可观测性介绍
Posted 回归心灵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可观测性介绍相关的知识,希望对你有一定的参考价值。
定义
控制理论中的可观测性(observability)是指系统可以由其外部输出推断其其内部状态的程度。系统的可观测性和可控制性是数学上对偶的概念。可观测性最早是匈牙利裔工程师鲁道夫·卡尔曼针对线性动态系统提出的概念。若以信号流图来看,若所有的内部状态都可以输出到输出信号,此系统即有可观测性。
一系统具有可观测性当且仅当,针对所有的状态向量及控制向量,都可以在有限时间内,只根据输出信号来识别目前的状态。
----维基百科
为什么需要可观测性
一个系统如果没有数据体现其内部状态,那么对于维护它的人员来说将变的非常困难,特别是遇到系统出问题时,将会无可适从。近些年随着微服务架构的流行,越来越多的系统被拆分为多个服务,每个服务的运行状况,服务间的调用关系,接口响应时延等问题都是每一个系统维护人员所有面对的,因此可观测性也越来越受到人们的关注。可观测技术也被 Gartner 列为 2023 年十大战略技术趋势之一。
系统具有可观测性能解决以下问题:
- 能够随时随地了解系统的行为、性能和运行状况,以便为最终用户提供最佳体验。
- 可以通过告警机制,及时感知系统出问题,减少对用户的影响。
- 当系统出现问题时,能够快速检测问题,有效排查并快速修复,缩短了平均解决时间。
- 了解系统中一些关键指标的发展趋势,以便及早作出预判响应。
可观测性主要内容
可观测性在业界通常分为三个具体的方向:日志、追踪和度量。也通常被称为可观测性的三大支柱,这三个方向侧重点不同,但又不是完全独立,它们之间有重合的地方。
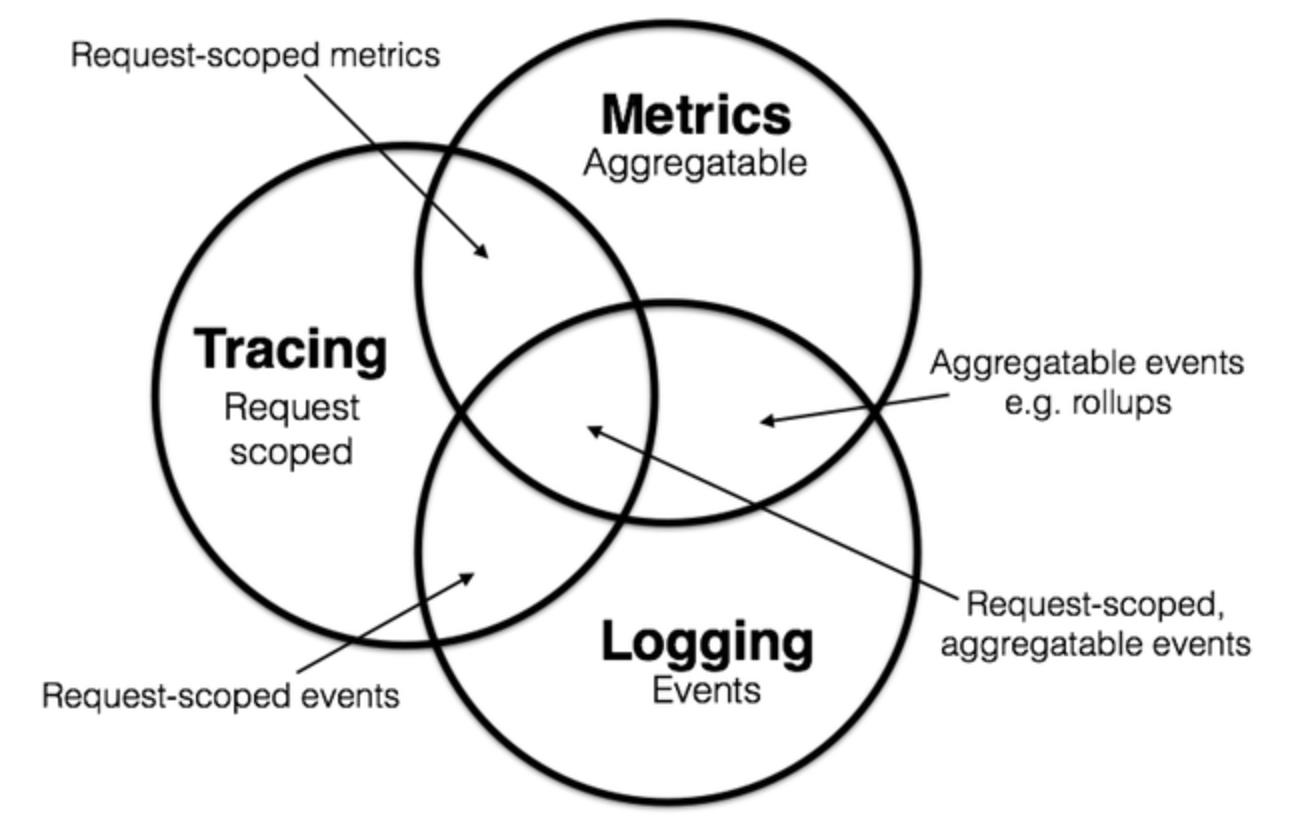
日志、追踪和度量(图片来源)
日志(Logging)
定义:
日志用来记录系统运行期间发生过的离散事件(时间随机、状态离散的事件)。主要包括记录事件发生的时间和事件发生时系统上下文的一些有效信息。日志对于生产系统来说是非常重要的,特别是当系统发生异常错误时,程序员就可以根据日志内容来排查问题并解决问题。
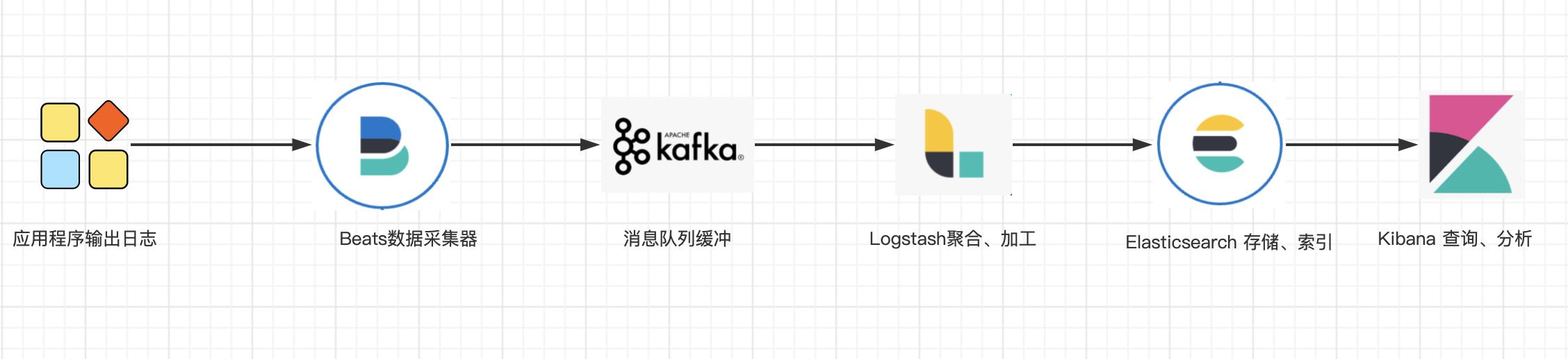
对于开发人员来说打印日志也许是很简单的,但是对于一个复杂的分布式系统,面对成千上万的服务节点,和快速产生的事件信息,仅仅打印日志还是不够的,如何收集日志,如何存储日志,以及如何分析日志都非常有挑战的事情。当然市面上已经有了一些优秀的开源产品可供我们选择,具体如下:

