大数据Spark Streaming Queries
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Spark Streaming Queries相关的知识,希望对你有一定的参考价值。
目录
1 输出模式
在StructuredStreaming中定义好Result DataFrame/Dataset后,调用writeStream()返DataStreamWriter对象,设置查询Query输出相关属性,启动流式应用运行,相关属性如下:
文档: http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#starting-streaming-queries
"Output"是用来定义写入外部存储器的内容,输出可以被定义为不同模式:
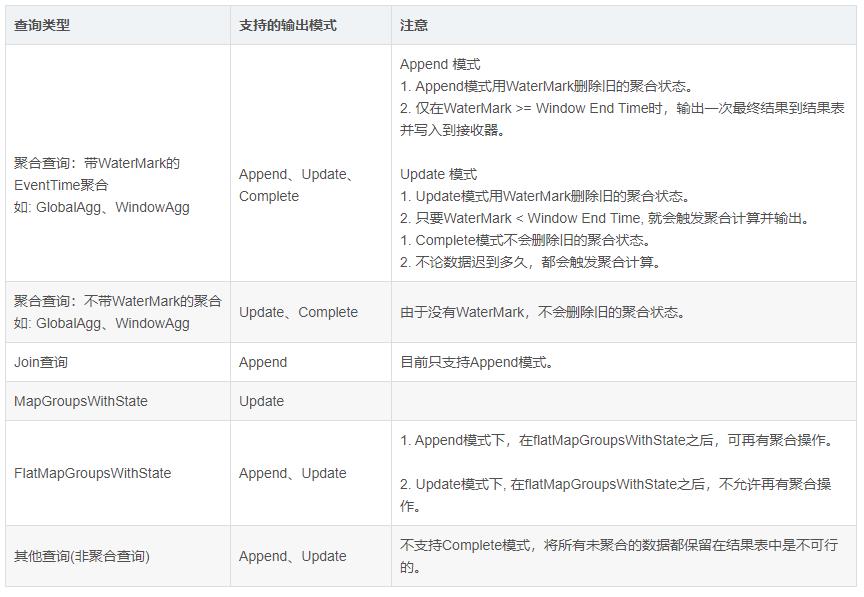
- 追加模式(Append mode),默认模式,其中只有自从上一次触发以来,添加到 Result Table的新行将会是outputted to the sink。只有添加到Result Table的行将永远不会改变那些查询才支持这一点。这种模式保证每行只能输出一次(假设 fault-tolerant sink )。例如,只有select,where, map, flatMap, filter, join等查询支持 Append mode 。只输出那些将来永远不可能再更新的数据,然后数据从内存移除 。没有聚合的时候,append和update一致;有聚合的时候,一定要有水印,才能使用。
- 完全模式(Complete mode),每次触发后,整个Result Table将被输出到sink,aggregationqueries(聚合查询)支持。全部输出,必须有聚合。
- 更新模式(Update mode),只有 Result Table rows 自上次触发后更新将被输出到 sink。与Complete模式不同,因为该模式只输出自上次触发器以来已经改变的行。如果查询不包含聚合,那么等同于Append模式。只输出更新数据(更新和新增)。
- 注意,不同查询Query,支持对应的输出模式,如下表所示:
2 查询名称
可以给每个查询Query设置名称Name,必须是唯一的,直接调用DataFrameWriter中queryName方法即可,实际生产开发建议设置名称,API说明如下:
3 触发间隔
触发器Trigger决定了多久执行一次查询并输出结果,当不设置时,默认只要有新数据,就立即执行查询Query,再进行输出。目前来说,支持三种触发间隔设置: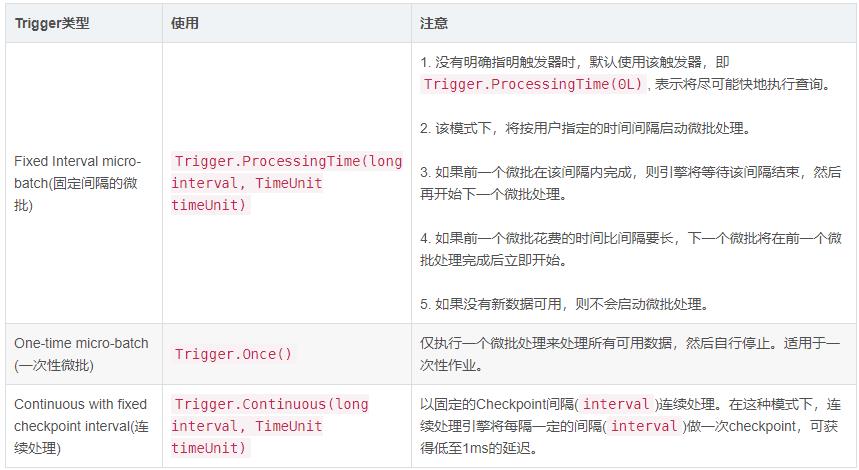
其中Trigger.Processing表示每隔多少时间触发执行一次,此时流式处理依然属于微批处理;从Spark 2.3以后,支持Continue Processing流式处理,设置触发间隔为Trigger.Continuous。设置
代码示例如下:
import org.apache.spark.sql.streaming.Trigger
// Default trigger (runs micro-batch as soon as it can)
df.writeStream
.format("console")
.start()
// ProcessingTime trigger with two-seconds micro-batch interval
df.writeStream
.format("console")
.trigger(Trigger.ProcessingTime("2 seconds"))
.start()
// One-time trigger
df.writeStream
.format("console")
.trigger(Trigger.Once())
.start()
// Continuous trigger with one-second checkpointing interval
df.writeStream
.format("console")
.trigger(Trigger.Continuous("1 second"))
.start()
4 检查点位置
在Structured Streaming中使用Checkpoint 检查点进行故障恢复。如果实时应用发生故障或
关机,可以恢复之前的查询的进度和状态,并从停止的地方继续执行,使用Checkpoint和预写日志
WAL完成。使用检查点位置配置查询,那么查询将所有进度信息(即每个触发器中处理的偏移范围)
和运行聚合(例如词频统计wordcount)保存到检查点位置。此检查点位置必须是HDFS兼容文件
系统中的路径,两种方式设置Checkpoint Location位置:
- 方式一:DataStreamWrite设置
- streamDF.writeStream.option(“checkpointLocation”, “xxx”)
- 方式二:SparkConf设置
- sparkConf.set(“spark.sql.streaming.checkpointLocation”, “xxx”)
