Redis核心知识点
Posted 热爱编程的大忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis核心知识点相关的知识,希望对你有一定的参考价值。
Redis核心知识点
- Redis核心知识点大全
整理的只是一部分核心知识点,不全。
Redis核心知识点大全
tips: 只列举核心知识点的概要,完整知识点可以参考 redis设计与实现一书以及随篇附上的文章链接
五种数据类型
1.字符串
- 常用命令:
set key val
get key
mset key1 val1 key2 val2 ...
mget key1 key2 ...
incr key1 #自增1
incrby key1 num #让key1自增num
setnx key val #key存在不执行,否则执行
setex key ttl val #指定过期时间
2.列表
- 常用命令:
lpush key val1 val2 ... #左侧插入多个元素
lpop key #从左边移除一个元素,没有元素返回nil
rpush key val1 val2 ... # 右侧插入多个元素
rpop key #右边移除一个元素
lrange key start end
blpop key timeout 和 brpop key timeout #弹出元素,如果列表为空就阻塞指定时间
3.集合
- 常用命令:
sadd key val1 val2 ....
srem key val1 val2 ... # 移除set中指定元素
scard key #返回set中元素个数
sismember key val1 #判断一个元素是否存在于set中
smembers key #获取set中所有元素
sinter key1 key2... # 求多个set集合之间的交集
sdiff key1 key2... # 求多个set集合之间的差集
sunion key1 key2... # 求讴歌set集合之间的并集
4.散列
常用命令:
hset hash-key field value
hget hash-key field
hmset hash-key field1 value1 field2 value2 ...
hmget hash-key field1 field2 ...
hgetall hash-key
hkeys hash-key
hvals hash-key
hincrby hash-key field num
hsetnx hash-key filed value #添加field成功的前提是不存在
5.有序集合
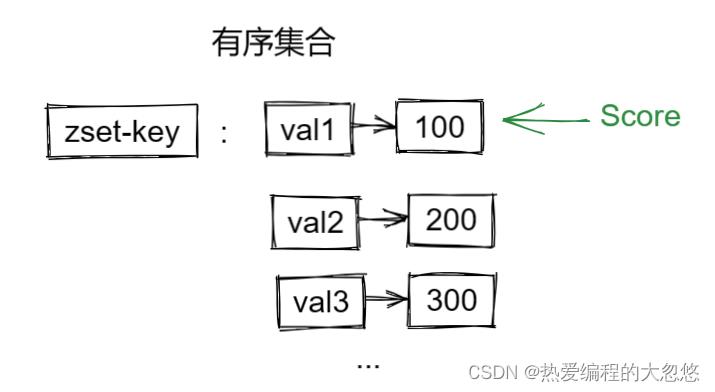
常用命令:
zadd zset-key score val # 还可以附加额外参数控制,参考官方文档
zrem zset-key val
zscore zset-key val # 获取某个val的score
zrank zset-key val # 获取某个val的排名
zcard zset-key #获取zset中的元素个数
zcount zset-key min max # 统计score在给定范围内的val个数
zincrby zset-key num val # 让指定val对应的score增加指定值
