《从Paxos到Zookeeper分布式一致性原理与实践》读书笔记
Posted 山河已无恙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《从Paxos到Zookeeper分布式一致性原理与实践》读书笔记相关的知识,希望对你有一定的参考价值。
写在前面
嗯,一直听人家说分布式,奈何这个概念一直不清晰,而且问大佬,也总是听的一知半解的,一直听人家讲Zookeeper,很早就想系统的学习一下,奈何时间挤不出来,除了工作就是不开心,没时间学习。现在离职准备找工作,留了点时间系统的学习一下。而且,忍受不了一知半解。要不就不学,要学就形成一个大概的知识体系,和已有的体系建立连接。个人觉得看书较看视频这方面要好一点,书更广一点。至于学了有用没有,那就不重要了,也不太考虑时间成本问题,要是这点任性都没有的,那活着多憋屈呀。哈哈…
嗯…时间原因,走马观花的刷了一遍,好多复杂的东西我都没看,先整体熟悉下,以后如果会用到在深入研究研究。
笔记还在更新中…
傍晚时分,你坐在屋檐下,看着天慢慢地黑下去,心里寂寞而凄凉,感到自己的生命被剥夺了。当时我是个年轻人,但我害怕这样生活下去,衰老下去。在我看来,这是比死亡更可怕的事。--------王小波
第1章分布式架构
随着计算机系统规模变得越来越大,将所有的业务单元集中部署在一个或若干个大型机上的体系结构,已经越来越不能满足当今计算机系统.
1.1从集中式到分布式
伴随着大型主机时代的到来,集中式的计算机系统架构也成为了主流。在那个时候,由于大型主机卓越的性能和良好的稳定性,其在单机处理能力方面的优势非常明显,使得IT系统快速进入了集中式处理阶段,其对应的计算机系统称为集中式系统。但从20世纪80年代以来,计算机系统向网络化和微型化的发展日趋明显,传统的集中式处理模式越来越不能适应人们的需求。(找重点,计算机系统架构,即分布式是一种计算机系统架构方式)
- 学习成本高
- 大型主机贵
- 容错性差,扩容困难
为了解决业务快速发展给IT系统带来的巨大挑战,从2009年开始,阿里集团启动了去IOE计划,其电商系统开始正式迈入分布式系统时代。
1.1.1集中式的特点
集中式系统:指由一台或多台主计算机组成中心节点,数据集中存储于这个中心节点中,并且整个系统的所有业务单元都集中部署在这个中心节点上,系统的所有功能均由其集中处理。
在集中式系统中:每个终端或客户端机器仅仅负责数据的录入和输出,而数据的存储与控制处理完全交由主机来完成。集中式系统最大的特点就是部署结构简单。由于集中式系统往往基于底层性能卓越的大型主机,因此无须考虑如何对服务进行多个节点的部署,也就不用考虑多个节点之间的分布式协作问题。
1.1.2分布式的特点
在《分布式系统概念与设计》生一书中,对分布式系统做了如下定义:
分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。 (找重点,硬件或软件组件,个人理解 ,硬件组件分布我们可以结合HarmonyOS理解,音画同步,应用跨设备流转,软总线等硬件抽象的分布式,软件组件分布这里结合我们常说微服务,类比Web分布式系统。)
一个标准的分布式系统在没有任何特定业务逻辑约束的情况下,都会有如下几个特征。
-
分布性:多台计算机都会在
空间上随意分布 -
对等性:计算机
没有主/从之分- 副本(Replica)最常见的概念之一,对数据和服务提供的一种冗余方式。为了对外提供高可用的服务,我们往往会对数据和服务进行副本处理。
- 数据副本是指在不同的节点上持久化同一份数据,当某一个节点上存储的数据丢失时,可以从副本上读取到该数据,这是解决分布式系统数据丢失问题最为有效的手段。
- 服务副本指多个节点提供同样的服务,每个节点都有能力接收来自外部的请求并进行相应的处理。
-
并发性:在一个计算机网络中,程序运行过程中的
并发性操作是非常常见的行为,例如同一个分布式系统中的多个节点,可能会并发地操作一些共享的资源,诸如数据库或分布式存储等. -
缺乏全局时钟一个典型的分布式系统是由一系列在
空间上随意分布的多个进程组成的,具有明显的分布性,这些进程之间通过交换消息来进行相互通信。因此,在分布式系统中,很难定义两个事件究竟谁先谁后,原因就是因为分布式系统缺乏一个全局的时钟序列控制。 -
故障总是会发生:任何在
设计阶段考虑到的异常情况,一定会在系统实际运行中发生,并且,在系统实际运行过程中还会遇到很多在设计时未能考虑到的异常故障。所以,除非需求指标允许,在系统设计时不能放过任何异常情况。
1.1.3分布式环境的各种问题
通信异常
分布式系统需要在各个节点之间进行网络通信,因此每次网络通信都会伴随着网络不可用的风险,网络光纤、路由器或是DNS等硬件设备或是系统不可用都会导致最终分布式系统无法顺利完成一次网络通信。
即使分布式系统各节点之间的网络通信能够正常进行,其延时也会远大于单机操作。通常我们认为在现代计算机体系结构中,单机内存访问的延时在纳秒数量级(通常是10ns左右),而正常的一次网络通信的延迟在0.1~1ms左右(相当于内存访问延时的105-106倍),如此巨大的延时差别,也会影响消息的收发的过程,因此消息丢失和消息延迟变得非常普遍。
