聊聊数据仓库建设
Posted zhisheng_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊数据仓库建设相关的知识,希望对你有一定的参考价值。
数据仓库是一个面向主题的、集成的、随时间变化的、但信息本身相对稳定的数据集合,用于对管理决策过程的支持。
数仓建设思路
数仓主要是围绕着数据使用方与数据开发方诉求进行建设;因此在开始规划数仓建设时,需要先剖析各方需求、痛点与痒点,然后再在这些诉求设计解决方案与确定建设内容。数据使用方主要诉求是能不能快速找到、找到怎么用、有哪些数据,在使用数据时,主要存在三大类问题:
找不到,不知道数据有没有、在哪里。
看不懂,有很多业务方不是技术研发团队的,看不懂数据到底什么含义、怎么关联查询、来源于哪个业务系统。
不会用,如何写 SQL 或者哪些产品里面能查询到自己想要的数据指标。
因此针对数据使用方,在数仓建设过程中需要满足:找得到、看得懂、用得对数据开发工程师更多是关注数据开发便利性、高效性与快速定位问题,因此数据开发方主要是以下几点诉求:
数据复用:数据需求烟囱式开发,导致了大量重复逻辑代码的研发,通过数据复用可以缩短数据需求交付,提高数据开发效率,满足业务对数据的敏捷研发要求。
问题追踪:在数据处理过程与数据质量分析过程可以快速定位问题源头。
影响分析:可以快速高效对数据规则修改或数据上下架影响进行分析。
数仓建设内容
明确数仓建设目标之后,主要是从以下几个方面搭建数仓能力:
分层架构:分层架构可以简化数据清洗的过程、为数据与模型可复用提供基础。
主数据管理:通过主数据打通各业务链条,统一数据语言,统一数据标准,实现数据共享。
指标体系:指标体系就是将各个指标按照特定的框架组织起来,从而统一指标名称及口径定义,理清指标间构成关系,避免重复建设
词根管理:通过词根可以用来规范表名、字段名、主题域名等等。
数据血缘:数据溯源、数据价值与质量评估。
分层架构
通过数据分层管理可以更好组织、管理与维护数仓数据,简化数据开发工作,每一层的处理逻辑相对简单与容易理解,也比较容易保证每一个步骤的正确性,从而简化数据清洗的过程。分层是在利用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。通过数据分层为数据与模型可复用提供基础,很多数据质量问题是因为我们数据与模型无法复用导致业务口径与技术口径无法统一;新的需求,都从原始数据重新计算,从而衍生出很多数据质量问题。数仓分层一般如下:
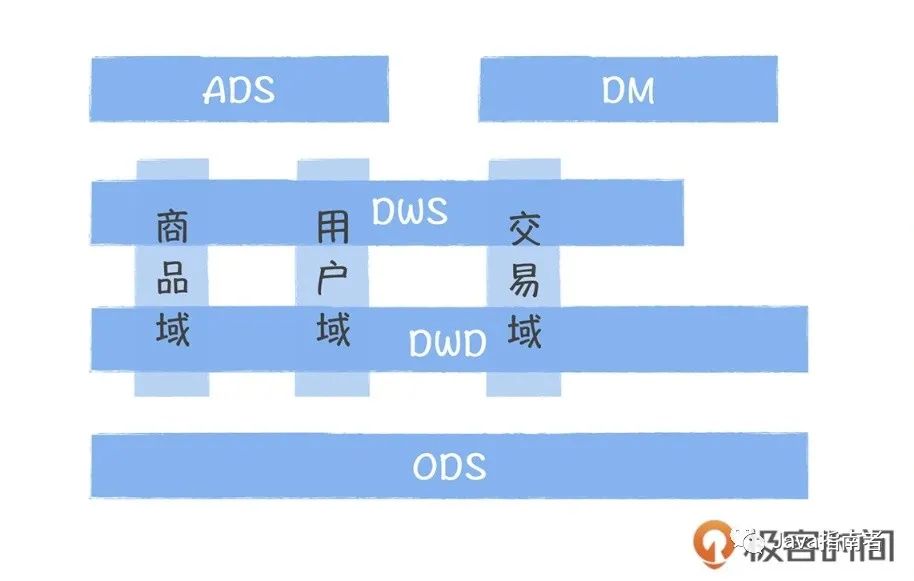
