linux学习记录:shell脚本
Posted 河边小咸鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux学习记录:shell脚本相关的知识,希望对你有一定的参考价值。
shell脚本
- 这是本人在学习shell脚本时的记录,方便日后查询。
- 里面会记录一些自己写的shell脚本,都是在实习中用到的。由此这篇笔记的内容也会不断扩充,也算是记录一下心路历程。
- 默认使用解释器
/bin/bash
目录
零、shell基础
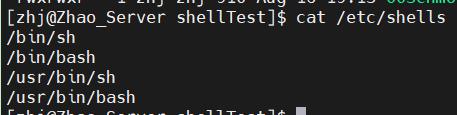
通过命令cat /etc/shells可以查看当前系统支持的解释器。如下图,可以看到这个系统支持解释器sh和bash。可以直接执行解释器文件来进入新的shell命令行,相当于套娃,并可以输入命令exit来退出shell命令行。
然后是几个很常见的快捷键。
bash和sh都是支持使用键盘的上下方向键来查询历史记录的。这样在操作有共同之处时,就可以对之前的命令进行简单修改来更快捷的执行命令。此时ctrl a与ctrl e就会显得很好用,可以避免光标挨个移动到头…
关于清屏的ctrl l,命令clear和它的效果是一样的。但是有一点需要注意,由于现在很多终端是支持鼠标滑轮上下翻滚的(例如图形化发行版的终端和各类模拟终端),所以当输出太多时,清屏后的输出并不能很好的与上文分割。所以我一般会长按回车手动清屏,这样在输出刷屏后,也可以很轻易的翻出此次输出的开头。而ctrl l带给我的,可能是一丝源自强迫症的清爽。
| 操作 | 效果 |
|---|---|
| ctrl a | 移动到最前 |
| ctrl e | 移动到最后 |
| ctrl c | 撤销当前命令 |
| ctrl l | 清屏 |
接着是很重要的输出重定向。
在shell执行完命令后,一般来说都会有输出。这个输出可能是错误输出,例如提示权限不足、参数错误等等;也可能是常规的输出,即命令正确执行后的输出。但是有时候可能只想让输出显示错误信息或正确信息或是都不显示,当然也有可能是想把输出信息保存下来,这时就需要用到输出重定向了。
这里不细说符号功能,只记录一下我在脚本中使用的感受。就目前我用到的场景来看,大部分用到的是2>/dev/null,这个意思是忽略报错信息。比如在find /全盘扫描,扫到/proc进程目录时,由于进程信息改变,很有可能报错找不到文件,这种错误是不重要的所以可以忽略报错信息来确保输出的纯净性。
当然有时也需要把一些内容重定向输出到文件里,比如上面的find找到内容后可能要把找到的内容存放在一个文本文件中保存,这时候就可以使用>或>>。这里要根据情况来选择是>追加还是>>覆盖。总而言之输出重定向用的还是蛮多的。当然输入重定向<我感觉用的也不少,只不过可能没有输出重定向>用的多罢了。
| 符号 | 功能 |
|---|---|
| > | 正确(覆盖) |
| >> | 正确(追加) |
| 2> | 错误(覆盖) |
| 2>> | 错误(追加) |
| &> | 正确&错误(覆盖) |
| &>> | 正确&错误(追加) |
最后要提一嘴的是最常用的符号之一,管道|。
这个涉及到流的概念,可以理解为把管道前面命令的结果流向管道后面的命令,使得流入的结果成为后面命令的输入。
在脚本中,可以对命令进行慢慢的涉及和尝试,所以很可能一个命令会变得很长很复杂,而其中少不了的就是这个管道。在使用管道时要注意一下参数传递的格式,例如在find寻找完数据后,往往要在管道后用xargs处理一下,把结果转为命令行参数,从而可以正常执行后续命令,这东西我感觉用的也挺多的。
一、变量
1. 基础
格式为变量名=变量值,取消变量用unset 变量名,在引用时用$变量名。需要注意的是,等号两边不能有空格,且变量不可以使用数字开头(组成:字母/数字/下划线),当变量已经存在时,会覆盖原来的值,所以如果想要添加变量的值,可以使用变量=${变量}要添加的值这种操作扩充变量。
这里提一嘴:shell脚本里应该是没有Makefile里的:=等操作的,所以想扩充变量内容得使用上面那种重声明覆盖的方法(当然也有别的方法),就这一部分来看,感觉还是Makefile那边方便点。