网络分区
当网络由于发生异常情况,导致分布式系统中部分节点之间的网络延时不断增大,最终导致组成分布式系统的所有节点中,只有部分节点之间能够进行正常通信,而另一些节点则不能–我们将这个现象称为网络分区,就是俗称的脑裂。当网络分区出现时,分布式系统会出现局部小集群,在极端情况下,这些局部小集群会独立完成原本需要整个分布式系统才能完成的功能,包括对数据的事务处理等。
三态
分布式系统的每一次请求与响应,存在特有的三态概念,即成功、失败与超时。在传统的单机系统中,应用程序在调用一个函数之后,能够得到一个非常明确的响应:成功或失败
分布式系统中当网络出现异常的情况下,就可能会出现超时现象,通常有以下两种情况:
- 由于网络原因,该请求(消息)并没有被成功地发送到接收方,而是在发送过程就发生了消息丢失现象。
- 该请求(消息)成功的被接收方接收后,并进行了处理,但是在将响应反馈给发送方的过程中,发生了消息丢失现象。
当出现这样的超时现象时,网络通信的发起方是无法确定当前请求是否被成功处理的。
节点故障
节点故障则是比较常见的问题,组成分布式系统的服务器节点出现的宕机或“僵死”现象。通常根据经验来说,每个节点都有可能会出现故障,并且每天都在发生。
1.2从ACID到CAP/BASE
1.2.1 ACID
事务(Transaction)是由一系列对系统中数据进行访问与更新的操作所组成的一个程序执行逻辑单元(Unit),狭义上的事务特指数据库事务。
- 一方面,当多个应用程序并发访,问数据库时,事务可以在这些应用程序之间提供一个
隔离方法,以防止彼此的操作互相干扰。 - 另一方面,事务为数据库操作序列提供了一个
从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持数据一致性的方法。
事务具有四个特征,分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),简称为事务的ACID特性。
- 原子性: 事务的原子性是指
事务必须是一个原子的操作序列单元。事务中包含的各项操作在一次执行过程中,只允许出现以下两种状态之一。全部成功执行。全部不执行。任何一项操作失败都将导致整个事务失败,同时其他已经被执行的操作都将被撤销并回滚,只有所有的操作全部成功,整个事务才算是成功完成。 - 一致性: 事务的一致性是指
事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。也就是说,事务执行的结果必须是**使数据库从一个一致性状态转变到另一个一致性状态,**因此当数据库只包含成功事务提交的结果时,就能说数据库处于一致性状态。而如果数据库系统在运行过程中发生故障,有些事务尚未完成就被迫中断,这些未完成的事务对数据库所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是不一致的状态。 - 持久性: 事务的
持久性也被称为永久性,是指一个事务一旦提交,它对数据库中对应数据的状态变更就应该是永久性的。换句话说,一旦某个事务成功结束,那么它对数据库所做的更新就必须被永久保存下来-即使发生系统崩溃或机器宕机等故障,只要数据库能够重新启动,那么一定能够将其恢复到事务成功结束时的状态。 - 隔离性: 事务的隔离性是指在并发环境中,并发的事务是相互隔离的,
一个事务的执行不能被其他事务干扰。也就是说,不同的事务并发操纵相同的数据时,每个事务都有各自完整的数据空间,即一个事务内部的操作及使用的数据对其他并发事务是隔离的,并发执行的各个事务之间不能互相干扰。在标准SQL规范中,定义了4个事务隔离级别,不同的隔离级别对事务的处理不同:
| 隔离级别 | 描述 |
|---|---|
未授权读取 | 未授权读取也被称为读未提交(Read Uncommitted)该隔离级别允许脏读取,其隔离级别最低。换句话说,如果一个事务正在处理某一数据,并对其进行了更新,但同时尚未完成事务,因此还没有进行事务提交;而与此同时,允许另一个事务也能够访问该数据。举个例子来说,事务A和事务B同时进行,事务A在整个执行阶段,会将某数据项的值从1开始,做一系列加法操作(比如说加1操作)直到变成10之后进行事务提交,此时,事务B能够看到这个数据项在事务A操作过程中的所有中间值(如1变成2、2变成3等),而对这一系列的中间值的读取就是未授权读取。 |
授权读取 | 授权读取也被称为读已提交(Read Committed)它和未授权读取非常相近,唯一的区别就是授权读取只允许获取已经被提交的数据。同样以上面的例子来说,事务A和事务B同时进行,事务A进行与上述同样的操作,此时,事务B无法看到这个数据项在事务A操作过程中的所有中间值,只能看到最终的10,另外,如果说有一个事务C,和事务A进行非常类似的操作,只是事务C是将数据项从10加到20,此时事务B也同样可以读取到20,即授权读取允许不可重复读取。 |