修改上述词频统计案例程序,设置输出模式、查询名称、触发间隔及检查点位置,演示代码如下:
package cn.itcast.spark.output
import org.apache.spark.sql.streaming.{OutputMode,StreamingQuery,Trigger}
import org.apache.spark.sql.{DataFrame,SparkSession}
/**
* 使用Structured Streaming从TCP Socket实时读取数据,进行词频统计,将结果打印到控制台。
*/
object StructuredQueryOutput{
def main(args:Array[String]):Unit={
// 构建SparkSession实例对象
val spark:SparkSession=SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.config("spark.sql.shuffle.partitions","2")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
import org.apache.spark.sql.functions._
// 1. 从TCP Socket 读取数据
val inputStreamDF:DataFrame=spark.readStream
.format("socket")
.option("host","node1.itcast.cn")
.option("port",9999)
.load()
// 2. 业务分析:词频统计WordCount
val resultStreamDF:DataFrame=inputStreamDF
// 将DataFrame转换为Dataset进行操作
.as[String]
// 过滤数据
.filter(line=>null!=line&&line.trim.length>0)
// 分割单词
.flatMap(line=>line.trim.split("\\\\s+"))
// 按照单词分组,聚合
.groupBy($"value").count()
// 3. 设置Streaming应用输出及启动
val query:StreamingQuery=resultStreamDF.writeStream
// TODO: 输出模式Complete,表示将ResultTable中所有结果数据输出
.outputMode(OutputMode.Complete())
// TODO: 查询名称
.queryName("query-socket-wc")
// TODO:触发时间间隔
.trigger(Trigger.ProcessingTime("5 seconds"))
// TODO: 输出终端控制台console
.format("console")
.option("numRows","10")
.option("truncate","false")
.option("checkpointLocation","datas/structured/ckpt-1001") // TODO: 设置检查点目录
.start() // 启动start流式应用
query.awaitTermination() // 流式查询等待流式应用终止
query.stop() // 等待所有任务运行完成才停止运行
}
}
运行流式应用,查看Checkpoint Location,包含以下几个目录:
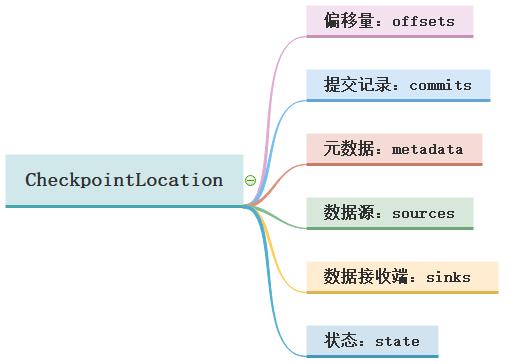
各个子目录及文件含义说明:
- 第一、偏移量目录【offsets】:记录每个批次中的偏移量。为了保证给定的批次始终包含相同的
数据,在处理数据前将其写入此日志记录。此日志中的第 N 条记录表示当前正在已处理,第
N-1 个条目指示哪些偏移已处理完成。 - 第二、提交记录目录【commits】:记录已完成的批次,重启任务检查完成的批次与 offsets 批
次记录比对,确定接下来运行的批次; - 第三、元数据文件【metadata】:metadata 与整个查询关联的元数据,目前仅保留当前job id
- 第四、数据源目录【sources】:sources 目录为数据源(Source)时各个批次读取详情
- 第五、数据接收端目录【sinks】:sinks 目录为数据接收端(Sink)时批次的写出详情
- 第六、记录状态目录【state】:当有状态操作时,如累加聚合、去重、最大最小等场景,这个
目录会被用来记录这些状态数据,根据配置周期性地生成.snapshot文件用于记录状态。
5 输出终端(Sinks)
Structured Streaming 非常显式地提出了输入(Source)、执行(StreamExecution)、输出(Sink)的3个组件,并且在每个组件显式地做到fault-tolerant(容错),由此得到整个streaming程序的end-to-end exactly-once guarantees。目前Structured Streaming内置FileSink、Console Sink、Foreach Sink(ForeachBatch Sink)、Memory Sink及Kafka Sink,其中测试最为方便的是Console Sink。
