Python,OpenCV基于支持向量机SVM的手写数字OCR
Posted 程序媛一枚~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python,OpenCV基于支持向量机SVM的手写数字OCR相关的知识,希望对你有一定的参考价值。
Python,OpenCV基于支持向量机SVM的手写数字OCR
上一节介绍了基于KNN的手写数字OCR+字母OCR,这一节将介绍基于支持向量机SVM的手写数字OCR。
1. 效果图
简单线性向量机训练效果图如下:
图中有4个点,3个趋于白色点,一个灰黑色点,可以看到分割线的决策边界很明显。

非线性向量机训练数据效果图如下:
下图中绿色、蓝色点杂糅在一起,中间的决策边界是非线性的,但可以近似为线性。边界有灰色圆圈的点是 支持向量,依赖这些少量的数据就可以找到 决策边界。

2. SVM及原理
支持向量机SVM(Supported Vector Machines)
要了解SVM,首先需要了解线性可分数据及线性不可分数据,简单来说,就是在平面或多维有一堆点进行分类,能否用一根线分隔以分类彼此。
-
线性可分数据
KNN需要计算测试数据到所有点的距离,当数据量比较大的时候,需要较大的内存来存储。 可以有另一种思路:找到一条线 f(x)=ax_1+bx_2+c ,它将数据分为两个区域。当得到一个新的 test_data X 时,只需将其替换为 f(x)。如果 f(X) > 0,则属于蓝色组,否则属于红色组。
称这条线为 决策边界,它非常简单且节省内存。 这种可以用直线(或更高维的超平面)一分为二的数据称为 线性可分数据。
-
低维空间中的非线性可分离数据在高维空间中变为线性可分离的可能性更大。
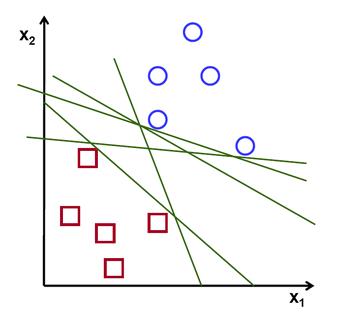
在上图中可以看到很多这样的线条是可能的。要拿哪一个?非常直观,可以说这条线应该尽可能远离所有点。
走最远的线路将提供更多的抗噪能力。所以SVM所做的就是找到一条到训练样本最小距离最大的直线(或超平面)。
- 要找到这个决策边界,并不需要所有数据,只需要那些靠近相反群体的数据。
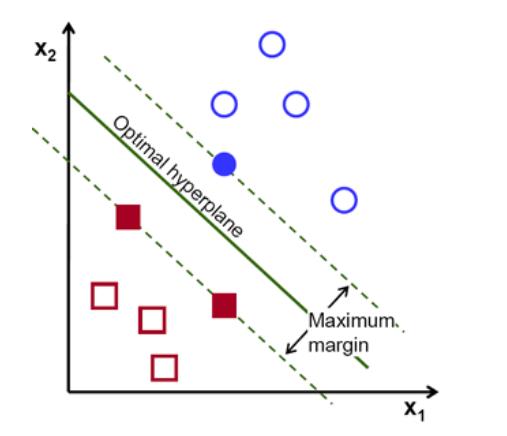
在该图像中,它们是一个蓝色实心圆圈和两个红色实心方块。我们可以称它们为支持向量,穿过它们的线称为支持平面。它们足以找到决策边界。
- 权重向量决定决策边界的方向,而偏置点决定其位置。
2. 源码
2.1 SVM的手写数字OCR
# 使用SVM进行手写数据OCR
# 在KNN中直接使用像素强度作为特征向量。
# 在SVM中使用方向梯度直方图(HOG Histogram of Oriented Gradients)作为特征向量。
# 在这里,使用二阶矩对图像进行反扭曲。
import cv2
import numpy as np
SZ = 20
bin_n = 16 # Number of bins
svm_params = dict(kernel_type=cv2.ml.SVM_LINEAR,
svm_type=cv2.ml.SVM_C_SVC,
C=2.67, gamma=5.383)
affine_flags = cv2.WARP_INVERSE_MAP | cv2.INTER_LINEAR
# 左图像是原始图像,右图像是倾斜图像。
def deskew(img):
m = cv2.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11'] / m['mu02']
M = np.float32([[1, skew, -0.5 * SZ * skew], [0, 1, 0]])
img = cv2.warpAffine(img, M, (SZ, SZ), flags=affine_flags)
return img
# (HOG Histogram of Oriented Gradients)方向梯度直方图
def hog(img):
gx = cv2.Sobel(img, cv2.CV_32F, 1, 0)
gy = cv2.Sobel(img, cv2.CV_32F, 0, 1)
mag, ang = cv2.cartToPolar(gx, gy)
# 量化 (0...16)的binvalues
bins = np.int32(bin_n * ang / (2 * np.pi))
# 分成四个子块
bin_cells = bins[:10, :10], bins[10:, :10], bins[:10, 10:], bins[10:, 10:]
mag_cells = mag[:10, :10], mag[10:, :10], mag[:10, 10:], mag[10:, 10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists)
return hist
img = cv2.imread('images/digits.png', 0)
print(img.shape) # (1000,2000)
cells = [np.hsplit(row, 100) for row in np.vsplit(img, 50)]
print(len(cells)) # 50*100
# 一半数据用于训练,一半用于测试(前50列,后50列)
train_cells = [i[:50] for i in cells]
test_cells = [i[50:] for i in cells]
# cv2.imshow("img", train_cells[0][0])
# cv2.imshow("deskew", deskew(train_cells[0][0]))
# cv2.waitKey(0)
# 训练数据
deskewed = [list(map(deskew, row)) for row in train_cells]
hogdata = [list(map(hog, row)) for row in deskewed]
trainData = np.float32(hogdata).reshape(-1, 64)
responses = np.repeat(np.arange(10), 250)[:, np.newaxis]
print('trainData: ', type(trainData), len(trainData))
print('responses: ', type(responses), responses.shape, len(responses))
print(responses[0])
svm = cv2.ml.SVM_create()
svm.setGamma(svm_params['gamma'])
svm.setC(svm_params['C'])
svm.setKernel(cv2.ml.SVM_LINEAR)
svm.setType(cv2.ml.SVM_C_SVC)
svm.train(trainData, cv2.ml.ROW_SAMPLE, responses)
# 把训练的数据及模型保存下来
svm.save('images/svm_data.dat')
# 测试数据
deskewed = [list(map(deskew, row)) for row in test_cells]
