Python数学建模系列:时间序列
Posted 海轰Pro
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数学建模系列:时间序列相关的知识,希望对你有一定的参考价值。
文章目录
前言
Hello!小伙伴!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
自我介绍 ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,有幸拿过一些国奖、省奖…已保研。目前正在学习C++/Linux/Python
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
初学Python 小白阶段
文章仅作为自己的学习笔记 用于知识体系建立以及复习
题不在多 学一题 懂一题
知其然 知其所以然!
往期文章
1 JetRail高铁乘客量预测——7种时间序列方法
内容简介
时间序列预测在日常分析中常会用到,是重要的时序数据处理方法。
高铁客运量预测
假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量。
数据获取:获得2012-2014两年每小时乘客数量
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
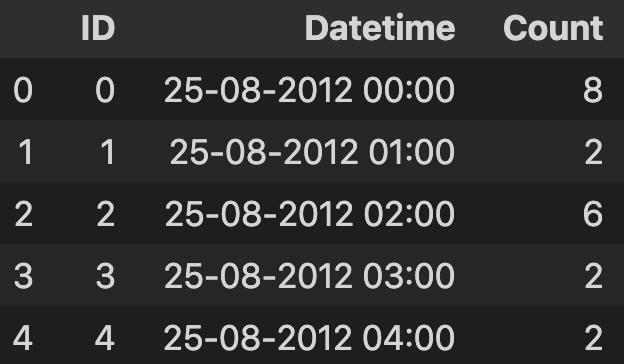
df = pd.read_csv('../profile/train2.csv')
df.head()
运行结果
数据集处理:(以每天为单位构造和聚合数据集)
- 从2012年8月—2013年12月的数据中构造一个数据集
