python数据分析与展示Numpy入门
Posted BkbK-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python数据分析与展示Numpy入门相关的知识,希望对你有一定的参考价值。
Numpy入门
文章目录
一、Numpy基础
1.1 NumPy简介
NumPy是一个开源的Python科学计算基础库,包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合C/C++/Fortran代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
1.2 NumPy的引用及输出
NumPy的引用
import numpy as np
np.array()生成一个ndarray数组
a = np.array([[0,1,2,3,4],
[9,8,7,6,5]])
np.array()输出成[]形式,元素由空格分割
print(a)
[[0 1 2 3 4]
[9 8 7 6 5]]
二、ndarray对象
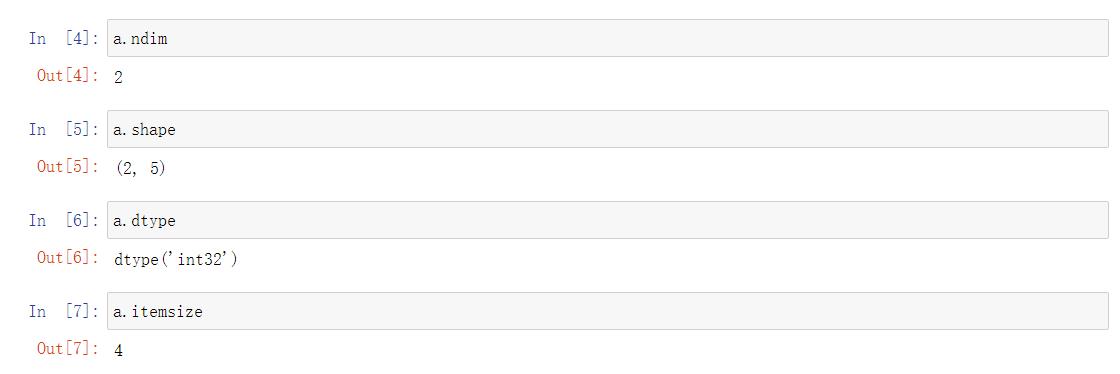
2.1 ndarray对象的属性
| 属性 | 说明 |
|---|---|
| .ndim | 秩,即轴的数量或维度的数量 |
| .shape | ndarray对象的尺度,对于矩阵,n行m列 |
| .size | ndarray对象元素的个数,相当于.shape中n*m的值 |
| .dtype | ndarray对象的元素类型 |