可重复读取(Repeatable Read) | 简单地说,就是保证在事务处理过程中,多次读取同一个数据时,其值都和事务开始时刻是一致的。因此该事务级别禁止了不可重复读取和脏读取,但是有可能出现幻影数据。所谓幻影数据,就是指同样的事务操作,在前后两个时间段内执行对同一个数据项的读取,可能出现不一致的结果。在上面的例子,可重复读取隔离级别能够保证事务B在第一次事务操作过程中,始终对数据项读取到1,但是在下一次事务操作中,即使事务B(注意,事务名字虽然相同,但是指的是另一次事务操作)采用同样的查询方式,就可能会读取到10或20. |
串行化(Serializable) | 是最严格的事务隔离级别。它要求所有事务都被串行执行,即事务只能一个接一个地进行处理,不能并发执行。类似于java的同步块同步方法 |
{kind=link}
| 隔离级别 | 脏读 | 可重复读 | 幻读 |
|---|---|---|---|
| 未授权读取 | 存在 | 不可以 | 存在 |
| 授权读取 | 不存在 | 不可以 | 存在 |
| 可重复读取 | 不存在 | 可以 | 存在 |
| 串行化 | 不存在 | 不存在 | 不存在 |
事务隔离级别越高,就越能保证数据的完整性和一致性,但同时对并发性能的影响也越大。通常,对于绝大多数的应用程序来说,可以优先考虑将数据库系统的隔离级别设置为授权读取,这能够在避免脏读取的同时保证较好的并发性能。
尽管这种事务隔离级别会导致不可重复读、虚读和第二类丢失更新等并发问题,但较为科学的做法是在可能出现这类问题的个别场合中,由应用程序主动采用悲观锁或乐观锁来进行事务控制。
1.2.2分布式事务
分布式事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于分布式系统的不同节点之上。通常一个分布式事务中会涉及对多个数据源或业务系统的操作。
1.2.3 CAP和BASE理论
在可用性和一致性之间永远无法存在一个两全其美的方案,于是如何构建一个兼顾可用性和一致性"的分布式系统成为了无数工程师探讨的难题,出现了诸如CAP和BASE这样的分布式系统经典理论。
CAP定理
CAP定理:CAP理论告诉我们,一个分布式系统不可能同时满足一致性(C: Consistency)、可用性(A: Availability)和分区容错性(P: Partition tolerance)这三个基本需求,最多只能同时满足其中的两项。
一致性:在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的特性。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。那么这样的系统就被认为具有强一致性(或严格的一致性)。
可用性:可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。对于用户的一个操作请求,系统必须能够在指定的时间(即响应时间)内返回对应的处理结果,如果超过了这个时间范围,那么系统就被认为不可用。
分区容错性:分区容错性 约束 了一个分布式系统需要具有如下特性:
- 分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足
一致性和可用性的服务,除非是整个网络环境都发生了故障。 网络分区是指在分布式系统中,不同的节点分布在不同的子网络(机房或异地网络等)中,由于一些特殊的原因导致这些子网络之间出现网络不连通的状况,但各个子网络的内部网络是正常的,从而导致整个系统的网络环境被切分成了若干个孤立的区域。需要注意的是,组成一个分布式系统的每个节点的加入与退出都可以看作是一个特殊的网络分区。
| 放弃CAP定理 | 说明 |
|---|---|
放弃P(分区容错性) | 如果希望能够避免系统出现分区容错性问题,一种较为简单的做法是将所有的数据(或者仅仅是那些与事务相关的数据)都放在一个分布式节点上。这样的做法虽然无法100%地保证系统不会出错,但至少不会碰到由于网络分区带来的负面影响。但同时需要注意的是,放弃P的同时也就意味着放弃了系统的可扩展性,分区容错性可以说是一个最基本的要求 |
放弃A(可用性) | 相对于放弃“分区容错性”来说,放弃可用性则正好相反,其做法是一旦系统遇到网络分区或其他故障时,那么受到影响的服务需要等待一定的时间,因.此在等待期间系统无法对外提供正常的服务,即不可用 |
放弃C(一致性) | 这里所说的放弃一致性,并不是完全不需要数据一致性,如果真是这样的话,那么系统的数据都是没有意义的,整个系统也是没有价值的。事实上,放弃一致性指的是放弃數据的强一致性,而保留數据的最终一致性。这样的系统无法保证数据保持实时的一致性,但是能够承诺的是,数据最终会达到一个一致的状态。这就引入了一个时间窗口的概念,具体多久能够达到数据一致取决于系统的设计,主要包括数据副本在不同节点之间的复制时间长短 |
而对于分布式系统而言,网络问题又是一个必定会出现的异常情况,因此分区容错性也就成为了一个分布式系统必然需要面对和解决的问题。因此系统架构设计师往往需要把精力花在如何根据业务特点在C(一致性)和A (可用性)之间寻求平衡。
BASE理论
BASE是Basically Available (基本可用), Soft state (软状态)和Eventually consistent(最终一致性)三个短语的简写.
BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency),
BASE中的三要素:
-
基本可用:是指分布式系统在出现不可预知故障的时候,允许损失部分可用性-但请注意,这绝不等价于系统不可用。以下两个就是“基本可用”的典型例子。响应时间上的损失:正常情况下,一个在线搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障(比如系统部分机房发生断电或断网故障) ,查询结果的响应时间增加到了1-2秒。功能上的损失:正常情况下,在一个电子商务网站上进行购物,消费者几乎能够顺利地完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
-
弱状态:弱状态也称为软状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。 -
最终一致性:最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
亚马逊首席技术官Werner Vogels在于2008年发表的一篇经典文章:对最终一致性进行了非常详细的介绍。他认为最终一致性是一种特殊的弱一致性:系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问都能够获取到最新的值。同时,在没有发生故障的前提下,数据达到一致状态的时间延迟,取决于网络延迟、系统负载和数据复制方案设计等
最终一致性变种:
因果一致性( Causal consistency )
因果一致性是指,如果进程A在更新完某个数据项后通知了进程B,那么进程B之后对该数据项的访问都应该能够获取到进程A更新后的最新值,并且如果进程B要对该数据项进行更新操作的话,务必基于进程A更新后的最新值,即不能发生丢失更新情况。与此同时,与进程A无因果关系的进程C的数据访问则没有这样的限制。
读已之所写( Read your writes)
读己之所写是指,进程A更新一个数据项之后,它自己总是能够访问到更新过的最新值,而不会看到旧值。也就是说,对于单个数据获取者来说,其读取到的数据,一定不会比自己上次写入的值旧。因此,读己之所写也可以看作是一种特殊的因果一致性。
会话一致性(Session consistency )
会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现“读己之所写”的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。
单调读一致性( Monotonic read consistency )
单调读一致性是指如果一个进程从系统中读取出一个数据项的某个值后,那么系统对于该进程后续的任何数据访问都不应该返回更旧的值。单调写一致性是指,一个系统需要能够保证来自同一个进程的写操作被顺序地执行。
总的来说, BASE理论面向的是大型高可用可扩展的分布式系统,和传统事务的ACID特性是相反的,它完全不同于ACID的强一致性模型,而是提出通过牺牲强一致性来获,得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中, ACID特性与BASE理论往往又会结合在一起使用。
第2章一致性协议
为了解决分布式一致性问题,在长期的探索研究过程中,涌现出了一大批经典的一致性协议和算法,其中最著名的就是二阶段提交协议、三阶段提交协议和Paxos算法了。
2.1 2PC3PC
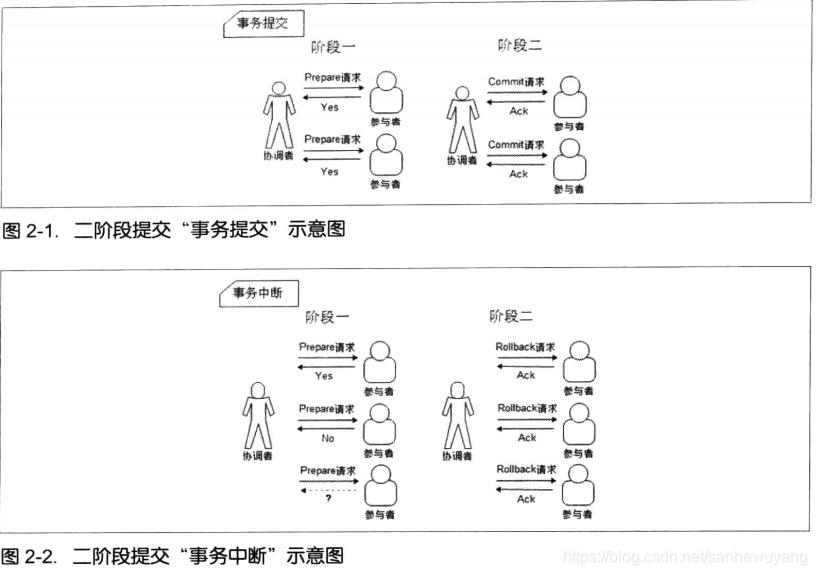
在分布式系统中,每一个机器节点虽然都能够明确地知道自己在进行事务操作过程中的结果是成功或失败,但却无法直接获取到其他分布式节点的操作结果。因此,当一个事务操作需要跨越多个分布式节点的时候,为了保持事务处理的ACID特性,就需要引入一个称为“协调者(Coordinator)”的组件来统一调度所有分布式节点的执行逻辑,这些被调度的分布式节点则被称为“参与者” (Participant),协调者负责调度参与者的行为,并最终决定这些参与者是否要把事务真正进行提交。基于这个思想,衍生出了二阶段提交和三阶段提交两种协议。
2.1.1 2PC
2PC,是Two-Phase Commit的缩写,即二阶段提交,是计算机网络尤其是在数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务处理过程中能够保持原子性和一致性而设计的一种算法。通常,二阶段提交协议也被认为是一种一致性协议,用来保证分布式系统数据的一致性。目前,绝大部分的关系型数据库都是采用二阶段提交协议·来完成分布式事务处理的,利用该协议能够非常方便地完成所有分布式事务参与者的协调,统一决定事务的提交或回滚,从而能够有效地保证分布式数据一致性.
