Elasticsearch:如何在提高跨索引搜索相关性的同时返回更多相关的文档
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:如何在提高跨索引搜索相关性的同时返回更多相关的文档相关的知识,希望对你有一定的参考价值。
在 Elasticsearch 的搜索中,经常遇到的情况是,我们创建一个 data view 或者 index pattern 跨多个索引,这样我们可以对它们进行统一的搜索。我们有遇到这样的情况:完全匹配的文档的分数反而低于部分匹配的文档,这是为什么呢?
例子展示
例子一
我们先看一下如下的一个例子:
POST /_bulk
"index": "_index": "my_index"
"name": "Vincent van Gogh"
"index": "_index": "my_index"
"name": "Rembrandt van Rijn"
"index": "_index": "my_index"
"name": "Frans Hals"
"index": "_index": "my_index"
"name": "Johann Adam Ackermann"
"index": "_index": "my_index"
"name": "Piet Mondriaan"
"index": "_index": "my_index"
"name": "Claude Monet"
"index": "_index": "my_index"
"name": "Jackson Pollock"
"index": "_index": "my_index"
"name": "Andy Warhol"
"index": "_index": "my_index"
"name": "Frida Kahlo"
"index": "_index": "my_index"
"name": "Johannes Vermeer"
"index": "_index": "my_index"
"name": "Leonardo da Vinci"
"index": "_index": "my_index"
"name": "Pieter Breugel"
"index": "_index": "my_index"
"name": "Johann Sebastian Bach"
"index": "_index": "my_index"
"name": "Johann Christoph Bach"
"index": "_index": "my_index"
"name": "Johann Ambrosius Bach"
"index": "_index": "my_index"
"name": "Clara Schumann"在上面索引 my_index,我把所有的文档放到这个索引里。我们进行如下的搜索:
GET my_index/_search?filter_path=**.hits
"query":
"match":
"name": "johann sebastian bach"
这里搜索的 “johann sebastian bach” 是其中一个文档里的 name。上面搜索返回的结果是:
"hits":
"hits": [
"_index": "my_index",
"_id": "gRoPQ4YB2XodIZsbxfzo",
"_score": 4.8769255,
"_source":
"name": "Johann Sebastian Bach"
,
"_index": "my_index",
"_id": "ghoPQ4YB2XodIZsbxfzo",
"_score": 2.6585994,
"_source":
"name": "Johann Christoph Bach"
,
"_index": "my_index",
"_id": "gxoPQ4YB2XodIZsbxfzo",
"_score": 2.6585994,
"_source":
"name": "Johann Ambrosius Bach"
,
"_index": "my_index",
"_id": "eBoPQ4YB2XodIZsbxfzo",
"_score": 1.214482,
"_source":
"name": "Johann Adam Ackermann"
]
很显然这个是我们希望的结果。文档含有 “johann sebastian bach” 排在前一名。这个完全是符合我们的搜索的习惯,因为这个搜索结果最匹配我们的搜索内容。
例子二
我们现在使用另外一种方法来展示。这次,我们把上面的文档不是写入到同一个索引中,而是把它们分别写入到两个索引中:
POST /_bulk
"index": "_index": "painters"
"name": "Vincent van Gogh"
"index": "_index": "painters"
"name": "Rembrandt van Rijn"
"index": "_index": "painters"
"name": "Frans Hals"
"index": "_index": "painters"
"name": "Johann Adam Ackermann"
"index": "_index": "painters"
"name": "Piet Mondriaan"
"index": "_index": "painters"
"name": "Claude Monet"
"index": "_index": "painters"
"name": "Jackson Pollock"
"index": "_index": "painters"
"name": "Andy Warhol"
"index": "_index": "painters"
"name": "Frida Kahlo"
"index": "_index": "painters"
"name": "Johannes Vermeer"
"index": "_index": "painters"
"name": "Leonardo da Vinci"
"index": "_index": "painters"
"name": "Pieter Breugel"
"index": "_index": "composers"
"name": "Johann Sebastian Bach"
"index": "_index": "composers"
"name": "Johann Christoph Bach"
"index": "_index": "composers"
"name": "Johann Ambrosius Bach"
"index": "_index": "composers"
"name": "Clara Schumann"如上所示,我们把前一部分的文档写入到 painters 里,二后面的一些文档写入到 composers 这个索引中。
现在,为了说明问题,让我们搜索名为“Johann Sebastian Bach” 的人:
GET /painters,composers/_search?filter_path=**.hits
"query":
"match":
"name": "johann sebastian bach"
上面搜索的结果为:
"hits":
"hits": [
"_index": "painters",
"_id": "uBoWQ4YB2XodIZsbJfyz",
"_score": 1.9334917,
"_source":
"name": "Johann Adam Ackermann"
,
"_index": "composers",
"_id": "wRoWQ4YB2XodIZsbJfyz",
"_score": 1.8485742,
"_source":
"name": "Johann Sebastian Bach"
,
"_index": "composers",
"_id": "whoWQ4YB2XodIZsbJfyz",
"_score": 0.6877716,
"_source":
"name": "Johann Christoph Bach"
,
"_index": "composers",
"_id": "wxoWQ4YB2XodIZsbJfyz",
"_score": 0.6877716,
"_source":
"name": "Johann Ambrosius Bach"
]
从上面的搜索的结果中我们可以看出来,排名第一的是 "Johann Adam Ackermann",而第二名才是我们真正想要的结果 "Johann Sebastian Bach"。这个完全颠覆了我们对搜索的认知。哇,这是怎么回事? 与我们的预期相反,Bach 并不是最重要的搜索结果。 虽然我们的作曲家索引中有 “Johann Sebastian Bach”(得分 ~1.8485742)的字面匹配,但画家 “Johann Adam Ackermann” 只匹配我们搜索查询的一小部分,得分更高(~1.9334917)!
