漫游语音识别技术——带你走进语音识别技术的世界
Posted 声网Agora
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了漫游语音识别技术——带你走进语音识别技术的世界相关的知识,希望对你有一定的参考价值。

前有古人,后有小王,大家好,我是你们爱思考的小王学长,今天我来带大家漫游一下当下发展火热的语音识别技术,通俗易懂、干货满满、一定要学到最后呦!
一看到语音识别,不知道大家有没有想到智能语音交互助手,苹果的“Siri”、华为的“小 E”、OPPO 的“小欧”、小米的“小爱同学”,总有一款你接触过,还有目前发展火热的智能音箱“小度小度”、天猫精灵、微信的“语音转文字功能”、“智能家电”、车联网人机交互系统,这些都是依靠语音识别技术来实现的。

平时我们用的电脑大都是微软的 windows 系列,其中的语音助手小娜更是被大家所熟知。那么究竟什么是语音识别技术呢?
一、什么是语音识别技术?
语音识别是将人说出的话转换为文本的技术,也被称为自动语音识别(Automatic Speech Recognition, ASR),简单来说就是与机器进行交流,让机器明白你说的话是什么意思。用更为广义的概念就是把人类发出语音到计算机理解人类所说内容为止的所有技术手段统称为语音识别。
用专业术语来说,就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。
在这里可能会有人问语音识别和自然语言处理(NLP)有什么区别呢,语音识别是自然语言处理的一项比较基础的分支范畴。很多情况下,你得先让机器知道你在说什么,才能进一步让机器去理解和做出特定的反应。其他分支范畴有机器翻译、搜索、摘要、问答等等。用一句话说就是语音识别技术是自然语言处理的一部分、一个分支。
好了,我们接着漫游语音识别技术,我们知道了语音识别的简单概念,接下来简单了解下语音识别的历史。
二、语音识别的历史
语音识别自计算机诞生(20 世纪 50 年代)以来,就一直是一个人类梦寐以求的技术。在以前的科幻电影中,人类就是用语音向计算机传达指令的。在 1968 年上映的美国电影《2001 太空漫游》中,宇宙飞船上搭载的计算机 HAL9000 就是通过语音与乘务员交流的。而从 1966 年播放至今的美国电视剧《星际迷航》中,主人公只要用语音询问计算机就可以得到准备探索的星球的数据。自计算机被发明之后,人类就坚信通过语音来驱动计算机的时代终会到来。
语音识别的研究正式开始于 20 世纪 60 年代,这时期人们曾尝试提取语音的频谱图 0 与音素 2 之间的关联规则。1970 年在大阪举办的世界博览会上就展出过基于声谱图工作的打字机原型。