- 创建train and test文件用于建模。前14个月(2012年8月—2013年10月)用作训练数据,后两个月(2013年11月—2013年12月)用作测试数据。
- 以每天为单位聚合数据集
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('../profile/train2.csv',nrows=11856)
train = df[0:10392]
test = df[10392:]
df['Timestamp'] = pd.to_datetime(df['Datetime'], format='%d-%m-%Y %H:%M') # 4位年用Y,2位年用y
df.index = df['Timestamp']
df = df.resample('D').mean() #按天采样,计算均值
train['Timestamp'] = pd.to_datetime(train['Datetime'], format='%d-%m-%Y %H:%M')
train.index = train['Timestamp']
train = train.resample('D').mean()
test['Timestamp'] = pd.to_datetime(test['Datetime'], format='%d-%m-%Y %H:%M')
test.index = test['Timestamp']
test = test.resample('D').mean()
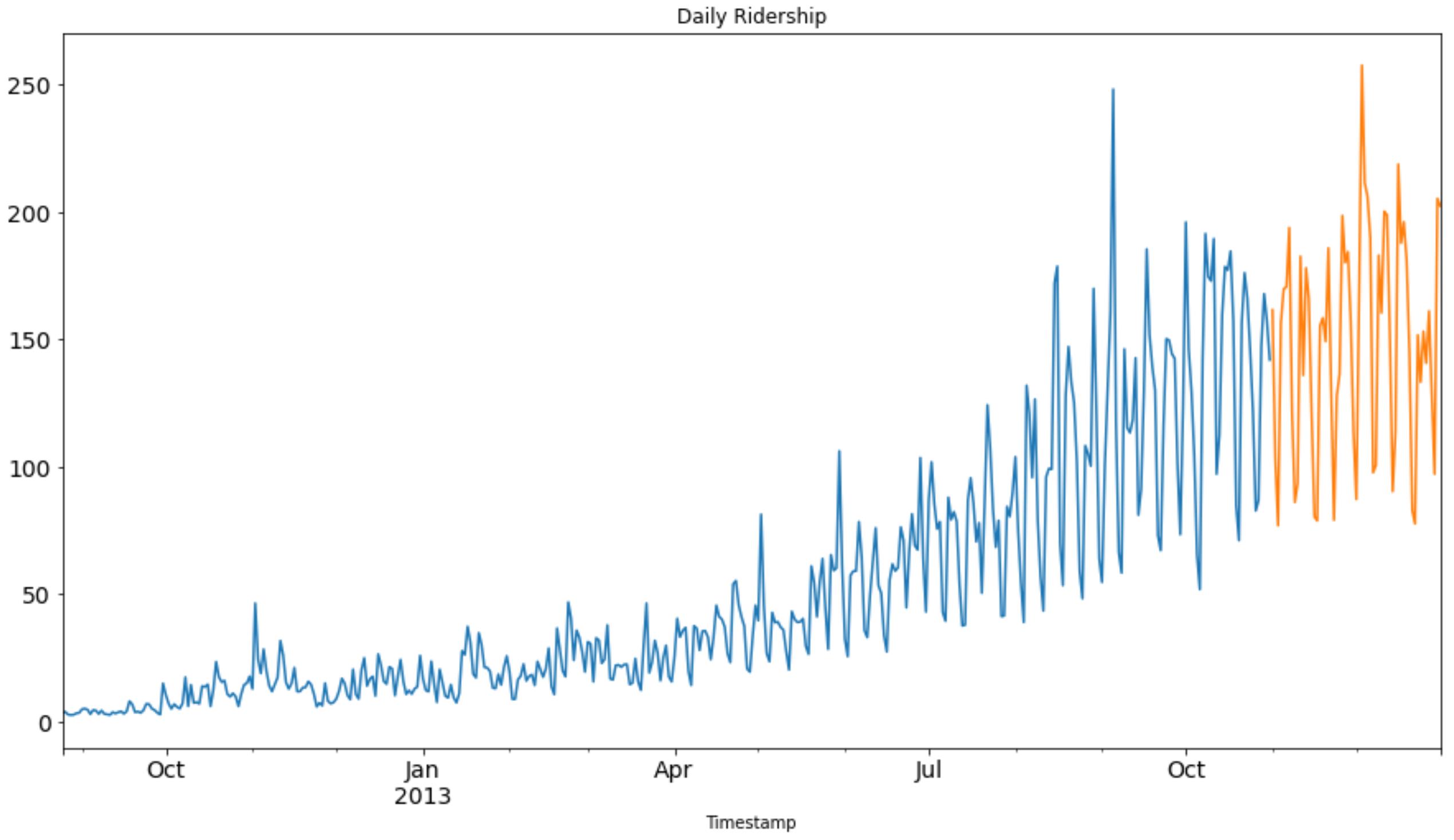
train.Count.plot(figsize=(15,8), title= 'Daily Ridership', fontsize=14)
test.Count.plot(figsize=(15,8), title= 'Daily Ridership', fontsize=14)
