你这 Saga 事务保“隔离性”吗?
Posted _江南一点雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你这 Saga 事务保“隔离性”吗?相关的知识,希望对你有一定的参考价值。
文章目录
Seata 一共提供了四种分布式事务的处理模式:
- AT
- TCC
- XA
- Saga
前面三种松哥都和大家介绍过了,今天我们来看看 Saga 这种模式。如果大家对于前三种还不太熟悉,可以先看看之前的文章,传送门:
好啦,开始今天的正文吧。
1. 什么是 Saga 事务模式
Saga 模式是 Seata 提供的长事务解决方案,在 Saga 模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。
注意最后一句话很关键,说明 Saga 模式的回滚其实和 AT、TCC 的回滚一样,都是反向补偿操作(区别于 XA 模式)。
官方给了下面一张流程图,我们一起来看下:
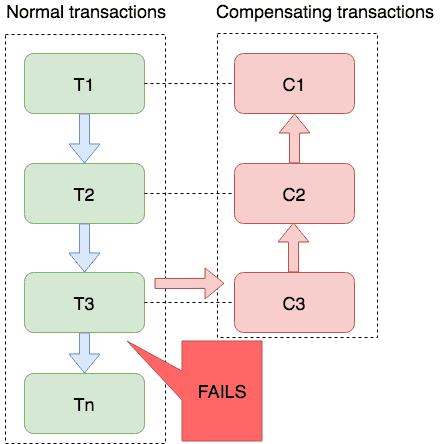
可以看到,T1、T2、T3 一直到 Tn 分别代表分布式事务中的分支事务,这条线都是事务的正常状态,如果在执行的过程中,有某一个抛出异常,则执行 C3、C2 一直到 C1 进行事务的回滚,这里的回滚实际上就是反向补偿操作。
一般来说,Saga 模式适用于业务流程长、业务流程多的分布式事务,就像上面的流程图这样,不过当业务流程比较长的时候,如何去定义每一个事务的状态也就成了问题。
这里就涉及到 Saga 分布式事务的状态机。
2. Saga 的状态图
状态图这个东西,如果小伙伴们用过 Activiti 流程引擎,那么基本上就知道什么是状态图,Saga 的状态图跟那个也差不多。
Saga 中的状态图是这样:
- 首先我们需要定义一个状态流程图,像下面这样:
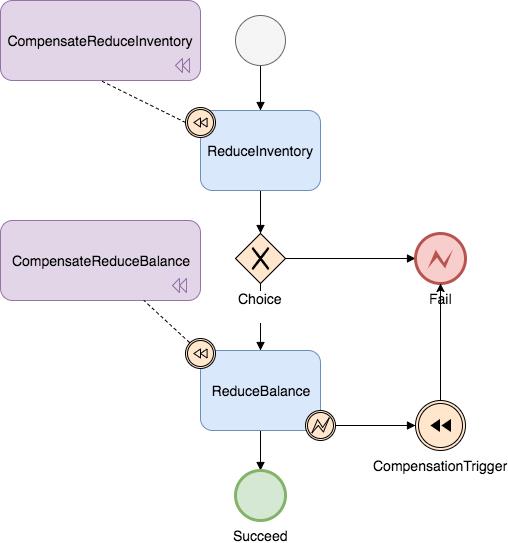
这个流程图官方提供了绘制工具,地址如下:
https://seata.io/saga_designer/index.html
官方还为此提供了一个视频教程,松哥看了下,录视频的人估计也是第一次录视频,没啥经验,视频各种问题没法看,所以我就不放链接了,小伙伴们在工作中如果需要绘制状态图,可以参考这个文档:
https://help.aliyun.com/document_detail/172550.html
流程图上记录了每一个分支事务的状态以及相关的补偿操作,流程图画好之后,会自动生成 JSON 状态语言定义文件,把这个文件将来拷贝到项目中。
- 状态图中的每一个节点可以调用一个服务,每一个节点都可以配置它的补偿节点,当节点出现异常时状态引擎反向执行已成功节点对应的补偿节点将事务回滚(是否回滚可由用户自行决定)。
- 状态图可以实现服务编排需求,支持单项选择、并发、子流程、参数转换、参数映射、服务执行状态判断、异常捕获等功能。
3. Saga 模式案例
我们来看一个 Saga 模式的案例,看完案例大家就懂什么是 Saga 模式了。
3.1 准备工作
我们还是使用官方的案例。不过还是松哥之前说的,官方的案例容易导入失败,并且里边有的地方有问题,所以小伙伴们可以直接在公众号后台回复 seata-demo 下载本文案例。
Saga 的例子我们用这个:

如果小伙伴们直接使用官方的案例,需要做如下修改:
- 修改 Dubbo 的版本为 2.7.3,原本默认的 3.0.1 这个版本运行时候有问题。
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring</artifactId>
</exclusion>
</exclusions>
<version>2.7.3</version>
</dependency>
- 官方默认提供的数据库脚本少一个字段,不知道咋回事,这么明显的 BUG。这个需要我们在
src/main/resources/sql/h2_init.sql文件中,为 seata_state_inst 表添加一个gmt_updated timestamp(3) not null字段。
准备工作就算完成啦。
3.2 测试运行
接下来我们来测试运行。
首先我们先来执行 src/main/java/io/seata/samples/saga/starter/DubboSagaProviderStarter.java 中的 main 方法,启动服务端。
然后打开 src/main/java/io/seata/samples/saga/starter/DubboSagaTransactionStarter.java 类,这个类需要修改一下才能运行。
public static void main(String[] args) {
AbstractApplicationContext applicationContext = new ClassPathXmlApplicationContext(new String[] {"spring/seata-saga.xml", "spring/seata-dubbo-reference.xml"});
StateMachineEngine stateMachineEngine = (StateMachineEngine) applicationContext.getBean("stateMachineEngine");
transactionCommittedDemo(stateMachineEngine);
