表示学习总结
Posted Coding With you.....
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了表示学习总结相关的知识,希望对你有一定的参考价值。
知识图谱 发展规律
| 本周主要找了一些表示学习、信息提取和图谱的文章,了解了下Trans系列的表示学习模型;然后看了那篇论文,使用层次结构描述学科中的演化规律,里面主要通过分析不同研究之间的相互作用为出发点进行创新---不同主题之间的权重以及时间演化。我就在想如果对于这种发展规律的话 用图谱的意义是什么。就是要融合与推理,而且数据规模大,图谱的语义相对比较丰富。之后也查了国内不同领域一些热点与发展趋势的研究,大多数是基于供词分析、聚类等方法进行考虑的。其实和之前合作网络那些的分析差不多,共现 共被引 聚类 词频。。。就是算法以及分析不同了,比如那篇多层生成树就是在,,,, 因为图谱他对于概念和对象是有一定标准的在不同领域。 然后我下周计划看一下表示学习这块的论文并且结合代码进行理解,时序与演化知识图谱的综述。 明天:再看一遍徐老师发的论文,看刘志远老师书 之后借书看看; 蓝色背景是将要做的 |
目录
1.Knowledge Graph Embedding: A Survey of Approaches and Applications
、2.Heterogeneous Supervision for Relation Extraction: A Representation Learning Approach
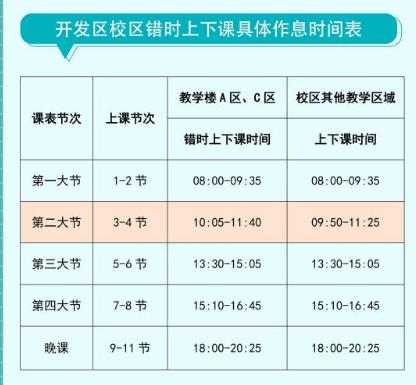
编译技术这门课程综合性比较强,涉及数据结构、离散数学、程序设计、操作系统等课程的相关知识,因此将这些课程综合应用加实践操作。提高自身知识,增强社会历练,锻炼自我,通过这个经历可以提升自己的综合能力,使得研究生期间的生活更加充实。因此希望拥有一次锻炼的机会,我会全力以赴,尽自己所能协助老师做好助教工作;在工作中遵守学校各种规章制度;根据安排完成批改作业、指导实验等任务,以高度的责任心及时完成指派的各项任务。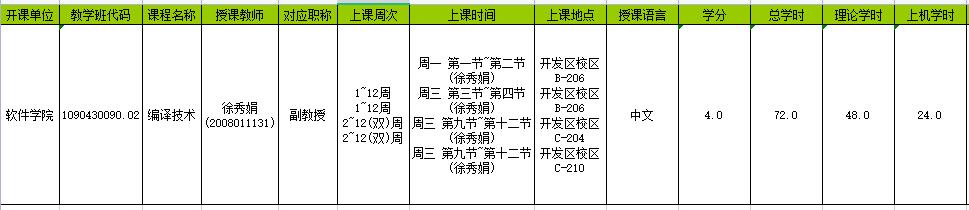
为什么要用图谱?意义是什么------语义复杂、时空信息
知识图谱容易融合、支持推理、有很强的解释性、支持大规模、语义信息丰富。而语义网络是比较简单、直白符合人的思维但没有具体的标准,无法区分概念与对象
知识图谱系统的生命周期包含四个重要环节:知识表示、知识获取、知识管理与知识应用。这四个环节循环迭代。
主要的技术是要实现下面几部分:
对于科学知识图谱的热点发展规律研究,首先要明白这其中三个大概念。
科学知识图谱以科学知识为计量研究对象,绘制与挖掘知识之间的相互关系,用可视化的形式揭示知识的活动规律
关键词时间线聚类知识图谱-----热点及发展规律
