为什么说datax是目前最好的异构数据源数据交换工具
Posted Java鱼仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么说datax是目前最好的异构数据源数据交换工具相关的知识,希望对你有一定的参考价值。
本文收录于JavaStarter ,里面有我完整的Java系列文章,学习或面试都可以看看
(一)什么是Datax
以前我做过一个项目,其中有个需求就是每天定时把sql server中的数据同步到mysql中,当时写了一段Java的代码来实现,一套Java代码中需要写两个数据源的连接以及两套sql的代码,十分不方便。如果还要实现Oracle、Mysql、SqlServer的互相同步,那代码逻辑就更加复杂。而且通过代码的方式,同步600万条数据要花费2个多小时,性能效率十分低下。
最近在工作中接触到了一个新的工具datax,才意识到数据同步原来还有这么简单的方式。
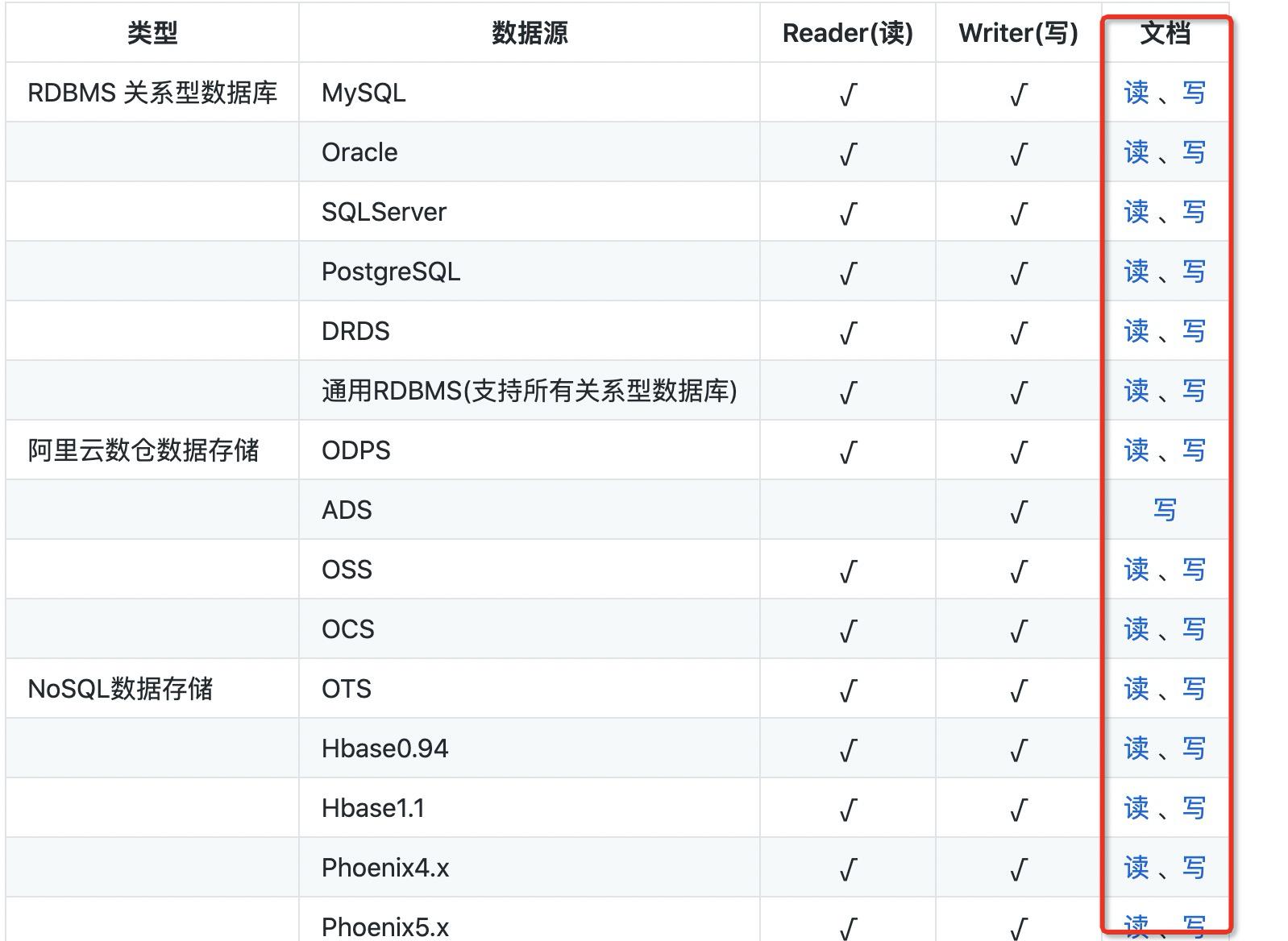
Datax是阿里巴巴开源的一个异构数据源离线同步工具,DataX 实现了包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能。