2. 各种变量类型
2.1 环境变量
- 这部分内容都储存在
/etc/profile内,也有可能在依据某用户配置的~/.bash_profile内 - 使用命令
env可以查看所有环境变量 - 个人感觉常用的环境变量有
PWD、PATH、UID、USER、SHELL、HOME等
2.2 位置变量
- 就是bash内置的变量,储存脚本执行时的参数
- 在执行脚本时可以直接在后面加上参数,而脚本里不用声明,这就是位置变量
- 例如我写了一个脚本
test.sh,启动命令为bash test.sh hello world,则hello和world均为参数(由位置变量储存),在脚本中通过$1、$2这样的格式来指定($1为hello、$2为world)
2.3 预定义变量
- 用来保存进程内相关信息
- 这些变量可以直接使用,且不能赋值
- 个人感觉
$?是我使用最多的预定义变量
| 符号 | 意义 | 在bash内直接调用的结果(bash没有位置变量) |
|---|---|---|
| $0 | 当前所在进程或脚本名 |  |
| $$ | 当前运行进程的PID号 |  |
| $? | 命令执行后的状态 0为正常 其他值为异常 |  |
| $# | 已加载的位置变量个数 |  |
| $* | 所有位置变量的值 |  |
2.4 自定义变量
- 就是用户自己定义的变量
3. 变量扩展内容
3.1 三种定界符
| 符号 | 含义 |
|---|---|
单引号' ' | 禁止扩展 比如$变量视为普通字符 |
双引号" " | 允许扩展 比如$变量会进行替换 |
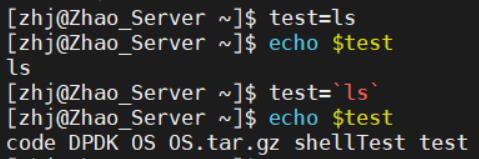
反引号`` | 执行反引号内的命令 并将结果返回 等同于$(命令) |
3.2 read
- 通过read可以从键盘接收内容使其赋值到指定变量上
- 格式为:
read [-p "提示信息"] 变量名 -t可以指定超时时间-s可以指定是否在shell里显示输入的内容(在设定密码之类的内容时候用)
3.3 局部变量和全局变量
- 使用
变量名=变量名这种格式声明的变量,只能在当前shell环境下使用。一旦不在当前shell,这些变量就不存在了。这就是局部变量 - 可以通过
export 变量名=变量名这种格式来声明全局变量,这样所有的shell环境中都可以使用这个变量。这就是全局变量
3.4 变量初始化判定
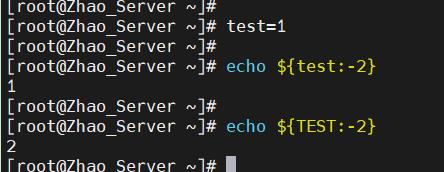
- 有时候不知道变量是否已经存在且初始化,需要有一个默认值,可以通过这样来实现:
${变量:-关键词}- 当变量已初始化,则结果为变量的值;否则结果为后面的关键词
二、运算
1. $[] 运算
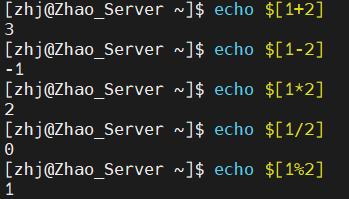
$[]等同于$(())- 格式为:
$[整数1 运算符 整数2 ... ...],其中并不支持小数运算,需要注意 - 计算结果会替换这个表达式本身,可以赋值或者直接
echo
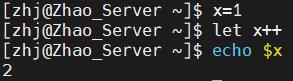
2. 自加自减 运算
- 直接
let就行,还是那一套东西
三、条件测试
1. 字符串条件
| 格式 | 作用 |
|---|---|
[ -z 字符串 ] | 字符串是否为空 |
[ -n 字符串 ] | 字符串是否存在 |
[ 字符串1 == 字符串2 ] | 字符串判等 |
[ 字符串1 != 字符串2 ] | 字符串判不等 |
2. 整数条件
- 格式为
[ 整数1 参数 整数2 ],注意要有空格
| 参数 | 含义 |
|---|---|
| -eq | 等于 |
| -ne | 不等于 |
| -ge | 大于等于 |
| -le | 小于等于 |
| -gt | 大于 |
| -lt | 小于 |
3. 文件条件
- 格式为
[ 参数 文件或目录 ],注意要有空格
| 参数 | 含义 |
|---|---|
| -e | 是否存在 |
| -d | 是否为目录 |
| -f | 是否为文件 |
