图解最大熵原理(The Maximum Entropy Principle)
Posted 哦...
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解最大熵原理(The Maximum Entropy Principle)相关的知识,希望对你有一定的参考价值。
这个“熵“并不是指热力学上熵的概念,而是由信息论男神克劳德·艾尔伍德·香农(Claude Elwood Shannon)在1948年提出的“信息熵“,用来描述信息的不确定程度。
信息熵公式:
H = − ∑ p ( x ) l o g p ( x ) , H = - \\sum p(x) logp(x),H=−∑p(x)logp(x),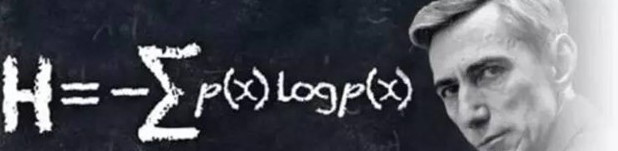
这个听起来很神奇的概念,其实蕴含着最朴素最简洁的思想,看下去你就能体会这一点了。
先来问个问题,如果给你一颗骰子,你觉得分别掷到1,2,…,6的概率是多少?
我觉得你肯定会立刻就回到我,答案是1/6。
很好,如果你知道答案是1/6,就说明其实你已经掌握了最大熵原理。
对于这个骰子问题,我们并不知道它到底是均匀的还是不均匀的,我们唯一知道的条件是1-6出现的总概率总是等于1的。
我们把这个已知的条件称为“约束条件“。除了约束条件,我们对这个骰子一无所知,所以最符合现实的假设就是这个骰子是个均匀的骰子,每一点出现的概率是一个等概率事件。
所谓的最大熵原理其实就是指包含已知信息,不做任何未知假设,把未知事件当成等概率事件处理。
好,再来看个例子,假设你去参加抽奖活动,有5个盒子ABCDE,奖品就放在这5个盒子中的一个,请问奖品在ABCDE盒子里的概率分别是多少?
其实和骰子问题一样,我们除了知道奖品一定在其中一个盒子里(约束条件),但是对奖品到底在哪个盒子里一点额外的信息都没有,所以只能假设奖品在每个盒子里的概率都是1/5(等概率)。
这时有个围观抽奖多时的吃瓜群众根据他的观察事实决定给你点提示,他说,奖品在A和B盒子里的概率总共是3/10。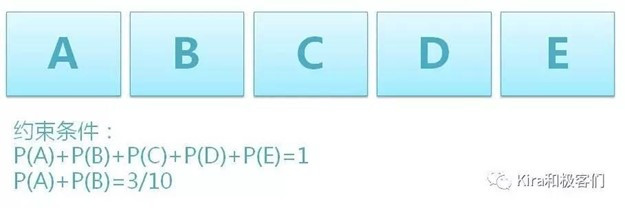
也就是说此时你知道了额外信息:P(A)+P(B)=3/10,你得到了新的约束条件。
那么这个时候我再问你,奖品分别在各个盒子里的概率是多少呢?
根据最大熵原理,我们加入新的约束条件,然后继续把剩下的做等概率处理。
虽然P(A)+P(B)=3/10,但是我们并不知道A和B各自的贡献是多少,所以也只能假设它们两个贡献依然是平均的,所以各自就是3/20。
因为P(A)+P(B)=3/10,所以P©+P(D)+P(E)=7/10,但是我们依然不知道这三者的贡献,所以还是假设它们等概率,因此每一项就是7/30。
这就是通过最大熵原理处理概率问题了。
怎么样?是不是很简单?现在你估计要问这种简单的道理为什么还要搞出什么最大熵原理?