协议说明
顾名思义,二阶段提交协议是将事务的提交过程分成了两个阶段
阶段一:提交事务请求
- 事务询问。
协调者向所有的参与者发送事务内容,询问是否可以执行事务提交操作,并开始等待各参与者的响应。 - 执行事务。各
参与者节点执行事务操作,并将Undo和Redo信息记入事务日志中。 - 各参与者向协调者反馈事务询问的响应。
如果参与者成功执行了事务操作,那么就反馈给协调者Yes响应,表示事务可以执行;如果参与者没有成功执行事务,那么就反馈给协调者No响应,表示事务不可以执行。
由于上面讲述的内容在形式上近似是协调者组织各参与者对一次事务操作的投票表态过程,因此二阶段提交协议的阶段一也被称为“投票阶段”,即各参与者投票表明是否要继续执行接下的事务提交操作。
阶段二:执行事务提交
阶段二中,协调者会根据各参与者的反馈情况来决定最终是否可以进行事务提交操作,正常情况下,包含以下两种可能:
执行事务提交:假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务提交。发送提交请求。协调者向所有参与者节点发出Commit请求。事务提交。参与者接收到Commit请求后,会正式执行事务提交操作,并在完成提交之后释放在整个事务执行期间占用的事务资源。反馈事务提交结果。参与者在完成事务提交之后,向协调者发送Ack消息。完成事务。协调者接收到所有参与者反馈的Ack消息后,完成事务。
中断事务:假如任何一个参与者向协调者反馈了No响应,或者在等待超时之后,协调者尚无法接收到所有参与者的反馈响应,那么就会中断事务。发送回滚请求。协调者向所有参与者节点发出Rollback请求。事务回滚。参与者接收到Rollback请求后,会利用其在阶段一中记录的Undo信息来执行事务回滚操作,并在完成回滚之后释放在整个事务执行期间占用的资源。反馈事务回滚结果。参与者在完成事务回滚之后,向协调者发送Ack消息。中断事务。协调者接收到所有参与者反馈的Ack消息后,完成事务中断。
二阶段提交将一个事务的处理过程分为了投票和执行两个阶段,其核心是对每个事务都采用先尝试后提交的处理方式,因此也可以将二阶段提交看作一个强一致性的算法.
优缺点:
- 优点:
原理简单,实现方便。 - 缺点:
同步阻塞、单点问题、脑裂、太过保守。
同步阻塞:所有参与该事务操作的逻辑都处于阻塞状态,也就是说,各个参与者在等待其他参与者响应的过程中,将无法进行其他任何操作。
单点问题:如果协调者是在阶段二中出现问题的话,那么其他参与者将会一直处于锁定事务资源的状态中,而无法继续完成事务操作。
数据不一致:在二阶段提交协议的阶段二,即执行事务提交的时候,当协调者向所有的参与者发送Commit请求之后,发生了局部网络异常或者是协调者在尚未发送完Commit请求之前自身发生了崩溃,导致最终只有部分参与者收到了Commit请求。于是,这部分收到了Commit请求的参与者就会进行事务的提交,而其他没有收到Commit请求的参与者则无法进行事务提交,于是整个分布式系统便出现了数据不一致性现象。
太过保守:如果在协调者指示参与者进行事务提交询问的过程中,参与者出现故障而导致协调者始终无法获取到所有参与者的响应信息的话,这时协调者只能依靠其自身的超时机制来判断是否需要中断事务,这样的策略显得比较保守。换句话说,二阶段提交协议没有设计较为完善的容错机制,任意一个节点的失败都会导致整个事务的失败。
2.1.2 3PC
二阶段提交协议的基础上进行了改进,提出了三阶段提交协议。
3PC,是Three-Phase Commit的缩写,即三阶段提交,是2PC的改进版,其将二阶段提交协议的“提交事务请求”过程一分为二,形成了由CanCommit, PreCommit和do Commit三个阶段组成的事务处理协议.
阶段一: CanCommit1
1.事务询问。协调者向所有的参与者发送一个包含事务内容的canCommit请求,询问是否可以执行事务提交操作,并开始等待各参与者的响应。
2. 各参与者向协调者反馈事务询问的响应。参与者在接收到来自协调者的canCommit请求后,正常情况下,如果其自身认为可以顺利执行事务,那么会反馈Yes响应,并进入预备状态,否则反馈No响应。
阶段二: PreCommit
在阶段二中,协调者会根据各参与者的反馈情况来决定是否可以进行事务的PreCommit操作,正常情况下,包含两种可能。
- 执行事务预提交假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务预提交。
发送预提交请求。协调者向所有参与者节点发出preCommit的请求,并进入Prepared阶段。事务预提交。参与者接收到preCommit请求后,会执行事务操作,并将Undo和Redo信息记录到事务日志中。各参与者向协调者反馈事务执行的响应。如果参与者成功执行了事务操作,那么就会反馈给协调者Ack响应,同时等待最终的指令:提交(commit)或中止(abort)中断事务
- 中断事务假如任何一个参与者向协调者反馈了No响应,或者在等待超时之后,协调者尚无法接收到所有参与者的反馈响应,那么就会中断事务。
发送中断请求。协调者向所有参与者节点发出abort请求。中断事务。无论是收到来自协调者的abort请求,或者是在等待协调者请求过程中出现超时,参与者都会中断事务。
阶段三: doCommit
该阶段将进行真正的事务提交,会存在以下两种可能的情况。
- 执行提交.
