《Kubernetes权威指南:从Docker到Kubernetes实践全接触》读书笔记
Posted 山河已无恙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Kubernetes权威指南:从Docker到Kubernetes实践全接触》读书笔记相关的知识,希望对你有一定的参考价值。
写在前面
- 之前简单的了解过,但是机器的原因,只有单机,因为安装Docker的原因,本机VM上的红帽节点起不来了。懂得不多,视频上都是多节点的,所以教学视屏上的所以Demo没法搞。
- 前些时间公司的一个用K8s搞得项目要做安全测试,结果连服务也停不了。很无力。所以刷这本书,系统学习下。
- 博客主要是读书笔记。在更新。。。。。。
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
第1章Kubernetes入门
1.1 Kubernetes是什么?
首先,它是一个全新的基于容器技术的分布式架构领先方案。这个方案虽然还很新,但它是谷歌十几年以来大规模应用容器技术的经验积累和升华的一个重要成果。
使用Kubernetes提供的解决方案,我们不仅节省了不少于30%的开发成本,同时可以将精力更加集中于业务本身,而且由于Kubernetes提供了强大的自动化机制,所以系统后期的运维难度和运维成本大幅度降低。
Kubermetes平台对现有的编程语言、编程框架、中间件没有任何侵入性,因此现有的系统也很容易改造升级并迁移到Kubernetes平台上。
最后, Kubermetes是一个完备的分布式系统支撑平台。Kubernetes具有完备的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、内建智能负载均衡器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制,以及多粒度的资源配额管理能力。
Kubermetes提供了完善的管理工具,这些工具涵盖了包括开发、部署测试、运维监控在内的各个环节
Kubernetes是一个全新的基于容器技术的分布式架构解决方案,并且是一个一站式的完备的分布式系统开发和支撑平台。
Kubermetes的一些基本知识,在Kubermetes 中, Service (服务)是分布式集群架构的核心,一个Service对象拥有如下关键特征。
- 拥有一个唯一指定的名字(比如mysgq-server).
- 拥有一个虚拟IP (Cluster IP, Service IP或VIP)和端口号。
- 能够提供某种远程服务能力。
- 被映射到了提供这种服务能力的一组容器应用上。
Kubemetes能够让我们通过Service (虚拟Cluster IP +Service Port)连接到指定的Service上。有了Kubernetes内建的透明负载均衡和故障恢复机制,不管后端有多少服务进程,也不管某个服务进程是否会由于发生故障而重新部署到其他机器,都不会影响到我们对服务的正常调用。
容器提供了强大的隔离功能,所以有必要把为 Service 提供服务的这组进程放入容器中进行隔离。为此, Kubemetes 设计了Pod 对象,将每个服务进程包装到相应的Pod中,使其成为Pod中运行的一个容器( Container )。
为了建立 Service &&Pod 间的关联关系, Kubemetes 首先给每Pod 贴上 个标签(Label),类似于html中,给元素定义属性。然后给相应的 Service定义标签选择器( Label Selector ),比如 mysql Service 的标签选择器的选择条件为 name=mysql ,意为该 Service 要作用于所有包含 name=mysql的
Label Pod 这样 来,就巧妙地解决了 Service Pod 的关联问题
到
Pod,我们这里先简单说说其概念:
-
Pod运行在一个我们称之为节点(Node)的环境中,这个节点既可以是物理机,也可以是私有云或者公有云中的虚拟机,通常在一个节点上运行几百个Pod: -
每个
Pod里运行着 个特殊的被称之为Pause的容器,其他容器则为业务容器,这些业务容器共享 Pause 容器的网络栈和Volume 挂载卷因此它们之间的通信和数据交换更为高效,在设计时我们可以充分利用这特性将一组密切相关的服务进程放入同一 Pod 中。 -
并不是每个 Pod 和它里面运行的容器都能“映射”到Service 上,只有那些提供服务(无论是对内还是对外)的 Pod 才会被“映射”成服务。
在
集群管理方面, Kubemetes 将集群中的机器划分为Master节点和一群工作节点(Node)
- 在
Master 节点上运行着集群管理相关的组进程kube-apiserver,kube-controller-manager,kube-scheduler,这些进程实现了整个集群的资源管理、 Pod 调度、弹性伸缩、安全控制、系统监控和纠错等管理功能,且都是全自动完成的。 - Node 作为集群中的工作节点,运行真正的应用程序,在 Node上 Kubemetes 管理的最小运行单元是 Pod ,Node 上运行着 Kubemetes的
kubelet,kube-proxy服务进程,这些服务进程负责 Pod 的创建、启动、监控、重启、销毁,以及实现软件模式的负载均衡器。
传统的 IT 系统中服务扩容和服务升级这两个难题在k8s中的解决
Kubemetes 集群中,你只需为需要扩容的 Service 关联的 Pod 创建一个 RC(Replication
Con oiler ),则该 Service 的扩容以至于后来的 Service 升级等头疼问题都迎刃而解 .