在上述的开源产品中,目前业界比较通用的是 Elastic Stack(ELK)技术栈,Fluentd 作为 CNCF 下的开源项目,发展也很快,未来会有取代 Logstash 的可能。
常见的日志处理过程:
追踪(Tracing)
定义:
追踪通常也被称为全链路追踪,表示请求通过系统时所经过的旅程。对于单体应用来说基本上指的是程序调用栈追踪。对于分布式系统来说,一个请求通常要经过若干个服务节点,此时的追踪是记录请求所经过的每一个服务节点的调用轨迹。记录的数据通常包含,一次请求随着时间的全链路调用过程,以及每段处理请求的耗时等信息,最终形成一个追踪树。如下图所示:

追踪链路时间图(图片来源)
在分布式系统中,通过全链路追踪我们可以很快的找出一个请求处理主要耗时在哪个阶段,找到系统性能瓶颈,然后有针对性的优化程序。同样也可以找到请求是在哪里出错的,提高排查故障的效率。
追踪系统也常被称为“APM 系统”(Application Performance Management),通常包含数据收集、数据存储和数据展示。国内比较知名的开源产品是 SkyWalking ,下面是一些比较优秀的开源产品:
图片来源
度量(Metrics)
定义:
度量是指对系统中某类信息的统计聚合。通常来说是收集一些比较关注的指标,这些指标能够反应系统的整体运行状况。
