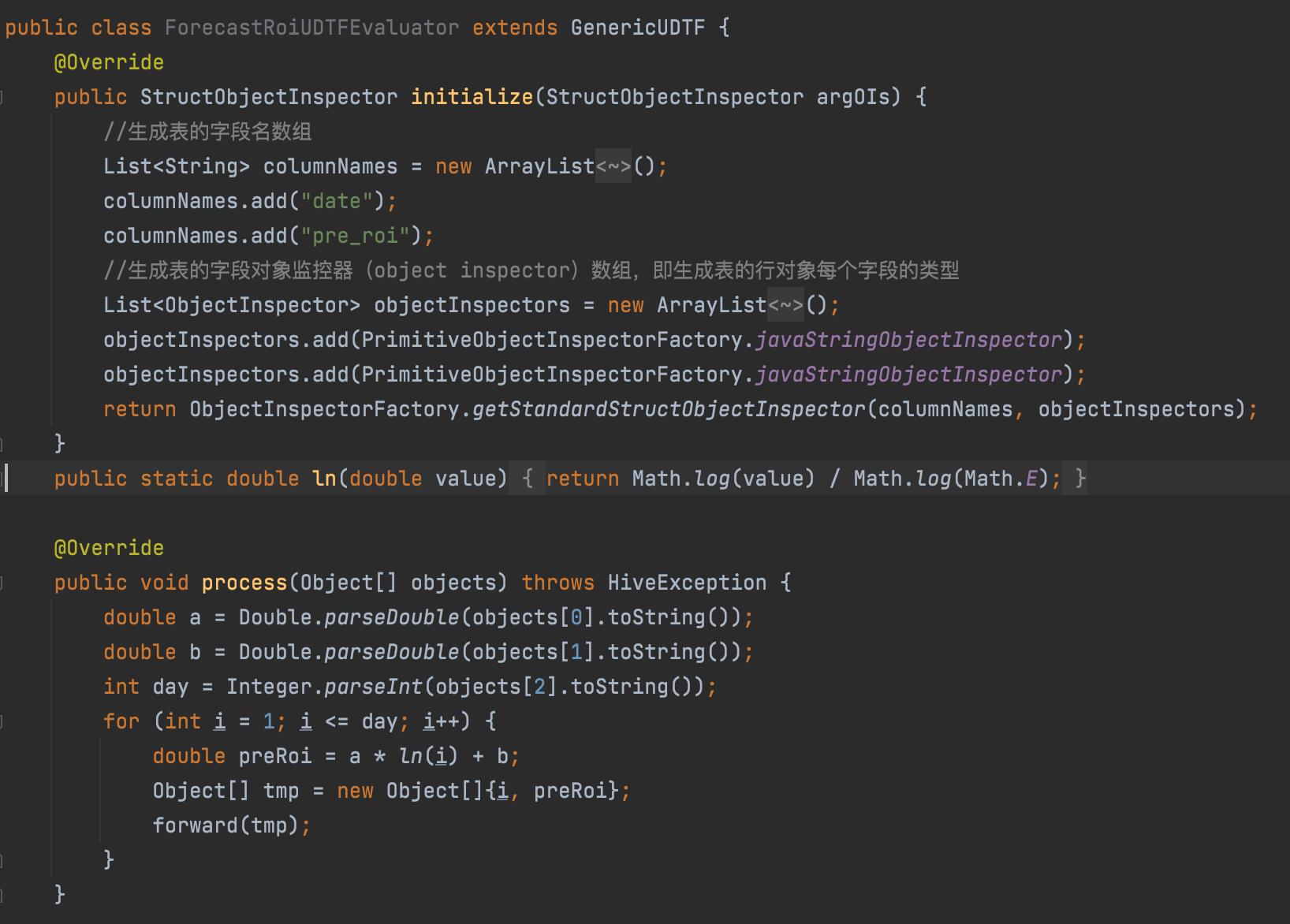
继承GenericUDTF类,主要的处理逻辑就在porcess 中,在这里将一转多的逻辑表达出来,也就完成了,代码中,拿到了a,b,day,分别对应截距,斜率和天数。构建a * ln(i) + b; 直接返回数据就完成了整体的工作。
使用验证可以通过
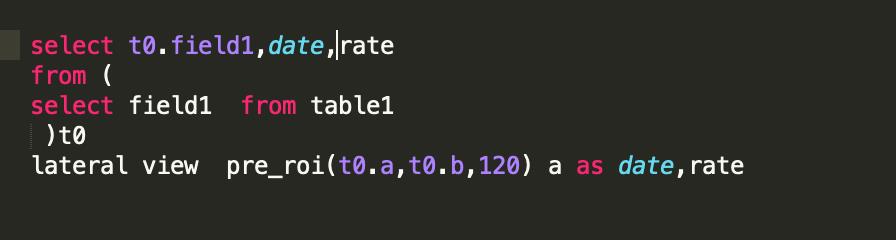
总体来看,相对于UDAF,UDTF的逻辑就要简单很多。
以上是关于趋势拟合实现分析的主要内容,如果未能解决你的问题,请参考以下文章