RC定义文件中包括以下 3 个关键信息。
- 目标 Pod 的定义
- 目标 Pod 需要运行的副本数量(Replicas )。
- 要监控的目标 Pod 的标签( Label)
在创建好RC (系统将自动创建好Pod)后, Kubernetes会通过RC中定义的Label筛选出对应的Pod实例并实时监控其状态和数量,如果实例数量少于定义的副本数量(Replicas),则·会根据RC中定义的Pod模板来创建一个新的Pod,然后将此Pod调度到合适的Node上启动运行,直到Pod实例的数量达到预定目标。这个过程完全是自动化的,. 服务的扩容就变成了一个纯粹的简单数字游戏了,只要修改 RC 中的副本数量即可。后续的Service 升级也将通过修改 RC 来自动完成。
1.2 为什么要用 Kubernetes
使用 Kubemetes 的理由很多,最根本的一个理由就是: IT 从来都是 个由新技术驱动的行业。
Kubemetes 作为当前唯一被业界广泛认可和看好的Docker 分布式系统解决方案,
使用了 Kubemetes 又会收获哪些好处呢?
- 在采用Kubemetes 解决方案之后,只需个1精悍的小团队就能轻松应对
- 使用 Kubemetes 就是在全面拥抱微服务架构。微服务架构的核心是将 个巨大的单体应用分解为很多小的互相连接的微服务,一个微服务背后可能有多个实例副本在支撑,副本的数量可能会随着系统的负荷变化而进行调整,内嵌的负载均衡器在这里发挥了重要作用
- 系统可以随时随地整体“搬迁”到公有云上。
- Kubemetes 系统架构具备了超强的横向扩容能力。利用 ubemetes 提供的工具,甚至可以在线完成集群扩容 只要我们的微服务设计得好,结合硬件或者公有云资源的线性增加,系统就
能够承受大 用户并发访问所带来的巨大压力。
1.3 从一个简单的例子开始
Java Web 应用的结构比较简单,是一个运行在 Tomcat 里的 Web App。
此应用需要启动两个容器: Web App容器和MySQL容器,并且Web App容器需要访问MySQL容器。
在Docker时代,假设我们在一个宿主机上启动了这两个容器,
则我们需要把MySQL容器的IP地址通过环境变量的方式注入Web App容器里;同时,需要将Web App容器的8080端口映射到宿主机的8080端口,以便能在外部访问。
在Kubernetes时代是如何完成这个目标的。
1.3.1环境准备
# 关闭CentoS自带的防火墙服务:
systemctl disable firewalld --now
systemctl status firewalld
# 安装etcd和Kubernetes软件(会自动安装Docker软件):
yum install -y etcd kubernetes
#按顺序启动所有的服务:
systemctl start etcd
systemctl start docker
systemctl start kube-apiserver
systemctl start kube-controller-manager
systemctl start kube-scheduler
systemctl start kubelet
systemctl start kube-proxy
# 查看服务状态
systemctl status etcd docker kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy
至此,一个单机版的Kubernetes集群环境就安装启动完成了。接下来,我们可以在这个单机版的Kubernetes集群中上手练习了。
书里镜像相关地址: https://hub.docker.com/u/kubeguide/.