基于已经有的应用,可以看到直接可视化出时间的发展规律。目前时序的知识图谱也是非常有必要研究的。时序时间嵌入方法通过将常见的形式为(h,r,t)的三元组扩展为(h,r,t,τ)的时序四元组,可以在时间感知嵌入中考虑时间信息,其中τ提供有关何时事实能够成立的额外时间信息;动态实体通过RNN进行动态演化;时间关系的依存根据时间线,关系链条中存在时序依存的特性,例如,wasBornIn →graduateFrom → workAt → diedIn这样一个关系链条,其中的关系由于存在时序依存约束所以需要满足一定的先后顺序。下面是一些资源:
时序知识图谱补全综述:
https://github.com/woojeongjin/dynamic-KG
时序与演化知识图谱综述:
https://github.com/shengyp/Temporal-and-Evolving-KG
HyTE:
https://github.com/malllabiisc/HyTE
Know-Evolve
https://github.com/rstriv/Know-Evolve
RENET:
https://github.com/INK-USC/RE-Net
好的知识图谱:斯坦福知识图谱课程https://www.bilibili.com/video/BV12
- 便于更新:当实例发生变化或有新的实例添加进来,本体模型都是可用的,这样可以减少维护成本。
- 人类可读文档:包括可读的术语,关系,标签等用来表示本体。
- 严格的定义:经过严格定义后的本体模型能够减少歧义性。
知识图谱嵌入:知识图谱嵌入是将知识图谱中的实体和关系转换为数值化的表示,可以看成一个基础任务,学习出的嵌入表示可以用于各种和知识图谱相关的任务,
一 理解
1.表示学习是什么
--------------------可以说是自然语言处理中最底层的词汇处理,对词进行编码--可以有不同的编码方式(也就是一个数据可以有不同的表示方式)
在我们的意识中,是怎么理解句子的呢,基于语法?语义?上下文?如何将这个句子叫机器理解呢?
模型层面+学习层面:就是设计一个模型,去组合这些局部、全局的语义,然后进行模型的训练学习
表示学习是自然语言处理中一个核心的任务,是语言的形式化表示,便于计算机识别与理解。主要是将以前人工提取数据中特征的过程转变为自己从数据中学习并表示的过程。
其核心是分布式表示,这个分布式的理解是可以将一个对象使用低维的稠密的向量进行表示,这样也表达出了不同向量之间的联系。这里很重要,有必要举个例子进行理解。比如现在有一个句子包含10个单词,用传统的方法我们可以将这10个词表示为10维向量(one-hot),这样每个词只有一维为1其余维为0,不同向量之间是稀疏的、离散的,没有上下文关系。采用表示学习进行表示,就可以进行稠密维度的表示,10个词可以用2进制下4位来表示,因此这10个词用4维就可以表示,每一个是稠密向量,如果第一个词为0,0,0,0第二个词为0,0,0,1 那么这两个词之间是有相似部分的 也就是有上下文联系的。这个就是分布式
2.可以应用在哪些方面
相似度计算:对词和词之间进行语义表示
知识图谱补全:可以根据实体与关系的语义表示,进行预测两个实体之间的关系