简单来讲,datax就是可以把各个数据库之间的数据来回传输同步,并且操作起来只需要配置一下json文件就可以了。
目前Datax开源在github上:https://github.com/alibaba/DataX
(二)Datax架构

Datax的架构采用FrameWork+plugin构建,其中:
Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework
Writer:数据写入模块,负责不断向Framework取数据,并将数据写入到目的端
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲、流控、并发、数据转换等核心技术问题。
(三)Datax运行原理
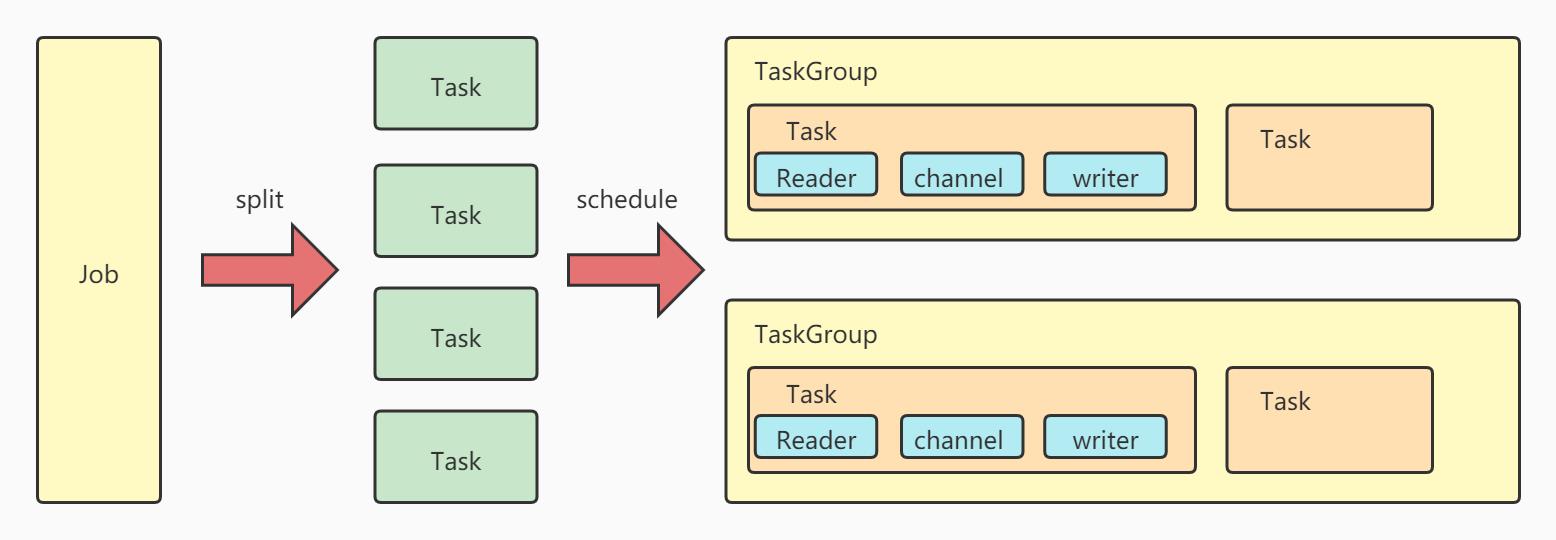
Job:单个作业的管理节点,负责数据清理、子任务划分、TaskGroup监控管理
Task:由Job切分出来,是Datax的最小单元,每隔Task负责一部分数据的同步工作
Schedule:将Task组成TaskGroup,单个TaskGroup的并发数量为5.