请解释一下
一如既往,我们可以向 Elasticsearch 寻求解释:
GET /painters,composers/_search
"explain": true,
"query":
"match":
"name": "johann sebastian bach"
这给了我们一个关于正在发生的事情的提示:与我们人类不同,Elasticsearch 不知道 “Johann Sebastian Bach” 这个名字是一个连贯的单元,因此它单独搜索每个术语。
- 首先,分词器将查询分为三个词:johann OR sebastian OR bach。
- 然后,Elasticsearch 分别搜索每个术语。
- 最后,它通过合并每个术语的分数来计算总分。
所以 Elasticsearch 默认运行 OR 查询。 也就是说,至少有一个搜索词必须匹配,但不一定全部匹配。 这解释了为什么 Johann Adam Ackermann 包含在结果中,即使只有一个词('Johann')匹配我们的查询。
逆向文件频率在起作用
如果你对 inverse document frequency 还不是很清楚的话,请阅读我之前的文章 “Elasticsearch:分布式计分”。但这还没有回答为什么 Acermann 的排名高于 Bach 的问题。 是什么让 Ackermann 更具相关性? 这与 Elasticsearch 计算相关性的方式有关:它依赖于 TF/IDF 算法。 IDF(逆向文档频率)部分让我们很头疼:对于一个给定的搜索词,它出现在越多的文档中,它被认为越不相关。
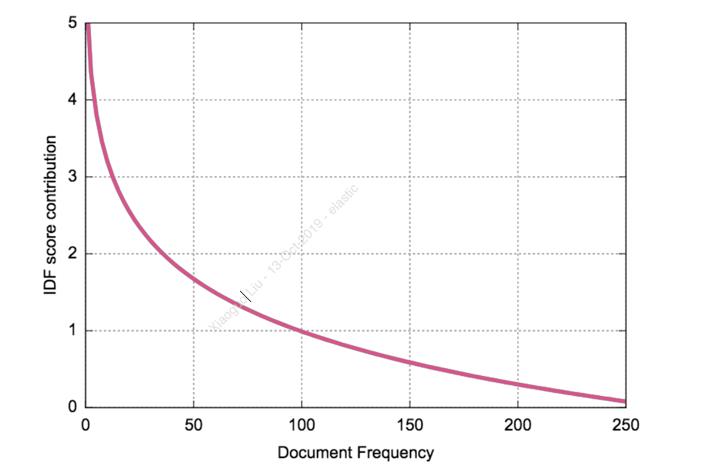
因此,出现在许多文档中的术语具有较低的权重。 一般来说,这是有道理的:如果你搜索 “the well-tempered keyboard”,你不会对所有包含常见术语(如 “the”)的文档感兴趣,而只对少数提到键盘的文档感兴趣,最好是对 well-tempered。
如果你查看上面的数据,你会发现这两个索引加起来包含四位 Johann 和三位 Bach。 所以这仍然使 Bach 成为更独特、更相关的术语,不是吗? 不幸的是不是,因为:
每个字段都有自己的倒排索引,因此,对于 TF/IDF 而言,字段的值就是文档的值。
也就是说,我们需要在字段层面进行区分,而不是(仅)在索引层面。 (即使两个索引中的字段都称为 name,但它们属于两个不同的索引这一事实使它们成为两个字段。)在这种情况下,我们在 painters.name 字段中只有一个 Johann (Ackermann),在 composers.name 中只有三个,这确实将 painers 的相关性提高到了 composers(Johann Sebastian Bach)之上。
解决方案 1:仅匹配完整结果
正如我们在上面看到的,Elasticsearch 默认使用 OR 组合术语。 那么,一个明显的解决方案是告诉 Elasticsearch 匹配所有搜索词。 你可以通过将运算符更改为 AND 来实现:
GET /painters,composers/_search
"query":
"match":
"name":
"query": "johann sebastian bach",
"operator": "and"
就是这样,我们只得到一个结果,它是 johann sebastian bach。 完毕?