| .itemsize | ndarray对象中每个元素的大小,以字节为单位 |
a = np.array([[0,1,2,3,4],
[9,8,7,6,5]])
2.2 ndarray数组的元素类型
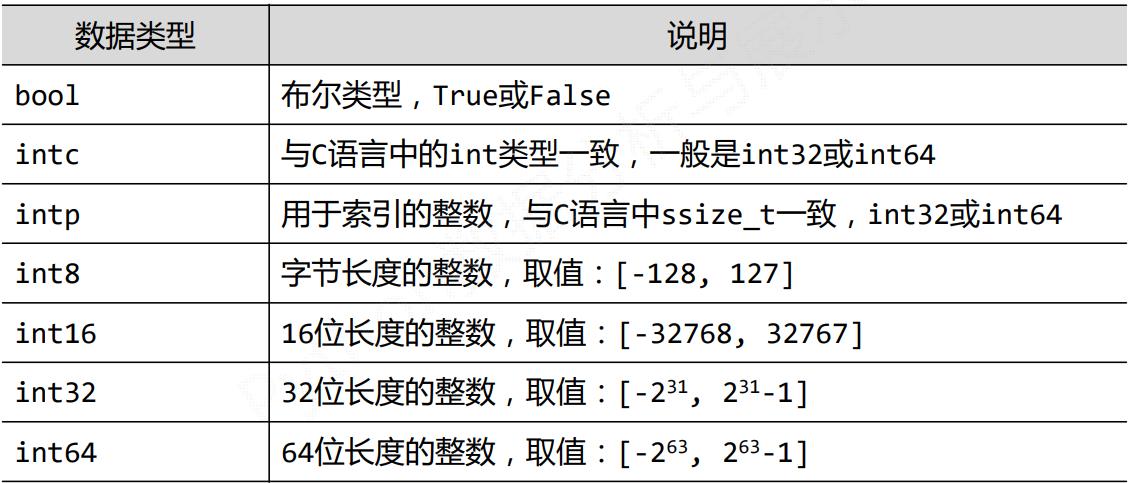
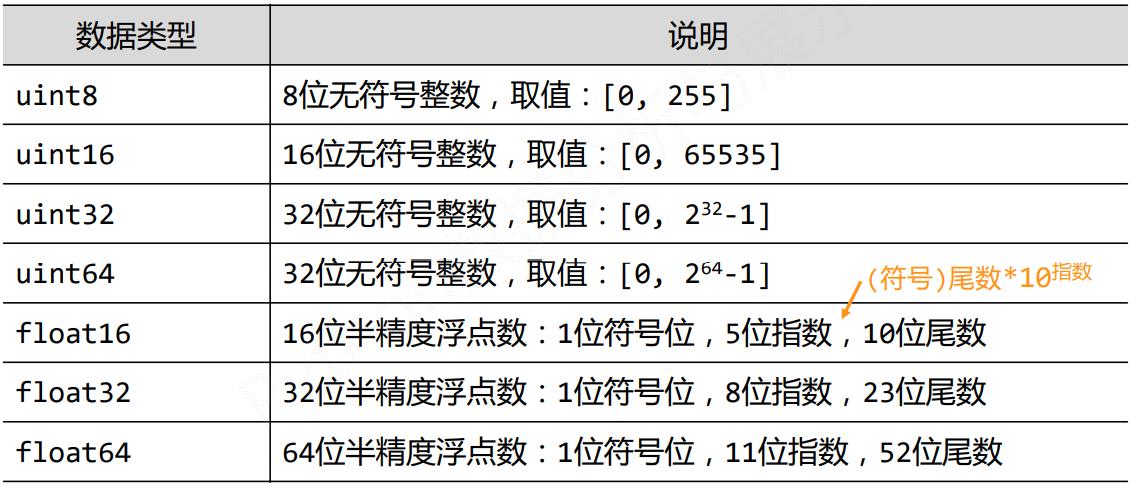

- 科学计算涉及数据较多,对存储和性能都有较高要求
- 对元素类型精细定义,有助于NumPy合理使用存储空间并优化性能
- 对元素类型精细定义,有助于程序员对程序规模有合理评估
三、ndarray操作
3.1 ndarray数组的创建
从Python中的列表、元组等类型创建ndarray数组
x = np.array(list/tuple)
x = np.array(list/tuple, dtype=np.float32)
当np.array()不指定dtype时,NumPy将根据数据情况关联一个dtype类型
-
从列表类型创建
x = np.array([0,1,2,3]) print(x)[0 1 2 3]
-
从元组类型创建
x = np.array((0,1,2,3)) print(x)[0 1 2 3]
-
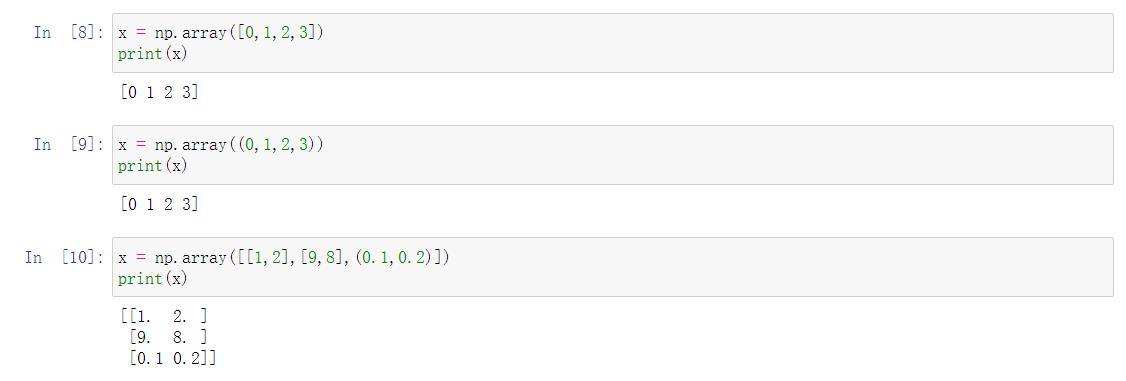
从列表和元组混合类型创
x = np.array([[1,2],[9,8],(0.1,0.2)]) print(x)[[1. 2. ]
[9. 8. ]
[0.1 0.2]]
使用NumPy中函数创建ndarray数组