| -r | 是否有r权限 |
| -w | 是否有w权限 |
| -x | 是否有x权限 |
4. 控制符
- 三个常用的控制符
&&、||、; ;用来分割语句,比如说cd /etc; pwd就是先执行cd再执行pwd&&不管其前面的命令执行是否成功,均执行后面的命令||当前面的命令执行成功时就不执行后面,前面执行失败了就执行后面的命令&&优先级比||高,所以优先执行&&。比如这条命令[ a == a ] && echo Y || echo N,输出就是Y;命令[ a == b] && echo Y || echo N,输出就是N
同理可以这么用:
[ 判断1 ] && [判断2]或[ 判断1 ] || [判断2]
四、if语句
最常用的句式,我一般是按下面这个结构写,then放上面。
if 条件测试;then
操作
fi
然后呢,多重判断结构语法是这样的,就是记住有个then就行。
if 条件测试;then
操作
elif 条件测试;then
操作
else
操作
fi
五、for循环
有两种写法,分别是:
# 第一种
for 变量 in 值列表
do
操作
done
# 第二种
for ((初值;条件;步长))
do
操作
done
第一种的话,我感觉用的比较多,一般是find或是什么检索出的结构列表,通过for来挨个判定操作。比如说下面这种用法:
# 挨个显示/etc/passwd里的用户名
for user in `cat /etc/passwd | awk -F: {'print $1'}`;
do
echo $user;
done;
第二种的话,反正我目前没咋用过,可能以后会用到吧。
for ((i=0;i<=5;i++))
do
echo hello
done
六、while循环
语法格式是这样的:
while 条件测试
do
操作
done
一个简单的例子:
i=0
while [ $i -eq 0 ]
do
echo $i
let i++
done
七、case语句
语法格式是这样的:
case 变量 in
模式1)
操作 ;;
模式2)
操作 ;;
...
*)
操作 ;;
esac
需要注意的是,最终结尾是两个分号。这里的*)相当于c case里的default。
x=4
case x in
1)
echo this is 1 ;;
2)
echo this is 2 ;;
*)
echo error
esac

八、数组
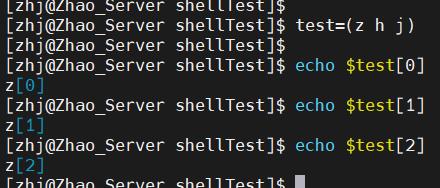
定义很简单,括号括起来,元素之间用空格隔开,例如test=(z h j)。调用时也很简单,大括号加中括号,例如echo ${test[0]}。下面是演示。

如果不加大括号的话,就会输出数组第一个元素加上中括号内容,如下图。所以需要加上大括号来告诉系统中括号内的东西和变量是一体的。
九、shell函数
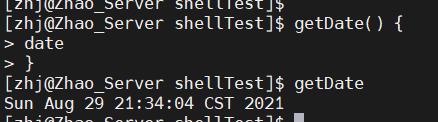
语法格式是这样的:
函数名() {
操作
}
调用的话,直接
函数名 [$1 $2 $3 ...]
就行
例子如下:
十、中断与退出
就是三个东西:continue、break和exit。怎么用也不多说了,跟c里一样。
continue是结束单次循环break是结束一个循环体exit可以退出脚本
十一、字符串处理
1. 显示指定区域
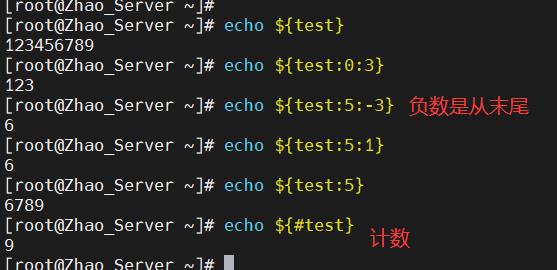
- 语法为
${变量:起始位置:长度},和数组一样下标从0开始计数
2. 字符串替换
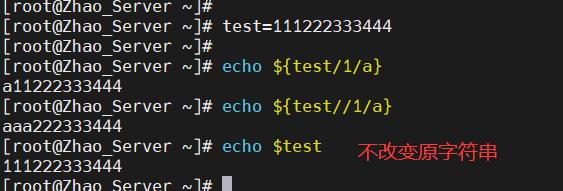
- 替换一次:
${变量/旧字串/新字串} - 替换全部:
${变量//旧字串/新字串}
3. 字符串掐头
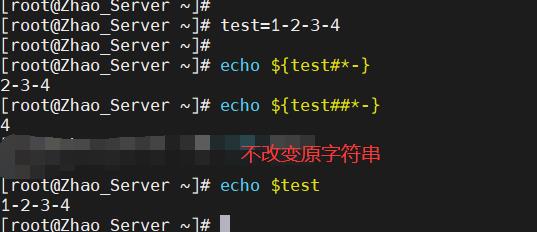
- 从左至右,最短匹配删除:
${变量#关键词} - 从左至右,最长匹配删除:
${变量##关键词}
4. 字符串截取
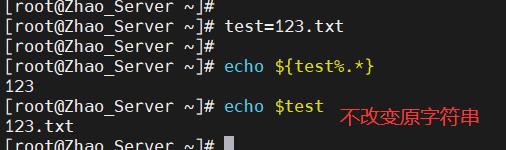
- 语法为:
${变量%关键词}
十二、正则表达式!
