知识图谱开发实战:搭建上市公司知识图谱
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识图谱开发实战:搭建上市公司知识图谱相关的知识,希望对你有一定的参考价值。
搭建上市公司知识图谱(二)
学习目标
-
获取上市公司原始数据
-
设计知识图谱数据库
-
知识图谱数据库查询实战
-
使用Cypher语言探索知识图谱数据库
-
使用Python访问知识图谱数据库
1. 获取上市公司公开数据
开发步骤:
- 从
tushare.org获取上市公司列表与行业信息并存储为CSV文件 - 从网站爬取上市公司网页并存储为 HTML 文件
- 解析HTML文件,获取高管信息并存储为 csv 文件
1.1 获取上市公司列表与行业信息
从 tushare.org 获取上市公司列表与行业信息并存储为CSV文件

使用前提:
- 安装Python
- 安装pandas
- lxml也是必须的,正常情况下安装了Anaconda后无须单独安装,如果没有可执行:
pip install lxml
访问:http://tushare.org/classifying.html
概念分类:
import tushare as ts
ts.get_industry_classified()
结果显示:
code name c_name
0 600007 中国国贸 外资背景
1 600114 东睦股份 外资背景
2 600132 重庆啤酒 外资背景
3 600182 S佳通 外资背景
4 600595 中孚实业 外资背景
5 600641 万业企业 外资背景
6 600779 水井坊 外资背景
7 600801 华新水泥 外资背景
8 600819 耀皮玻璃 外资背景
9 000001 平安银行 外资背景
10 000005 世纪星源 外资背景

1.2 代码展示
# 获取股票数据
# 使用 tushare.org
import tushare as ts
# get and save industry classification: 股票行业
df_industry = ts.get_industry_classified()
df_industry.to_csv("./industry.csv", index=False, sep=',')
# get and save concept classification: 股票概念
df_concept = ts.get_concept_classified()
df_concept.to_csv("./concept.csv", index=False, sep=',')
print("股票信息保存成功")
# 股票行业
industry= ts.get_industry_classified()
# 股票概念
concept= ts.get_concept_classified()
print(industry.head())
print(concept.head())
code name c_name
0 600051 宁波联合 综合行业
1 600209 罗顿发展 综合行业
2 600212 江泉实业 综合行业
3 600256 广汇能源 综合行业
4 600576 祥源文化 综合行业
code name c_name
0 600007 中国国贸 外资背景
1 600114 东睦股份 外资背景
2 600132 重庆啤酒 外资背景
3 600182 S佳通 外资背景
4 600595 中孚实业 外资背景
2. 从网站爬取上市公司网页并存储为 HTML文件
2.1 准备环境
pip install requests fake_useragent
爬取网站:http://stockpage.10jqka.com.cn/
分析之后,可以通过股票代码获取公司信息:
http://stockpage.10jqka.com.cn/{}/company.html

2.2 爬取上市公司公开信息
# 使用requests 下载上市公司信息
import requests
from fake_useragent import UserAgent
from requests_html import HTMLSession
# 下载并保存文件
def download_html(code, filename):
headers = {
'User-Agent': UserAgent().random,
}
# url http://stockpage.10jqka.com.cn/600007/company/
url= "http://stockpage.10jqka.com.cn/{}/company/".format(code)
r = requests.get(url, headers=headers)
if r.status_code == 200:
with open(filename, "wb") as fout:
fout.write(r.content)
print("成功下载:", code)
else:
print("下载失败:", r.status_code)
# 遍历所有上市公司
import time
import os.path
import pandas as pd
industry = pd.read_csv("industry.csv", dtype={'code':'object'})
for index, stock in industry.iterrows():
# print( stock['code'])
filename = "./data/{}.html".format(stock['code'])
# 判断文件是否存在
if os.path.isfile( filename ) == False:
download_html(stock['code'], filename)
else:
print("文件已存在:", filename)
time.sleep(1)
爬取整个页面数据,便于后序解析其他数据!
