pytorch学习:xavier分布和kaiming分布
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch学习:xavier分布和kaiming分布相关的知识,希望对你有一定的参考价值。
1 函数的增益值
torch.nn.init.calculate_gain(nonlinearity, param=None)提供了对非线性函数增益值的计算。
增益值gain是一个比例值,来调控输入数量级和输出数量级之间的关系。
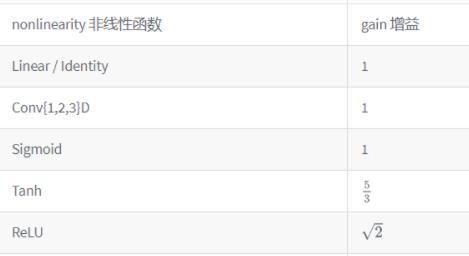
常见的非线性函数的增益值(gain)有:
2 fan_in和fan_out
以下是pytorch计算fan_in和fan_out的源码
def _calculate_fan_in_and_fan_out(tensor):
dimensions = tensor.ndimension()
if dimensions < 2:
raise ValueError("Fan in and fan out can not be computed
for tensor with fewer than 2 dimensions")
#如果tensor的维度小于两维,那么报错
if dimensions == 2: # Linear
fan_in = tensor.size(1)
fan_out = tensor.size(0)
else:
num_input_fmaps = tensor.size(1)
num_output_fmaps = tensor.size(0)
receptive_field_size = 1
if tensor.dim() > 2:
receptive_field_size = tensor[0][0].numel()
#tensor[0][0].numel():tensor[0][0]元素的个数
fan_in = num_input_fmaps * receptive_field_size
fan_out = num_output_fmaps * receptive_field_size
return fan_in, fan_out
- 对于全连接层,fan_in是输入维度,fan_out是输出维度;
- 对于卷积层,设其维度为
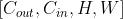 ,其中H × W为kernel规模。则fan_in是
,其中H × W为kernel规模。则fan_in是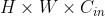 ,fan_out是
,fan_out是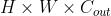
3 Xavier初始化
xavier初始化可以使得输入值x的方差和经过网络层后的输出值y的方差一致。
3.1 xavier均匀分布
torch.nn.init.xavier_uniform_(
tensor,
gain=1) 填充一个tensor,使得这个tensor满足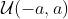
其中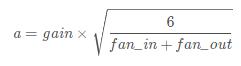
import torch
w = torch.empty(3, 5)
torch.nn.init.xavier_uniform_(w,
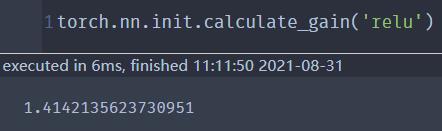
gain=torch.nn.init.calculate_gain('relu'))
w
'''
tensor([[-0.3435, -0.4432, 0.1063, 0.6324, 0.3240],
[ 0.6966, 0.6453, -1.0706, -0.9017, -1.0325],
[ 1.2083, 0.5733, 0.7945, -0.6761, -0.9595]])
'''3.2 xavier正态分布
torch.nn.init.xavier_normal_(
tensor,
gain=1)填充一个tensor,使得这个tensor满足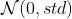
其中,std满足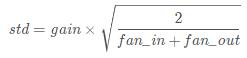
import torch
w = torch.empty(3, 5)
torch.nn.init.xavier_normal_(w,
gain=torch.nn.init.calculate_gain('relu'))
w
'''
tensor([[ 0.2522, -1.3404, -0.7371, -0.0280, -0.9147],
[-0.1330, -1.4434, -0.2913, -0.1084, -0.9338],
[ 0.8631, 0.1877, 0.8003, -0.0865, 0.9891]])
'''4 Kaiming 分布
Xavier在tanh中表现的很好,但在Relu激活函数中表现的很差,所何凯明提出了针对于relu的初始化方法。
pytorch默认使用kaiming正态分布初始化卷积层参数。
4.1 kaiming均匀分布
torch.nn.init.kaiming_uniform_(
tensor,
a=0,
mode='fan_in',
nonlinearity='leaky_relu')填充一个tensor,使得这个tensor满足U(−bound,bound)
其中,bound满足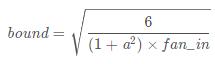
| a | 激活函数的负斜率(对于leaky_relu来说) 如果激活函数是relu的话,a为0 |
| mode | 默认为fan_in模式,可以设置为fan_out模式 fan_in可以保持前向传播的权重方差的数量级,fan_out可以保持反向传播的权重方差的数量级 |
import torch
w = torch.empty(3, 5)
torch.nn.init.kaiming_uniform_(
w,
mode='fan_in',
nonlinearity='relu')
'''
tensor([[ 0.8828, 0.0301, 0.9511, -0.0795, -0.9353],
[ 1.0642, 0.8425, 0.1968, 0.9409, -0.7710],
[ 0.3363, 0.9057, -0.1552, 0.5057, 1.0035]])
'''
import torch
w = torch.empty(3, 5)
torch.nn.init.kaiming_uniform_(
w,
mode='fan_out',
nonlinearity='relu')
w
'''
tensor([[-0.0280, -0.5491, -0.4809, -0.3452, -1.1690],
[-1.1383, 0.6948, -0.3656, 0.8951, -0.3688],
[ 0.4570, -0.5588, -1.0084, -0.8209, 1.1934]])
'''4.2 kaiming正态分布
torch.nn.init.kaiming_normal_(
tensor,
a=0,
mode='fan_in',
nonlinearity='leaky_relu')参数的意义同4.1 kaiming均匀分布
填充一个tensor,使得这个tensor满足
其中,std满足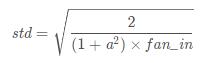
import torch
w = torch.empty(3, 5)
torch.nn.init.kaiming_normal_(
w,
mode='fan_out',
nonlinearity='relu')
w
'''
tensor([[ 0.9705, 1.6935, -0.4261, 1.1065, 1.0238],
[-0.3599, -0.8007, 1.3687, 0.1199, 0.4077],
[ 0.5240, -0.5721, -0.2794, 0.3618, -1.1206]])
'''
以上是关于pytorch学习:xavier分布和kaiming分布的主要内容,如果未能解决你的问题,请参考以下文章
人脸口罩检测(含运行代码+数据集)Pytorch+TensorRT+Xavier NX
Jetson-Xavier-NX刷机+pytorch环境配置+yolov5运行
资源分享jetson xavier nx(aarch64)平台上的pytorch1.8.0+torchvision0.9.0(python=3.6)