首先哈,我感觉这东西很常见,其次呢是非常好用很灵活。这部分内容我也用的挺多的,只能说是熟能生巧,很多符号用着用着就记住了。
基本正则符号:
| 符号 | 意义 | 例子 |
|---|---|---|
| abc | 匹配abc | grep abc ./ |
| ^ | 匹配开头 | grep ^abc ./ |
| $ | 匹配结尾 | grep abc$ ./ |
| [集合] | 匹配集合 | grep “[abc]” ./ |
| [^集合] | 集合取反 | grep “[^abc]” ./ |
| . | 匹配任意单个字符 | grep . ./ |
| * | 匹配前一个字符任意次(可以是0次) | grep ab*c ./ |
| .* | 匹配任意,即上面两个连起来(匹配单个字符任意次) | grep a.*c ./ |
| {n,m} | 匹配前一个字符n到m次 反斜杠是为了转义 下同 | grep “[abc]{2,3}” ./ |
| {n,} | 匹配前一个字符至少n次 | grep “[abc]{2,}” ./ |
| {n} | 匹配前一个字符n次 | grep “[abc]{2}” ./ |
上面这部分的内容是使用最多的,我个人比较常用的是^开头、$结尾以及.*匹配任意。
扩展正则符号:
| 符号 | 意义 |
|---|---|
| + | 匹配前面的字符至少一次 |
| ? | 匹配前面的字符0或1次 |
| () | 组合和保留 |
| | | 或者 |
上面这部分的内容需要加上-E参数,即grep -E 正则表达式。
这部分我用过的好像也就+,只能说用的还是偏少,我感觉上面的基础正则已经够我当前用了。
Perl兼容正则符号:
| 符号 | 意义 |
|---|---|
| \\b | 匹配单词边界 |
| \\w | 匹配字符数字下划线 |
| \\W | 和\\w相反 |
| \\s | 匹配空白 |
| \\d | 匹配数字 |
| \\d+ | 匹配多个数字 |
| \\D | 匹配非数字 |