zrange key min max # 按照score排序后,获取指定排名范围内的元素
zrangebyscore key min max # 按照score排序后,获取指定score范围内的元素
zdiff,zinter,zunion #求差集,交集和并集
#注意: 所有的排名默认都是升序,如果要降序,在命令的Z后面添加REV即可
redis整合SpringBoot
序列化问题
RedisTemplate底层默认使用JDK序列化来将key和value输出为字节数组:
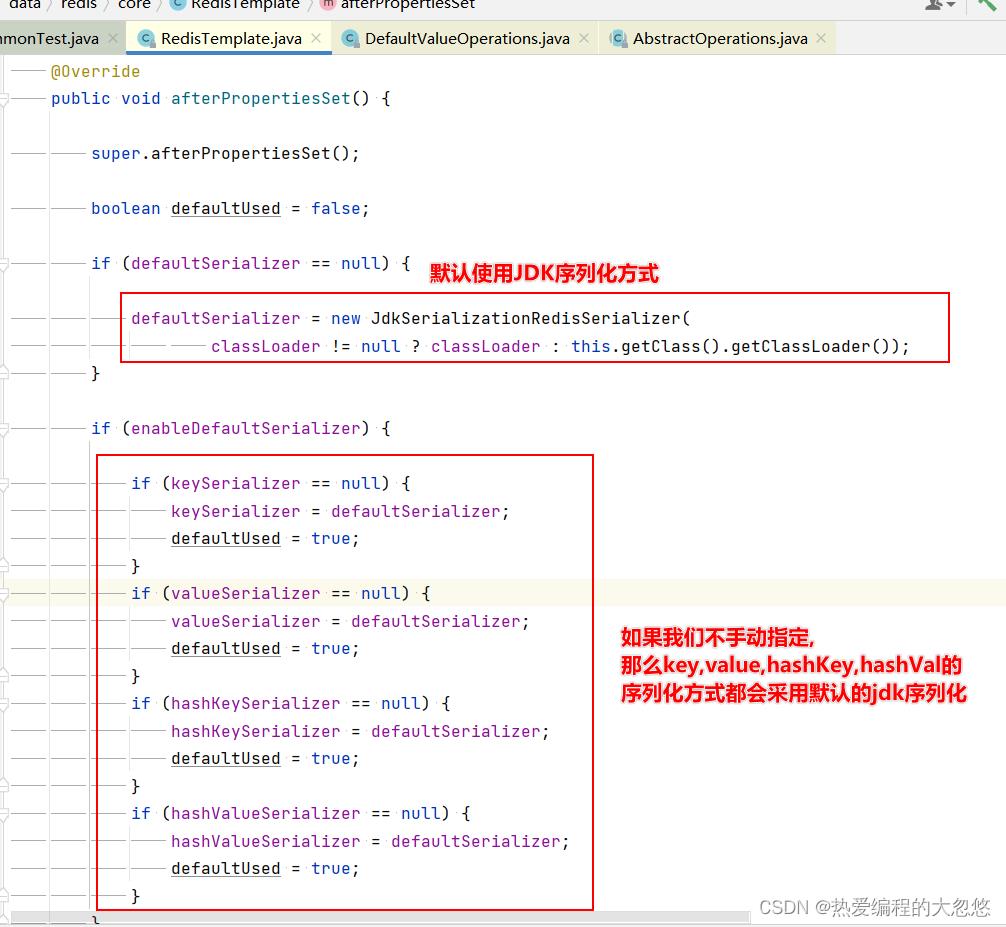
通过向容器中注入一个RedisTemplate替换默认的redis自动配置:
@Configuration
public class RedisConfig
@Bean
public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)
//创建template
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
//设置连接工厂
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
//key和hashKey采用String序列化
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
//value和hashValue用JSON序列化
redisTemplate.setValueSerializer(jsonRedisSerializer);
redisTemplate.setHashValueSerializer(jsonRedisSerializer);
return redisTemplate;
如果你的key也想存对象,那么就不要使用RedisSerializer.string(),转而使用jsonRedisSerializer
渐进式扫描
keys命令会遍历所有键,在数据量很大的情况下会阻塞redis主线程执行,并且还可能会造成网络拥塞。
scan命令采用渐进式遍历的方式来解决keys命令可能带来的阻塞问题,通过类似分页的处理方式,每次扫描一部分key。
scan cursor [match pattern] [count number]
- cursor是一个游标,第一次遍历从0开始,每次scan遍历完都会返回当前游标值,直到游标值为0,表示遍历结束
- match pattern是可选参数,过滤出符合条件的指定key
- count number指明每次遍历的键的个数,默认为10
Redis提供了面向哈希类型,集合类型,有序集合的扫描遍历命令:
- hgetall —> hscan
- smembers —> sscan
- zrange —> zscan
ps: 如果在scan过程中有键增删改变化,那么遍历过程可能会遇到新增的键没有遍历到,遍历出现重复键的情况,也就是说scan过程不保证完整遍历出来所有的键。
慢查询
redis执行一条命令的过程大体分为以下四个部分:
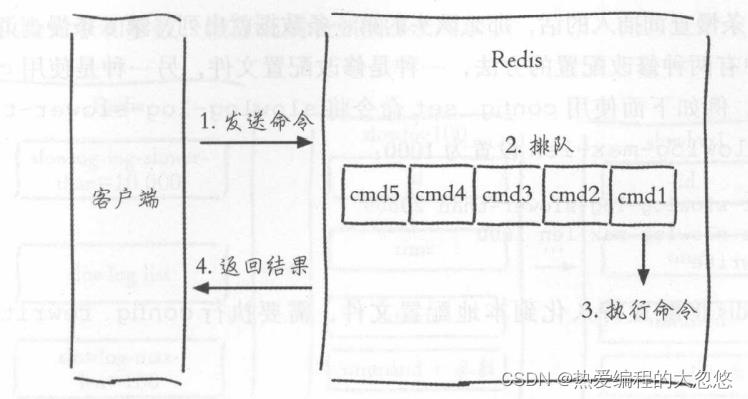
慢查询只统计第三步命令执行过程,所以没有慢查询不代表客户端没有超时问题。
我们需要关心慢查询两件事:
1.相关阈值如何设置?
