机器学习类别/标称(categorical)数据处理:目标编码(target encoding)
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习类别/标称(categorical)数据处理:目标编码(target encoding)相关的知识,希望对你有一定的参考价值。
机器学习类别/标称(categorical)数据处理:目标编码(target encoding)
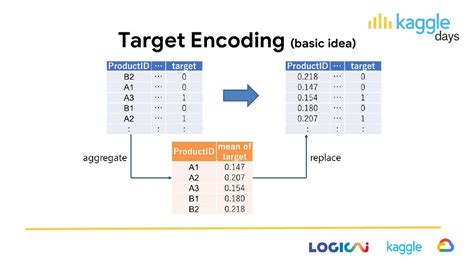
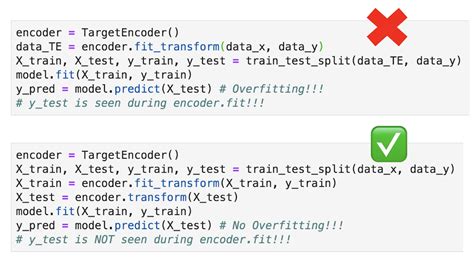
序号编码:序号编码通常用于处理类别间具有大小关系的数据
可以通过导入sklearn.preprocessing中的OrdinalEncoder进行处理。
独热编码:通常用于处理类别间不具有大小关系的特征。
可以通过导入sklearn.preprocessing中的OneHotEncoder,创建哑变量进行处理。或者使用pandas的get dummy方法;
二进制编码:二进制编码主要分为两步,先用序号编码给每个类别赋予一个类别ID,然后将类别ID对应的二进制编码作为结果。
target encoding:其实就是将分类特征替换为对应目标值的后验概率。
以性别“男”、“女”和“其他”为例,分别赋予其类别ID为1,2,3,对应二进制编码为001,010,011。
二进制
以上是关于机器学习类别/标称(categorical)数据处理:目标编码(target encoding)的主要内容,如果未能解决你的问题,请参考以下文章
机器学习类别/标称(categorical)数据处理:独热编码(One Hot Encoding)
标称变量(Categorical Features)或者分类变量(Categorical Features)缺失值填补详解及实战
使用Categorical_endcoder包对标称变量进行个性化编码
标称变量(Categorical Features)或者分类变量(Categorical Features)编码为数值变量(Continuous Features)
有序标称变量(Categorical Features)编码为数值变量(Continuous Features)详解及实践