因为只有引入“信息熵“的概率,我们才可以把上述这些个看起来很简单的例子“量化“,然后用它来解决更加复杂的问题。
现在我们来看看信息熵到底是怎么定义的,(其实就是上面那张香农的图)。一个系统的信息熵其实就是系统中每一个事件的概率乘以log概率,然后把所有事件相加后取负数。
因为概率总是在0-1之间,所以log后会小于0,取了负号以后熵就是正数了。
log如果以2为底数的话,信息熵的单位就是比特(bit),以e为底数的话,信息熵的单位就是奈特(nat),以10为底数的话,单位就是哈脱特(hat)。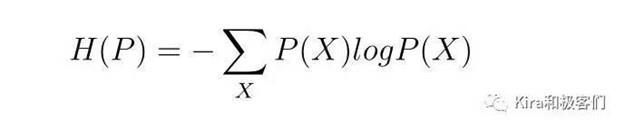
我们来看一枚硬币的例子,对于一枚均匀硬币,抛一次,正面朝上和背面朝上的概率各为0.5。
那么它总共的信息熵就是log2,如果以2为底计算话就是1bit的信息熵。
根据我们之前讲过的例子,0.5这个概率应该是满足最大熵原理的(等概率)。
既然我们已经明确给出了信息熵的定义那么根据这个公式计算的话能不能得到0.5这个概率使系统的熵最大呢?
换言之,等概率让系统的熵最大到底是不是真的?
为了验证这一点,我们假设抛硬币出现正面的概率是p,那么出现背面的概率就是1-p(注意,1-p其实就是包含了约束条件,因为两者的总和总是1)。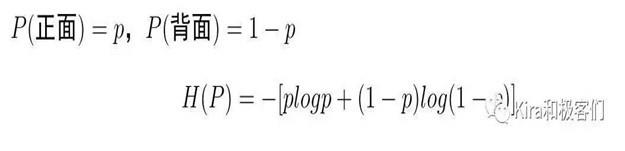
接下来我们要找到一个p,让H§最大,也就是熵最大。
求最大也就是求这个函数的极值,学过高数的小伙伴们都知道对于这个问题,求导等于0。也就是说H§’=0的解,函数在这点的值不是最大就是最小。
我们解方程H§’=0,得到当p=0.5的时候,函数H§达到极值(此时是极大值,你可以代入其它p值,会发现结果比p=0.5的时候小。)。
所以也就是说p=0.5的时候(等概率),系统的熵最大。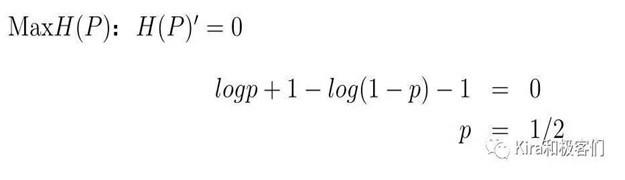
硬币是一个二元系统(一正一反两个概率),我们也可以把这个结论推广到一般情况:对于一个有n个事件的系统,每一个事件发生的概率为pi,唯一已知的约束条件是事件发生的总和等于1。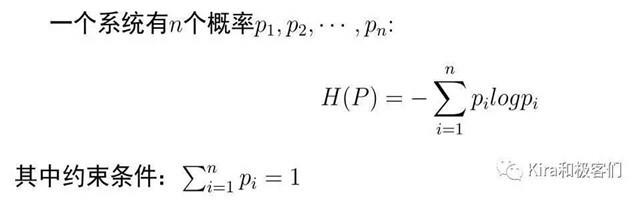