发送提交请求。进入这一阶段,假设协调者处于正常工作状态,并且它接收到了来自所有参与者的Ack响应,那么它将从“预提交”状态转换到“提交”状态,并向所有的参与者发送doCommit请求。事务提交。参与者接收到doCommit请求后,会正式执行事务提交操作,并在完成提交之后释放在整个事务执行期间占用的事务资源。反馈事务提交结果。参与者在完成事务提交之后,向协调者发送Ack消息。完成事务。协调者接收到所有参与者反馈的Ack消息后,完成事务。
- 中断事务进入这一阶段,假设
协调者处于正常工作状态,并且有任意一个参与者向协调者反馈了No响应,或者在等待超时之后,协调者尚无法接收到所有参与者的反馈响应,那么就会中断事务。发送中断请求。协调者向所有的参与者节点发送abort请求。事务回滚。参与者接收到abort请求后,会利用其在阶段二中记录的Undo信息来执行事务回滚操作,并在完成回滚之后释放在整个事务执行期间占用的资源。
需要注意的是,一旦进入阶段三,可能会存在以下两种故障。
- 协调者出现问题。
- 协调者和参与者之间的网络出现故障。
无论出现哪种情况,最终都会导致参与者无法及时接收到来自协调者的doCommit或是abort请求,针对这样的异常情况,参与者都会在等待超时之后,继续进行事务提交。
感觉这里说的有点问题,感觉和第二阶段的中断事务是有冲突的
优缺点
三阶段提交协议的优点:
相较于二阶段提交协议,三阶段提交协议最大的优点就是降低了参与者的阻塞范围,并且能够在出现单点故障后继续达成一致。
三阶段提交协议的缺点:
三阶段提交协议在去除阻塞的同时也引入了新的问题,那就是在参与者接收到preCommit消息后,如果网络出现分区,此时协调者所在的节点和参与者无法进行正常的网络通信,在这种情况下,该参与者依然会进行事务的提交,这必然出现数据的不一致性。
2.2 Paxos算法
嗯,这部分有点深,简单了解一下。
2.2.1追本湖源
- 拜占廷将军问题
- Paxos算法名称的由来也是取自Lamport论文(The Par-Time Parliament)中提到的Paxos小岛。
2.2.2 Paxos理论的诞生
由于Lamport个人自负固执的性格,使得Paxos理论的诞生可谓一波三折。
2.2.3 Paxos算法详解
嗯。。。这个以后在学习。
第3章Paxos的工程实践
嗯。。。这个以后在学习。
第4章Zookeeper与Paxos
Apache ZooKeeper是由Apache Hadoop的子项目发展而来,于2010年11月正式成为了Apache的顶级项目。ZooKeeper为分布式应用提供了高效且可靠的分布式协调服务,提供了诸如统一命名服务、配置管理和分布式锁等分布式的基础服务。在解决分布式数据一致性方面, ZooKeeper并没有直接采用Paxos算法,而是采用了一种被称为ZAB(Zookeeper Atomic Broadcast)的一致性协议。
4.1初识ZooKeeper
4.1.1 ZooKeeper介绍
ZooKeeper是一个开放源代码的分布式协调服务,由知名互联网公司雅虎创建,是Google.Chubby的开源实现。ZooKeeper的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
Zookeeper是什么
Zookeeper是一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能. ZooKeeper可以保证如下分布式一致性特性.
- 顺序一致性:从同一个客户端发起的事务请求,最终将会严格地按照其发起顺序被应用到ZooKeeper中去.
- 原子性:所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群所有机器都成功应用了某一个事务,要么都没有应用,一定不会出现集群中部分机器应用了该事务,而另外一部分没有应用的情况
- 单一视围( Single System Image ):无论客户端连接的是哪个ZooKeeper服务器,其看到的服务端数据模型都是一致的。
- 可靠性:一旦服务端成功地应用了一个事务,并完成对客户端的响应,那么该事务所引起的服务端状态变更将会被一直保留下来,除非有另一个事务又对其进行了变更。
- 实时性:Zookeeper仅仅保证在一定的时间段内,客户端最终一定能够从服务端上读取到最新的数据状态。
ZooKeeper的设计目标
Zookeeper致力于提供一个高性能、高可用,且具有严格的顺序访问控制能力(主要是写操作的严格顺序性)的分布式协调服务。高性能使得ZooKeeper能够应用于那些对系统吞吐有明确要求的大型分布式系统中,高可用使得分布式的单点问题得到了很好的解决,而严格的顺序访问控制使得客户端能够基于ZooKeeper实现一些复杂的同步原语。下面我们来具体看一下Zookeeper的四个设计目标。
- 目标一:简单的数据模型:
ZooKeeper使得分布式程序能够通过一个共享的、树型结构的名字空间来进行相互协调。 - 目标二:可以构建集群:一个
ZooKeeper集群通常由一组机器组成,一般3-5台机器就可以组成一个可用的ZooKeeper集群了。 - 目标三:顺序访问:对于来自客户端的每个更新请求, ZooKeeper都会分配一个全局唯一的递增编号,这个编号反映了所有事务操作的先后顺序,应用程序可以使用ZooKeeper的这个特性来实现更高层次的同步原语。关于ZooKeeper的事务请求处理和事务ID的生成,
- 目标四:高性能“由于ZooKeeper将全量数据存储在内存中,并直接服务于客户端的所有非事务请求,因此它尤其适用于以读操作为主的应用场景。
4.1.2 Zookeeper从何而来
关于"ZooKeeper"这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家Raghu Ramakrishnan开玩笑地说: “在这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧-因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而ZooKeeper正好要用来进行分布式环境的协调-于是,ZooKeeper的名字也就由此诞生了。