- slowlog-log-slower-than : 默认值为10000 , 单位是微秒 , 如果某个命令执行时间超过了10毫秒,那么该命令会被记录在慢查询日志中。
slowlog-log-slower-than=0会记录所有命令,小于0不会记录任何命令
- slowlog-max-len: 说明慢查询日志最多存储多少条记录, redis使用一个列表来存储慢查询日志,该参数就是用来控制该列表的最大长度,一个新的慢查询命令被插入列表时,如果此时慢查询日志列表已经处于最大长度,那么最早插入的一个漫查询命令会从列表中移出 , 默认值为128。
在Redis中有两种修改配置的方法,一种是修改配置文件,另一种是使用config set命令动态修改:
config set slowlog-slower-than 20000
config set slowlog-max-len 1000
config rewrite
config rewrite命令负责将配置持久化到本地配置文件:
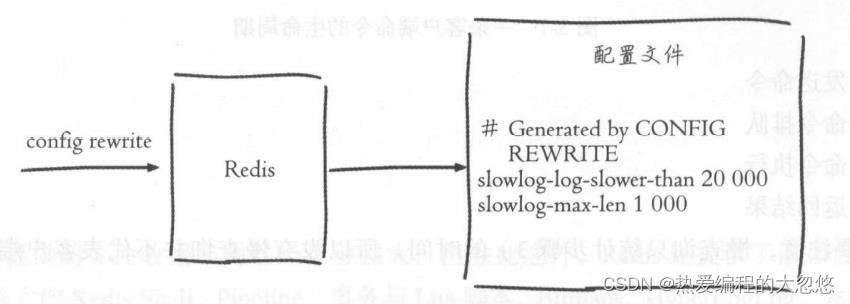
Redis没有暴露存储慢查询日志的列表键,我们只能通过下面一组命令来实现对慢查询日志的访问和管理:
-
获取慢查询日志
slowlog get [n]

每个慢查询日志由四部分组成:
-
慢查询日志标识id
-
发生时间戳
-
命令耗时
-
执行命令和参数
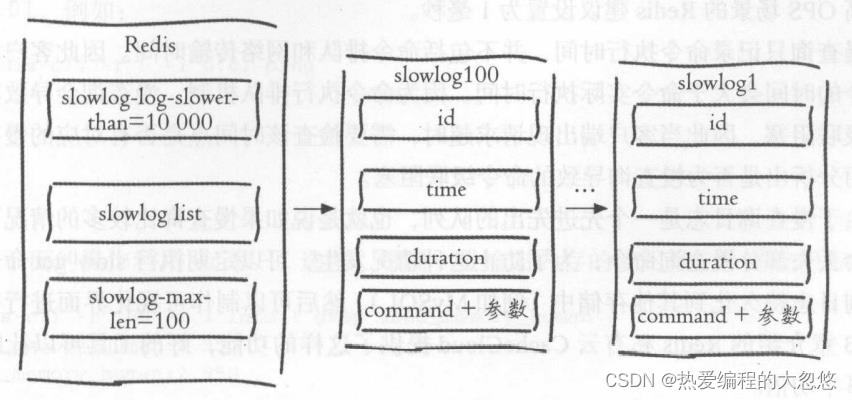
-
获取慢查询日志列表当前的长度
slowlog len -
慢查询日志重置
slowlog reset
缓存相关问题
数据库和缓存谁先更新