为了求出满足最大熵的事件概率pi,我们首先构造Lagrange函数:就是把需要满足的约束条件加到H§后(见第二项)。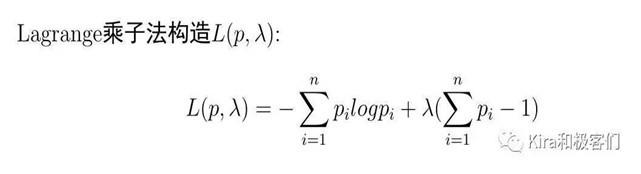
然后老规矩,求这个函数的极值,还是求导等于0。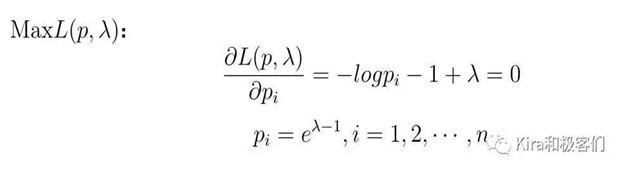
求解得到的pi具有未知参数λ(来自约束项),于是我们可以利用约束条件进一步求解。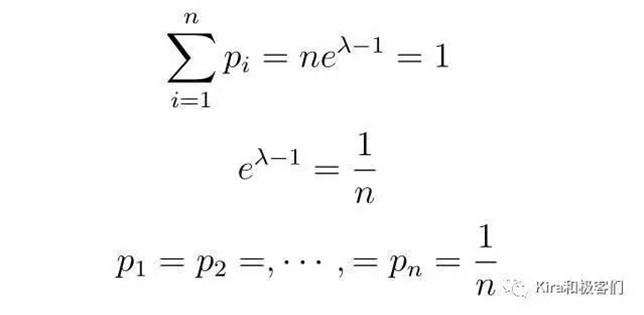
最终我们会发现,对于一个含有n个事件的系统,熵最大时,事件的概率必然满足等概率。
所以对于一个符合最大熵原理的掷骰子模型,每一点出现的概率就是1/6,对于一个从5个盒子中抽奖的事件,奖品在每个盒子中的概率就是1/5。
至此,我们可以发现信息熵的定义的确能够描述并且量化那些生活中看起来很简单但是却总觉得有点说不清楚的问题。
由于下面要继续用到Lagrange乘子法,所以我们给大家简单解释下这个到底是什么东西。
对于一般的求极值问题我们都知道,求导等于0就可以了。但是如果我们不但要求极值,还要求一个满足一定约束条件的极值,那么此时就可以构造Lagrange函数,其实就是把约束项添加到原函数上,然后对构造的新函数求导。
看张图就很容易理解了。
对于一个要求极值的函数f(x,y),图上的蓝圈就是这个函数的等高图,就是说f(x,y)=C1,C2,…Cn分别代表不同的数值(每个值代表一圈,等高图),我要找到一组(x,y),使它的Ci值越大越好,但是这点必须满足约束条件g(x,y)(在黄线上)。
也就是说f(x,y)和g(x,y)相切,或者说它们的梯度▽f和▽g平行,因此它们的梯度(偏导)成倍数关系(假设为λ倍)。
因此把约束条件加到原函数后再对它求导,其实就等于满足了下图上的式子。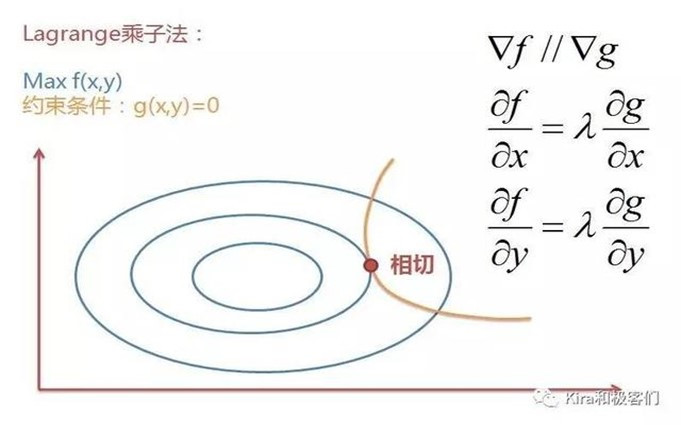
大致理解了Lagrange乘子法的意义后,我们来用数学化的信息熵定义解决之前提过的多了一个约束条件的盒子抽奖问题。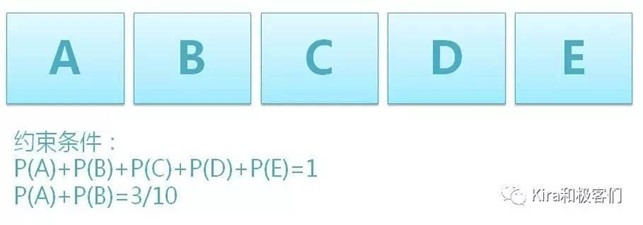
为了方便描述,我们用数字12345代替字母ABCDE,因此这个系统中一共有5个概率,分别是p1,p2,p3,p4,p5。
并且包含两个约束条件:1. 总概率和=1; 2. p1+p2=3/10。