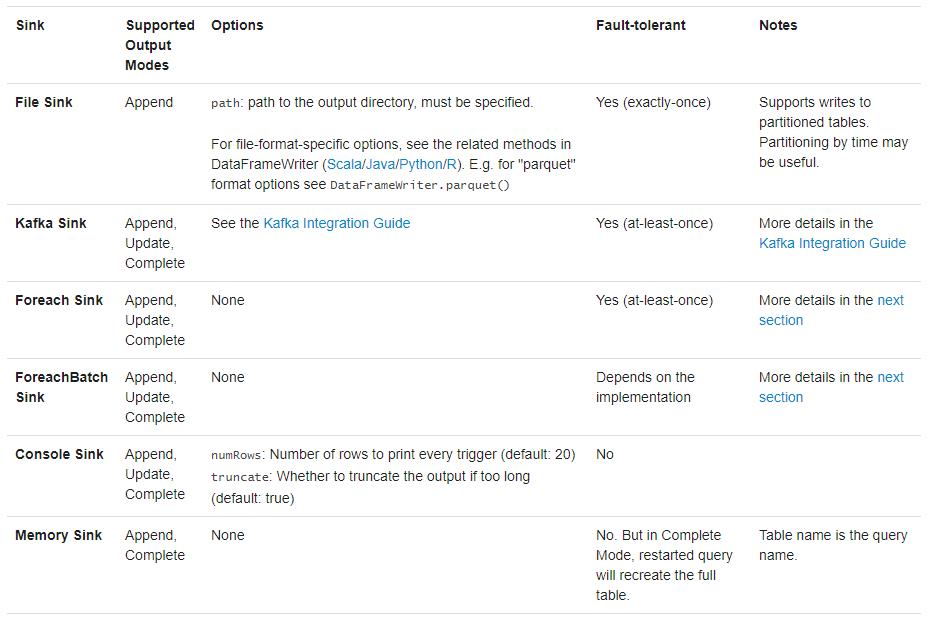
5.1 文件接收器
将输出存储到目录文件中,支持文件格式:parquet、orc、json、csv等,示例如下:
相关注意事项如下:
- 支持OutputMode为:Append追加模式;
- 必须指定输出目录参数【path】,必选参数,其中格式有parquet、orc、json、csv等等;
- 容灾恢复支持精确一次性语义exactly-once;
- 此外支持写入分区表,实际项目中常常按时间划分;
5.2 Memory Sink
此种接收器作为调试使用,输出作为内存表存储在内存中, 支持Append和Complete输出模式。这应该用于低数据量的调试目的,因为整个输出被收集并存储在驱动程序的内存中,因此,请谨慎使用,示例如下:
5.3 Foreach Sink
Structured Streaming提供接口foreach和foreachBatch,允许用户在流式查询的输出上应用任意操作和编写逻辑,比如输出到mysql表、Redis数据库等外部存系统。其中foreach允许每行自定义写入逻辑,foreachBatch允许在每个微批量的输出上进行任意操作和自定义逻辑,建议使用foreachBatch操作。
foreach表达自定义编写器逻辑具体来说,需要编写类class继承ForeachWriter,其中包含三个
方法来表达数据写入逻辑:打开,处理和关闭。
streamingDatasetOfString.writeStream.foreach(
new ForeachWriter[String] {
def open(partitionId: Long, version: Long): Boolean = {
// Open connection
}
def process(record: String): Unit = {
// Write string to connection
}
def close(errorOrNull: Throwable): Unit = {
// Close the connection
}
}
).start()
演示案例:将前面词频统计结果输出到MySQL表【tb_word_count】中。
- 第一步、数据库创建表,语句如下:
CREATE TABLE `db_spark`.`tb_word_count` (
`id` int NOT NULL AUTO_INCREMENT,
`word` varchar(255) NOT NULL,
`count` int NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `word` (`word`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
REPLACE INTO ` tb_word_count` (`id`, `word`, `count`) VALUES (NULL, ?, ?);
-- 当使用 REPLACE插入数据到表时:
/*
1)、所有字段
2)、表必须有主键
3)、要求唯一索引
*/
- 第二步、编写MySQLForeachWriter,继承ForeachWriter,其中DataFrame中数据类型为Row
import java.sql.{Connection,DriverManager,PreparedStatement}
import org.apache.spark.sql.{ForeachWriter,Row}
/**
* 创建类继承ForeachWriter,将数据写入到MySQL表中,泛型为:Row,针对DataFrame操作,每条数据类型就是Row
*/
class MySQLForeachWriter extends ForeachWriter[Row]{
// 定义变量
var conn:Connection=_
var pstmt:PreparedStatement=_
val insertSQL="REPLACE INTO `tb_word_count` (`id`, `word`, `count`) VALUES (NULL, ?, ?)"
// open connection
override def open(partitionId:Long,version:Long):Boolean={
// a. 加载驱动类
Class.forName("com.mysql.cj.jdbc.Driver")
// b. 获取连接
conn=DriverManager.getConnection(
"jdbc:mysql://node1.itcast.cn:3306/db_spark?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true", //
"root",
"123456"
)
// c. 获取PreparedStatement
pstmt=conn.prepareStatement(insertSQL)
