05-flink-1.10.1-flink on yarn 流处理WordCount
Posted 逃跑的沙丁鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了05-flink-1.10.1-flink on yarn 流处理WordCount相关的知识,希望对你有一定的参考价值。
1 启动相应服务
① 启动 hdfs ,启动yarn
② 事先部署好flink
2 打包WordCount代码成jar包
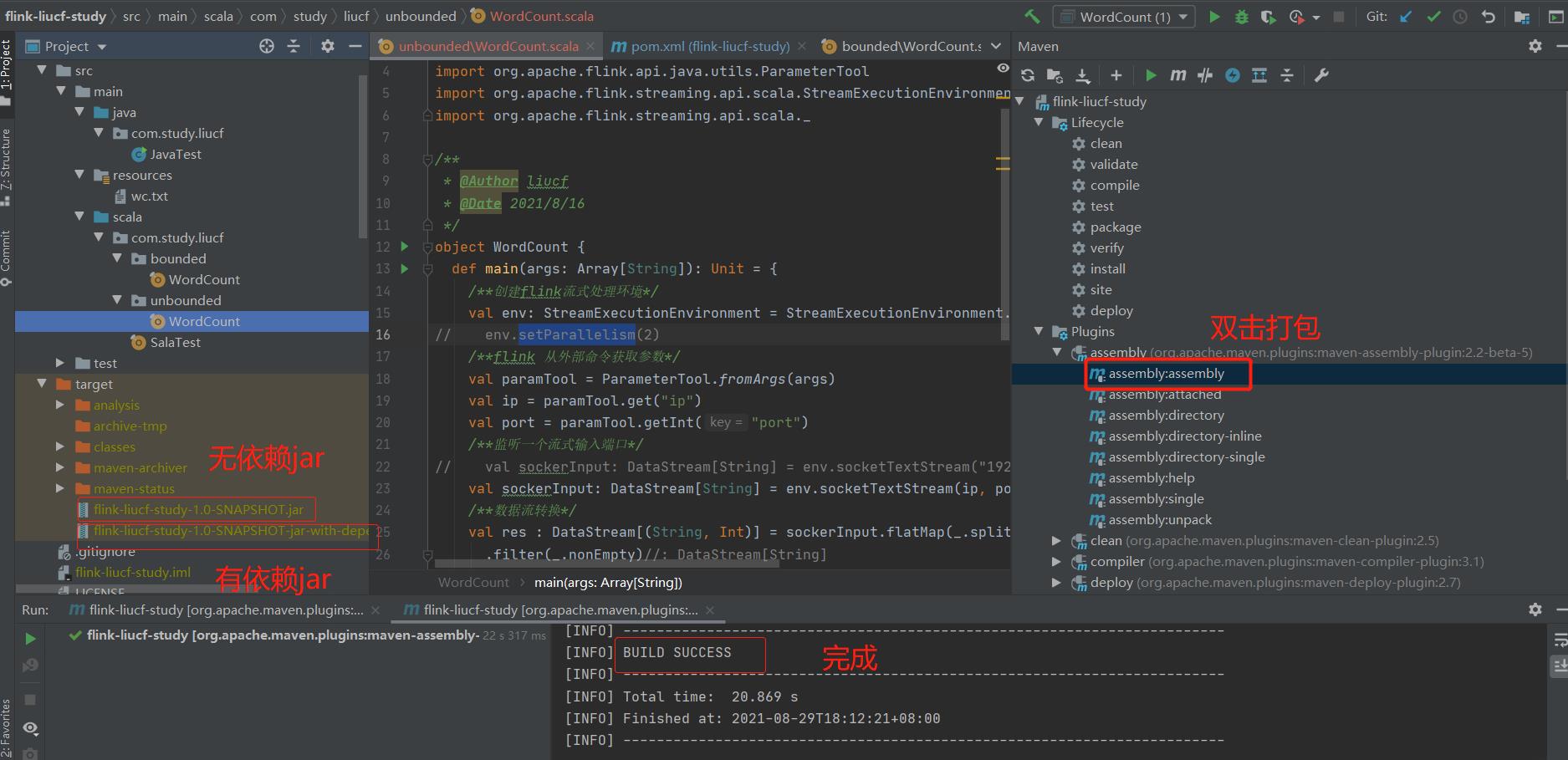
3 上传打包好的jar到客户端机器

4 flink on yarn
4.1 session cluster