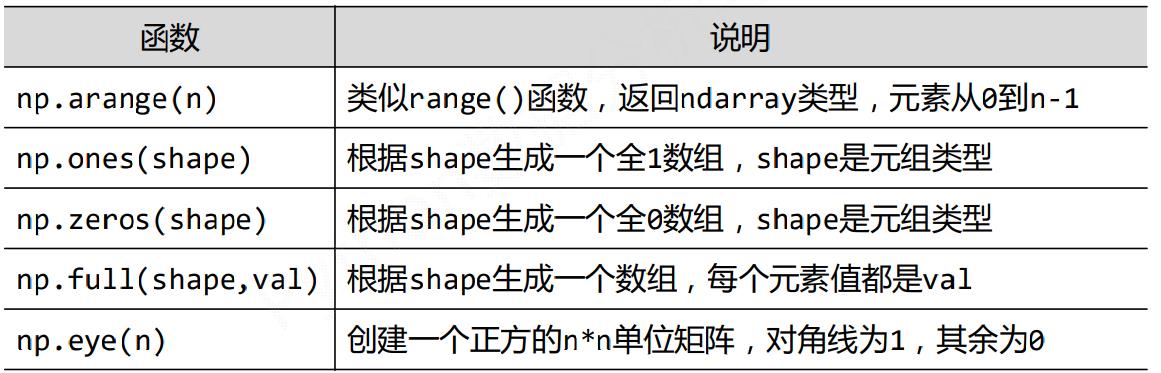
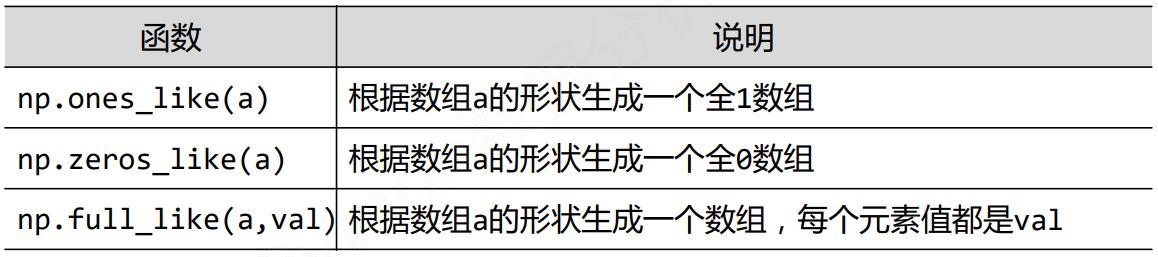

-
arange生成一维顺序数组np.arange(1,10,2)array([1, 3, 5, 7, 9])
np.arange(1,9,2)array([1, 3, 5, 7])
np.arange(10)array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
-
特殊多维数组
np.ones((3,6))array([[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]])np.zeros((3,6),dtype = np.int32)array([[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]])np.eye(5)array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])x = np.ones((2,3,4)) print(x) x.shape[[[1. 1. 1. 1.] [1. 1. 1. 1.] [1. 1. 1. 1.]] [[1. 1. 1. 1.] [1. 1. 1. 1.] [1. 1. 1. 1.]]] (2, 3, 4) -
其他方法
a = np.linspace(1,10,4) print(a)[ 1. 4. 7. 10.]