4.1.3 ZooKeeper的基本概念
集群角色
通常在分布式系统中,构成一个集群的每一台机器都有自己的角色,最典型的集群模式就是Master/Slave模式(主备模式)。在这种模式中,我们把能够处理所有写操作的机器称为Master机器,把所有通过异步复制方式获取最新数据,并提供读服务的机器称为Slave机器。
而在ZooKeeper中,这些概念被颠覆了。它没有沿用传统的Master/Slave概念,而是引入了Leader, Follower和Observer三种角色。ZooKeeper集群中的所有机器通过一个Leader选举过程来选定一台被称为"Leader"的机器, Leader服务器为客户端提供读和写服务。除Leader外,其他机器包括Follower``和Observer, Follower和Observer都能够提供读服务,唯一的区别在于, Observer机器不参与Leader选举过程,也不参与写操作的“过半写成功”策略,因此Observer可以在不影响写性能的情况下提升集群的读性能。
会话(Session)
Session是指客户端会话,在讲解会话之前,我们首先来了解一下客户端连接。在ZooKeeper中,一个客户端连接是指客户端和服务器之间的一个TCP长连接.ZooKeeper对外的服务端口默认是2181,客户端启动的时候,首先会与服务器建立一个TCP连接,从第一次连接建立开始,客户端会话的生命周期也开始了,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向ZooKeeper服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的Watch事件通知.
数据节点(Znode)
在谈到分布式的时候,我们通常说的“节点”是指组成集群的每一台机器。然而,在ZooKeeper中, “节点”分为两类,第一类同样是指构成集群的机器,我们称之为机器节点;第二类则是指数据模型中的数据单元,我们称之为数据节点-ZNode,.
ZooKeeper将所有数据存储在内存中,数据模型是一棵树(ZNode Tree),由斜杠(/)进行分割的路径,就是一个Znode,例如/oo/pathl,每个ZNode上都会保存自己的数据内容,同时,还会保存一系列属性信息。在ZooKeeper中, ZNode可以分为持久节点和临时节点两类。所谓持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在Zookeeper上。而临时节点就不一样了,它的生命周期和客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。
Zookeeper还允许用户为每个节点添加一个特殊的属性: SEQUENTIAL,一旦节点被标记上这个属性,那么在这个节点被创建的时候, ZooKeeper会自动在其节点名后面追加上一个整型数字,这个整型数字是一个由父节点维护的自增数字。
版本
在前面我们已经提到, ZooKeeper的每个ZNode上都会存储数据,对应于每个ZNode,ZooKeeper都会为其维护一个叫作Stat的数据结构, Stat中记录了这个ZNode的三个数据版本,分别是version (当前ZNode的版本), cversion (当前ZNode子节点的版本)和aversion (当前ZNode的ACL版本)
Watcher
Watcher (事件监听器),是ZooKeeper中的一个很重要的特性。ZooKeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候, ZooKeeper服务端会将事件通知到感兴趣的客户端上去,该机制是ZooKeeper实现分布式协调服务的重要特性。
ACL
ZooKeeper采用ACL (Access Control Lists)策略来进行权限控制,类似于UNIX文件系统的权限控制。ZooKkeeper定义了如下5种权限。
- CREATE;创建子节点的权限。
- READ:获取节点数据和子节点列表的权限。
- WRITE:更新节点数据的权限。
- DELETE:删除子节点的权限。
- ADMIN:设置节点ACL的权限。其中尤其需要注意的是.
CREATE和DELETE这两种权限都是针对子节点的权限控制。
4.1.4为什么选择Zookeeper
- 达到了一个工业级产品的标准。其次, ZooKeeper是开放源代码的.
- ZooKeeper是免费的,你无须为它支付任何费用。
- ZooKeeper已经得到了广泛的应用。诸如Hadoop, HBase, Storm和Solr等.
4.2 Zookeeper的ZAB协议
嗯,时间紧张,这部分以后在看
4.2.1 ZAB协议
4.2.2协议介绍
4.2.3深入ZAB协议
4.2.4 ZAB与Paxos算法的联系与区别
第5章使用Zookeeper
5.1部署与运行
如何部署一个ZooKeeper集群。
5.1.1系统环境
- 操作系统: GNU/Linux, Sun Solaris, Win32以及MacoSX等
- Java环境: JDK1.6 以上。
5.1.2集群与单机
ZooKeeper有两种运行模式:集群模式和单机模式。涉及的部署与配置操作都是针对GNU/Linux系统的。
集群模式
- zookeeper安装
下载网站: https://zookeeper.apache.org/releases.html
[root@liruilong opt]# wget https://downloads.apache.org/zookeeper/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin.tar.gz
--2021-07-01 16:47:48-- https://downloads.apache.org/zookeeper/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin.tar.gz
Resolving downloads.apache.org (downloads.apache.org)... 135.181.214.104, 88.99.95.219, 135.181.209.10, ...