plt.show()
运行结果
1.1 朴素法
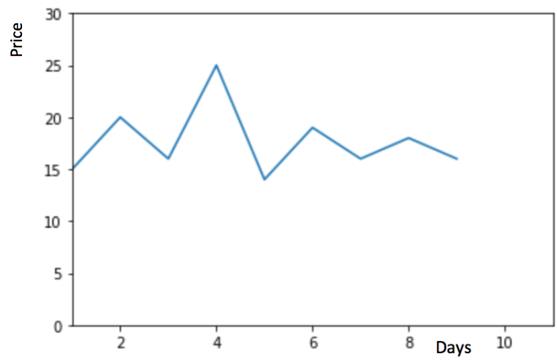
如下图所示, y 轴表示物品的价格,x 轴表示时间(天)
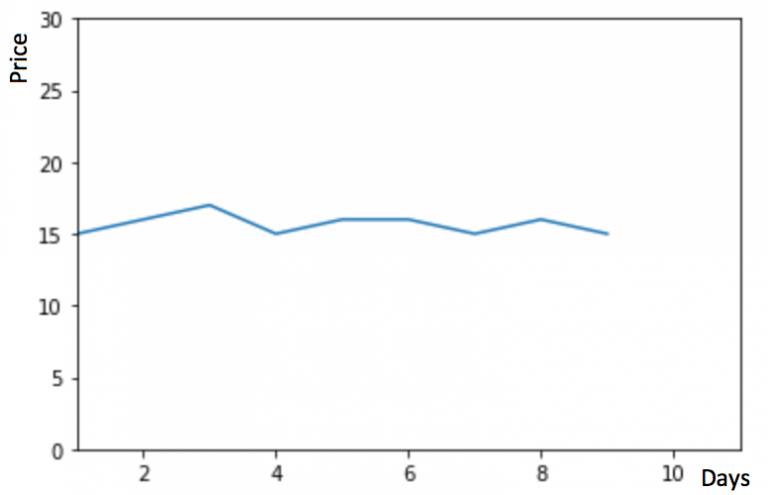
如果数据集在一段时间内都很稳定,我们想预测第二天的价格,可以取前面一天的价格,预测第二天的值。这种假设第一个预测点和上一个观察点相等的预测方法就叫朴素法。即
H
e
n
c
e
y
^
t
+
1
=
y
t
Hence \\quad \\hat y_{t+1} = y_t
Hencey^t+1=yt
Demo代码
dd = np.asarray(train['Count'])
y_hat = test.copy()
y_hat['naive'] = dd[len(dd) - 1]
plt.figure(figsize=(12, 8))
plt.plot(train.index, train['Count'], label='Train')
plt.plot(test.index, test['Count'], label='Test')
plt.plot(y_hat.index, y_hat['naive'], label='Naive Forecast')
plt.legend(loc='best')
plt.title("Naive Forecast")
plt.show()
运行结果
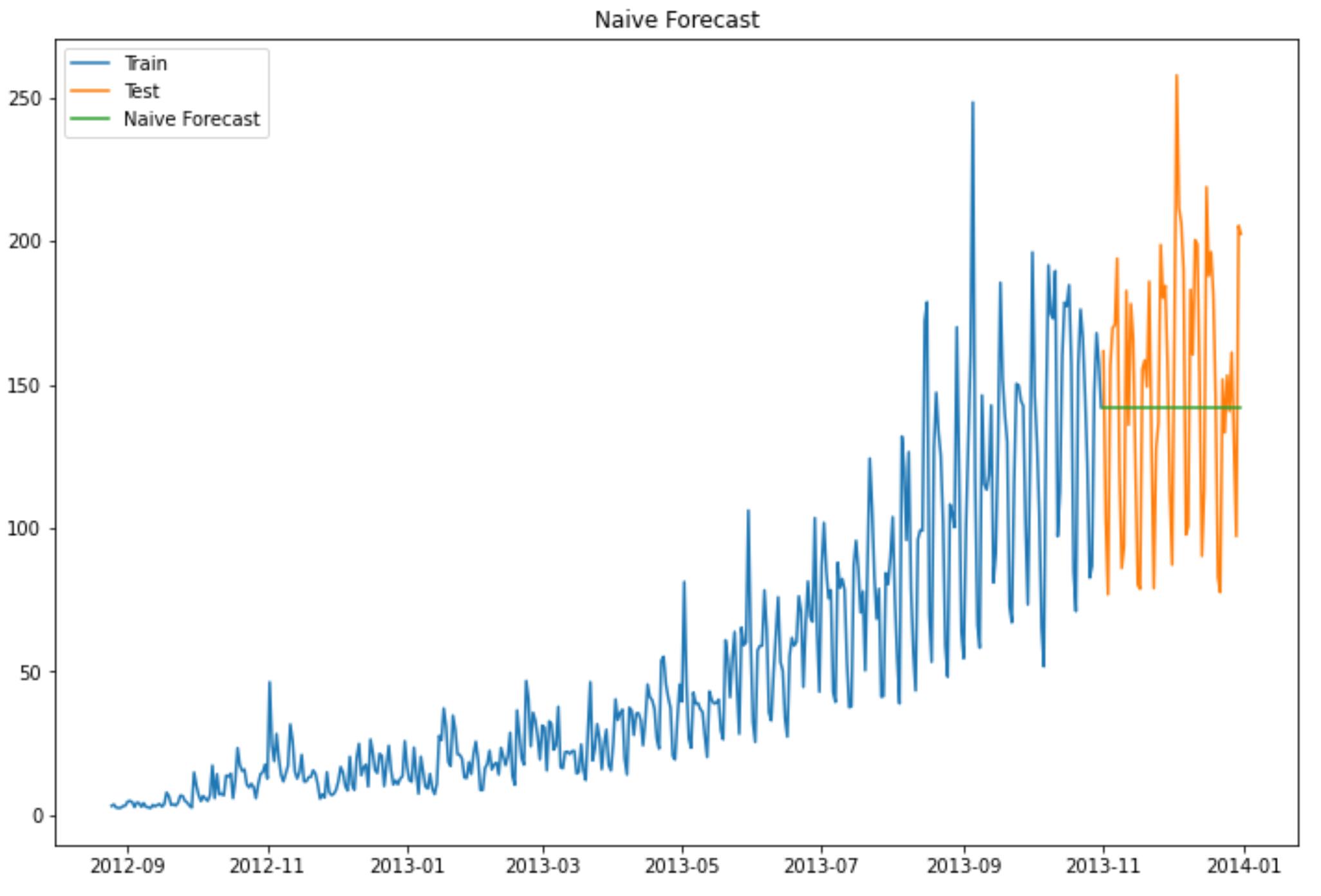
朴素法并不适合变化很大的数据集,最适合稳定性很高的数据集。我们计算下均方根误差,检查模型在测试数据集上的准确率:
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat['naive']))
print(rms)
# 43.91640614391676
运行结果

最终均方根误差RMS为:43.91640614391676
1.2 简单平均法
如下图所示, y 轴表示物品的价格,x 轴表示时间(天)
物品价格会随机上涨和下跌,平均价格会保持一致。我们经常会遇到一些数据集,虽然在一定时期内出现小幅变动,但每个时间段的平均值确实保持不变。这种情况下,我们可以预测出第二天的价格大致和过去天数的价格平均值一致。这种将预期值等同于之前所有观测点的平均值的预测方法就叫简单平均法。即
H
e
n
c
e
y
^
x
+
1
=
1
x
∑
i
=
1
x
y
i
Hence \\quad \\hat y_{x+1} = \\frac{1}{x} \\sum^x_{i=1}y_i
Hencey^x+1=x1∑i=1xyi
y_hat_avg = test.copy()
y_hat_avg['avg_forecast'] = train['Count'].mean()
plt.figure(figsize=(12,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['avg_forecast'], label='Average Forecast')
plt.legend(loc='best')
plt.show()
运行结果
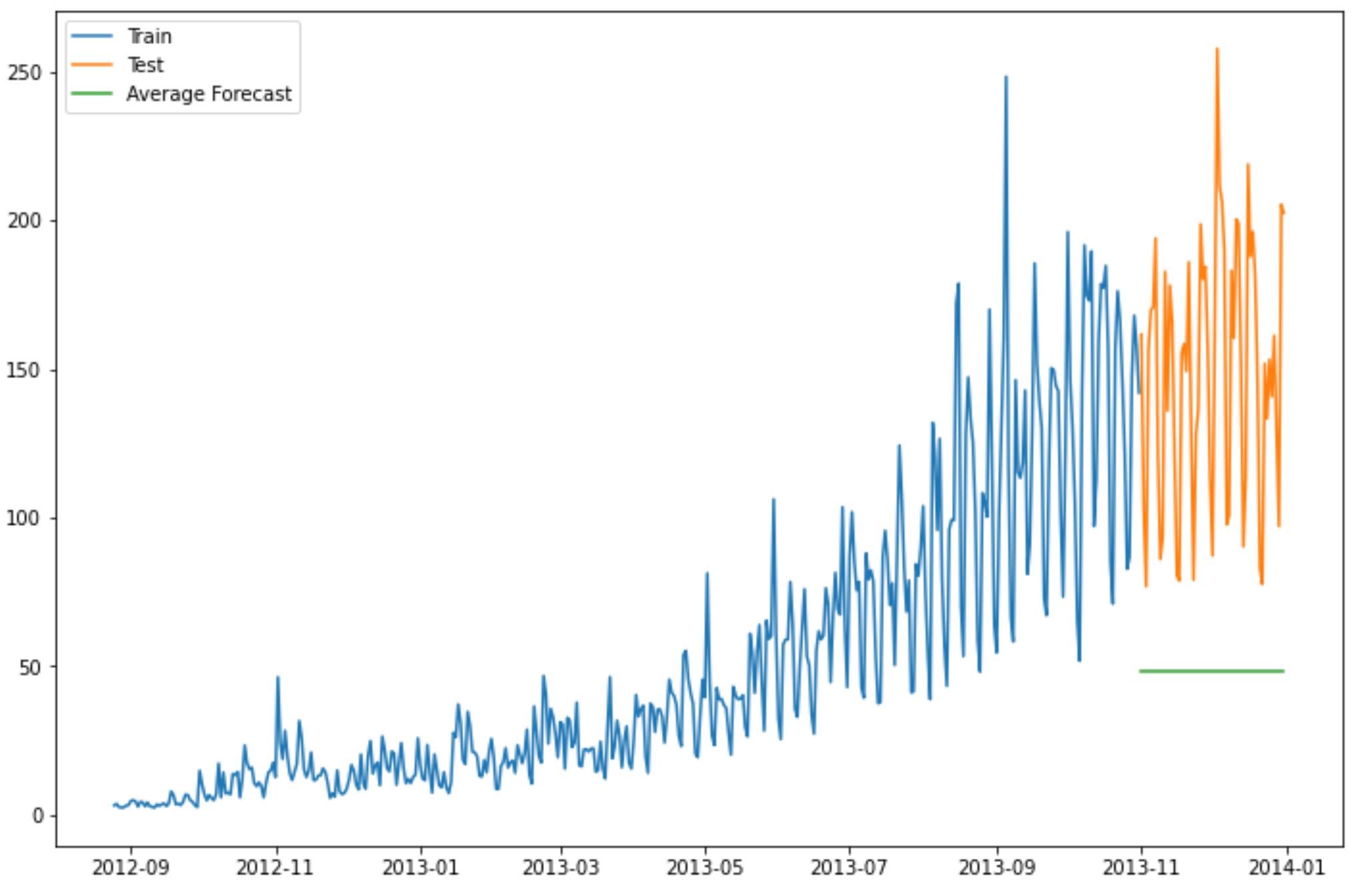
简单平均法用之前全部已知的值计算出它们的平均值,将它作为要预测的下一个值。当然这不会 很准确,但这种预测方法在某些情况下效果是最好的。
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['avg_forecast']))