transactionCompensatedDemo(stateMachineEngine);
new ApplicationKeeper(applicationContext).keep();
}
可以看到,这个 main 方法中有两个测试方法:
- transactionCommittedDemo
- transactionCompensatedDemo
第一个方法是二阶段提交的测试,第二个方法是二阶段补偿的测试,我们注释掉其中一个,每次执行的时候只要执行其中一个就可以了。
另外,对于 transactionCommittedDemo 方法,它里边提供了两种状态的获取方式:同步和异步,我们需要注释掉其中一种然后进行测试,像下面这样:
private static void transactionCommittedDemo(StateMachineEngine stateMachineEngine) {
Map<String, Object> startParams = new HashMap<>(3);
String businessKey = String.valueOf(System.currentTimeMillis());
startParams.put("businessKey", businessKey);
startParams.put("count", 10);
startParams.put("amount", new BigDecimal("100"));
//sync test
//StateMachineInstance inst = stateMachineEngine.startWithBusinessKey("reduceInventoryAndBalance", null, businessKey, startParams);
//Assert.isTrue(ExecutionStatus.SU.equals(inst.getStatus()), "saga transaction execute failed. XID: " + inst.getId());
//System.out.println("saga transaction commit succeed. XID: " + inst.getId());
//async test
businessKey = String.valueOf(System.currentTimeMillis());
StateMachineInstance inst = stateMachineEngine.startWithBusinessKeyAsync("reduceInventoryAndBalance", null, businessKey, startParams, CALL_BACK);
waittingForFinish(inst);
Assert.isTrue(ExecutionStatus.SU.equals(inst.getStatus()), "saga transaction execute failed. XID: " + inst.getId());
System.out.println("saga transaction commit succeed. XID: " + inst.getId());
}
注释掉同步的代码块或者注释掉异步的代码块,注释掉之后,执行 main 方法进行测试。
如果测试 transactionCommittedDemo 方法,控制台打印日志如下:
saga transaction commit succeed. XID: 192.168.1.105:8091:2612256553007833092
如果测试 transactionCompensatedDemo 方法,控制台打印日志如下:
saga transaction compensate succeed. XID: 192.168.1.105:8091:2612256553007833094
能看到如上两个日志,说明案例运行没问题了。
接下来我们就来分析一下,这个案例到底讲了个啥!
3.3 案例分析
3.3.1 JSON 状态描述分析
这个案例并没有一个明确的业务,就单纯是一个案例。
首先定义了两个 Action:
- InventoryAction
- BalanceAction
这两个 Action 中各自定义了两个方法:
- reduce
- compensateReduce
从方法名就能看出,reduce 方法就是正常的执行逻辑,compensateReduce 方法则是代码补偿逻辑,即回滚的时候需要执行的代码。
具体到这两个方法的实现上,并没有啥,都是打印日志,所以这个项目我们只需要认真观察打印出来的日志,就能知道事务是提交了还是回滚了。
在 src/main/resources/statelang/reduce_inventory_and_balance.json 文件中定义了各个事务的状态,我们可以大概看一下,由于完整 JSON 文件比较长,我就分段贴出来。
{
"Name": "reduceInventoryAndBalance",
"Comment": "reduce inventory then reduce balance in a transaction",
"StartState": "ReduceInventory",
"Version": "0.0.1",
...
...