b = np.linspace(1,10,4,endpoint=False) print(b)[1. 3.25 5.5 7.75]
c = np.concatenate((a,b)) print(c)[ 1. 4. 7. 10. 1. 3.25 5.5 7.75]
3.2 ndarray数组的变换
数组维度的变换
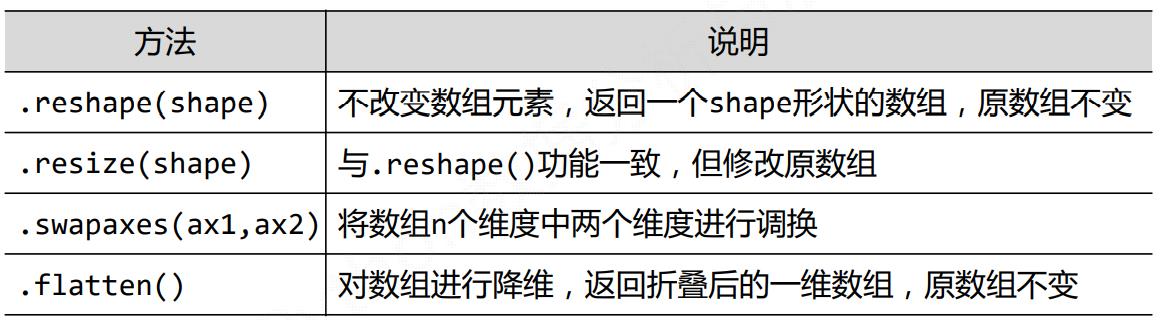
元素类型的变换
new_a = a.astype(new_type)
astype()方法一定会创建新的数组(原始数据的一个拷贝),即使两个类型一致
数组向列表的转换
ls = a.tolist()
3.3 ndarray数组的索引和切片
a = np.arange(24).reshape((2,3,4))
print(a)
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]][[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
索引
每个维度一个索引值,逗号分割
a[1,2,3]
a[1,2,3]