注意事项:
- 数据类型问题, 股票代码code需要指定为 object 类型
- 原因是有 000001 被pandas 转为int 变为 1
# 数据类型问题, code需要指定为 object 类型
industry = pd.read_csv("industry.csv", dtype={'code':'object'})
industry.dtypes
code object
name object
c_name object
dtype: object
3. 解析HTML文件,获取高管信息并存储为 csv 文件
# 解析高管信息
import os
import csv
from lxml import etree
# /html/body/div[3]/div[3]/div[2]/div[2]/div[2]/table/tbody/tr[1]/td[1]/a
def extract_html(code, file_output):
"""解析高管信息
Args:
code: 股票代码
file_output: 存储高管信息到文件
"""
filename = "./data/{}.html".format(code)
# 判断文件是否存在
if os.path.isfile( filename ) == True:
executives = []
with open(filename, 'r', encoding='gbk') as file_page:
content = file_page.read() # 读取HTML代码
html = etree.HTML(content) # XPath解析
# 获取所有详情表格
divs = html.xpath('//div[@id="ml_001"]//div[contains(@class, "person_table")]')
for div in divs:
item = {}
# 姓名
item['name'] = div.xpath('.//thead/tr/td/h3/a/text()')[0].replace(',', '-')
# 职务
item['jobs'] = div.xpath('.//thead/tr[1]/td[2]/text()')[0].replace(',', '/')
# 性别、年龄、教育程度
gender_age_education = div.xpath('.//thead/tr[2]/td[1]/text()')[0].split()
try:
item['gender'] = gender_age_education[0]
if item['gender'] not in ('男', '女'):
item['gender'] = 'null' # null for unknown
except IndexError:
item['gender'] = 'null'
# 异常处理
try:
item['age'] = gender_age_education[1].strip('岁')
try:
item['age'] = int(item['age'])
except ValueError:
item['age'] = -1 # -1 for unknown
except IndexError:
item['age'] = -1
item['code'] = code
executives.append(item)
# 返回所有高管
return executives
extract_html('600051','executives.csv') # 测试代码
import pandas as pd
industry = pd.read_csv("industry.csv", dtype={'code':'object'})
headers = ['name', 'gender', 'age', 'code', 'jobs']
with open("executive.csv", 'w', encoding='utf-8') as file_out:
file_out_csv = csv.DictWriter(file_out, headers)
file_out_csv.writeheader()
for index, stock in industry.iterrows():
# print( stock['code'])
filename = "./data/{}.html".format(stock['code'])
# 判断文件是否存在
if os.path.isfile( filename ) == True:
e = extract_html( stock['code'])
if e != False :
file_out_csv.writerows(e)
print("解析完成:", stock['code'])
[{'name': '李水荣', 'jobs': '董事长/董事', 'gender': '男', 'age': -1, 'code': '600051'},
{'name': '王维和',
'jobs': '副董事长/董事',
'gender': '男',
'age': 65,
'code': '600051'},
{'name': '李彩娥', 'jobs': '董事', 'gender': '女', 'age': 55, 'code': '600051'},
{'name': '俞春萍', 'jobs': '独立董事', 'gender': '女', 'age': 53, 'code': '600051'},
{'name': '郑晓东', 'jobs': '独立董事', 'gender': '男', 'age': 40, 'code': '600051'}]
注意事项:
- 数据文件存在编码问题,要使用 gbk 编码
4. 设计知识图谱数据库
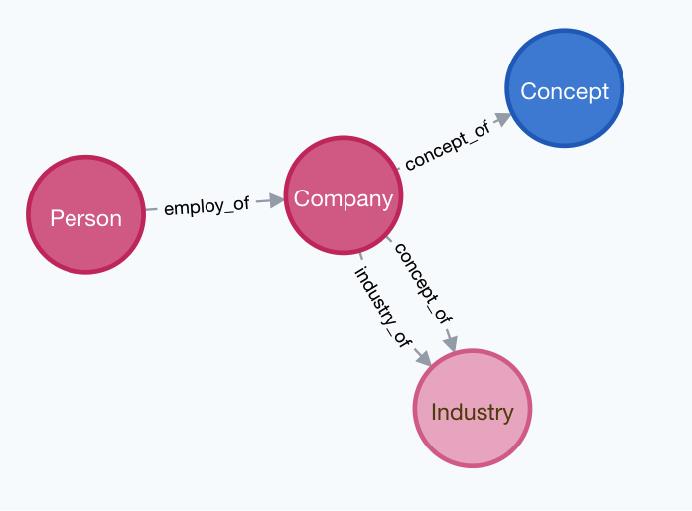
4.1 实体
4种实体:
- 高管: Person
- 公司: Company
- 行业: Industry
- 概念: Concept
4.2 关系
3种关系:
- 高管 -[受雇]-> 公司
- 公司 –[属于]-> 行业
- 公司 –[属于]-> 概念
4.3 属性
属性:
- 公司属性: 股票代码,公司名称
- 高管属性:姓名,年龄,性别
- 雇佣关系属性: 职位
4.4 特殊
特殊公司: ST
- 名称中包括 ST 的单独设计一个 ST 实体, 重点关注
4.5 代码
import os
import csv
import hashlib
def get_md5(string):
"""生成md5
"""
byte_string = string.encode("utf-8")
md5 = hashlib.md5()
md5.update(byte_string)
result = md5.hexdigest()
return result
def build_executive(executive_prep, executive_import):
"""生成Person csv 文件
format -> person_id:ID,name,gender,age:int,:LABEL
label -> Person
"""
print('准备写入数据 {} '.format(executive_import.split('/')[-1]))
with open(executive_prep, 'r', encoding='utf-8') as file_prep, \\