TaskGroup:负责启动Task
(四)DataX快速入门
datax的推荐系统为:
- Linux
- JDK(1.8以上,推荐1.8)
- Python(推荐Python2.6.X)
- Apache Maven 3.x (Compile DataX)
我这里就按照推荐系统进行操作。
首先我们将datax下载下来,datax的下载有两种方式,一种是直接下载压缩包,另外一种是下载源码自己手动编译,这里先展示下载压缩包的使用方式:
首先是下载datax的压缩包:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
下载下来后上传到linux服务器上,解压:
tar -zxvf datax.tar.gz
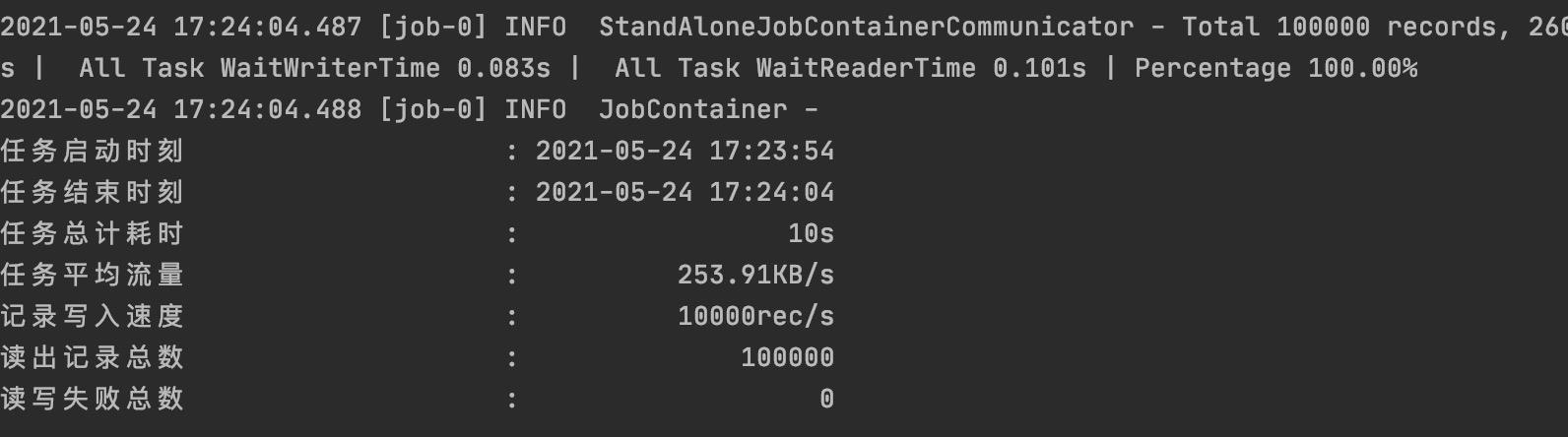
进入datax的bin目录,运行自检脚本
cd datax/bin/
python datax.py ../job/job.json
运行结果如果是下面这样说明datax安装成功。
(五)datax控制台数据同步
datax的作用就是实现异构数据库之间的数据传输,并且应用起来还比较简单,只需要配置好对应的json模板,就可以对数据进行传输。
通过下面的命令,就可以拿到datax对应的json模板,比如我现在的reader是控制台数据,writer也是控制台数据:
python datax.py -r streamreader -w streamwriter
就拿到了对应的模板:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
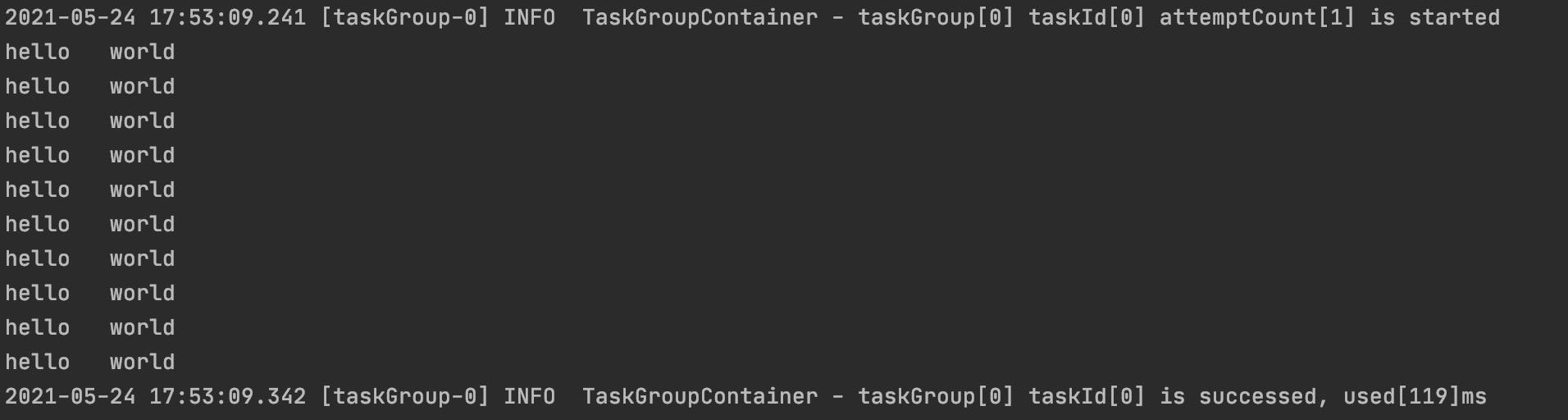
我们简单配置一下看看效果,效果就是在控制台输出十遍hello,world,在job目录下新建一个文件叫stream2stream.json
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{
"type":"string",
"value":"hello"
},
{
"type":"string",
"value":"world"
}
],
"sliceRecordCount": "10"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
运行项目:
python datax.py ../job/stream2stream.json
查看效果
(六)datax mysql数据同步
因为本地只装了mysql,就直接用mysql演示数据同步,首先还是通过命令拿到基本配置模板:
python datax.py -r mysqlreader -w mysqlwriter
简单介绍一下模板:
column:表示reader或者writer中对应的列名
connection:填写连接信息
where:设置连接条件
具体的其他参数可以在官方文档中全部找到更详细说明
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [], #需要同步的列