切片
选取一个维度用
a[:,1,-3]
array([ 5, 17])
每个维度切片方法与一维数组相同
a[:,1:3,:]
array([[[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[16, 17, 18, 19],
[20, 21, 22, 23]]])
每个维度可以使用步长跳跃切片
a[:,:,::2]
array([[[ 0, 2],
[ 4, 6],
[ 8, 10]],
[[12, 14],
[16, 18],
[20, 22]]])
3.4 ndarray数组的运算
NumPy一元函数
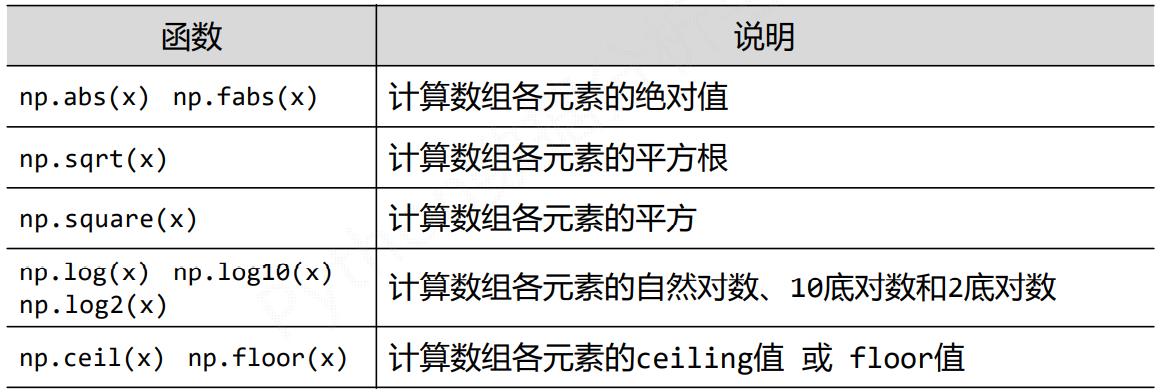
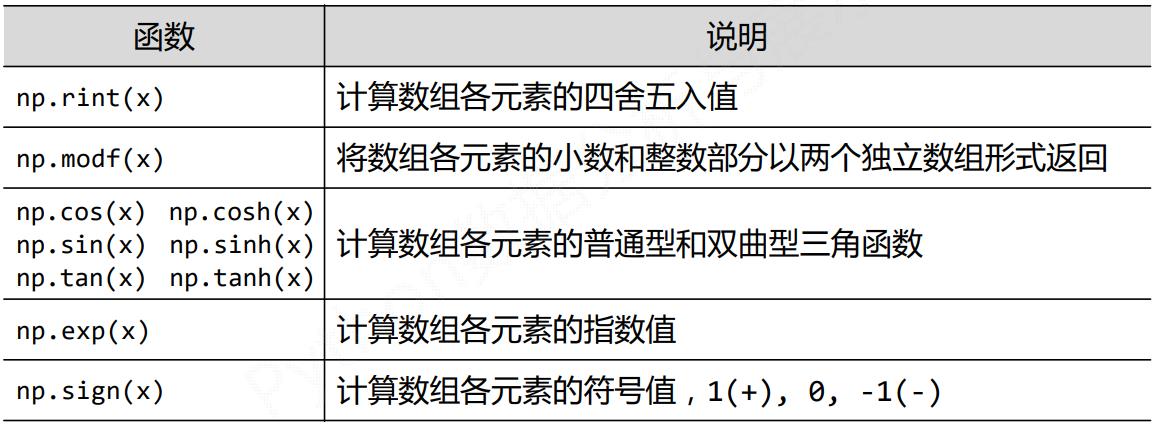
NumPy二元函数
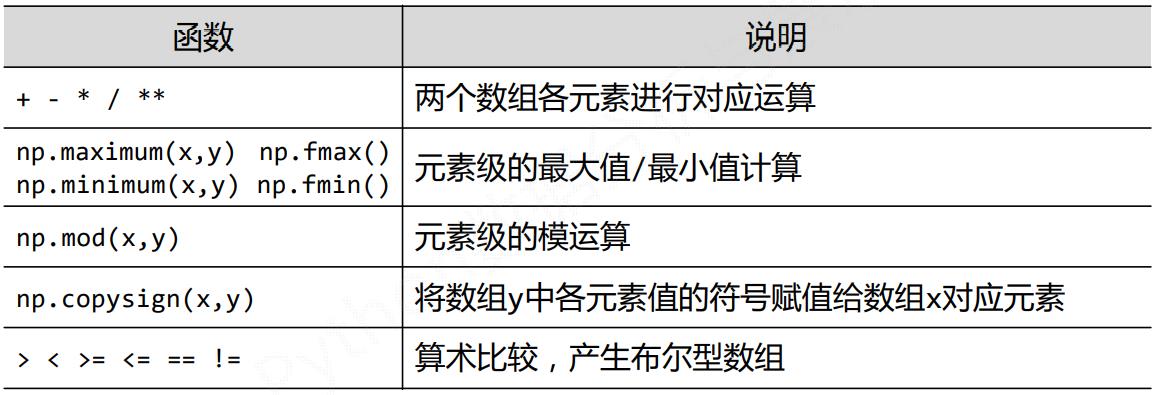
四、Numpy的数据存取
4.1 csv文件存取
CSV (Comma‐Separated Value, 逗号分隔值),CSV是一种常见的文件格式,用来存储批量数据.
