测开之数据类型进阶篇・第二篇《字典和集合的原理应用》
Posted 七月的小尾巴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了测开之数据类型进阶篇・第二篇《字典和集合的原理应用》相关的知识,希望对你有一定的参考价值。
目录
集合
什么是集合?
在开始之前,我们首先来看一下,什么是字典,什么是集合?字典和集合有什么区别?
# 集合
test_1 = {1, 1, 1, 1, 1, 2}
# 字典
test_2 = {"name": "Viki", "age": 18}
从上方代码中我们可以看出,字典是通过键值对的形式展示的,而集合的特点就是只有值,没有键。
定义空集合
# 定义空集合
test_1 = set()
# 定义空字典
test_2 = {}
有很多朋友在开始都会有一个误区,因为字典和集合都是用花括号包起来的,因此大家会以为 test_2 = {}就相当于定了一个空的集合,但是其实不是的,下面我们来看一下 test_2 的数据类型
test_2 = {}
print(type(test_2))
结果:
<class 'dict'>
Process finished with exit code 0
上方可以看出,这是一个字典类型
集合的特点 - 自动去重
集合有个比较强大的功能:自动去重。 里面不会存在重复的元素,集合最常见的应用就是对列表去重。
test_2 = {1, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3}
print(test_2)
结果:
{1, 2, 3}
Process finished with exit code 0
上方我们可以看到集合中存在多个重复元素,但是打印出结果是重复的元素会被自动过滤。
那么在平时开发过程中,最常见的就是用集合对列表去重。我们来看一下实现方式:
li = [1,1,1,2,2,2,3,3,3] # 利用集合对列表去重
li2 = list(set(li))
首先把列表转换成一个集合,自动把里面的重复元素给去除掉了,再转换回列表。
集合常用的方法
| 方法名 | 方法作用域 |
|---|---|
add() | 添加元素 |
update() | 更新元素 |
remove() | 删除元素 |
clear() | 清空集合中的所有元素 |
copy() | 复制元素 |
集合它里面的元素是无序的。可以修改,集合是可变类型的数据。
Python 里面把它称作散列类型。
Python 更新到 3.7 之后,字典出现一个新的特性:3.7 之前的字典是无序的。3.7 之后字典中元素的顺序,它会按你依次添加的顺序进行保存。现在字典,里面的元素实际上是有序的。
空集合添加元素 add()
add() 方法,每次可以往里面添加一个数据进去。
se = set() # 空集合
# 集合添加数据
se.add('tom') # 一次只能添加一个,所以只添加了一个tom
print(se)
结果:
{'tom'}
Process finished with exit code 0
删除集合元素 remove()
集合可以添加也可以删除。删除用remove(),传入对应的元素就可以进行删除。
test = {"tom", "lili"}