//println(s"p-${partitionId}: ${conn}")
// 返回,表示获取连接成功
true
}
// write data to connection
override def process(row:Row):Unit={
// 设置参数
pstmt.setString(1,row.getAs[String]("value"))
pstmt.setLong(2,row.getAs[Long]("count"))
// 执行插入
pstmt.executeUpdate()
}
// close the connection
override def close(errorOrNull:Throwable):Unit={
if(null!=pstmt)pstmt.close()
if(null!=conn)conn.close()
}
}
- 第三步、修改词频统计程序,使用foreach设置Sink为自定义MySQLForeachWriter,代码如下:
import org.apache.spark.sql.streaming.{OutputMode,StreamingQuery}
import org.apache.spark.sql.{DataFrame,SparkSession}
/**
* 使用Structured Streaming从TCP Socket实时读取数据,进行词频统计,将结果存储到MySQL数据库表中
*/
object StructuredMySQLSink{
def main(args:Array[String]):Unit={
// 构建SparkSession实例对象
val spark:SparkSession=SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置Shuffle分区数目
.config("spark.sql.shuffle.partitions","2")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
// 1. 从Kafka读取数据,底层采用New Consumer API
val inputStreamDF:DataFrame=spark.readStream
.format("socket")
.option("host","node1.itcast.cn")
.option("port",9999)
.load()
// 2. 业务分析:词频统计WordCount
val resultStreamDF:DataFrame=inputStreamDF
// 转换为Dataset类型
.as[String]
// 过滤数据
.filter(line=>null!=line&&line.trim.length>0)
// 分割单词
.flatMap(line=>line.trim.split("\\\\s+"))
// 按照单词分组,聚合
.groupBy($"value").count()
// 设置Streaming应用输出及启动
val query:StreamingQuery=resultStreamDF.writeStream
// 对流式应用输出来说,设置输出模式,Update表示有数据更新才输出,没数据更新不输出
.outputMode(OutputMode.Update())
// TODO: def foreach(writer: ForeachWriter[T]): DataStreamWriter[T]
.foreach(new MySQLForeachWriter())
.start() // 启动start流式应用
// 查询器等待流式应用终止
query.awaitTermination()
query.stop() // 等待所有任务运行完成才停止运行
}
}
运行应用,模式数据,查看MySQL表的结果数据如下: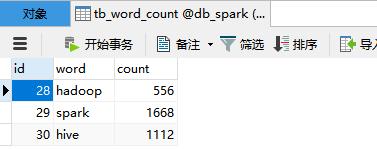
5.4 ForeachBatch Sink
方法foreachBatch允许指定在流式查询的每个微批次的输出数据上执行的函数,需要两个参数:微批次的输出数据DataFrame或Dataset、微批次的唯一ID。

使用foreachBatch函数输出时,以下几个注意事项:
- 第一、重用现有的批处理数据源,可以在每个微批次的输出上使用批处理数据输出Output;
- 第二、写入多个位置,如果要将流式查询的输出写入多个位置,则可以简单地多次写入输出
DataFrame/Dataset 。但是,每次写入尝试都会导致重新计算输出数据(包括可能重新读取输入数据)。要避免重新计算,您应该缓存cache输出 DataFrame/Dataset,将其写入多个位置,然后 uncache 。

- 第三、应用其他DataFrame操作,流式DataFrame中不支持许多DataFrame和Dataset操作,使用foreachBatch可以在每个微批输出上应用其中一些操作,但是,必须自己解释执行该操作的端到端语义。
- 第四、默认情况下,foreachBatch仅提供至少一次写保证。 但是,可以使用提供给该函数的batchId作为重复数据删除输出并获得一次性保证的方法。