一维和二维数组的存取
CSV只能有效存储一维和二维数组 np.savetxt() np.loadtxt()只能有效存取一维和二维数组
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
frame: 文件、字符串或产生器,可以是.gz或.bz2的压缩文件array: 存入文件的数组fmt: 写入文件的格式,例如:%d %.2f %.18edelimiter: 分割字符串,默认是任何空格
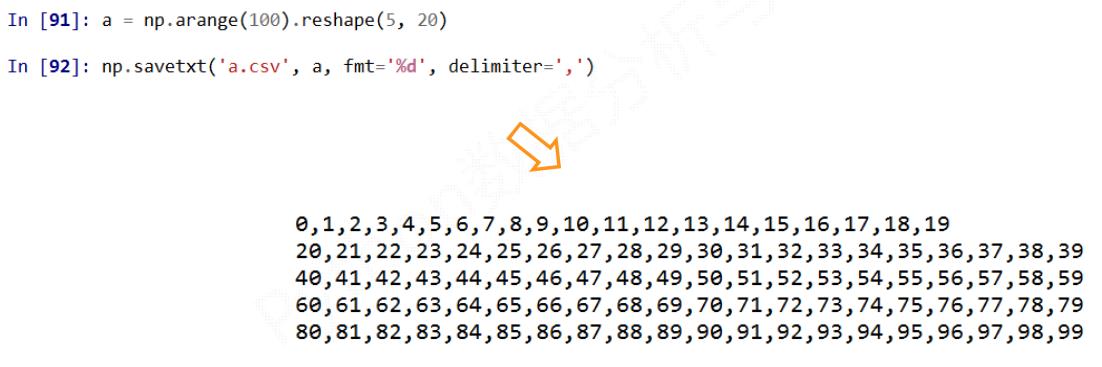
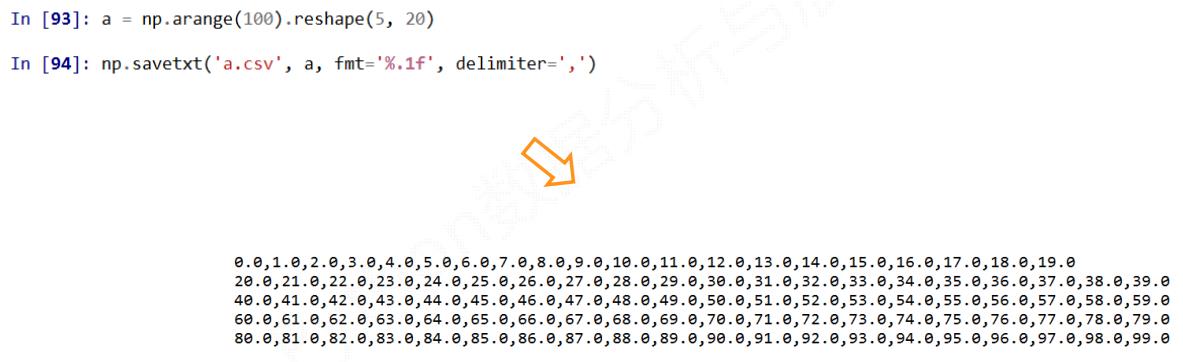
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