像 Java 就提供了基本的度量,可以通过 JMX(Java Management Extensions)来监控程序的运行状态,并获取一些度量数据,比如内存使用情况、垃圾回收情况、线程数等信息。度量的主要作用就是监控和预警,当某些指标到达预警值时,可以自动触发告警以通知相关责任人员及时介入。
度量系统可以大致分为目标系统指标数据收集、指标数据存储以及数据可视化和告警三大方面。度量方面比较优秀的产品有老牌的 zabbix,以及即将成为云原生时代下的度量监控标准的 Prometheus。下面是
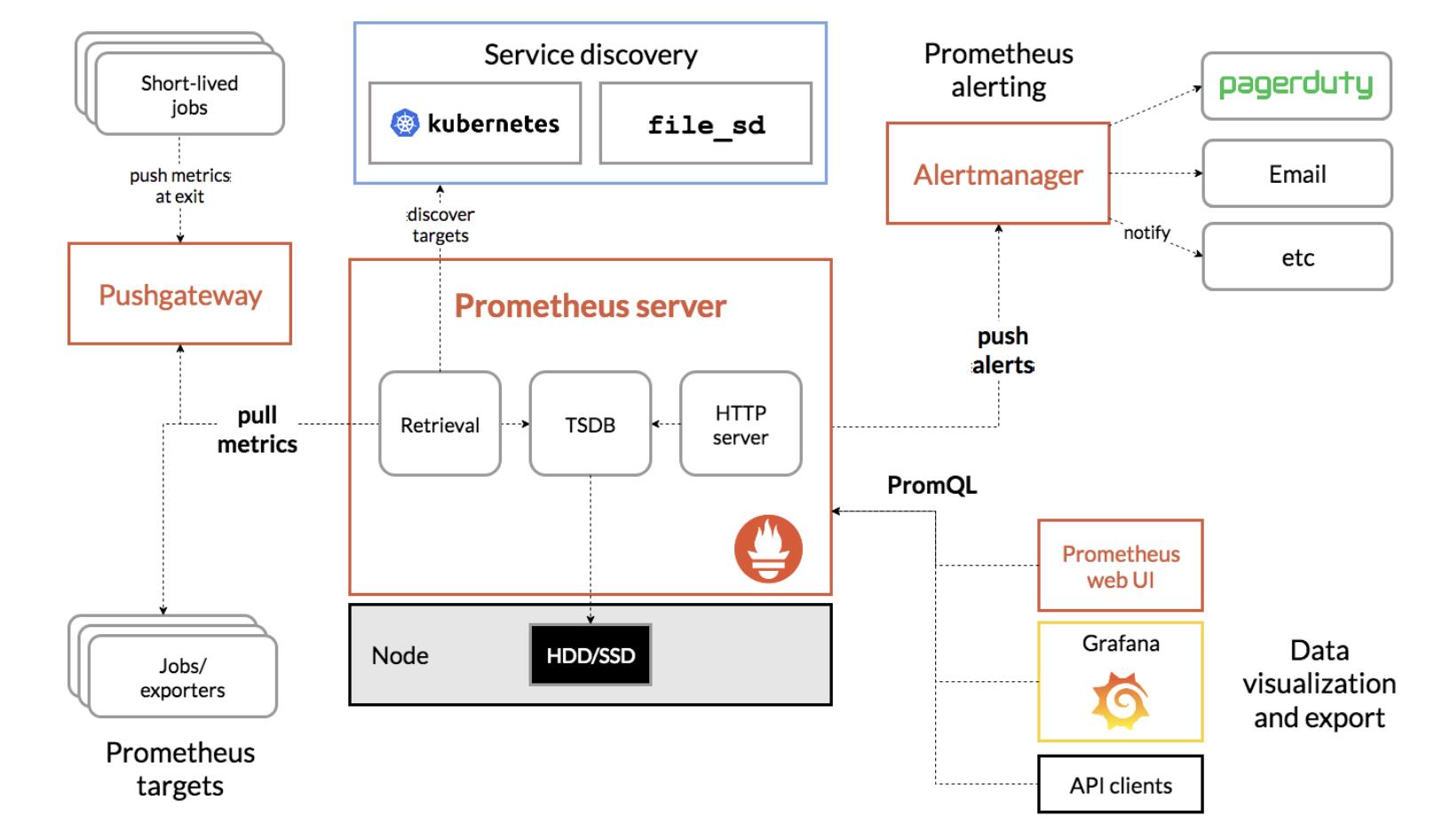
Prometheus 架构及生态组件(图片来源)
优秀的一些开源产品:
图片来源
可观测性发展趋势
OpenTelemetry 逐渐成为行业标准
在现有可观测性开源框架下,日志、追踪、度量分别是三个系统,它们之间的联系甚少。当系统出现问题时,程序员往往需要在三个系统间来回切换,而且需要程序员自己去思考寻找问题在三个系统间的关联性。
例如某个时间突然某个指标告警,那么程序员将会在度量系统中查看这个指标的一些信息,及指标数据发展趋势,哪个时间段发生等信息。然后大脑就会飞速运转猜测可能造成指标异常的原因,再去日志系统、追踪系统去排查更详细的信息,日志系统和追踪系统之间还要推测思考它们之间的关联性。