1.3.2启动MySQL服务
首先为MySQL服务创建一个
RC定义文件:mysql-rc.yaml,文件的完整内容和解释;
apiVersion: v1
kind: ReplicationController #副本控制器RC
metadata: # RC的名称,全局唯一
name: mysql # Pod副本期待数量
spec:
replicas: 1
selector: # 符合目标的Pod拥有此标签
app: mysql # 根据此模板创建Pod的副本(实例).
template:
metadata: #Pod副本拥有的标签,对应RC的Selector
labels:
app: mysql
spec:
containers: # Pod内容器的定义部分
- name: mysql # 容器的名称,容器对应的Docker Image
image: mysql
ports: #容器应用监听的端口号
- containerPort: 3306
env: #注入容器内的环境变量
- name: MYSQL_ROOT_PASSWORD
value: "123456"

yaml定义文件中
kind属性,用来表明此资源对象的类型,比如这里的值为"ReplicationController",表示这是一个RC:spec一节中是RC的相关属性定义,比如spec.selector是RC的Pod标签(Label)选择器,即监控和管理拥有这些标签的Pod实例,确保当前集群上始终有且仅有replicas个Pod实例在运行,这里我们设置replicas=1表示只能运行一个MySQL Pod实例。- 当集群中运行的
Pod数量小于replicas时, RC会根据spec.template一节中定义的Pod模板来生成一个新的Pod实例,spec.template.metadata.labels指定了该Pod的标签. - 需要特别注意的是:这里的
labels必须匹配之前的spec.selector,否则此RC每次创建了一个无法匹配Label的Pod,就会不停地尝试创建新的Pod。
[root@liruilong k8s]# kubectl create -f mysql-rc.yaml
replicationcontroller "mysql" created
E:\\docker>ssh root@39.97.241.18
Last login: Sun Aug 29 13:00:58 2021 from 121.56.4.34
Welcome to Alibaba Cloud Elastic Compute Service !
^[[AHow would you spend your life?.I don t know, but I will cherish every minute to live.
[root@liruilong ~]# kubectl get rc
NAME DESIRED CURRENT READY AGE
mysql 1 1 1 1d
[root@liruilong ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql-q7802 1/1 Running 0 1d
[root@liruilong ~]#
嗯,这里刚开始搞得的时候是有问题的,
pod一直没办法创建成功,第一次启动容器时,STATUS一直显示CONTAINERCREATING,我用的是阿里云ESC单核2G+40G云盘,我最开始以为系统核数的问题,因为看其他的教程写的需要双核,但是后来发现不是,网上找了解决办法,一顿操作猛如虎,后来不知道怎么就好了。
- 有说基础镜像外网拉不了,只能用 docker Hub的,有说 ,权限的问题,还有说少包的问题,反正都试了,这里列出几个靠谱的解决方案
- https://blog.csdn.net/gezilan/article/details/80011905
- https://www.freesion.com/article/8438814614/
K8s 根据mysqlde RC的定义自动创建的Pod。由于Pod的调度和创建需要花费一定的时间,比如需要一定的时间来确定调度到哪个节点上,以及下载Pod里容器的镜像需要一段时间,所以一开始我们看到Pod的状态将显示为Pending。当Pod成功创建完成以后,状态最终会被更新为Running我们通过docker ps指令查看正在运行的容器,发现提供MySQL服务的Pod容器已经创建并正常运行了,此外,你会发现MySQL Pod对应的容器还多创建了一个来自谷歌的pause容器,这就是Pod的“根容器".