print(rms)
# 109.88526527082863
运行结果

这种模型并没有改善准确率。因此我们可以从中推断出当每个时间段的平均值保持不变时,这种 方法的效果才能达到最好。虽然朴素法的准确率高于简单平均法,但这并不意味着朴素法在所有 的数据集上都比简单平均法好。
1.3 移动平均法
如下图所示, y 轴表示物品的价格,x 轴表示时间(天)
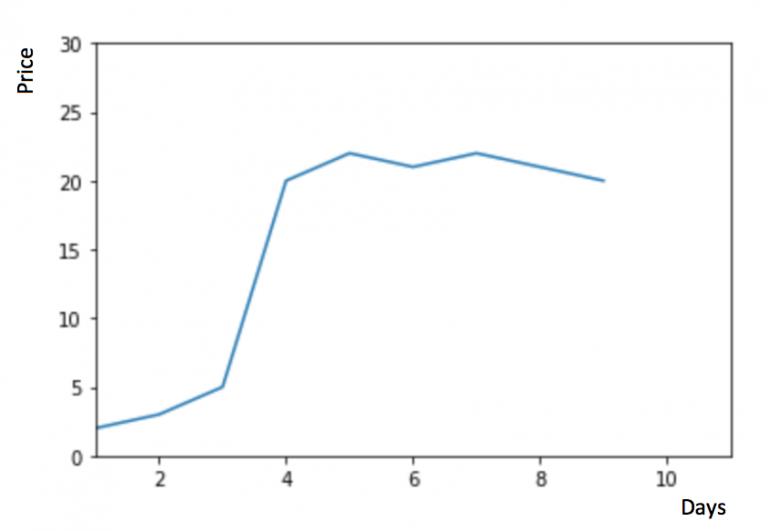
物品价格在一段时间内大幅上涨,但后来又趋于平稳。我们也经常会遇到这种数据集,比如价格或销售额某段时间大幅上升或下降。如果我们这时用之前的简单平均法,就得使用所有先前数据的平均值,但在这里使用之前的所有数据是说不通的,因为用开始阶段的价格值会大幅影响接下来日期的预测值。因此,我们只取最近几个时期的价格平均值。很明显这里的逻辑是只有最近的值最要紧。这种用某些窗口期计算平均值的预测方法就叫移动平均法。
计算移动平均值涉及到一个有时被称为“滑动窗口”的大小值p。使用简单的移动平均模型,我们可以根据之前数值的固定有限数p的平均值预测某个时序中的下一个值。这样,对于所有的 𝑖>𝑝:
H e n c e y ^ l = 1 p ( y i − 1 + y i − 2 + . . . + y i − p ) Hence \\quad \\hat y_l = \\frac{1}{p}(y_{i-1} + y_{i-2} + ... + y_{i-p}) Hencey^l=p1(yi−1+yi−2+...+yi−p)
移动平均法实际很有效,特别是当你为时序选择了正确的p值时
y_hat_avg = test.copy()
y_hat_avg['moving_avg_forecast'] = train['Count'].rolling(60).mean().iloc[-1]