进入 20 世纪 70 年代,人们研究出了动态规划( Dyamic Pogramming,DP)匹配方法。该方法能够将输人语音与样本语音的各自特征,按时间轴进行伸缩、匹配。基于这个技术,人们成功地将包含少量单词的短句的识别速度提高了一大截儿。
20 世纪 90 年代以后,基于统计方法的语音识别成为主流,市面上出现了面向普通用户的计算机听写软件,可以将输人的语音转换成文本输出。
三、语音识别的原理
从 20 世纪 80 年代开始,现在语音识别采用模式识别的基本框架,分为数据准备、信号处理、特征提取、模型训练、测试应用这 5 个步骤,为了方便大家理解,特意画了流程图,如图所示:
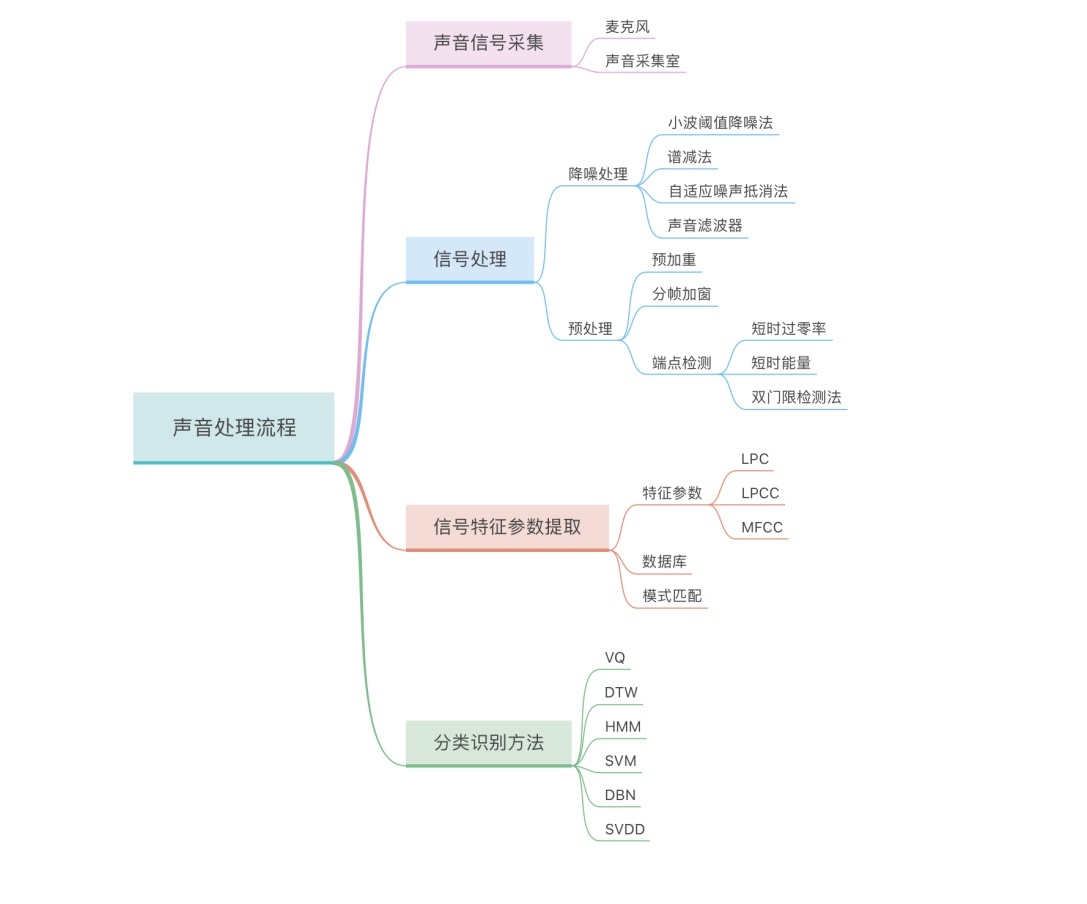
此图是为了方便大家理解语音识别的大致识别处理流程:
第一步 声音信号采集
首先,我们需要进行语音信号采集,也就是俗话说的录音,由我们手机里或者电脑等电子设备里所带的麦克风、语音采集模块把声音存储下来。
第二步 声音信号处理
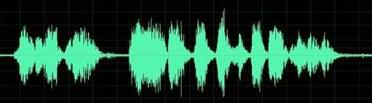
大家应该知道声音实际上是一种波。常见的 mp3、wmv 等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如 Windows PCM 文件,也就是俗称的 wav 文件。wav 文件里存储的除了一个文件头以外,就是声音波形的一个个点了。下图是波形的一个示例:
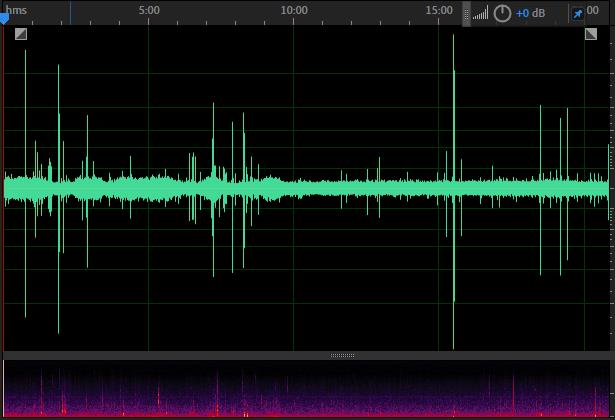
信号处理分为降噪处理和预处理两部分,我们采集到的声音数据里包含大部分噪声和无用的声音频段,先利用谱减法等降噪处理方法去噪,留得有用的声音信号,简单去噪对比图如下所示:
然后利用预加重等预处理手段使得想识别出的语音信号特征变得更加明显。在预处理部分还有分帧加窗和端点检测,目的是移除信号当中的直流偏置分量和一些低频噪声大家先明白是为了方便下一步更准确的提取特征参数就好,下一篇我会专门给大家讲解相关专业术语的含义。
第三步 特征提取
特征提取就是使用计算机提取声音信号中属于特征性的信息的方法及过程。举个例子,我说:“我喜欢你”,在语音识别过程中,会把文字变成编码的形式,并以音节、音素等分开,把 wo 这个字识别出来,在音频波纹中提取 w 和 o 就是相当于特征提取。
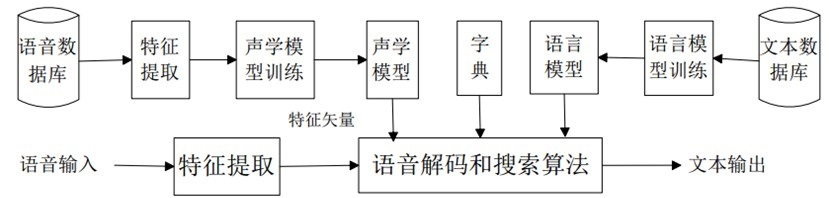
第四步 分类识别
分类识别就是利用语音识别系统根据对输入语音的限制加以分类。
从说话者与识别系统的相关性考虑可以将识别系统分为 3 类:
(1) 特定人语音识别系统:仅考虑对于专人的话音进行识别;
(2) 非特定人语音系统:识别的语音与人无关,通常要用大量不同人的语音数据库对识别系统进行学习;
(3) 多人的识别系统:通常能识别一组人的语音,或者成为特定组语音识别系统,该系统仅要求对要识别的那组人的语音进行训练。