根据之前的解释,为了求解包含约束条件的函数极值,我们构造Lagrange函数: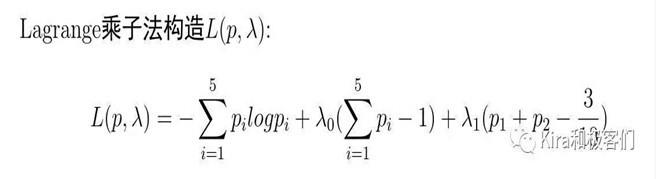
由于系统中包含两个约束条件,所以添加两项,两个参数λ0,λ1(当有n个约束条件时,就是添加n项,λ0,λ1,…,λn)。
对概率pi求偏导等于0(首先固定λ0,λ1,假设它们是已知参数):
根据上式,我们可以解得: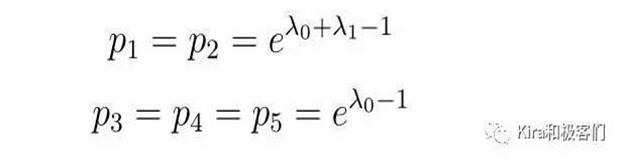
之后代入之前构造的Lagrange函数,并对λ求偏导,目的在于寻找使L最大的λ: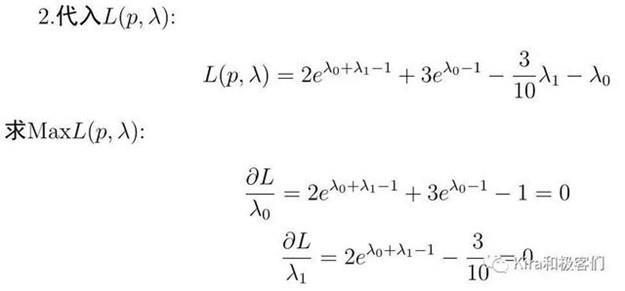
最后,我们可以解出:
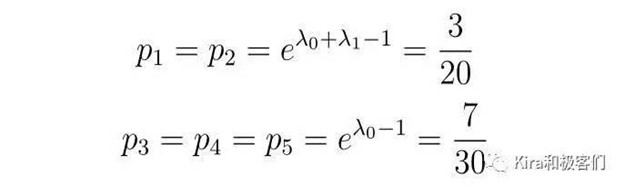
结果与我们之前的直观计算结果是相同的,再一次证明,最大熵原理就是对于未知信息的等概率处理。
好了,至此我觉得你应该已经了解了什么是最大熵原理,并且如何根据最大熵原理处理系统中的概率问题。
再次强调一下最大熵原理的本质:系统中事件发生的概率满足一切已知约束条件,不对任何未知信息做假设,也就是对于未知的,当作等概率处理。
当使用数学方法计算时,寻找满足系统的熵最大时的事件概率。
我们之前提过信息熵表示不确定程度,所以熵最大,也就是系统的不确定程度最大,系统中没有任何个人的主观假设。
以硬币为例,你当然也可以硬币正面出现的概率是0.6,背面是0.4,但是这种假设中就包含了你的个人假设,并不是完全客观的,当然你可以通过后续实验验证你的观点,但是在一开始,在你没有得到任何信息的前提下,假设正面和背面出现的概率各是0.5才是最客观的。
这里我们只是通过简单的例子让大家理解最大熵原理,在语音处理等领域,很多时候是无法直接通过代入约束条件得到满足极值的解的,也就是说往往当你得到了pi(λ)后(用λ表示的pi)后,便无法继续通过对λ求偏导得到最终pi。
所以则需要通过迭代算法等数值解法继续求解pi,这里我们就不展开了,有兴趣的小伙伴们可以查阅诸如改进的迭代尺度法和牛顿法等(参考资料)。
参考资料:
-
1.《统计学习方法》李航
-
2.《数学之美》 吴军
以上是关于图解最大熵原理(The Maximum Entropy Principle)的主要内容,如果未能解决你的问题,请参考以下文章