Connecting to downloads.apache.org (downloads.apache.org)|135.181.214.104|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 9623007 (9.2M) [application/x-gzip]
Saving to: ‘apache-zookeeper-3.5.9-bin.tar.gz’
100%[===========================================================================>] 9,623,007 7.57KB/s in 22m 35s
2021-07-01 17:10:25 (6.93 KB/s) - ‘apache-zookeeper-3.5.9-bin.tar.gz’ saved [9623007/9623007]
[root@liruilong opt]# ls
apache-zookeeper-3.5.9-bin.tar.gz
[root@liruilong opt]#
[root@liruilong opt]# mkdir zookeeper-3.5.9
[root@liruilong opt]# tar -xf apache-zookeeper-3.5.9-bin.tar.gz -C ./zookeeper-3.5.9/
[root@liruilong opt]# cd zookeeper-3.5.9/
[root@liruilong zookeeper-3.5.9]# ls
apache-zookeeper-3.5.9-bin
[root@liruilong zookeeper-3.5.9]#
[root@liruilong zookeeper-3.5.9]# ls
apache-zookeeper-3.5.9-bin
[root@liruilong zookeeper-3.5.9]# cd apache-zookeeper-3.5.9-bin/
[root@liruilong apache-zookeeper-3.5.9-bin]# ls
bin conf docs lib LICENSE.txt NOTICE.txt README.md README_packaging.txt
[root@liruilong apache-zookeeper-3.5.9-bin]# ls -l
total 40
drwxr-xr-x 2 502 games 4096 Jan 7 02:56 bin
drwxr-xr-x 2 502 games 4096 Jan 7 02:56 conf
drwxr-xr-x 5 502 games 4096 Jan 7 03:48 docs
drwxr-xr-x 2 root root 4096 Jul 1 19:12 lib
-rw-r--r-- 1 502 games 11358 Oct 5 2020 LICENSE.txt
-rw-r--r-- 1 502 games 432 Jan 7 00:12 NOTICE.txt
-rw-r--r-- 1 502 games 1560 Jan 7 02:56 README.md
-rw-r--r-- 1 502 games 1347 Jan 7 02:56 README_packaging.txt
[root@liruilong apache-zookeeper-3.5.9-bin]#
- 配置配置文件
[root@liruilong apache-zookeeper-3.5.9-bin]# ls conf/
configuration.xsl log4j.properties zoo_sample.cfg
[root@liruilong apache-zookeeper-3.5.9-bin]# cp ./conf/zoo_sample.cfg ./conf/zoo.cfg
[root@liruilong apache-zookeeper-3.5.9-bin]# ls conf/
configuration.xsl log4j.properties zoo.cfg zoo_sample.cfg
[root@liruilong apache-zookeeper-3.5.9-bin]# vim ./conf/zoo.cfg
初次使用ZooKeeper,需要将%ZK-HOME%conf目录下的zoo-sample.cfg文件重命名为zoo.cfg,并且按照如下代码进行简单配置即可:
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
server.1=IP1: 2888:3888
server.2=IP2: 2888:3888
server.3-IP3: 2888:3888
在集群模式下,集群中的每台机器都需要感知到整个集群是由哪几台机器组成的,在配置文件中,可以按照这样的格式进行配置,每一行都代表一个机器配置:
server.id-host:port:port其中,id被称为Server ID,用来标识该机器在集群中的机器序号。同时,在每台ZooKeeper机器上,我们都需要在数据目录(即dataDir参数指定的那个目录)下创建一个myid文件,该文件只有一行内容,并且是一个数字,即对应于每台机器的Server ID数字。在ZooKeeper的设计中,集群中所有机器上zoo.cfg文件的内容都应该是一致内。
myid文件中只有一个数字,即一个Server ID,例如, server.1的myid文件内容就是“1”。注意,请确保每个服务器的myid文件中的数字不同,并且和自己所在机器的zoo.cfg中server.id-host:port: port的d值一致。另外, id的范围是1-255
- 创建 myid文件
[root@liruilong ~]# touch /tmp/zookeeper/myid ;echo "1" > myid
- 按照相同的步骤,为其他机器都配置上zoo.cfg和myid文件。
- 启动服务器。
zkServer.sh脚本进行服务器的启动
[root@liruilong bin]# sh zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin/bin/../conf/zoo.cfg
Starting zookeeper ... already running as process 6580.
[root@liruilong bin]#
- 验证服务器。启动完成后,可以使用如下命令来检查服务器启动是否正常:
$telnet 127.0.0.1 2181
[root@liruilong bin]# telnet 127.0.0.1 2181
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape char以上是关于《从Paxos到Zookeeper分布式一致性原理与实践》读书笔记的主要内容,如果未能解决你的问题,请参考以下文章
《从Paxos到Zookeeper:分布式一致性原理与实践》PDF下载
从Paxos到Zookeeper分布式一致性原理与实践 -笔记
从Paxos到Zookeeper分布式一致性原理与实践 -笔记
《从PAXOS到ZOOKEEPER分布式一致性原理与实践》pdf