好吧,如果用户将 Bach 与其他著名作曲家混淆,而是搜索 johann van bach 怎么办? 该查询现在返回零结果(因为在 Bach 的名字中找不到 van),这对我们的用户来说有点太苛刻了。
解决方案 2:支持完整结果
我们可以通过用 minimum_should_match 替换自定义 operator 来解决这个问题:
GET /painters,composers/_search
"query":
"match":
"name":
"query": "johann sebastian bach",
"minimum_should_match": "2<75%"
2<75% 表示:
- 如果你只提供两个搜索词(例如,johann bach),则它们必须全部匹配 (johann AND bach);
- 但如果你提供两个以上的术语(例如,johann van bach),则只有 75%(向下舍入)必须匹配,因此这归结为(johann AND van)或(van AND bach)或(johann AND bach)。
现在我们的搜索结果只包含三位 Bach,Johann Sebastian 安排名最高:
"took": 3,
"timed_out": false,
"_shards":
"total": 2,
"successful": 2,
"skipped": 0,
"failed": 0
,
"hits":
"total":
"value": 3,
"relation": "eq"
,
"max_score": 1.8485742,
"hits": [
"_index": "composers",
"_id": "wRoWQ4YB2XodIZsbJfyz",
"_score": 1.8485742,
"_source":
"name": "Johann Sebastian Bach"
,
"_index": "composers",
"_id": "whoWQ4YB2XodIZsbJfyz",
"_score": 0.6877716,
"_source":
"name": "Johann Christoph Bach"
,
"_index": "composers",
"_id": "wxoWQ4YB2XodIZsbJfyz",
"_score": 0.6877716,
"_source":
"name": "Johann Ambrosius Bach"
]
但是,这会从搜索结果中删除画家 Johann Ackermann,我们可能希望将其作为 “johann” 的部分匹配项返回。
解决方案 3:以正确的方式支持完整的结果
因此,将运算符更改为 AND(解决方案 1)和提供 minimum_should_match(解决方案 2)都过于严格。 一个更好、更灵活的解决方案是支持完整结果,但仍然包括部分匹配的结果。
解决这个问题的方法是利用 should 子句在复合 bool 查询中的工作方式。 关键字应该类似于常规的 OR,但在一个重要方面有所不同:匹配的子句越多,文档的相关性就越高。
这使得将我们喜欢的结果指定为一组 should 子句变得非常自然。 我们首先将原始查询包装在 bool 查询中:
GET /painters,composers/_search
"query":
"bool":
"should": [
"match":
"name": "johann sebastian bach"
]
虽然这还没有改变我们的搜索结果,但它开辟了添加更多 should 子句的途径。 因此,在此基础上,如果文档包含与查询顺序相同的术语组合,我们可以认为该文档更相关。 用 Elasticsearch 的说法,这是一个短语匹配。 只需为此添加一个 should 子句:
GET /painters,composers/_search
"query":
"bool":
"should": [
"match":
"name": "johann sebastian bach"
,
"match_phrase":
"name": "johann sebastian bach"
]
最后,我们可以将 minimum_should_match 查询添加回我们的复合查询:
GET /painters,composers/_search?filter_path=**.hits
"query":
"bool":
"should": [
"match":
"name": "johann sebastian bach"
,
"match_phrase":
"name": "johann sebastian bach"
,
"match":
"name":
"query": "johann sebastian bach",
"minimum_should_match": "2<75%"
]
这给了我们正在寻找的东西:
"hits":
"hits": [
"_index": "composers",
"_id": "wRoWQ4YB2XodIZsbJfyz",
"_score": 5.5457225,
"_source":
"name": "Johann Sebastian Bach"
,
"_index": "painters",
"_id": "uBoWQ4YB2XodIZsbJfyz",
"_score": 1.9334917,
"_source":
"name": "Johann Adam Ackermann"
,
"_index": "composers",
"_id": "whoWQ4YB2XodIZsbJfyz",
"_score": 1.3755432,
"_source":
"name": "Johann Christoph Bach"
,
"_index": "composers",
"_id": "wxoWQ4YB2XodIZsbJfyz",
"_score": 1.3755432,
"_source":
"name": "Johann Ambrosius Bach"
]
结论
所有搜索都是 precision 和 recall 之间的权衡。 为了在两者之间取得良好的平衡,你可以使用 should 子句以增加特异性来描述您想要的结果。 这首先为你提供最佳结果,同时保持较长的搜索结果,但相关结果较少(但仍然)。
以上是关于Elasticsearch:如何在提高跨索引搜索相关性的同时返回更多相关的文档的主要内容,如果未能解决你的问题,请参考以下文章