上面这段定义了状态机的名称为 reduceInventoryAndBalance,在一个项目中,我们可以同时存在多个这样的 JSON 文件,每一个都有一个 name 属性,这样在 Java 代码调用的时候就可以通过具体的名字去指定需要调用哪一个流程了。StartState 则定义了整个流程从 ReduceInventory 开始,ReduceInventory 是后面定义的节点。
"ReduceInventory": {
"Type": "ServiceTask",
"ServiceName": "inventoryAction",
"ServiceMethod": "reduce",
"CompensateState": "CompensateReduceInventory",
"Next": "ChoiceState",
"Input": [
"$.[businessKey]",
"$.[count]"
],
"Output": {
"reduceInventoryResult": "$.#root"
},
"Status": {
"#root == true": "SU",
"#root == false": "FA",
"$Exception{java.lang.Throwable}": "UN"
}
}
这是整个流程图中的第一步,我挑几个关键的点说下。
- ServiceName:这个是服务的名字,也就是由哪个对象处理这里的请求,inventoryAction 是我们通过 dubbo 获取到的对象。
- ServiceMethod:这个指定了要执行的方法,也就是正常执行的方法。
- CompensateState:这个是指定了负责补偿服务的节点,它的取值是这个 JSON 文件中定义的另外一个节点。
- Next:这是当前节点走完后,下一步要去的节点。
- Input/Output/Status:分别表示输入参数/输出参数以及各个状态的取值。
上面这个节点执行完,就会进入到下面这个节点中:
"ChoiceState":{
"Type": "Choice",
"Choices":[
{
"Expression":"[reduceInventoryResult] == true",
"Next":"ReduceBalance"
}
],
"Default":"Fail"
},
这个很好懂,就是定义了期待上面一个节点的返回值为 true,如果上个节点返回值不为 true,那就是执行失败,要准备补偿操作了;如果上个节点执行结果是为 true,那就进入下个节点 ReduceBalance。
后面节点的定义也都差不多,我就不一一列出来了,小伙伴们公号后台回复 seata-demo 下载文章案例后,可以自行查看。
这是状态图。
3.3.2 代码分析
接下来再简单看下代码。
官方提供了两个测试方法,一个用来测试二阶段提交,一个用来测试二阶段回滚。
先来看这个这个测试二阶段提交的方法:
private static void transactionCommittedDemo(StateMachineEngine stateMachineEngine) {
Map<String, Object> startParams = new HashMap<>(3);
String businessKey = String.valueOf(System.currentTimeMillis());
startParams.put("businessKey", businessKey);
startParams.put("count", 10);
startParams.put("amount", new BigDecimal("100"));
businessKey = String.valueOf(System.currentTimeMillis());
StateMachineInstance inst = stateMachineEngine.startWithBusinessKeyAsync("reduceInventoryAndBalance", null, businessKey, startParams, CALL_BACK);
waittingForFinish(inst);
Assert.isTrue(ExecutionStatus.SU.equals(inst.getStatus()), "saga transaction execute failed. XID: " + inst.getId());
System.out.println("saga transaction commit succeed. XID: " + inst.getId());
}
官方这个方法中有同步和异步的案例,我这里把同步的那几行代码删了,我们就来看异步的。
首先前面 startParams 就是项目的参数,在上面 JSON 分析中,每个方法(reduce、compensateReduce)都有参数,参数就是这。
接下来调用状态机的 startWithBusinessKeyAsync 方法开始各个流程的执行,这个方法的第一个参数就是流程的名字,也就是我们前面说的 JSON 中的 name,通过这个名字就可以确定是执行哪一个流程,startParams 也是在这里传进去。
waittingForFinish 是一个自定的阻塞方法,目的是使流程执行完,以便获取事务的执行结果,这就是基本的线程知识,我这里就不强调了,大家可以自行下载源码查看。
最后通过断言判断事务的执行状态(inst.getStatus())并打印相关日志。
接下来我们再来看二阶段回滚的方法:
private static void transactionCompensatedDemo(StateMachineEngine stateMachineEngine) {
Map<String, Object> startParams = new HashMap<>(4);
String businessKey = String.valueOf(System.currentTimeMillis());
startParams.put("businessKey", businessKey);
startParams.put("count", 10);