- 第五、foreachBatch不适用于连续处理模式,因为它从根本上依赖于流式查询的微批量执行。 如果以连续模式写入数据,请改用foreach。
- 范例演示:使用foreachBatch将词频统计结果输出到MySQL表中,代码如下:
package cn.itcast.spark.sink.batch
import org.apache.spark.sql.streaming.{OutputMode,StreamingQuery}
import org.apache.spark.sql.{DataFrame,SaveMode,SparkSession}
/**
* 使用Structured Streaming从TCP Socket实时读取数据,进行词频统计,将结果存储到MySQL数据库表中
*/
object StructuredForeachBatch{
def main(args:Array[String]):Unit={
// 构建SparkSession实例对象
val spark:SparkSession=SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.config("spark.sql.shuffle.partitions","2")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
// 1. 从Kafka读取数据,底层采用New Consumer API
val inputStreamDF:DataFrame=spark.readStream
.format("socket")
.option("host","node1.itcast.cn")
.option("port",9999)
.load()
// 2. 业务分析:词频统计WordCount
val resultStreamDF:DataFrame=inputStreamDF
// 转换为Dataset类型
.as[String]
// 过滤数据
.filter(line=>null!=line&&line.trim.length>0)
// 分割单词
.flatMap(line=>line.trim.split("\\\\s+"))
// 按照单词分组,聚合
.groupBy($"value").count()
// 设置Streaming应用输出及启动
val query:StreamingQuery=resultStreamDF.writeStream
// 对流式应用输出来说,设置输出模式,Update表示有数据更新才输出,没数据更新不输出
.outputMode(OutputMode.Complete())
// TODO: def foreachBatch(function: (Dataset[T], Long) => Unit): DataStreamWriter[T]
.foreachBatch{(batchDF:DataFrame,batchId:Long)=>
println(s"BatchId = ${batchId}")
if(!batchDF.isEmpty){
// TODO:降低分区数目,保存数据至MySQL表
batchDF
.coalesce(1)
.write
.mode(SaveMode.Overwrite)
.format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url","jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&charact
erEncoding=utf8&useUnicode=true")
.option("user","root")
.option("password","123456")
.option("dbtable","db_spark.tb_word_count2")
.save()
}
}
.start() // 启动start流式应用
// 查询器等待流式应用终止
query.awaitTermination()
query.stop() // 等待所有任务运行完成才停止运行
}
}
6 容错语义
针对任何流式应用处理框架(Storm、SparkStreaming、StructuredStreaming和Flink等)处理数据时,都要考虑语义,任意流式系统处理流式数据三个步骤:
- 1)、Receiving the data:接收数据源端的数据
- 采用接收器或其他方式从数据源接收数据(The data is received from sources usingReceivers or otherwise)。
- 2)、Transforming the data:转换数据,进行处理
以上是关于大数据Spark Streaming Queries的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据Spark(五十二):Structured Streaming 事件时间窗口分析
走进大数据丨Spark Streaming VS Flink