上面这部分的内容需要加上-P参数,即grep -P 正则表达式。
这部分说实话没咋用过,不过在系统里找脚本学习的时候碰见过\\d。
十三、awk
1. 基础
awk我在写脚本的时候用的非常多,原因就是很好用,对于格式化的数据可以很轻松的筛出想要的那一部分。
- 语法1:
前置命令 | awk [选项] '[条件]{指令}' - 语法2:
awk [选项] '[条件]{指令}' 文件 - 如果想要使用正则,则语法为
/正则表达式/,~为匹配,!~为不匹配
awk我个人认为最常见的用法就是提取文本。例如在ls -l的命令中,如果只想要第一列的权限和第九列的文件名,就可以使用ll / | awk '{print $1,$9}'来输出第一列和第九列的内容。
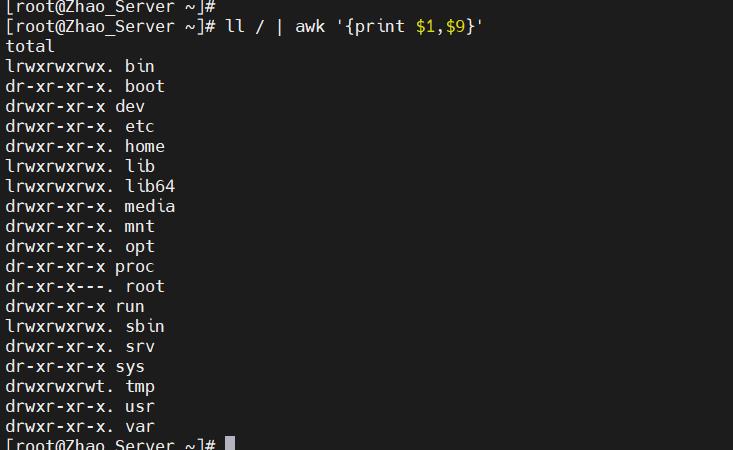
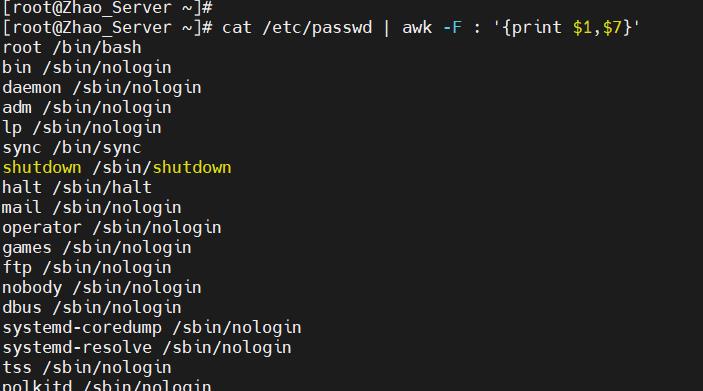
由此可知,awk默认是以空格来分列的。但是很多情况下并不是使用空格来分割,这个时候可以使用-F来指定分隔符。例如如果想读取/etc/passwd里的用户名和它的解释器,就可以使用cat /etc/passwd | awk -F : '{print $1,$7}'来获取,其中指定分隔符为:。
2. 内部变量
| 变量名 | 意义 |
|---|---|
| FS | 保存或设置字段分隔符,例如FS=":",与-F功能一样 |
| $n | 指定分割的第n个字段,例如$1代表第一个字段 |
| $0 | 当前读入的整行文本内容 |
| NF | 记录当前处理行的字段个数(列数) |
| NR | 记录当前已读入行的数量(行数) |
3. BEGIN和END
- 在所有行前处理,BEGIN{}
· 读入第一行文本之前执行
· 一般用来初始化操作 - 逐行处理,{}
· 逐行读入文本执行相应处理
· 是最常见的编辑指令块 - 在所有行后处理,END{}
· 处理完最后一行文本后执行
· 一般用来输出处理结果
4. 判断与比较
