Hadoop整体介绍
Posted 脚丫先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop整体介绍相关的知识,希望对你有一定的参考价值。
大家好,我是脚丫先生 (o^^o)
在大数据和后端开发的路上不知不觉已经走了两年了,想持续认真输出博客,虽然没有其他博主那么深厚的功力,但是也想把自己之前学习的大数据知识,通过博客的方式进行叙述,同时也是一种对大数据基础知识的复习,正所谓万丈高楼平地起,在今后,不管转项目经理或者架构师,都需要扎实的相关技术,才能收服少年们。
好了,我们开始今天的正文。

文章目录
零、三大重要海量数据面试题:
- 1、如何从一个海量文件中寻找出现次数最多的10个元素?(TopN)
- 2、如何从两个大数据集中找出共同元素?(求交集)
- 3、如何设计一个高效算法判断一个元素是否存在于一个庞大集合内?(布隆过滤器)
思路:
- 1、求 TopN
数据量小: 先排序,然后limit 3
数据量大: 先分区/分桶(把数据先分成多个小的组成部分),每个小的部分都单独计算出来 N 个最大的,最终把每个小部分计算出来的 N 个最大的,做最终的汇总。 - 2、求交集
假如 文件 a 和 文件b 都特别大:
现在求出共同的元素:
(1)、采用的思路依然是分治法
(2)、关键在于怎么分治(随机,范围,Hash散列,…)
做Hash散列(行业通用的默认做法)
a文件拆分成 10个文件:
b文件拆分成10个文件:
a1 和 b1 找共同元素就可以
a2 和 b2 找共同元素
… - 3、判断元素是否存在
数据量小: java中的hashset、redis的set
数据量大:布隆过滤器(更强大的位图算法)实现快速判断一个元素是否存在。
优点:快速判断(爬虫: url判重)
缺点:误判
一、Hadoop的快速入门
1.1、数据
数据是事实或观察的结果,是对客观事物的逻辑归纳,是用于表示客观事物的未经加工的的原始素材。数据可以是连续的值,比如声音、图像,称为模拟数据。也可以是离散的,如符号、文字,称为数字数据。在计算机系统中,数据以二进制信息单元0,1的形式表示。
1.2、大数据
大数据指的是传统数据处理应用软件,不足以处理(存储和计算)它们,大而复杂的数据集。
数据量最小的基本单位是bit,按顺序给出所有单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB
1.3、大数据的特点
一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库,软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低。
四大特征:大量,种类多,高速,低价值密度。
(1)、大量:数据的大小决定所考虑的数据的价值和潜在的信息。
(2)、种类:数据类型的多样性,包括文本,图片,视频,音频。
结构化数据:可以用二维数据库表来抽象,抽取数据规律。以数据库数据和文本数据为结构化数据。
半结构化数据:介于结构化和非结构化之间,主要指XML,html等,也可称非结构化
非结构化数据:不可用二维表抽象,比如图片,图像,音频,视频等 。
(3)、 高速:指获得数据的速度以及处理数据的速度,数据的产生呈指数式爆炸式增长,处理数据要求的延时越来越低。
1.4、大数据核心技术
大数据技术的体系庞大且复杂。首先给出一个通用化的大数据处理框架,主要分为下面几个方面:数据采集与预处理、数据存储、数据清洗、数据查询分析和数据可视化。
二、Hadoop产生的背景
Hadoop 最早起源于 Nutch。Nutch 的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题:如何解决数十亿网页的存储和索引问题。
之后谷歌陆续发表的多篇论文为该问题提供了可行的解决方案:
- 1、分布式文件系统GFS:可用于处理海量网页的存储
- 2、分布式计算框架MapReduce:可用于处理海量网页的索引计算问题
- 3、分布式数据库BigTable:每一张表可以存储上 billions 行和 millions 列。