ODS 层:加载与处理业务系统源数据的临时区。ODS 是面向系统,贴源迁移。不改变数据结构和数据粒度,但需清洗脏数据。
DWD:企业唯一的、集成的、准确的数据版本。数据按主题域组织,数据结构按实体和关系重构,数据粒度保留最细。使用 E-R 建模。
DWS:面向业务,维度建模。数据按业务过程组织,数据结构按事实表和维度表重构,数据粒业务度按需汇总。
ADS:面向应用场景使用适合的工具提升数据存储与处理的效率,从而提供数据服务。
主数据管理
能够满足企业跨部门协同需要的、反映核心业务实体状态属性的企业(组织机构)基础信息,属性相对稳定、准确度要求更高、唯一识别的,就是主数据,称为 MDM。这是《主数据管理实践白皮书》给出的定义。
主数据是描述核心业务的关键事实,例如客户、产品、员工、地区等;同时也包含这些事实间的数据关系。主数据管理主要体现了以下价值:
消除数据冗余:不同系统、不同部门按照自身规则和需求获取数据,容易造成数据重复存储,形成数据冗余。主数据打通各业务链条,统一数据语言,统一数据标准,实现数据共享,最大化消除了数据冗余。
提升数据处理效率:各系统、各部门对于数据定义不一样,不同版本的数据不一致,一个核心主题也有多个版本的信息,需要大量的人力、时间成本去整理和统一。通过主数据管理可以实现数据动态整理、复制、分发和共享。
提高公司战略协同力:数据作为公司内部经营分析、决策支撑的“通行语言”,实现多个部门统一后,有助于打通部门、系统壁垒,实现信息集成与共享,提高公司整体的战略协同力。
下图是主数据资产清单示例,要实现对主数据管理,主要是从以下几方面实现:

深入业务,扎根业务:每个业务线关键实体既有差异,也有交叉;主要深入了解业务,才可以保持主数据一致性、准确性、完整性、可控性。
面向主题域管理:按照业务线、主题域和业务过程三级目录方式管理主数据。通过分层归类管理主数据可以提高管理的效率。
指标体系
指标是一个可以量化目标事物多少的数值,有时候也称为度量,如:DNU、留存率等都是指标。指标体系就是将各个指标按照特定的框架组织起来,从而统一指标名称及口径定义,理清指标间构成关系,避免重复建设。下图是指标体系示例。
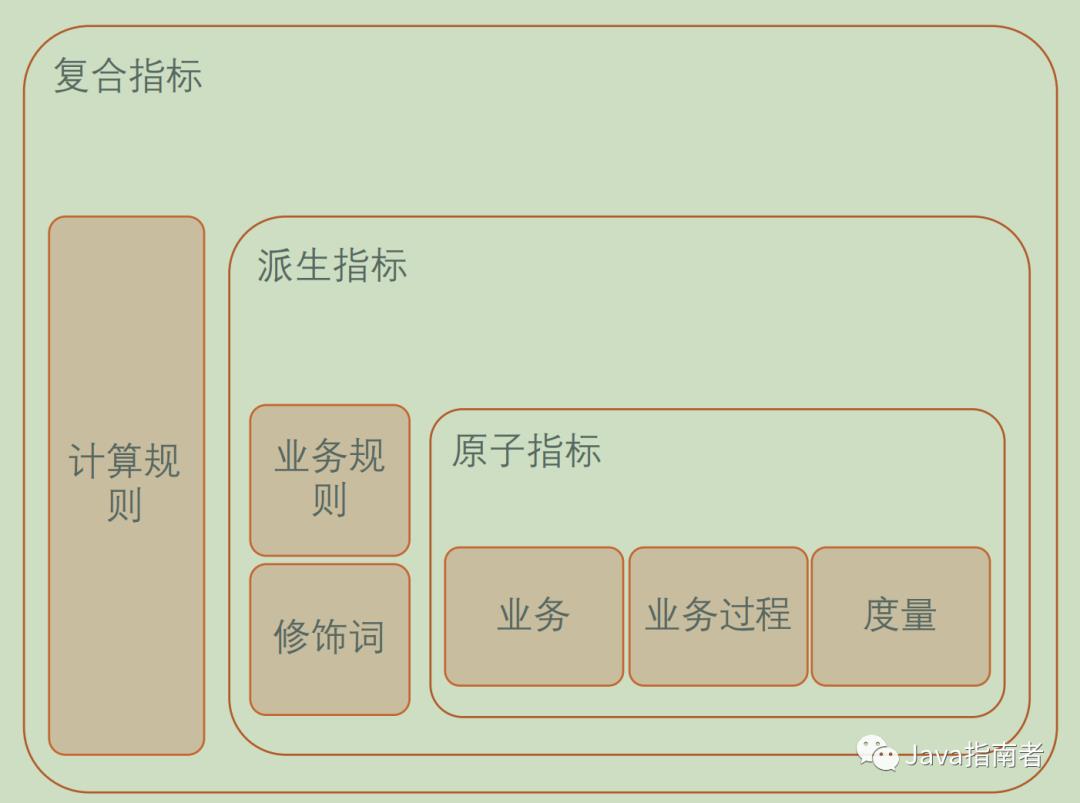
业务过程:业务过程是企业活动中不可拆分的行为事件。
维度/属性:维度是观察和分析业务过程的角度,属性是描述维度的信息。
原子指标:原子指标是对具体业务过程的度量或对具体维度/属性的计数,具有明确的业务含义且在逻辑层面不可再拆分。
修饰词:修饰词是对原子指标进行修饰限定的词汇,对应着明确的业务场景和业务规则,用于圈定原子指标业务统计的范围。