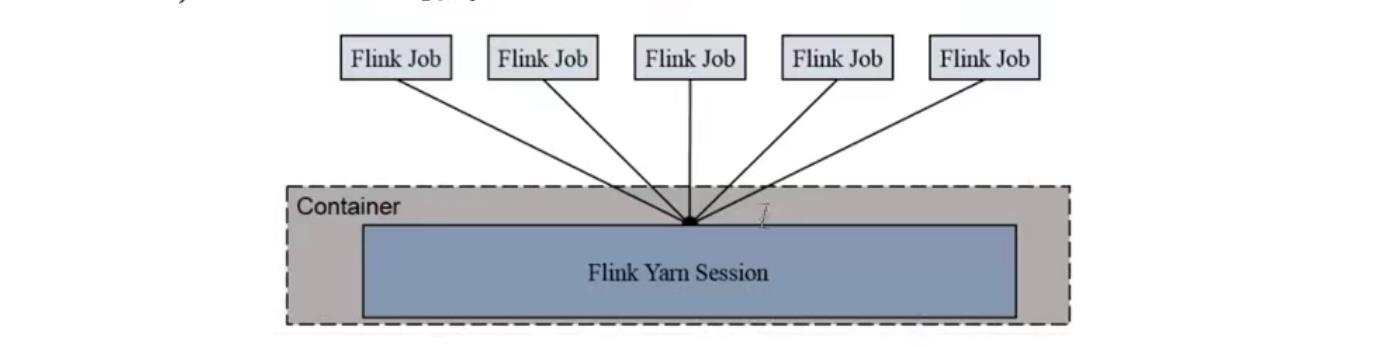
Session-cluster模式需要先启动集群,然后在提交作业,接着会向yarn申请一块空间,资源永远保持不变,如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交,所有作业共享Dispatcher和ResourceManager,共享资源,适合规模小执行时间段的作业。
在yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交,这个flink集群会常驻在yarn集群中,除非手工停止。
4.1.1 启动yarn-session申请资源