语音识别技术主要分为三大类
第一类是模型匹配法,包括矢量量化(VQ) 、动态时间规整(DTW)等;
第二类是概率统计方法,包括高斯混合模型(GMM) 、隐马尔科夫模型(HMM)等;
第三类是辨别器分类方法,如支持向量机(SVM) 、人工神经网络(ANN)和深度神经网络(DNN)等以及多种组合方法。
在分类识别方法这块,有传统算法模型 HMM 等,也有当今发展火热的深度学习、机器学习算法 SVM 等等,大家对算法感兴趣的可以自己去搜索一下,也可以跟我留言,我会以通俗易懂的方式带大家学习相关知识的哦!

最后,总结一下,语音识别其实就是一个先编码后解码的过程,信号处理和特征提取就是编码的过程。换句话说,就是一种基于语音特征参数的模式识别,即通过学习,系统能够把输入的语音按一定模式进行分类,进而依据判定准则找出最佳匹配结果。
四、语音识别主要在线开发平台
1、科大讯飞语音
2、百度语音
3、Microsoft Speech API
4、Google Speech API
5、IBM viaVoice
6、Nuance NVP
7、声网 agora API
五、语音识别的学习干货
书籍
《图解语音识别》,荒木雅弘 (作者) 陈舒扬 , 杨文刚 (译者)
这本书对于小白特别友好,很基础,以图解的形式让大家轻松入门。
《解析深度学习:语音识别实践》,俞栋、邓力著。
这本书算是中文写的比较好的教程了,内容非常新,而且深度学习的篇幅很大,喜欢算法的同学推荐这本。
《Spoken Language Processing-A Guide to Theory, Algorithm and System Development》,黄学东等著。
这本书基本上是 ASR 传统方法的大全了,无论理论还是工程实践都有相当大的篇幅。
教程
学有余力的同学可以学习以下教程:
http://tts.speech.cs.cmu.edu/courses/11492/schedule.html
Speech Processing。CMU 的这个教程主要包含 ASR(Automatic Speech Recognition)、TTS(Text To Speech)和 SDS(Spoken Dialog Systems)等三方面的内容。
苏格兰计算机科学家,语音处理专家,他的主页上有好多 Speech、NLP 方面的教程。
http://www.inf.ed.ac.uk/teaching/courses/asr/index.html
Automatic Speech Recognition。这个课程至少从 2012 年就开始了,每年都有更新。
以上是关于漫游语音识别技术——带你走进语音识别技术的世界的主要内容,如果未能解决你的问题,请参考以下文章