# 删除 "tom"
test.remove("tom")
print(test)
结果:
{'lili'}
Process finished with exit code 0
更新元素 update()
跟字典的update()一样的。 它是将一个集合更新到这个集合里面,可以往里面一次加入多个元素。
se = set() # 空集合
se.update({111,22,33,44})
print(se)
下面我们可以 update 的底层源码,接收的是不定量参数,可以传一个也可以传多个。
可以往里面加元组、列表、字符串,但是一般用的时候选择用集合,将一个集合更新到原来的集合里面。
def update(self, *args, **kwargs): # real signature unknown
""" Update a set with the union of itself and others. """
pass
清空集合元素 clear()
test = {"tom", "lily"}
test.clear()
print(test)
结果:
set()
Process finished with exit code 0
清空之后,我们可以看到,返回了一个空集合
复制元素copy()
test = {"tom", "lily"}
print(test)
test2 = test.copy()
print(test2)
返回:
{'lily', 'tom'}
{'lily', 'tom'}
Process finished with exit code 0
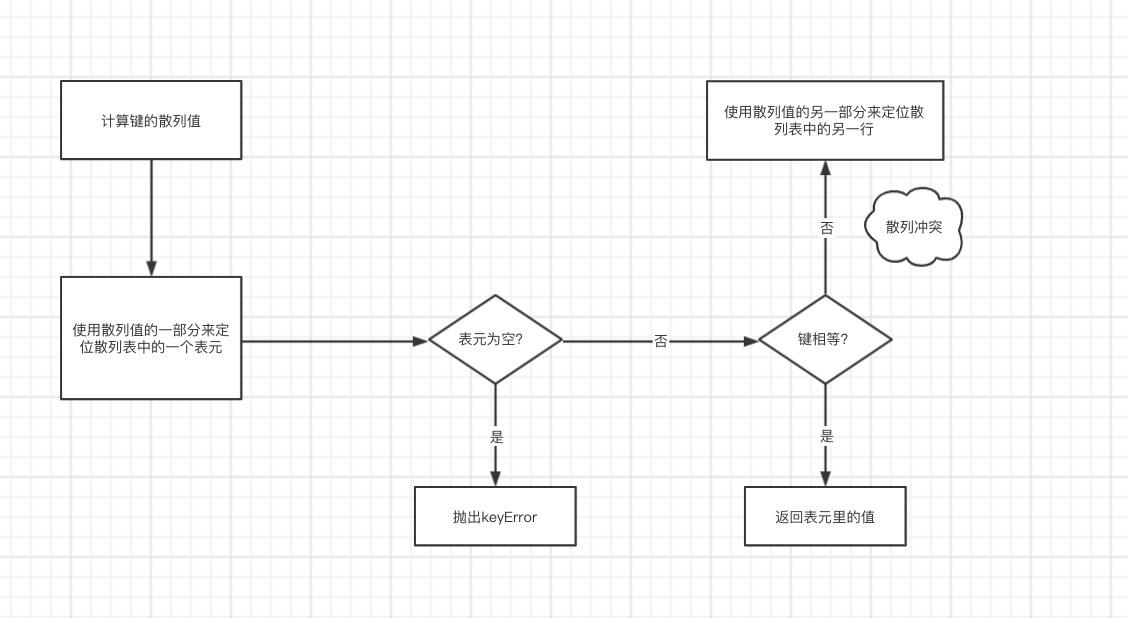
字典和集合的存储原理
dict 与 set 实现原理是一样的,都是将实际的值放到 list 中。
唯一不同的在于 hash 函数操作的对象,对于 dict,hash 函数操作的是其 key,而对于 set 是直接操作的它的元素。
假设操作内容为 x,其作为因变量,放入 hash 函数,通过运算后取 list 的余数,转化为一个 list 的下标,此下标位置对于 set 而言用来放其本身。
而对于 dict 则是创建了两个 list,一个 list 该下表放此 key,另一个 list 中该下标对应的 value。
其中,我们把实现 set 的方式叫做 Hash Set,实现 dict 的方式叫做 Hash Map/Table(注:map 指的是通过 Key 来寻找 value 的过程)。
字典和集合底层都是存储再列表里面的
我们定义一个字典,在存储的时候,会拆分成 2 部分,会存在 2 个列表里面,一个列表存键,一个列表存值。
怎么通过 Key 找到对应的 Value 值呢?
字典在存储之前,做了个 Hash 操作:
拿到字典的键,进行哈希操作。通过对应的哈希算法,然后得出一串数字。
拿哈希出来的值除以内存分出来的列表的长度,得到余数。这个余数当成对应元素的下标。把键和值通过下标存在列表中对应的位置。
下面这张图是字典找值的过程
关于集合、字典、元祖、列表性能分析
从时间上比较:集合 --> 字典 --> 元祖 --> 列表
从占用内存上比较:字典 --> 集合 --> 列表 --> 元祖
以上是关于测开之数据类型进阶篇・第二篇《字典和集合的原理应用》的主要内容,如果未能解决你的问题,请参考以下文章