3.具体的应用例子
比如输入一个句子,通过双通道CNN对其进行表示,然后通过pooling机制解决不同文本变长的问题,在解码时加入注意力机制提升整个模型的性能
还有就是基于门机制进行表示,如下图中,黑色是活跃神经元,空心是抑制神经元,边表示消息传递,实线边表示接受消息上传,虚线边表示拒绝,通过这样的过程可以得到整个句子的树结构,从而得到整个句子的表示
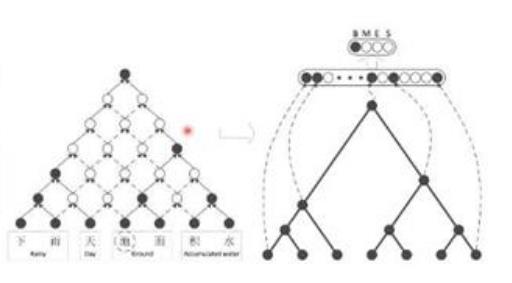
二 综述
1.Knowledge Graph Embedding: A Survey of Approaches and Applications
知识表示模型:------核心部分是打分函数
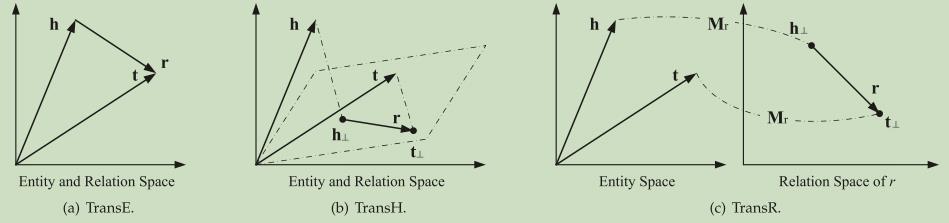
TransE
是知识图谱表示学习的开山之作,就是将模型翻译成低维向量空间中头实体到尾实体的翻译工作
这部分更加详尽的理解可以看论文和代码
序号 属性 值
1 模型名称 TransE
2 所属领域 自然语言处理
3 研究内容 知识表示
4 核心内容 knowledge embedding
5 GitHub源码 https://github.com/thunlp/KB2E
6 论文PDF http://www.thespermwhale.com/jaseweston/papers/CR_paper_nips13.pdf)
将关系看做从头实体到尾实体的翻译,如果(head,relation,tail)存在,那么 h + r ≈ t ,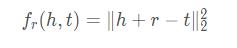
TransE却无法解决一对多,多对多的问题,因此通过TransH解决:通过关系r 的法向量w r
建立一个关系平面,然后将实体h 和实体t 映射到该平面,分别得到h ⊥ 和t ⊥ t,然后就是和TransE一样的公式来最小化目标函数:使得h⊥+dr与t⊥接近
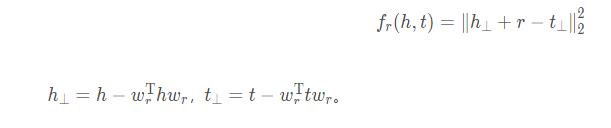
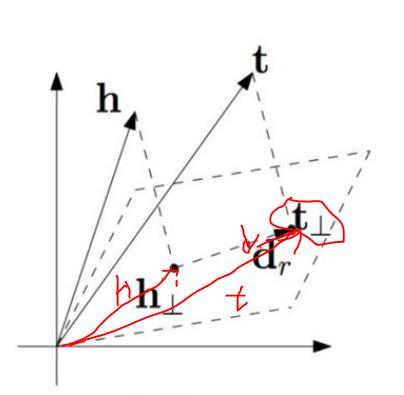
TransH实体和关系都嵌入在同一空间内,但一个实体具有多个“方面”,因此有多个关系。有些实体相似,所以在实体空间内相近;在某些特定方面实体之间有差别,所以在相应的关系空间中相距较远。为了解决这个问题,我们让TransR在两个不同的空间,即实体空间和多个关系空间(关系特定的实体空间)中建模实体和关系,并在对应的关系空间中进行转换.
TransR的基本思想是,对于每个三元组(h, r, t),将实体空间中的实体通过矩阵Mr投影到r关系空间中,分别为hr和tr,然后有hr + r ≈ tr,损失函数和训练方法与TransE相同。h和t为实体嵌入,r为关系嵌入。
基于TransR的不足,
- 首先,head和tail使用相同的转换矩阵将自己投射到超平面上,但是head和tail通常是一个不同的实体,例如,