我们创建一个与之关联的Kubernetes Service 的定义文件 mysql-sve.yaml
apiVersion: v1
kind: Service # 表明是Kubernetes Service
metadata:
name: mysql # Service的全局唯一名称
spec:
ports:
- port: 3306 #service提供服务的端口号
selector: #Service对应的Pod拥有这里定义的标签
app: mysql
我们通过kubectl create命令创建Service对象。运行kubectl命令:
[root@liruilong k8s]# kubectl create -f mysql-svc.yaml
service "mysql" created
[root@liruilong k8s]# kubectl get svc
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql 10.254.155.86 <none> 3306/TCP 1m
[root@liruilong k8s]#
注意到MySQL服务被分配了一个值为10.254.155.86的Cluster IP地址,这是一个虚地址,随后, Kubernetes集群中其他新创建的Pod就可以通过Service的Cluster IP+端口号3306来连接和访问它了。
在通常情况下, Cluster IP是在Service创建后由Kubernetes系统自动分配的,其他Pod无法预先知道某个Service的Cluster IP地址,因此需要一个服务发现机制来找到这个服务。
为此,最初时, Kubernetes巧妙地使用了Linux环境变量(Environment Variable)来解决这个问题,后面会详细说明其机制。现在我们只需知道,根据Service的唯一名字,容器可以从环境变量中获取到Service对应的Cluster IP地址和端口,从而发起TCP/IP连接请求了。
1.3.3启动Tomcat应用
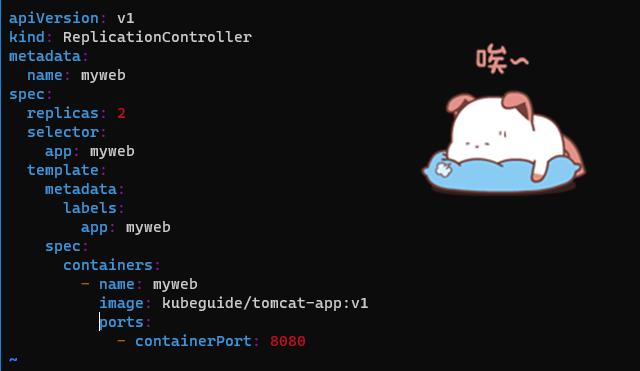
创建对应的 RC文件 myweb-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
spec:
replicas: 2
selector:
app: myweb
template:
metadata:
labels:
app: myweb
spec:
containers:
- name: myweb
image: kubeguide/tomcat-app:v1
ports:
- containerPort: 8080
[root@liruilong k8s]# vim myweb-rc.yaml
[root@liruilong k8s]# kubectl create -f myweb-rc.yaml
replicationcontroller "myweb" created
[root@liruilong k8s]# kubectl get rc
NAME DESIRED CURRENT READY AGE
mysql 1 1 1 1d
myweb 2 2 0 20s
[root@liruilong k8s]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql-q7802 1/1 Running 0 1d
myweb-53r32 0/1 ContainerCreating 0 28s
myweb-609w4 0/1 ContainerCreating 0 28s
[root@liruilong k8s]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql-q7802 1/1 Running 0 1d
myweb-53r32 1/1 Running 0 1m
myweb-609w4 1/1 Running 0 1m
[root@liruilong k8s]#
最后,创建对应的 Service 。以下是完整yaml定义文件 myweb-svc.yaml:
apiVersion: v1
kind: Service
metadata:
name: myweb
spec:
type: NodePort
ports:
- port: 8080
nodePort: 30001
selector:
app: myweb

[root@liruilong k8s]# vim myweb-svc.yaml
[root@liruilong k8s]# kubectl create -f myweb-svc.yaml
service "myweb" created
[root@liruilong k8s]# kubectl get services
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 10.254.0.1 <none> 443/TCP 2d
mysql 10.254.155.86 <none> 3306/TCP 5h
myweb 10.254.122.63 <nodes> 8080:30001/TCP 54s
[root@liruilong k8s]#
1.3.4通过浏览器访问网页
[root@liruilong k8s]# curl http://127.0.0.1:30001/demo/
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>HPE University Docker&Kubernetes Learning</title>
</head>
<body align="center">
<h3> Error:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server.</h3>
</body>
</html>
数据库连接有问题,这里百度发现是mysql驱动版本问题
[root@liruilong k8s]# docker logs a05d16ec69ff
[root@liruilong k8s]# vim mysql-rc.yaml
apiVersion: v1
kind: ReplicationController #副本控制器RC
metadata: # RC的名称,全局唯一
name: mysql # Pod副本期待数量
spec:
replicas: 1
selector: # 符合目标的Pod拥有此标签
app: mysql # 根据此模板创建Pod的副本(实例).