yarn-session.sh -nm wordCount -n 2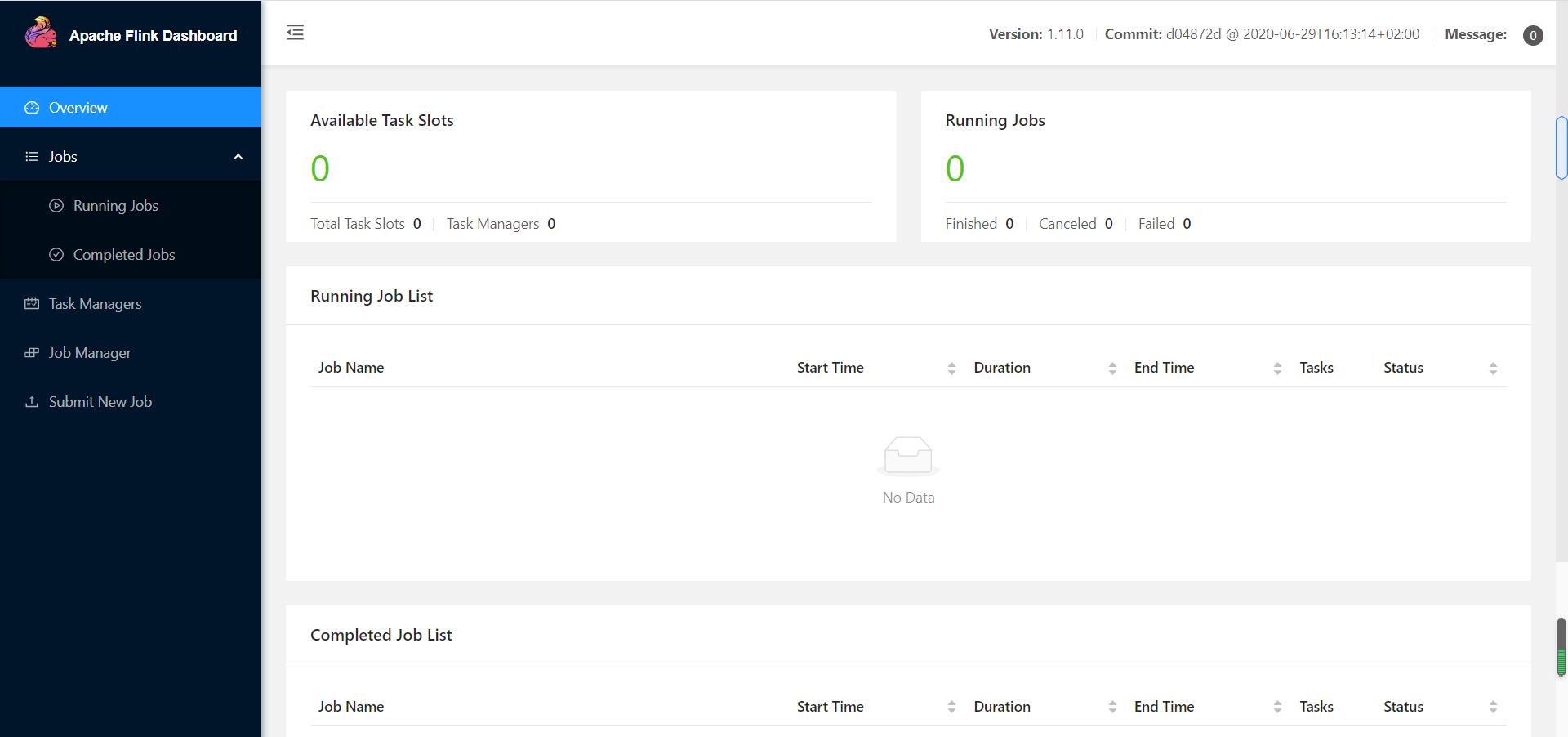
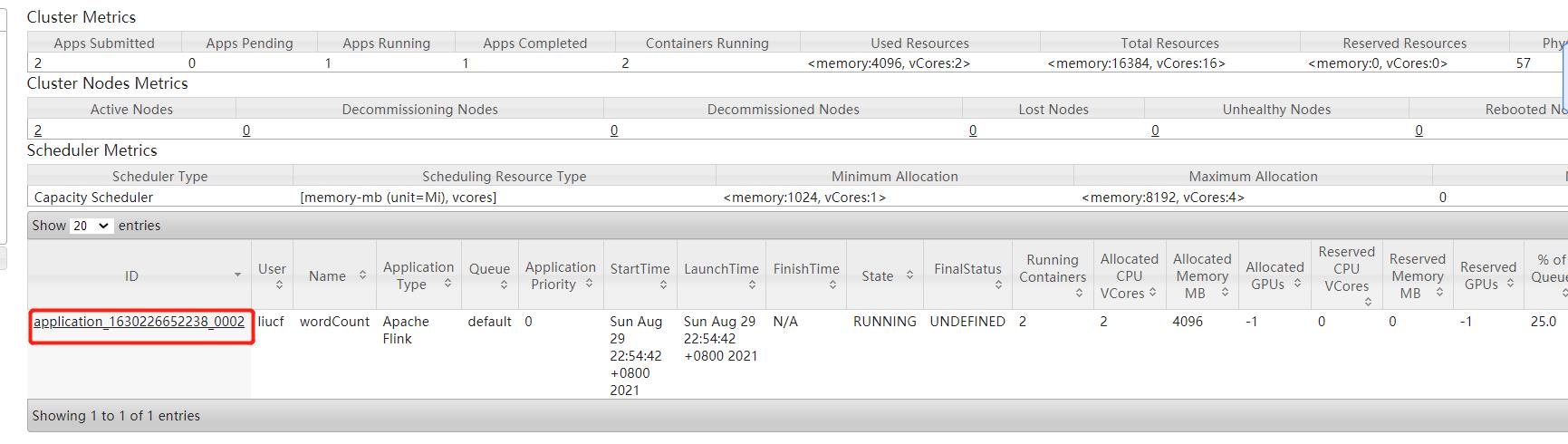
4.1.2 提交自己写的Wordcount 到 yarn
flink run -yid application_1630226652238_0002 -c com.study.liucf.unbounded.WordCount /home/liucf/liucffile/jarsflink-liucf-study-1.0-SNAPSHOT-jar-with-dependencies.jar --ip 192.168.109.151 --port 9999 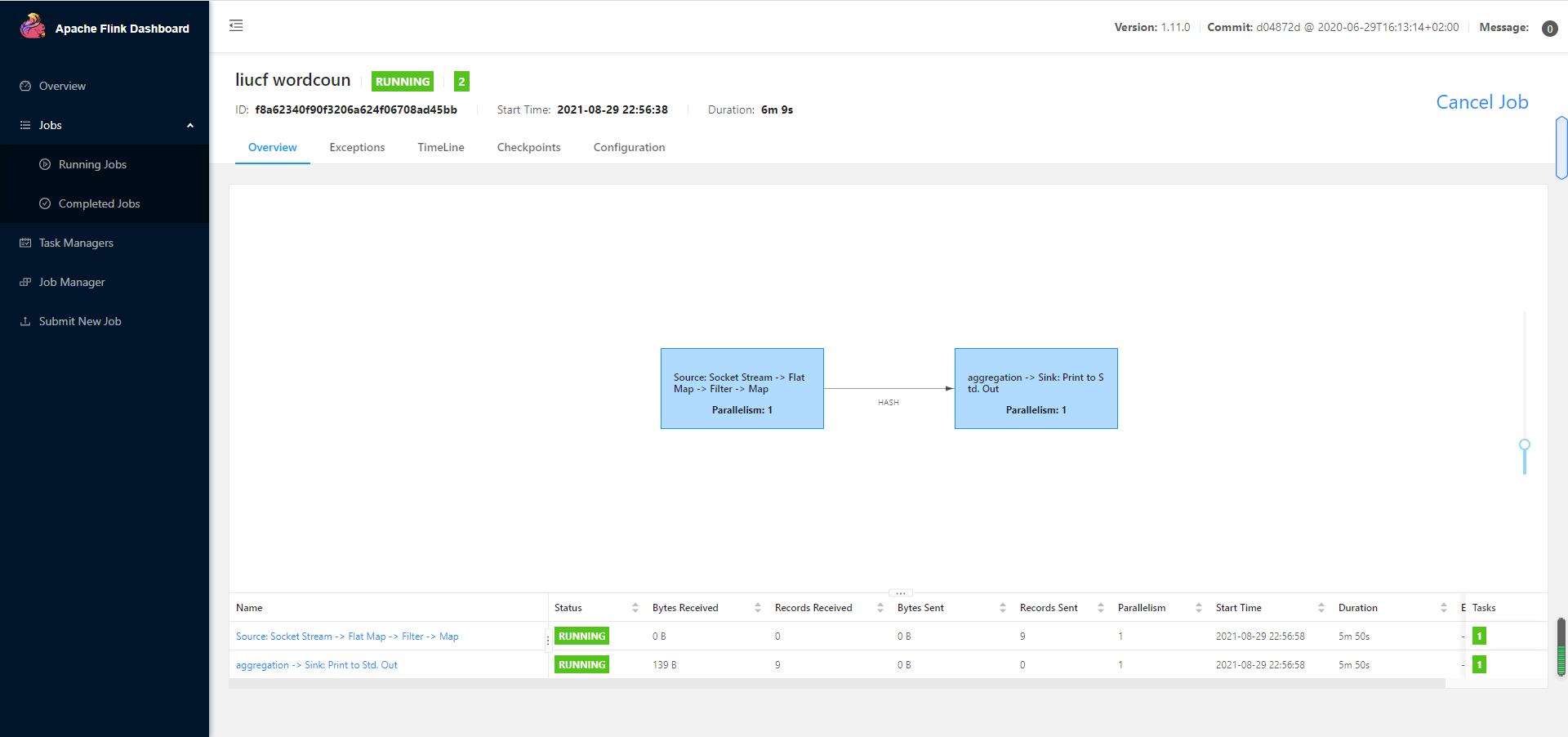
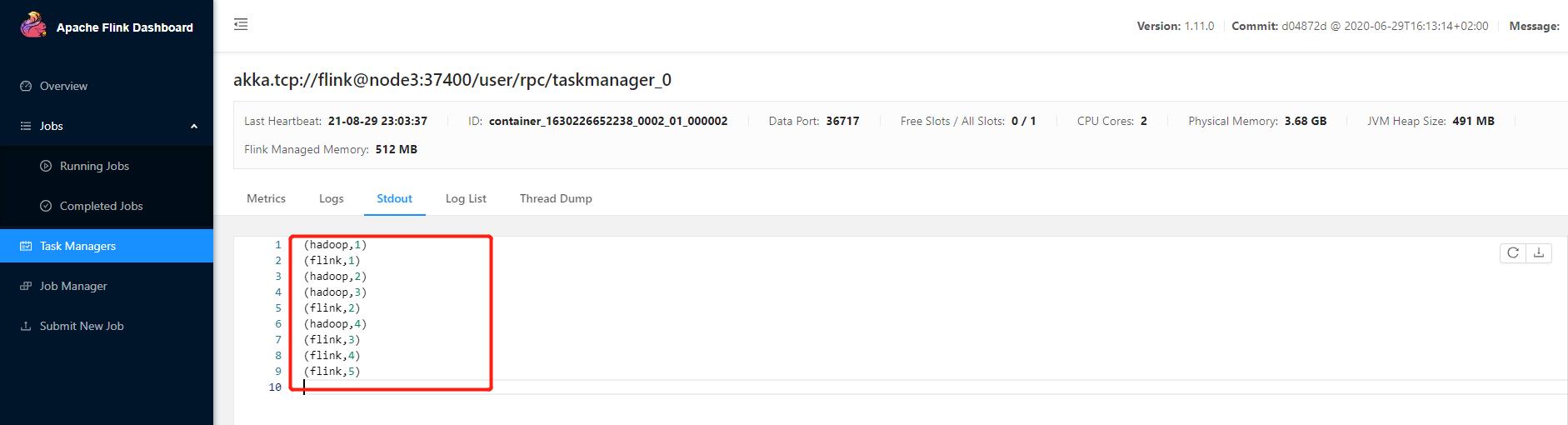
4.1.3 取消任务
yarn application -kill application_1630226652238_00024.2 Per-Job-Cluster 模式
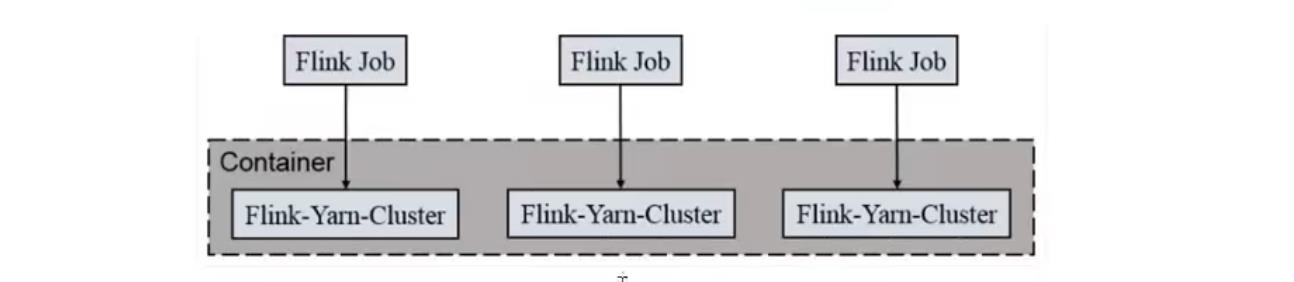
一个Job会应对一个集群,每提交一个作业会根据自身的情况都会单独向yarn申请资源,知道作业执行完成,一个作业的失败余否并不影响像一个作业的正常提交和运行,独享Dispatcher和ResourceManger,按需接受资源申请,适合规模大长时间运行的作业。