Nutch 的开发人员完成了相应的开源实现 HDFS 和 MapReduce,并且从 Nutch 中剥离成为独立项目 Hadoop,到2008年1月,Hadoop 成为 Apache 顶级项目,迎来了它的快速发展期。
2.1、什么是Hadoop
1、Hadoop 是 Apache 旗下的一套高可靠,高可扩展,分布式计算的开源软件平台
2、Hadoop 提供的功能:主要解决数据的存储和海量数据的分析计算功能
3、Hadoop 的核心组件有
A.Common (基础功能组件)(工具包,RPC框架)JNDI和 RPC
B.HDFS (Hadoop Distributed File System分布式文件系统)
C.YARN (Yet Another Resources Negotiator运算资源调度系统)
D.MapReduce (Map和Reduce分布式运算编程框架)
总之,广义上来说,Hadoop 通常是指一个更广泛的概念–Hadoop生态圈。
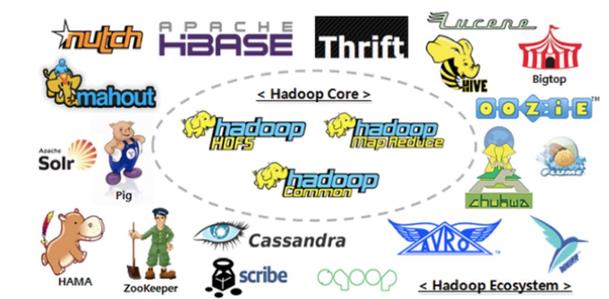
2.2、Hadoop三大发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。Cloudera在大型互联网企业中用的较多。
-
1.Apache Hadoop
优点:
完全开源免费
社区活跃
文档、资料详实
缺点:
(1) 版本管理比较混乱,各种版本层出不穷,很难选择,选择其他生态组件时,比如Hive,Sqoop,Flume,Spark等,需要考虑 兼容性问题、版本匹配问题、组件冲突问题、编译问题等。
(2) 集群安装部署复杂,需要编写大量配置文件,分发到每台节点,容易出错,效率低。
(3) 集群运维复杂,需要安装第三方软件辅助。 -
2.Cloudera Hadoop(CDH)
优点
(1) 版本管理清晰。
(2) 版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。
(3) 集群安装部署简单。提供了部署、安装、配置工具,大大提高了集群部署的效率
(4) 运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
缺点:
收费了 -
3 Hortonworks Hadoop(HDP)
开源,可以进行二次开发,但是没有CDH稳定,国内使用较少。
2.3、hadoop生态圈
Hadoop技术生态圈的一个大致组件分布图:
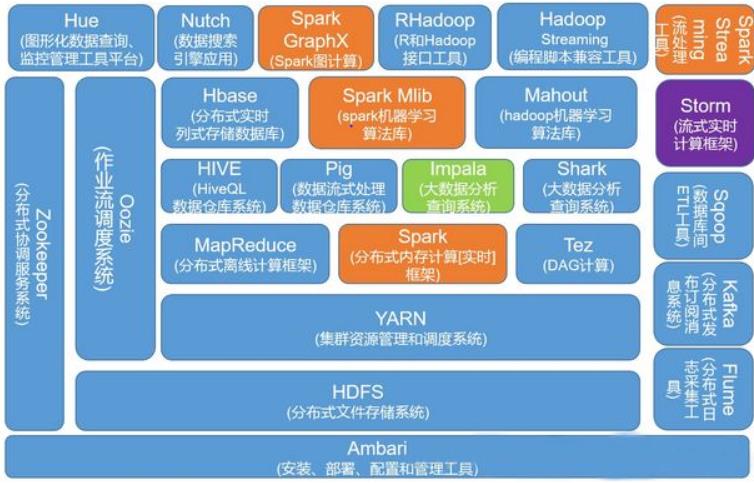
重点组件
(1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(mysql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
(2) Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
(3) Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,可以接收生产者(如webservice、文件、hdfs、hbase等)的数据,本身可以缓存起来,然后可以发送给消费者(同上),起到缓冲和适配的作。
(4) Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
(5) Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
(6) Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
(7) Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
(8) ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
(9) Flink: Flink是一个基于内存的分布式并行处理框架,类似于Spark,但在部分设计思想有较大出入。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。
以上是关于Hadoop整体介绍的主要内容,如果未能解决你的问题,请参考以下文章