plt.figure(figsize=(16,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['moving_avg_forecast'], label='Moving Average Forecast')
plt.legend(loc='best')
plt.show()
运行结果
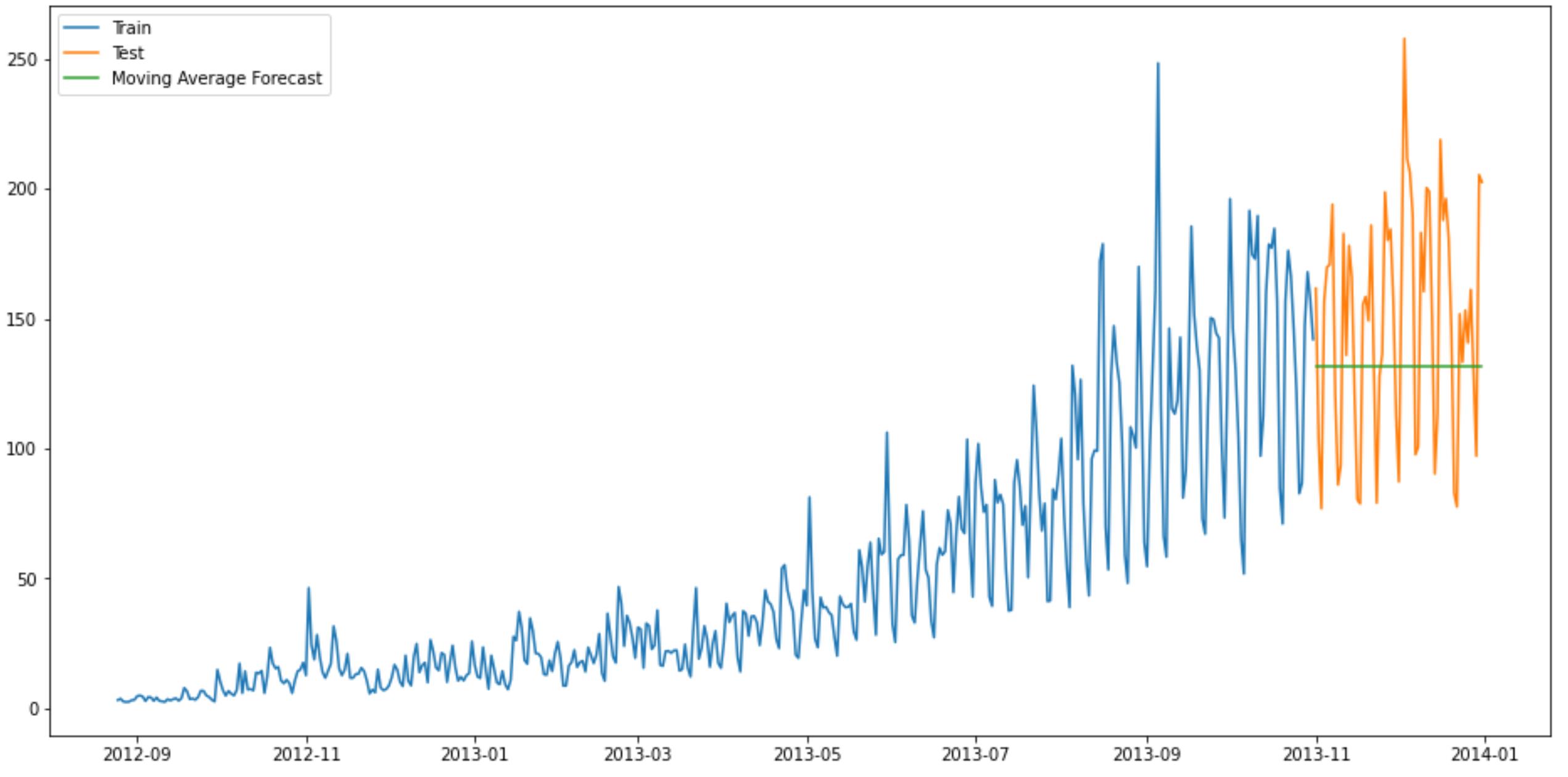
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['moving_avg_forecast']))
print(rms)
此方法计算出来的均方根差为:46.72840725106963
我们可以看到,对于这个数据集,朴素法比简单平均法和移动平均法的表现要好。此外,我们还可以试试简单指数平滑法,它比移动平均法的一个进步之处就是相当于对移动平均法进行了加权。在上文移动平均法可以看到,我们对“p”中的观察值赋予了同样的权重。但是我们可能遇到一些情况,比如“p”中每个观察值会以不同的方式影响预测结果。将过去观察值赋予不同权重的方法就叫做加权移动平均法。加权移动平均法其实还是一种移动平均法,只是“滑动窗口期”内的值被赋予不同的权重,通常来讲,最近时间点的值发挥的作用更大了。
H e n c e y ^ l = 1 m ( w 1 y i − 1 + w 2 y i − 2 + w 3 y i − 3 + . . . + w m y i − m ) Hence \\quad \\hat y_l = \\frac{1}{m}(w_1y_{i-1} + w_2y_{i-2} + w_3y_{i-3} + ... + w_my_{i-m}) Hencey^l=m1(w1yi−1+w2yi−2+w3yi−3+...+wmyi−m)