派生指标:派生指标是原子指标与一个或多个修饰词的组合。
复合指标:原子指标和派生指标经过叠加公式所计算出来的直接结果。
词根管理
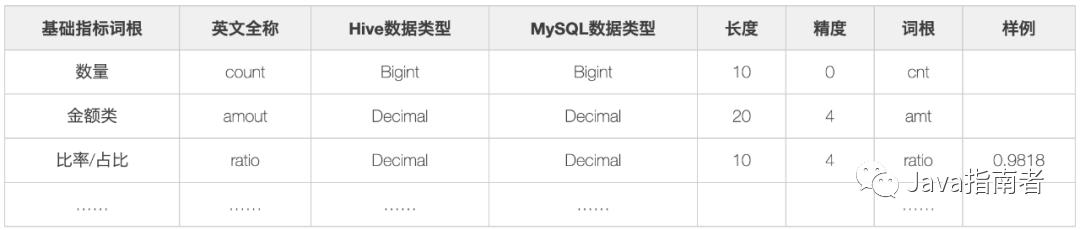
词根是企业最细粒度业务术语,是维度和指标管理的基础,通过词根可以用来统一表名、字段名、主题域名;建立和维护可收敛的词根库,业务域、主题域我们都可以用词根的方式枚举清楚,不断完善,粒度也是同样的,主要的是时间粒度、日、月、年、周等,使用词根定义好简称,数仓开发的字段命名也可以使用词根进行组合;划分为普通词根与专有词根
普通词根:描述事物的最小单元体,如:交易-trade。
专有词根:具备约定成俗或行业专属的描述体,如:美元-USD。
词根示例如下:
数据血缘
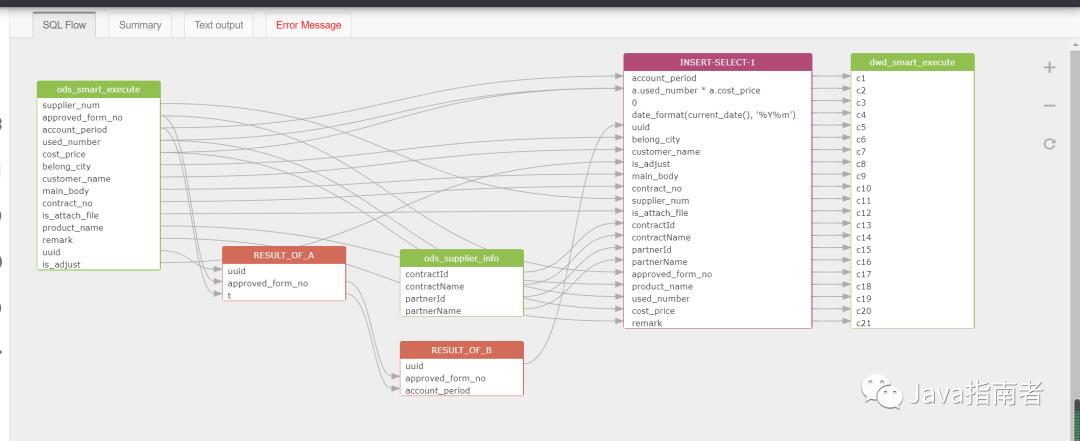
数据的处理过程中,从数据源头到最终的数据生成,每个环节都可能会导致我们出现数据质量的问题。比如我们数据源本身数据质量不高,在后续的处理环节中如果没有进行数据质量的检测和处理,那么这个数据信息最终流转到我们的目标表,它的数据质量也是不高的。也有可能在某个环节的数据处理中,我们对数据进行了一些不恰当的处理,导致后续环节的数据质量变得糟糕。因此,对于数据的血缘关系,我们要确保每个环节都要注意数据质量的检测和处理,那么我们后续数据才会有优良的基因,即有很高的数据质量。
数据血缘关系的作用
数据溯源:数据的血缘关系,体现了数据的来龙去脉,能帮助我们追踪数据的来源,追踪数据处理过程。
评估数据价值:数据的价值在数据交易领域非常重要,数据血缘关系,可以从数据受众、数据更新量级、数据更新频次几方面来给数据价值的评估提供依据。
数据质量评估:从数据质量评估角度来看,清晰的数据源和加工处理方法,可以明确每个节点数据质量的好坏。从数据的血缘关系图上,可以方便地看到数据清洗的标准清单。
数据归档、销毁的参考:从数据生命周期管理角度来看,数据的血缘关系有助于我们判断数据的生命周期,是数据的归档和销毁操作的参考。
数据血缘示例图如下:
end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统关于数据中台的深度思考与总结(干干货)日志收集Agent,阴暗潮湿的地底世界
公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。
点个赞+在看,少个 bug ????
以上是关于聊聊数据仓库建设的主要内容,如果未能解决你的问题,请参考以下文章