startParams.put("amount", new BigDecimal("100"));
startParams.put("mockReduceBalanceFail", "true");
//sync test
StateMachineInstance inst = stateMachineEngine.startWithBusinessKey("reduceInventoryAndBalance", null, businessKey, startParams);
Assert.isTrue(ExecutionStatus.SU.equals(inst.getCompensationStatus()), "saga transaction compensate failed. XID: " + inst.getId());
System.out.println("saga transaction compensate succeed. XID: " + inst.getId());
}
和上个方法相比,这里就是多了一个 mockReduceBalanceFail 参数,在前面所说的那个 JSON 文件的定义中,定义了这个输入参数,大家看下面这段 JSON:
"ReduceBalance": {
"Type": "ServiceTask",
"ServiceName": "balanceAction",
"ServiceMethod": "reduce",
"CompensateState": "CompensateReduceBalance",
"Input": [
"$.[businessKey]",
"$.[amount]",
{
"throwException" : "$.[mockReduceBalanceFail]"
}
],
"Output": {
"compensateReduceBalanceResult": "$.#root"
},
可以看到这个输入参数中有 mockReduceBalanceFail,不过这里不是直接将其作为输入参数,而是将之转为了一个 Map,这个 Map 的 key 是 throwException,所以在 BalanceActionImpl#reduce 方法中会有如下一段代码:
public boolean reduce(String businessKey, BigDecimal amount, Map<String, Object> params) {
if(params != null && "true".equals(params.get("throwException"))){
throw new RuntimeException("reduce balance failed");
}
LOGGER.info("reduce balance succeed, amount: " + amount + ", businessKey:" + businessKey);
return true;
}
如果 throwException 的值为 true,就会抛出异常,此时就会触发事务的回滚。
再回到二阶段回滚的方法中,最后通过 inst.getCompensationStatus() 方法获取事务补偿操作的状态,如果该方法返回 true,表示事务的补偿操作执行成功。
案例中涉及到一些 Dubbo 的知识点我这里就不赘述了,这不是我们本文的主旨。
好啦,经过上面的分析,大家应该大致上明白了这个 Saga 到底是怎么玩的了。
4. 设计经验
4.1 允许空补偿
空补偿就是原服务未执行,结果补偿服务执行了,当原服务出现超时、丢包等情况时或者在收到原服务请求之前先收到补偿请求,就可能会出现空补偿。
因此我们在服务设计时需要允许空补偿, 即没有找到要补偿的业务主键时返回补偿成功并将原业务主键记录下来,这也是案例中,无论是原服务还是补偿服务都有 businessKey 参数的原因。
4.2 防悬挂控制
悬挂就是补偿服务比原服务先执行,出现的原因和前面说的差不多,所以我们需要在执行原服务时,要先检查一下当前业务主键是否已经在空补偿记录下来,如果已经被记录下来,说明补偿已经先执行了,此时我们可以停止原服务的执行。
4.3 幂等控制
原服务与补偿服务都需要保证幂等性, 由于网络可能超时, 所以我们可能会设置重试策略,重试发生时要通过幂等控制,避免业务数据重复更新。如何保证幂等性,松哥之前公众号的文章中和大家聊过,这里就不再赘述了。
4.4 缺乏隔离性的应对
由于 Saga 事务不保证隔离性, 在极端情况下可能由于脏写无法完成回滚操作。
举一个极端的例子, 分布式事务内先给用户 A 充值, 然后给用户 B 扣减余额, 如果在给 A 用户充值成功, 在事务提交以前, A 用户把余额消费掉了, 如果事务发生回滚, 这时则没有办法进行补偿了。这就是缺乏隔离性造成的典型的问题。
对于这种问题,我们可以通过如下方式来尝试解决:
业务流程设计时遵循“宁可长款, 不可短款”的原则, 长款意思是客户少了钱机构多了钱, 以机构信誉可以给客户退款, 反之则是短款, 少的钱可能追不回来了。所以在业务流程设计上一定是先扣款。
有些业务场景可以允许让业务最终成功, 在回滚不了的情况下可以继续重试完成后面的流程, 所以状态机引擎除了提供“回滚”能力还需要提供“向前”恢复上下文继续执行的能力, 让业务最终执行成功, 达到最终一致性的目的。
4.5 性能优化
配置客户端参数 client.rm.report.success.enable=false,可以在当分支事务执行成功时不上报分支状态到 server,从而提升性能。
当上一个分支事务的状态还没有上报的时候,下一个分支事务已注册,可以认为上一个实际已成功
5. 小结
这就是 Seata 分布式事务中的 Saga 模式。至此,Seata 中的四种分布式事务模式松哥就都和大家扯完了,后面我在整一篇文章比较下这四种模式。
另外三篇传送门:
公号后台回复 seata-demo 可以下载本文案例。
参考资料:
- https://www.sofastack.tech/blog/sofa-channel-10-retrospect/
- https://seata.io/zh-cn/docs/user/saga.html
以上是关于你这 Saga 事务保“隔离性”吗?的主要内容,如果未能解决你的问题,请参考以下文章