这种方法并非选择一个窗口期的值,而是需要一列权重值(相加后为1)。例如,如果我们选择[0.40, 0.25, 0.20, 0.15]作为权值,我们会为最近的4个时间点分别赋给40%,25%,20%和15%的权重。
1.4 简单指数平滑法
我们注意到简单平均法和加权移动平均法在选取时间点的思路上存在较大的差异。我们就需要在这两种方法之间取一个折中的方法,在将所有数据考虑在内的同时也能给数据赋予不同非权重。例如,相比更早时期内的观测值,它会给近期的观测值赋予更大的权重。按照这种原则工作的方法就叫做简单指数平滑法。它通过加权平均值计算出预测值,其中权重随着观测值从早期到晚期的变化呈指数级下降,最小的权重和最早的观测值相关:
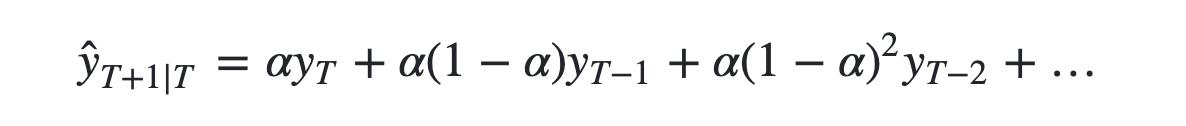
其中0≤α≤1是平滑参数。对时间点T+1的单步预测值是时序所有观测值的加权平均数。权重下降的速率由参数α控制,预测值
y
^
x
\\hat y_x
y^x是时间点T的单步预测值与
(
1
−
α
)
y
^
x
−
1
(1- \\alpha) \\hat y_{x-1}
(1−α)y^x−1的和。因而写作
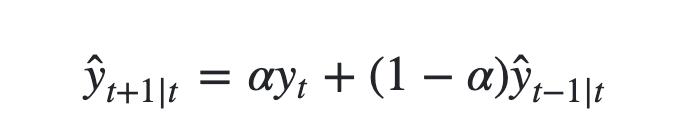
所以本质上,我们是用两个权重α和1−α得到一个加权移动平均值。我们可以看到 y ^ x − 1 \\hat y_{x-1} y^x−1和1−α相乘,让表达式呈递进形式,这也是该方法被称为“指数”的原因。时间 t+1 处的预测值为最近观测值yt和最近预测值 y ^ t ∣ t − 1 \\hat y_{t|t-1} 以上是关于Python数学建模系列:时间序列的主要内容,如果未能解决你的问题,请参考以下文章