frame: 文件、字符串或产生器,可以是.gz或.bz2的压缩文件dtype: 数据类型,可选delimiter: 分割字符串,默认是任何空格unpack: 如果True,读入属性将分别写入不同变量

任意维度数组的存取
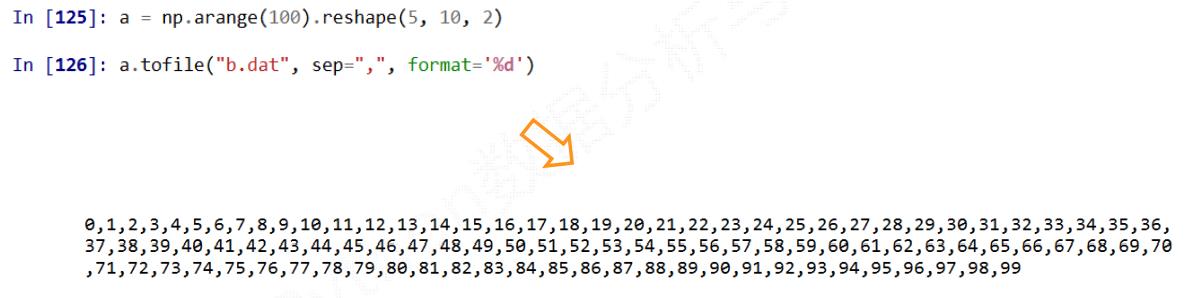
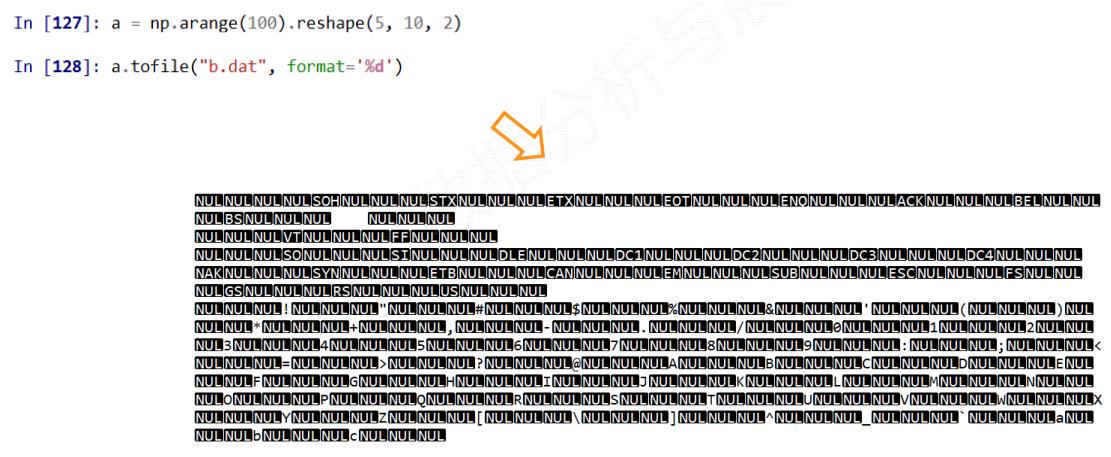
a.tofile(frame, sep='', format='%s')
frame: 文件、字符串sep: 数据分割字符串,如果是空串,写入文件为二进制format: 写入数据的格式
np.fromfile(frame, dtype=float, count=‐1, sep='')
frame: 文件、字符串dtype: 读取的数据类型count: 读入元素个数,‐1表示读入整个文件sep: 数据分割字符串,如果是空串,写入文件为二进制

4.2 便捷文件存取