template:
metadata: #Pod副本拥有的标签,对应RC的Selector
labels:
app: mysql
spec:
containers: # Pod内容器的定义部分
- name: mysql # 容器的名称,容器对应的Docker Image
image: mysql:5.7
ports: #容器应用监听的端口号
- containerPort: 3306
env: #注入容器内的环境变量
- name: MYSQL_ROOT_PASSWORD
value: "123456"
[root@liruilong k8s]# kubectl delete -f mysql-rc.yaml
replicationcontroller "mysql" deleted
[root@liruilong k8s]# kubectl create -f mysql-rc.yaml
replicationcontroller "mysql" created
[root@liruilong k8s]# kubectl get rc
NAME DESIRED CURRENT READY AGE
mysql 1 1 0 10s
myweb 2 2 2 4h
[root@liruilong k8s]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql-2cpt9 0/1 ContainerCreating 0 15s
myweb-53r32 1/1 Running 0 4h
myweb-609w4 1/1 Running 1 4h
[root@liruilong k8s]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql-2cpt9 0/1 ContainerCreating 0 32s
myweb-53r32 1/1 Running 0 4h
myweb-609w4 1/1 Running 1 4h
[root@liruilong k8s]#
Digest: sha256:7cf2e7d7ff876f93c8601406a5aa17484e6623875e64e7acc71432ad8e0a3d7e
Status: Downloaded newer image for docker.io/mysql:5.7
[root@liruilong k8s]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql-2cpt9 1/1 Running 0 31m
myweb-53r32 1/1 Running 0 5h
myweb-609w4 1/1 Running 1 5h
[root@liruilong k8s]# curl http://127.0.0.1:30001/demo/
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>HPE University Docker&Kubernetes Learning</title>
</head>
<body align="center">
<h2>Congratulations!!</h2>
<br></br>
<input type="button" value="Add..." onclick="location.href='input.html'" >
<br></br>
<TABLE align="center" border="1" width="600px">
<TR>
<TD>Name</TD>
<TD>Level(Score)</TD>
</TR>
<TR>
<TD>google</TD>
<TD>100</TD>
</TR>
<TR>
<TD>docker</TD>
<TD>100</TD>
</TR>
<TR>
<TD>teacher</TD>
<TD>100</TD>
</TR>
<TR>
<TD>HPE</TD>
<TD>100</TD>
</TR>
<TR>
<TD>our team</TD>
<TD>100</TD>
</TR>
<TR>
<TD>me</TD>
<TD>100</TD>
</TR>
</TABLE>
</body>
</html>
1.4 Kubernetes基本概念和术语
Kubernetes中的大部分概念如Node, Pod,Replication Controller, Service等都可以看作一种“资源对象”,几乎所有的资源对象都可以通过Kubernetes提供的kubect工具(或者API编程调用)执行增、删、改、查等操作并将其保存在etcd中持久化存储。从这个角度来看,Kubernetes其实是一个高度自动化的资源控制系统,它通过跟踪对比etcd库里保存的“资源期望状态”与当前环境中的“实际资源状态”的差异来实现自动控制和自动纠错的高级功能。
Kubernetes集群的两种管理角色:
Master和Node.

1.4.1 Master
Kubernetes里的Master指的是集群控制节点,每个Kubernetes集群里需要有一个Master节点来负责整个集群的管理和控制,基本上Kubernetes的所有控制命令都发给它,它来负责具体的执行过程,我们后面执行的所有命令基本都是在Master节点上运行的。
Master节点通常会占据一个独立的服务器(高可用部署建议用3台服务器),其主要原因是它太重要了,是整个集群的“首脑”,如果宕机或者不可用,那么对集群内容器应用的管理都将失效。Master节点上运行着以下一组关键进程。
Kubernetes API Server (kube-apiserver):提供了HTTP Rest接口的关键服务进程,是Kubernetes里所有资源的增、删、改、查等操作的唯一入口,也是集群控制的入口进程。Kubernetes Controller Manager (kube-controller-manager): Kubernetes里所有资源对象的自动化控制中心,可以理解为资源对象的“大总管”。Kubernetes Scheduler (kube-scheduler):负责资源调度(Pod调度)的进程,相当于公交公司的“调度室”。
另外,在Master节点上还需要启动一个etcd服务,因为Kubernetes里的所有资源对象的数据全部是保存在etcd中的。
除了Master, Kubernetes集群中的其他机器被称为Node节点
1.4.2 Node