open(executive_import, 'w', encoding='utf-8') as file_import:
# 使用 CSV 方法读取和写入
file_prep_csv = csv.reader(file_prep, delimiter=',')
file_import_csv = csv.writer(file_import, delimiter=',')
headers = ['person_id:ID', 'name', 'gender', 'age:int', ':LABEL']
file_import_csv.writerow(headers)
for i, row in enumerate(file_prep_csv):
if i == 0 or len(row) < 3:
continue
info = [row[0], row[1], row[2]]
# generate md5 according to 'name' 'gender' and 'age'
info_id = get_md5('{},{},{}'.format(row[0], row[1], row[2]))
info.insert(0, info_id)
info.append('Person')
file_import_csv.writerow(info)
print('- 完成转换.')
def build_stock(stock_industry_prep, stock_concept_prep, stock_import):
"""Create an 'stock' file in csv format that can be imported into Neo4j.
format -> company_id:ID,name,code,:LABEL
label -> Company,ST
"""
print('Writing to {} file...'.format(stock_import.split('/')[-1]))
stock = set() # 'code,name'
with open(stock_industry_prep, 'r', encoding='utf-8') as file_prep:
file_prep_csv = csv.reader(file_prep, delimiter=',')
for i, row in enumerate(file_prep_csv):
if i == 0:
continue
code_name = '{},{}'.format(row[0], row[1].replace(' ', ''))
stock.add(code_name)
with open(stock_concept_prep, 'r', encoding='utf-8') as file_prep:
file_prep_csv = csv.reader(file_prep, delimiter=',')
for i, row in enumerate(file_prep_csv):
if i == 0:
continue
code_name = '{},{}'.format(row[0], row[1].replace(' ', ''))
stock.add(code_name)
with open(stock_import, 'w', encoding='utf-8') as file_import:
file_import_csv = csv.writer(file_import, delimiter=',')
headers = ['stock_id:ID', 'name', 'code', ':LABEL']
file_import_csv.writerow(headers)
for s in stock:
split = s.split(',')
ST = False # ST flag
states = ['*ST', 'ST', 'S*ST', 'SST']
info = []
for state in states:
if split[1].startswith(state):
ST = True
split[1] = split[1].replace(state, '')
info = [split[0], split[1], split[0], 'Company;ST']
break
else:
info = [split[0], split[1], split[0], 'Company']
file_import_csv.writerow(info)
print('- done.')
def build_concept(stock_concept_prep, concept_import):
"""Create an 'concept' file in csv format that can be imported into Neo4j.
format -> concept_id:ID,name,:LABEL
label -> Concept
"""
print('Writing to {} file...'.format(concept_import.split('/')[-1]))
with open(stock_concept_prep, 'r', encoding='utf-8') as file_prep, \\
open(concept_import, 'w', encoding='utf-8') as file_import:
file_prep_csv = csv.reader(file_prep, delimiter=',')
file_import_csv = csv.writer(file_import, delimiter=',')
headers = ['concept_id:ID', 'name', ':LABEL']
file_import_csv.writerow(headers)
concepts = set()
for i, row in enumerate(file_prep_csv):
if i == 0:
continue
concepts.add(row[2])
for concept in concepts:
concept_id = get_md5(concept)
new_row = [concept_id, concept, 'Concept']
file_import_csv.writerow(new_row)
print('- done.')
def build_industry(stock_industry_prep, industry_import):
"""Create an 'industry' file in csv format that can be imported into Neo4j.
format -> industry_id:ID,name,:LABEL
label -> Industry
"""
print('Write to {} file...'.format(industry_import.split('/')[-1]))
with open(stock_industry_prep, 'r', encoding="utf-8") as file_prep, \\
open(industry_import, 'w', encoding='utf-8') as file_import:
file以上是关于知识图谱开发实战:搭建上市公司知识图谱的主要内容,如果未能解决你的问题,请参考以下文章