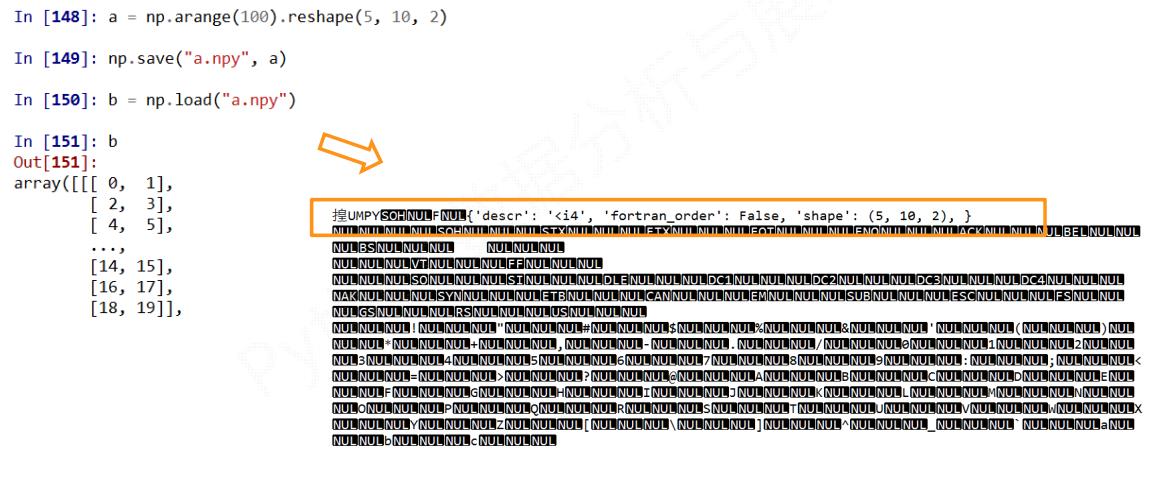
np.save(fname, array)
或
np.savez(fname, array)
fname: 文件名,以.npy为扩展名,压缩扩展名为.npzarray: 数组变量
np.load(fname)
fname: 文件名,以.npy为扩展名,压缩扩展名为.npz
五、Numpy的函数
5.1 Numpy的随机函数
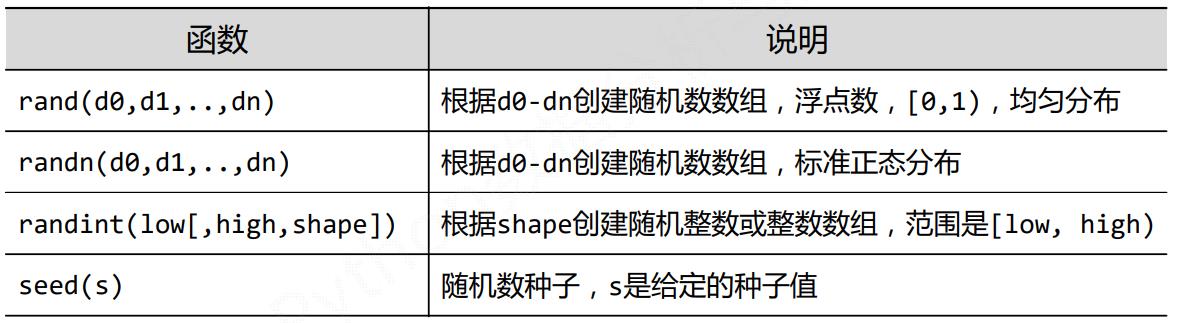
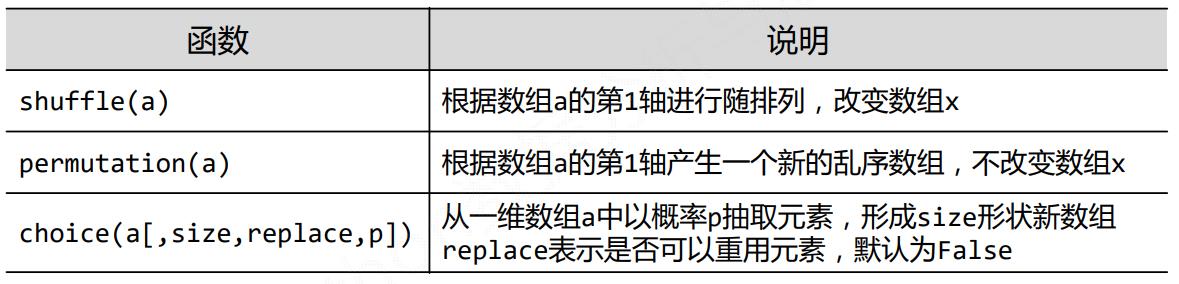

5.2 Numpy的统计函数

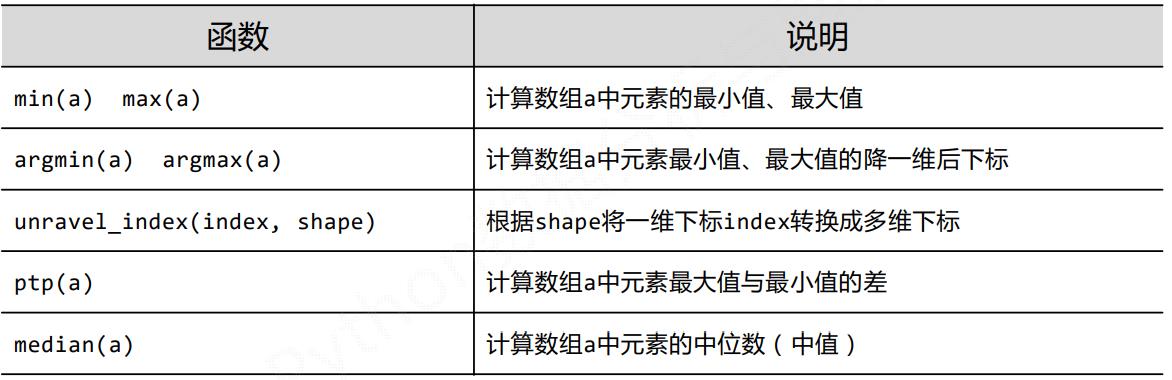
5.3 Numpy的梯度函数

以上是关于python数据分析与展示Numpy入门的主要内容,如果未能解决你的问题,请参考以下文章