hogdata = [list(map(hog, row)) for row in deskewed]
testData = np.float32(hogdata).reshape(-1, bin_n * 4)
result = svm.predict(testData)[1]
print('result: ', type(result))
print('responses: ', type(responses))
# 检查准确度
mask = result == responses
correct = np.count_nonzero(mask)
print('correct: ', correct)
# SVM得到93.8%的准确度,比KNN的91.76%要高一些
print(correct * 100.0 / len(list(result)))
2.2 非线性SVM
from __future__ import print_function
import random as rng
import cv2 as cv
import numpy as np
NTRAINING_SAMPLES = 100 # Number of training samples per class
FRAC_LINEAR_SEP = 0.9 # Fraction of samples which compose the linear separable part
# 可视化窗口大小
WIDTH = 512
HEIGHT = 512
I = np.zeros((HEIGHT, WIDTH, 3), dtype=np.uint8)
# 随机生成训练数据
trainData = np.empty((2 * NTRAINING_SAMPLES, 2), dtype=np.float32)
labels = np.empty((2 * NTRAINING_SAMPLES, 1), dtype=np.int32)
rng.seed(100) # 随机生成分类标签
# 为训练数据设置线性分离区
# Set up the linearly separable part of the training data
nLinearSamples = int(FRAC_LINEAR_SEP * NTRAINING_SAMPLES)
# 为分类1生成随机点
trainClass = trainData[0:nLinearSamples, :]
# x在[0,0.4]
c = trainClass[:, 0:1]
c[:] = np.random.uniform(0.0, 0.4 * WIDTH, c.shape)
# y在[0, 1)
c = trainClass[:, 1:2]
c[:] = np.random.uniform(0.0, HEIGHT, c.shape)
# 为分类2生成随机点
trainClass = trainData[2 * NTRAINING_SAMPLES - nLinearSamples:2 * NTRAINING_SAMPLES, :]
# x在 [0.6, 1]
c = trainClass[:, 0:1]
c[:] = np.random.uniform(0.6 * WIDTH, WIDTH, c.shape)
# y在 [0, 1)
c = trainClass[:, 1:2]
c[:] = np.random.uniform(0.0, HEIGHT, c.shape)
# 为测试数据集的分类1,2分别生成随机点
trainClass = trainData[nLinearSamples:2 * NTRAINING_SAMPLES - nLinearSamples, :]
# x在[0.4,0.6]
c = trainClass[:, 0:1]
c[:] = np.random.uniform(0.4 * WIDTH, 0.6 * WIDTH, c.shape)
# y在[0,1]
c = trainClass[:, 1:2]
c[:] = np.random.uniform(0.0, HEIGHT, c.shape)
# 设置分类标签1及2
labels[0:NTRAINING_SAMPLES, :] = 1 # 分类1
labels[NTRAINING_SAMPLES:2 * NTRAINING_SAMPLES, :] = 2 # 分类2
# 开始训练,首先设置支持向量机SVM参数
print('Starting training process')
# 初始化
svm = cv.ml.SVM_create()
svm.setType(cv.ml.SVM_C_SVC)
svm.setC(0.1)
svm.setKernel(cv.ml.SVM_LINEAR)
svm.setTermCriteria((cv.TERM_CRITERIA_MAX_ITER, int(1e7), 1e-6))
# 训练SVM
svm.train(trainData, cv.ml.ROW_SAMPLE, labels)
# 结束训练
print('Finished training process')
# 展示决策区域(绘制蓝色,绿色) 分类1为绿色,分类2为蓝色
green = (0, 100, 0)
blue = (100, 0, 0)
for i in range(I.shape[0]):
for j in range(I.shape[1]):
sampleMat = np.matrix([[j, i]], dtype=np.float32)
response = svm.predict(sampleMat)[1]
if response == 1:
I[i, j] = green
elif response == 2:
I[i, j] = blue
# 展示测试数据
thick = -1
# 分类1 绿色
for i in range(NTRAINING_SAMPLES):
px = trainData[i, 0]
py = trainData[i, 1]
cv.circle(I, (px, py), 3, (0, 255, 0), thick)
# 分类2 蓝色
for i in range(NTRAINING_SAMPLES, 2 * NTRAINING_SAMPLES):
px = trainData[i, 0]
py = trainData[i, 1]
cv.circle(I, (px, py), 3, (255, 0, 0), thick)
# 展示支持向量
thick = 2
sv = svm.getUncompressedSupportVectors()
for i in range(sv.shape[0]):
cv.circle(I, (sv[i, 0], sv[i, 1]), 6, (128, 128, 128), thick)
cv.imwrite('non_linear_svms_result.png', I) # 保存图片
cv.imshow('SVM for Non-Linear Training Data', I) # 展示图片结果
cv.waitKey()
参考
以上是关于Python,OpenCV基于支持向量机SVM的手写数字OCR的主要内容,如果未能解决你的问题,请参考以下文章