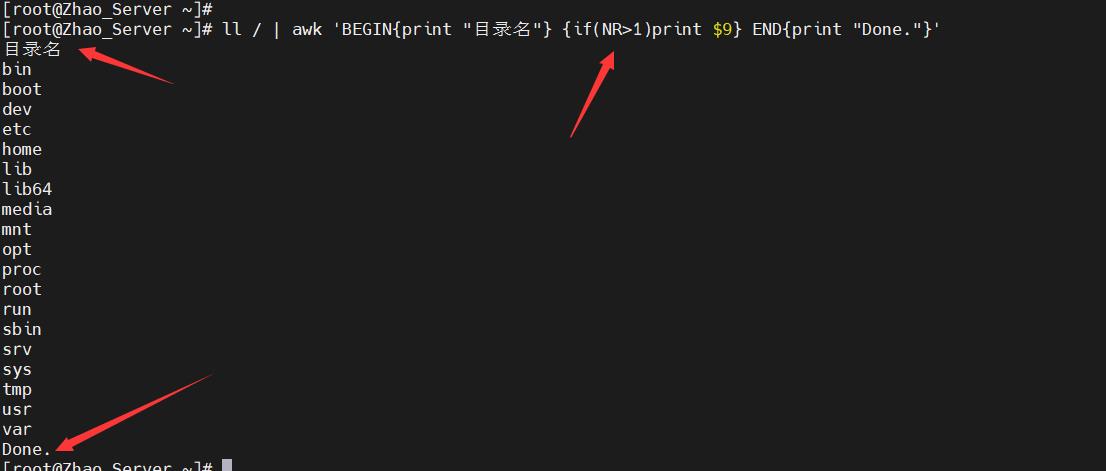
- 在awk里是支持分支
if语句的,并且可以使用!= >= <这样的符号来比较,下图是一个很好的例子 - 例子中判断略去第一行,只对第一行以后的进行判断,因为
ls -l的第一行是total xxx
十四、格式化输出
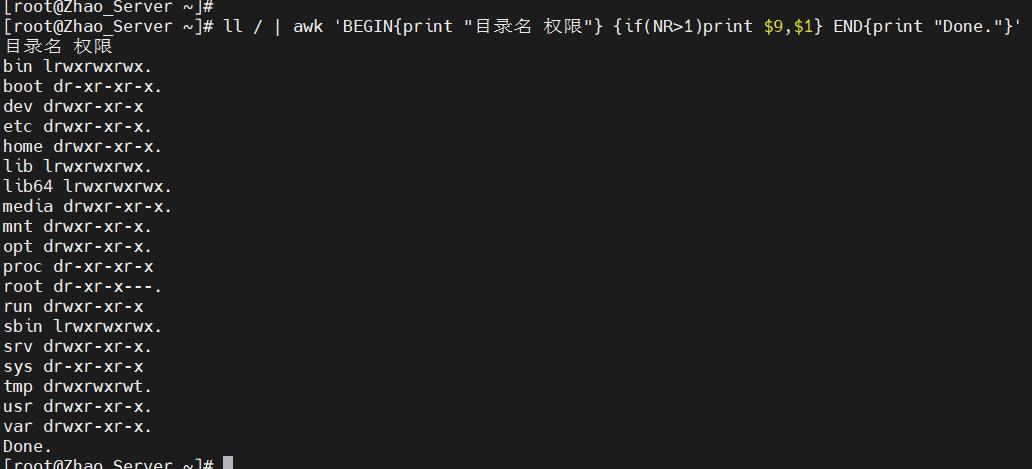
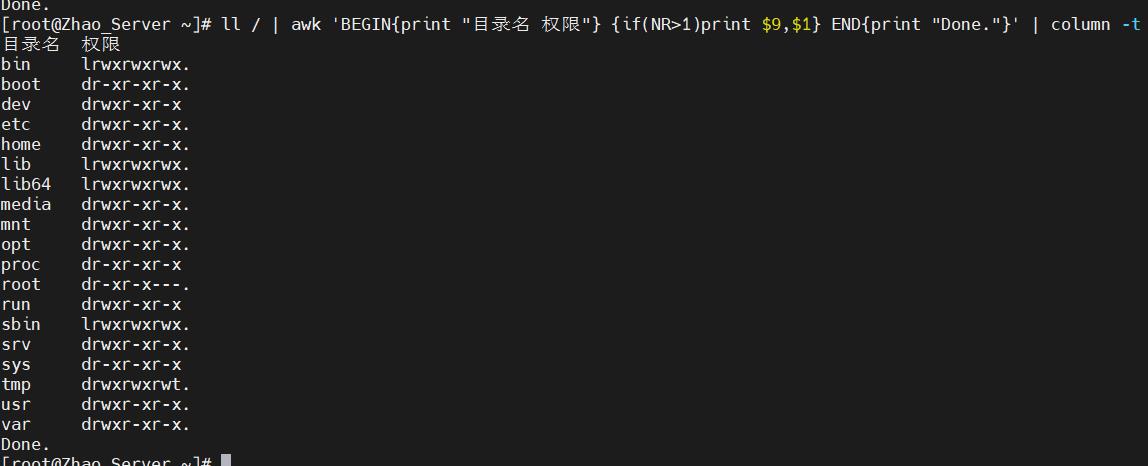
- 格式为:
输出内容 | column -t - 如下图是加与不加的区别
十五、一些自己写的实例
1. 寻找系统中所有可登录的用户
#!/bin/bash
# 可以查看所有未禁用用户
id=1
for user in `cat /etc/passwd | grep -E -v .*nologin$ | awk -F: {'print $1'}`;
do
cat /etc/shadow | grep -E ^$user | grep -E :\\\\$.\\\\$.*\\\\$.*: > /dev/null
if [ $? -eq 0 ];then
echo "$id: $user -- 该用户已设置密码可登录";
let id++;
elif [[ -z `cat /etc/shadow | grep -E ^$user` ]];then
echo "$id: $user -- 该用户在/etc/shadow中不存在";
let id++;
fi
done;
执行效果如下:

解析:
这个脚本我是利用了禁用用户登录的规则来判定此用户是否被禁用(如何判断可以看我的这篇笔记linux学习记录:用户与/etc/passwd与/etc/shadow),通过正则表达式加上awk筛出初步判定没有禁用的用户名,再前去/etc/shadow中通过正则表达式查看密码是否符合规范,即可得知此账号是否被禁。即可输出结果。
以上是关于linux学习记录:shell脚本的主要内容,如果未能解决你的问题,请参考以下文章