(Bill Gates, founder, Microsoft)。'Bill Gate'是一个人,'Microsoft'是一个公司,这是两个不同的类别。所以他们应该以不同的方式进行转换。 - 第二,这个投影与实体和关系有关,但投影矩阵仅由关系决定。
- 最后,TransR的参数数大于TransE和TransH。由于其复杂性,TransR/CTransR难以应用于大规模知识图谱。
后面也有TransD、TransM、TransF、TransA、RotatE等等。
知识图谱嵌入的模型分类:基于翻译的Trans系列、基于张量分解的DisMulu/HoIE、基于神经网络的ConvKB、基于图神经网络的KGAT/KBAT等。
、2.Heterogeneous Supervision for Relation Extraction: A Representation Learning Approach
使用来自异构信息源的注释进行关系提取器学习
将提取的文本特征嵌入低维向量,通过和关系提及之间的关系计算关系提及的向量,之后提取真实的标签。
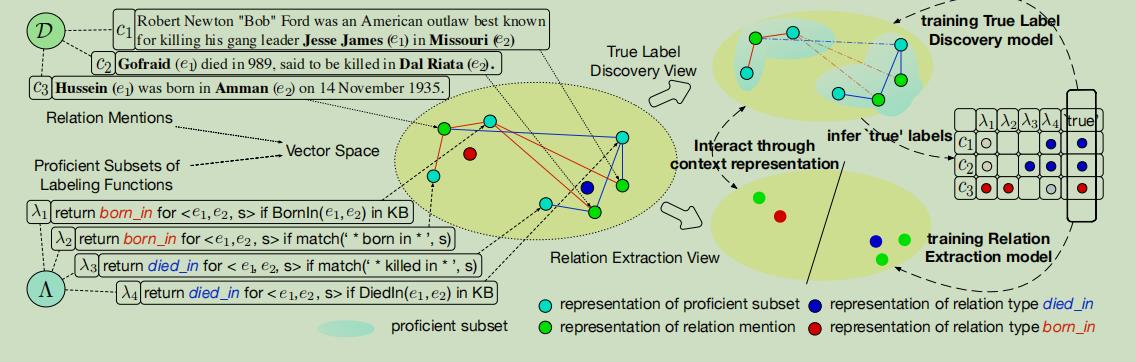
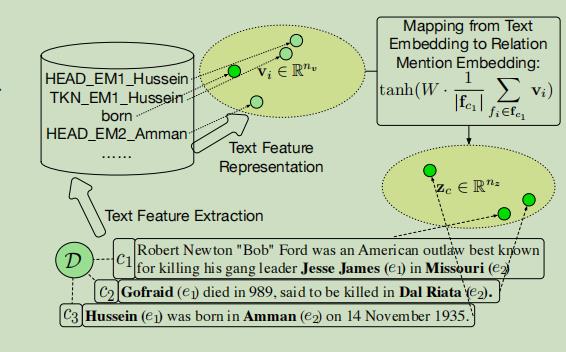
因为考虑到文本特征嵌入和关系类型有不同的
3.[徐老师推荐] Understanding Hierarchical Structural Evolution in a Scientifific Discipline: A Case Study of Artifificial Intelligence
本篇文章使用层次结构描述学科中的演化规律,通过分析不同研究之间的相互作用为出发点进行创新
如图,随着时间的变化,主题、不同主题之间的影响也是变化的
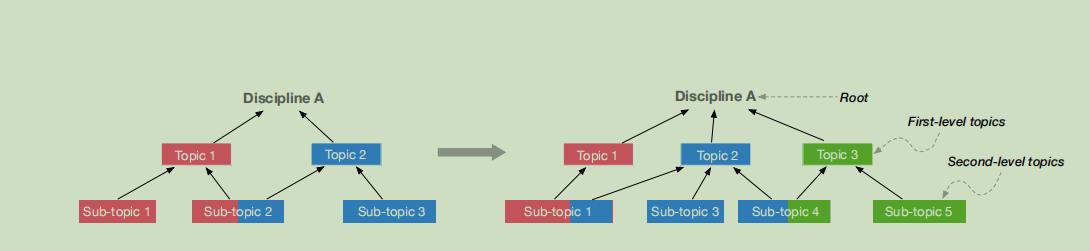
主要的创新是:父子主题之间的权重问题【采用非负矩阵分解】以及层次主题的生命周期【可视化分析方法】 相关工作:A 主题演化模型+ B 主题演化可视化
A:
- 我们的方法推断了子主题和父主题之间的成员权重,这为进化模式的分析开辟了一系列的见解。
- 生成的主题树中的一个子主题可以有多个具有不同成员权重的父主题,这允许对主题的知识结构进行健壮的探索。
- 该方法会自动过滤不重要的主题,它保留了主题树中的大规模结构,同时掩盖了不重要的细节
B:在我们的主题模型中,父主题和子主题之间有一个权重,因此,不可能直接使用传统的可视化方法来检查这个主题树。我们提出了堆叠图的一个变体,其中一个主题用一个块而不是一条河流表示。这样,成员的权重可以通过每个块中的颜色宽度来识别,块之间的直线颜色可以表示相邻时间段内主题之间关系的强度。
通过图进行查看趋势的发展。对于数据要删除频次低于5的然后剩余7000多个进行主题聚类,在分析整个领域的发展趋势中可以对每年的发文总量进行可是化分析,对于热点可以进行词频、每年该词占所有词的比例等等进行研究
总结
以上是关于表示学习总结的主要内容,如果未能解决你的问题,请参考以下文章