每次提交都会创建一个新的flink集群,任务之间相互独立,互不影响,方便管理,任务执行完成之后创建的集群也会消失。
4.2.1 提交自己写的Wordcount 到 yarn
flink run -m yarn-cluster -c com.study.liucf.unbounded.WordCount /home/liucf/liucffile/jars/flink-liucf-study-1.0-SNAPSHOT.jar --port 9999 --ip 192.168.109.151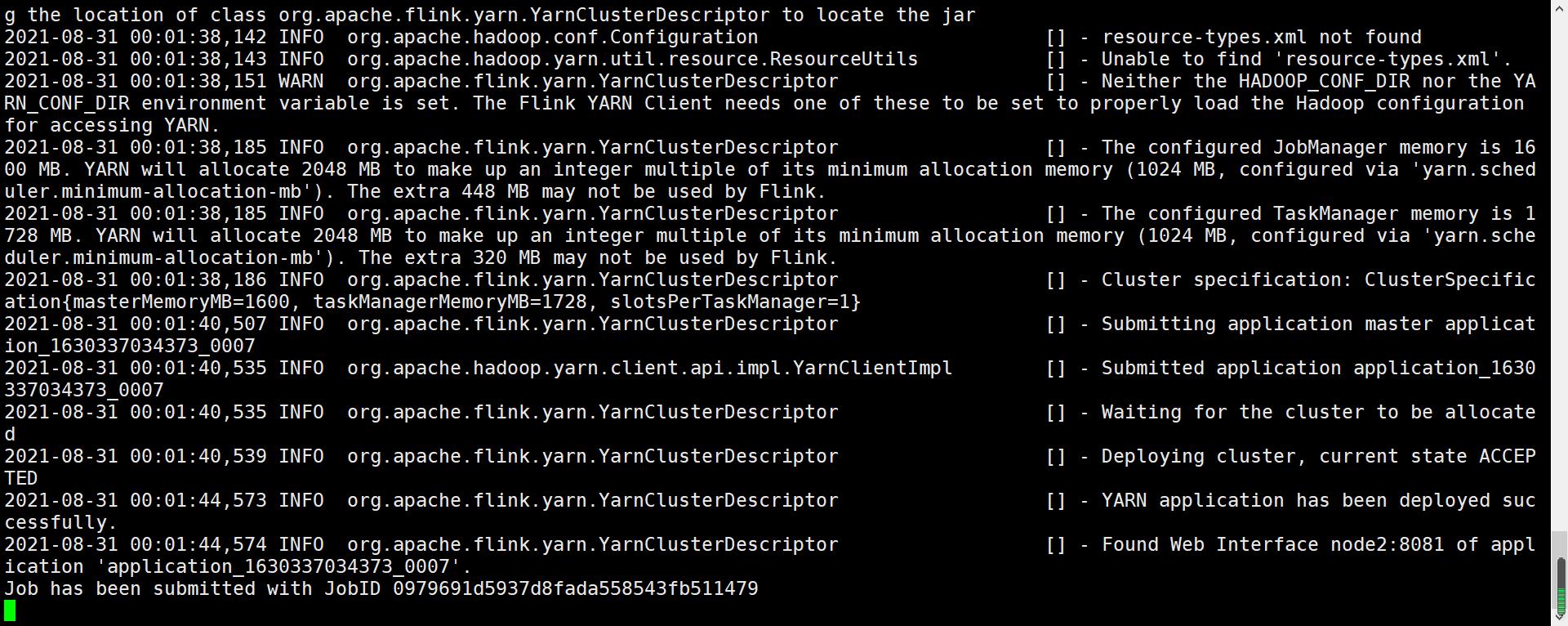
ok 成功了
运行flink自己带的Wordcount例子
flink run -m yarn-cluster /home/liucf/soft/flink-1.11.0/examples/streaming/SocketWindowWordCount.jar --port 9999 --hostname 192.168.109.151以上是关于05-flink-1.10.1-flink on yarn 流处理WordCount的主要内容,如果未能解决你的问题,请参考以下文章
[_], ... .?- length(X,N), path( state(on(c,on(b,on(a,void))), void, void), state(void, void, on(c,on