记线上 Jackson 使用不当引发的血案
Posted JasonLee-后厂村程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记线上 Jackson 使用不当引发的血案相关的知识,希望对你有一定的参考价值。
背景
最近业务方反馈线上一个 topic 的数据延迟比较大,然后我查看了这个 topic 的数据是由一个 Flink 任务产生的,于是就找到了这个任务开始排查问题,发现这个任务是一个非常简单的任务,大致的逻辑是 kafka source -> flatmap -> filter -> map -> sink kafka.中间没有复杂的操作,我在本地写了一个简单的程序模拟线上的任务.方便大家理解, 任务的 DAG 如下图所示
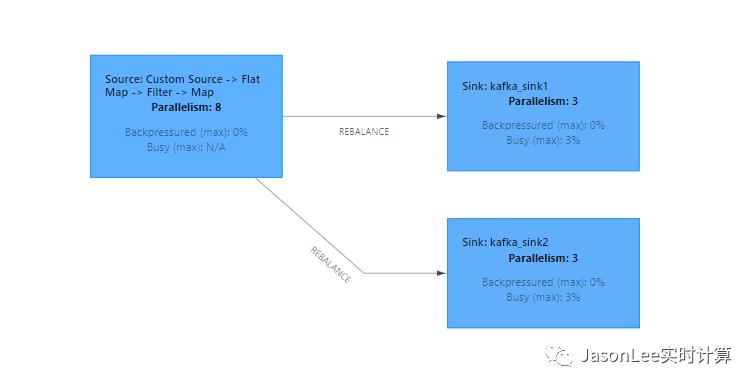
线上任务 source 的并行度设置的是 80 flatmap filter map 的并行度也是 80 所以和 source 都 chain 在一起,两个 sink 的并行度设置的都是 30,我这里本地就设置成 8 和 3 了.
排查过程
因为反馈说是下游 topic 的数据有延迟,我的第一反应是看任务是否有反压,通过 Flink 的 UI 上的 BackPressure 发现任务并没有反压,然后查看了第一个 operator 输入数据量的 QPS 大概是 50w/s 经过 filter 之后输出数据量的 QPS 是 15w/s 左右,然后查看了 kafka 的监控发现写入的 QPS 也是 15w/s ,这就说明确实不是因为写入 kafka 慢引起的反压,因为你产生了多少我就写入了多少,但是最终的数据有延迟,那就说明任务反压的地方是在第一个 operator 中的某个算子上,但是因为 operator chain 把所有的算子都 chain 在一起,不太方便定位反压的位置.于是我就在 flatmap 后面调用 disableChaining 打断了 operator chain.这个时候任务的 DAG 变成了下面这样.
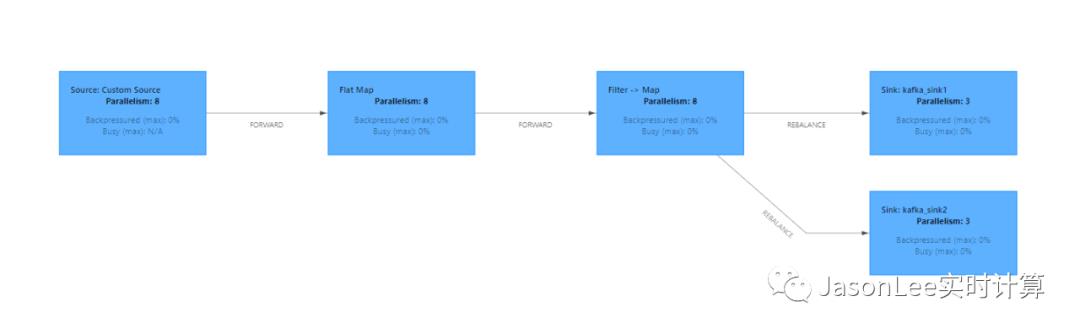
这个时候在查看 source 的 BackPressure 显示都是 high 状态,说明反压出现在 flatmap 算子,刚开始猜测可能是因为 flatmap 的时候数据量会暴增导致处理不过来了,所以就尝试增大了 flatmap 算子的并行度,但是发现并没有明显的效果,任务反压还是比较严重,哪怕是增大并行度到 500 效果都不是很明显,这就说明跟 flatmap 的数据量大小及并行度没有关系,没办法只能看代码了,大概看了下任务逻辑,代码非常简单,不应该会出现性能问题,唯一不足的就是代码逻辑不够简洁,略显繁琐,且有重复的逻辑,其实 filter 和 map 算子是没有必要的,优化了这些地方之后本以为就能解决反压问题,可是结果还是出现了反压.