从上述的一个排查问题的过程可以看出,如果有一个系统可以形成一个最终的结果是一个单一的、可遍历的图,包含了描述分布式系统状态所需的所有数据,这种类型的数据结构将给分析工具一个完整的系统视图。那么排查问题将变得更加高效和便捷。日志、追踪和度量“三根支柱”不再是相互独立的系统,而是相互连接数据的一股绳,彼此之间互相关联。
OpenTelemetry 因此诞生。OpenTelemetry,也简称为OTel,是一个中立的开源的可观测性框架,由一系列工具、API 和 SDK 组成,用于检测、生成、收集和导出遥测数据,如 轨迹、指标、日志,以进行分析和了解软件性能和行为。它的目标是统一追踪、度量和日志三大领域。作为云原生计算基金会 (CNCF) 的孵化项目,OTel 旨在提供与供应商无关的统一库和 API 集。下面是 OpenTelemetry 架构图。
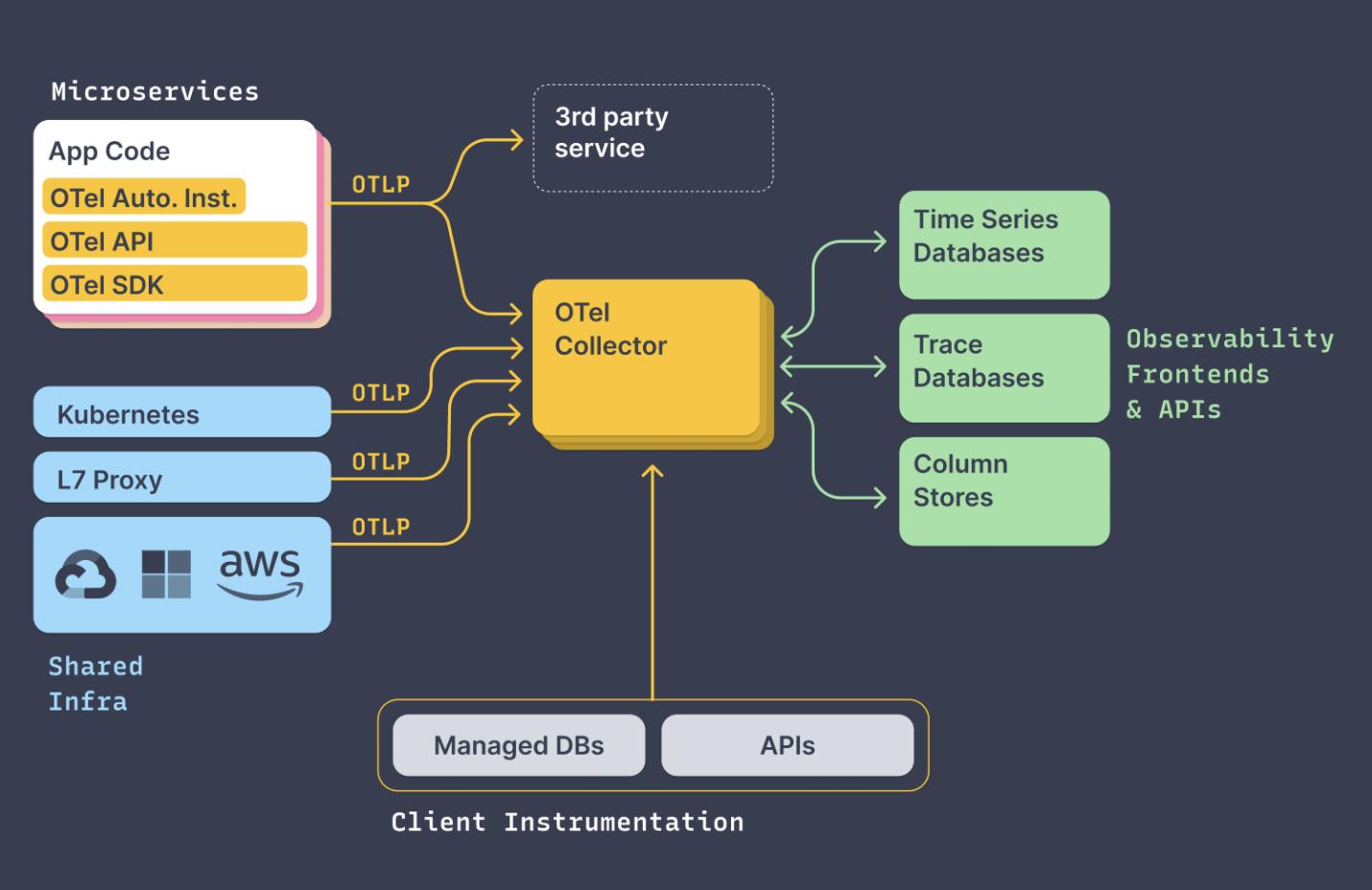
OpenTelemetry 架构(图片来源)
参考引用
1、Metrics, tracing, and logging
2、凤凰架构
以上是关于可观测性介绍的主要内容,如果未能解决你的问题,请参考以下文章