在较早的版本中也被称为Miniono与Master一样, Node节点可以是一台物理主机,也可以是一台虚拟机。 Node节点才是Kubermetes集群中的工作负载节点,每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机时,其上的工作负载会被Master自动转移到其他节点上去。 每个Node节点上都运行着以下一组关键进程。
kubelet:负责Pod对应的容器的创建、启停等任务,同时与Master节点密切协作,实现集群管理的基本功能。kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件。)Docker Engine(docker): Docker引擎,负责本机的容器创建和管理工作。
Node节点可以在运行期间动态增加到Kubernetes集群中,前提是这个节点上已经正确安装、配置和启动了上述关键进程,在默认情况下kubelet会向Master注册自己,这也是Kubernetes推荐的Node管理方式。
一旦Node被纳入集群管理范围, kubelet进程就会定时向Master节点汇报自身的情报,例如操作系统、Docker版本、机器的CPU和内存情况,以及当前有哪些Pod在运行等,这样Master可以获知每个Node的资源使用情况,并实现高效均衡的资源调度策略。而某个Node超过指定时间不上报信息时,会被Master判定为“失联", Node的状态被标记为不可用(Not Ready),随后Master会触发“工作负载大转移”的自动流程。
查看集群中的Node节点和节点的详细信息
[root@liruilong k8s]# kubectl get nodes
NAME STATUS AGE
127.0.0.1 Ready 2d
[root@liruilong k8s]# kubectl describe node 127.0.0.1
# Node基本信息:名称、标签、创建时间等。
Name: 127.0.0.1
Role:
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/hostname=127.0.0.1
Taints: <none>
CreationTimestamp: Fri, 27 Aug 2021 00:07:09 +0800
Phase:
# Node当前的运行状态, Node启动以后会做一系列的自检工作:
# 比如磁盘是否满了,如果满了就标注OutODisk=True
# 否则继续检查内存是否不足(如果内存不足,就标注MemoryPressure=True)
# 最后一切正常,就设置为Ready状态(Ready=True)
# 该状态表示Node处于健康状态, Master将可以在其上调度新的任务了(如启动Pod)
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
OutOfDisk False Sun, 29 Aug 2021 23:05:53 +0800 Sat, 28 Aug 2021 00:30:35 +0800 KubeletHasSufficientDisk kubelet has sufficient disk space available
MemoryPressure False Sun, 29 Aug 2021 23:05:53 +0800 Fri, 27 Aug 2021 00:07:09 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Sun, 29 Aug 2021 23:05:53 +0800 Fri, 27 Aug 2021 00:07:09 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
Ready True Sun, 29 Aug 2021 23:05:53 +0800 Sat, 28 Aug 2021 00:30:35 +0800 KubeletReady kubelet is posting ready status
# Node的主机地址与主机名。
Addresses: 127.0.0.1,127.0.0.1,127.0.0.1
# Node上的资源总量:描述Node可用的系统资源,包括CPU、内存数量、最大可调度Pod数量等,注意到目前Kubernetes已经实验性地支持GPU资源分配了(alpha.kubernetes.io/nvidia-gpu=0)
Capacity:
alpha.kubernetes.io/nvidia-gpu: 0
cpu: 1
memory: 1882012Ki
pods: 110
# Node可分配资源量:描述Node当前可用于分配的资源量。
Allocatable:
alpha.kubernetes.io/nvidia-gpu: 0
cpu: 1
memory: 1882012Ki
pods: 110
# 主机系统信息:包括主机的唯一标识UUID, Linux kernel版本号、操作系统类型与版本、Kubernetes版本号、kubelet与kube-proxy的版本号等。
System Info:
Machine ID: 963c2c41b08343f7b063dddac6b2e486
System UUID: EB90EDC4-404C-410B-800F-3C65816C0E2D
Boot ID: 4a9349b0-ce4b-4b4a-8766-c5c4256bb80b
Kernel Version: 3.10.0-1160.15.2.el7.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://1.13.1
Kubelet Version: v1.5.2
Kube-Proxy Version: v1.5.2
ExternalID: 127.0.0.1
# 当前正在运行的Pod列表概要信息
Non-terminated Pods: (3 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
default mysql-2cpt9 0 (0%) 0 (0%) 0 (0%) 0 (0%)
default myweb-53r32 0 (0%) 0 (0%) 0 (0%) 0 (0%)
default myweb-609w4 0 (0%) 0 (0%) 0 (0%) 0 (0%)
# 已分配的资源使用概要信息,例如资源申请的最低、最大允许使用量占系统总量的百分比。
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
0 (0%以上是关于《Kubernetes权威指南:从Docker到Kubernetes实践全接触》读书笔记的主要内容,如果未能解决你的问题,请参考以下文章