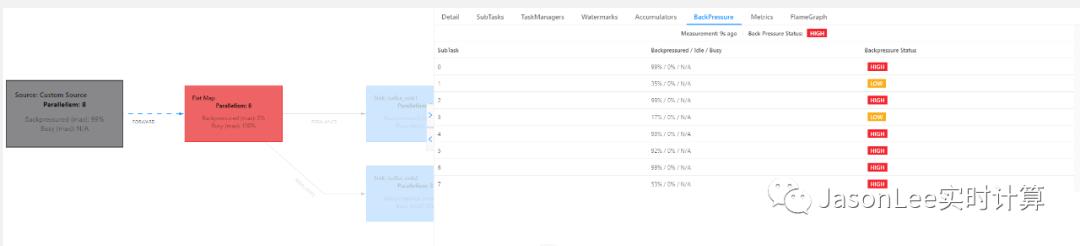
这就有点奇怪了,代码中没有复杂的逻辑,也没有和第三方交互,按道理来说不应该会有性能问题,再次查看代码发现代码里面解析 JSON 数据用的是 Jackson 类库,Jackson 的稳定性和性能肯定是没有问题的,在国外应用比较广泛,比如 springboot 包括 Flink 这种大型的框架内默认都使用 Jackson 更加能说明这一点,国内使用 Fastjson 类库会比较多一点.然后仔细看代码发现使用 Jackson 的时候需要实例化 ObjectMapper 对象,但是代码里面是在 flatmap 方法里面实例化 ObjectMapper 对象的,也就是说每来一条数据都需要实例化一次 ObjectMapper 对象,这显然是不合理的.刚开始没有发现是因为解析 json 被封装在一个方法里面,没有进到方法里面来看,那么究竟是不是因为 ObjectMapper 实例化影响到性能呢? 其实非常简单,我们可以在本地测试一下提前实例化好 ObjectMapper 和每条数据都实例化一遍的差别就能得到答案.测试代码如下
public static long a(String json) throws IOException {
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i ++) {
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.readValue(json, List.class);
}
long end = System.currentTimeMillis();
return end - start;
}
public static long b(String json) throws IOException {
long start = System.currentTimeMillis();
ObjectMapper objectMapper = new ObjectMapper();
for (int i = 0; i < 100000; i ++) {
objectMapper.readValue(json, List.class);
}
long end = System.currentTimeMillis();
return end - start;
}
String json = "[{\\"name\\":\\"JasonLee\\",\\"age\\":18},{\\"name\\":\\"JasonLee1\\",\\"age\\":18}]";
System.out.println(a(json));
System.out.println(b(json));
// 打印的结果是:
68425
316
从上面测试的结果可以发现,这两种写法性能相差甚大,耗时完全不在一个量级上,也就是说 jackson 的 ObjectMapper 实例化是一个非常耗时的过程,这就能解释任务为什么会在 flatmap 算子出现反压了.
解决
既然知道了反压的原因,那解决办法就非常的简单了,把 ObjectMapper 对象的实例化放在 open 方法里面即可,类似于创建 JDBC 连接,让每个 task 初始化一次 ObjectMapper 对象,然后在 flatmap 方法里面直接使用.这样就不用每条数据都初始化一次.
SingleOutputStreamOperator<JasonEntity> filter = jasonEntityDataStreamSource.flatMap(new RichFlatMapFunction<JasonEntity, JasonEntity>() {
private ObjectMapper objectMapper = null;
@Override
public void open(Configuration parameters) throws Exception {
objectMapper = new ObjectMapper();
}
@Override
public void flatMap(JasonEntity jasonEntity, Collector<JasonEntity> collector) throws Exception {
List<Map<String, String>> list = objectMapper.readValue("[\\n" +
" {\\"name\\":\\"JasonLee\\",\\"age\\":18},\\n" +
" {\\"name\\":\\"JasonLee1\\",\\"age\\":18}\\n" +
"]", List.class);
System.out.println(list.toString());
collector.collect(jasonEntity);
}
}).disableChaining();
当然除了改成上面的写法外,还可以直接用 fastjson 来解析 JSON 数据,jackson 和 fastjson 的性能是差不多的,网上也有很多这两者对比的文章,感兴趣的也可以自己测试一下.这里就不做对比测试了.
最后把修改后的代码提交到线上后发现没有出现反压,下游的数据自然也不会有延迟了.其实这是一个非常小的问题,或者说是一个小细节吧,但是却能带来严重的后果.所以我们在写代码的时候还是要多注意细节,尽可能提高程序的性能.
推荐阅读
如果你觉得文章对你有帮助,麻烦点一下赞和在看吧,你的支持是我创作的最大动力.
以上是关于记线上 Jackson 使用不当引发的血案的主要内容,如果未能解决你的问题,请参考以下文章