"connection": [ #连接信息
{
"jdbcUrl": [],
"table": []
}
],
"password": "", #密码
"username": "", #用户名
"where": "" #筛选条件
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [], #写入段的列名,与上面需要同步的值的位置保持一致
"connection": [ #连接信息
{
"jdbcUrl": "",
"table": []
}
],
"password": "", #密码
"preSql": [], #执行写入之前做的事情
"session": [], # DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性
"username": "", #用户名
"writeMode": "" #控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
做个初始工作,在mysql中先建两张表,一张有数据,一张没有数据:
CREATE TABLE `user`(
`id` int(4) not null auto_increment,
`name` varchar(32) not null,
PRIMARY KEY(id)
)
CREATE TABLE `user2`(
`id` int(4) not null auto_increment,
`name` varchar(32) not null,
PRIMARY KEY(id)
)
INSERT INTO `user` VALUES (1,'javayz')
INSERT INTO `user` VALUES (2,'java')
接下来配置mysql2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://10.10.128.120:3306/test"],
"table": ["user"]
}
],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://10.10.128.120:3306/test",
"table": ["user2"]
}
],
"password": "123456",
"username": "root"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
同样运行脚本:
python datax.py ../job/mysql2mysql.json
控制台输出成功之后,查看数据库,可以发现数据已经同步过去了。
(七)总结
上面展示了两种方式的数据同步,除此之外datax还支持大量的数据库,并且使用文档写的十分详细,大家有兴趣可以自己去尝试一下,十分有意思的工具。
我是鱼仔,我们下期再见!
以上是关于为什么说datax是目前最好的异构数据源数据交换工具的主要内容,如果未能解决你的问题,请参考以下文章