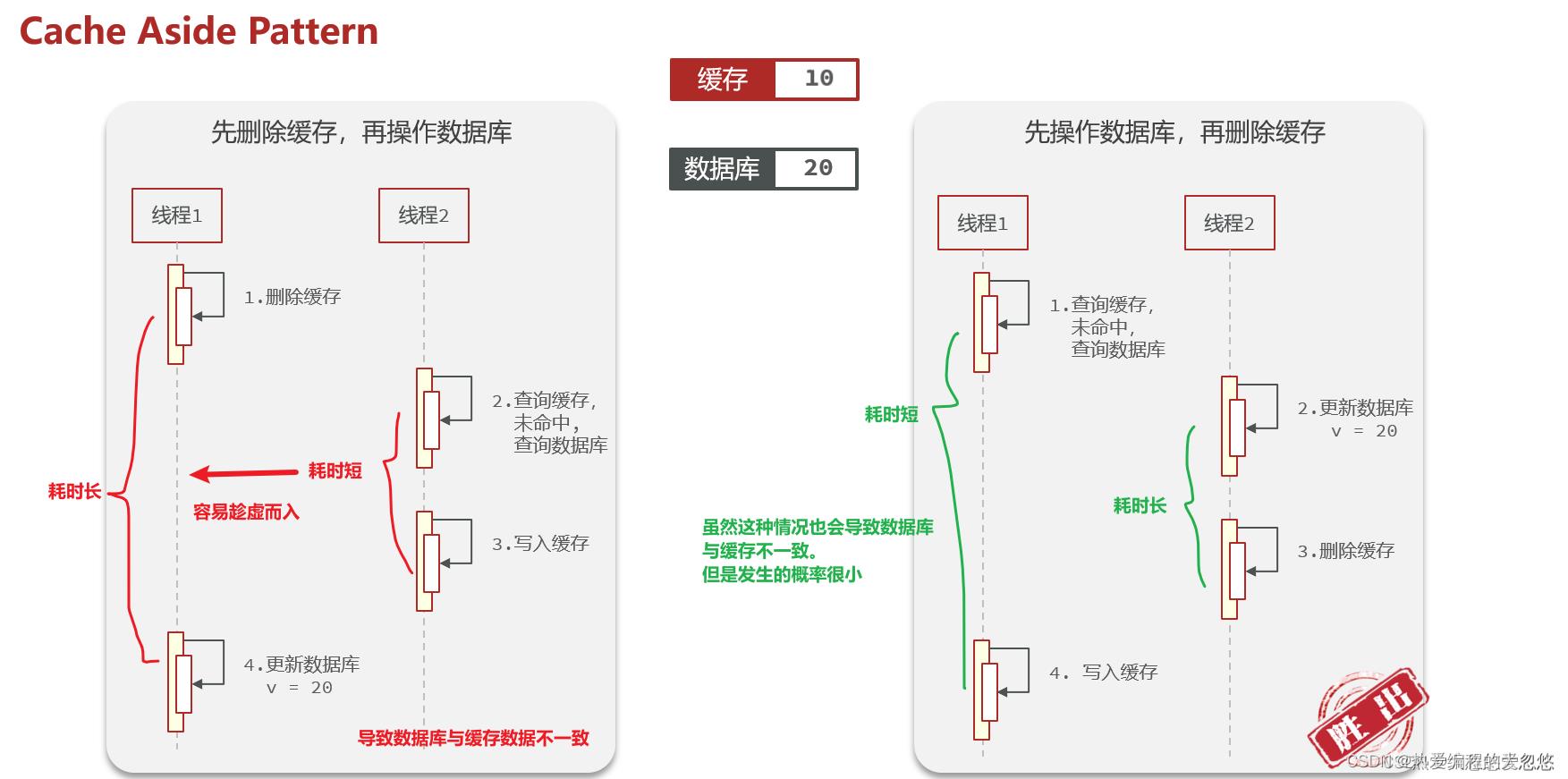
Innodb存储引擎采用了change buffer延迟写操作,这样一来写入更新操作未必一定比查询慢 ,如果buffer pool此时没有缓存对应页面,而需要从磁盘加载,那么查询速度反而会比更新慢。
缓存穿透
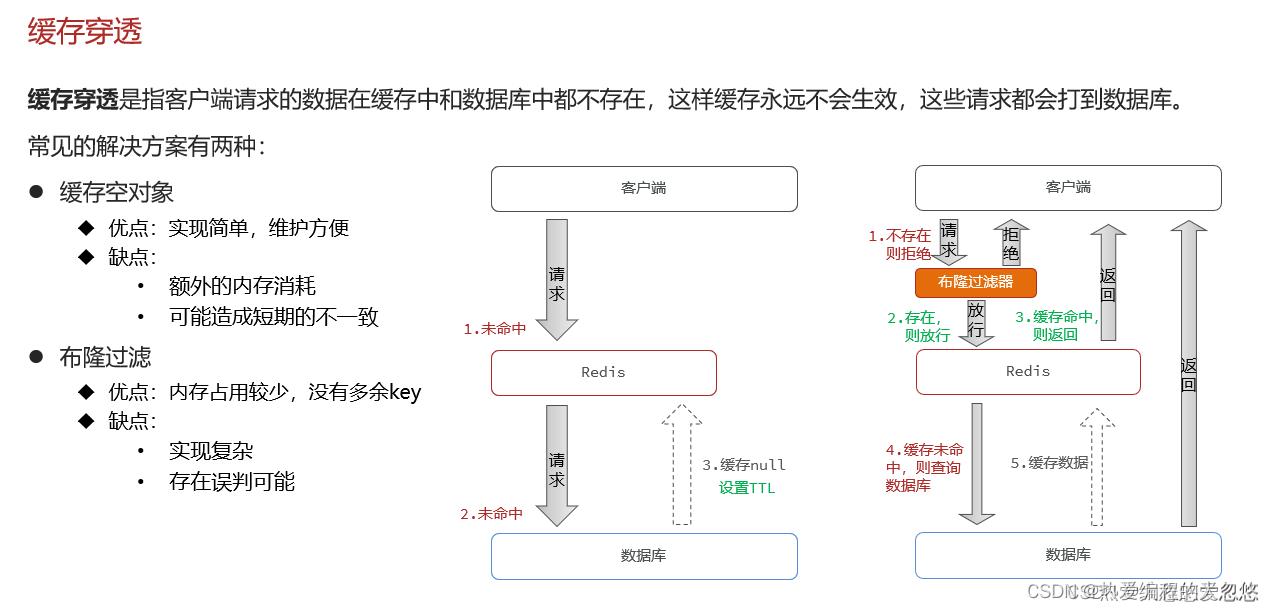
布隆过滤器的特点: 如果布隆过滤器告诉你某个key不存在,那么就一定不存在,如果说存在,那么可能存在也可能不存在。
在业务层面做好参数合法性校验,避免恶意攻击伪造的非法参数,同时拉黑攻击者的IP。
spring-cache模块默认是开启了缓存空对象功能的
缓存雪崩
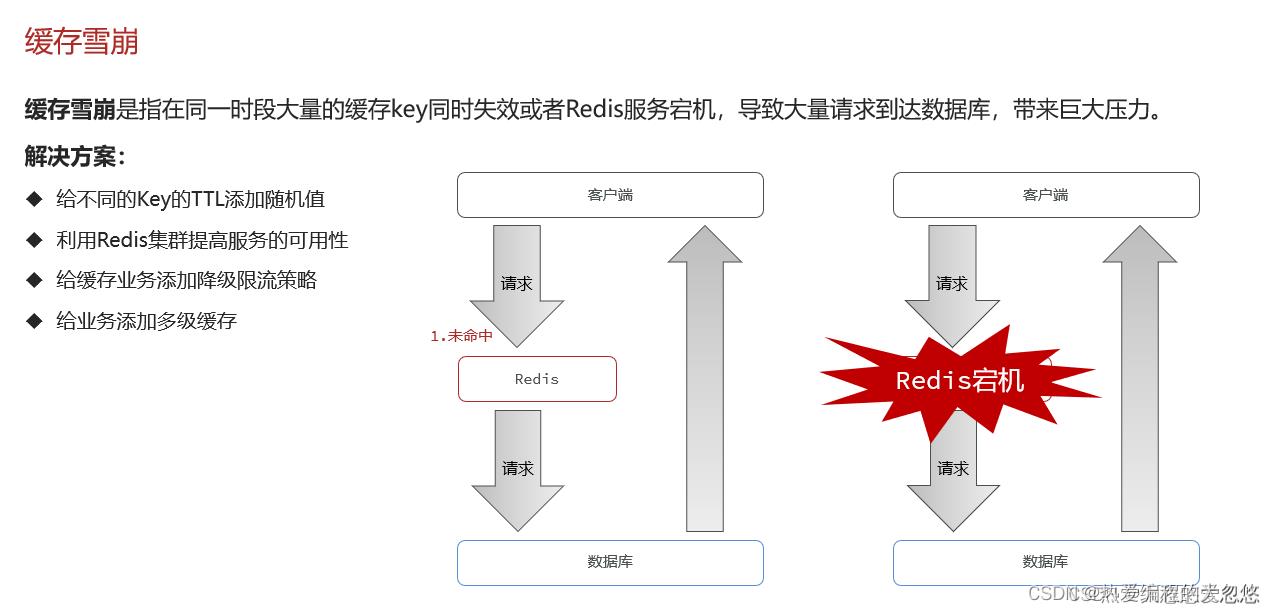
还可以利用定时任务定时刷新缓存过期时间。
缓存击穿
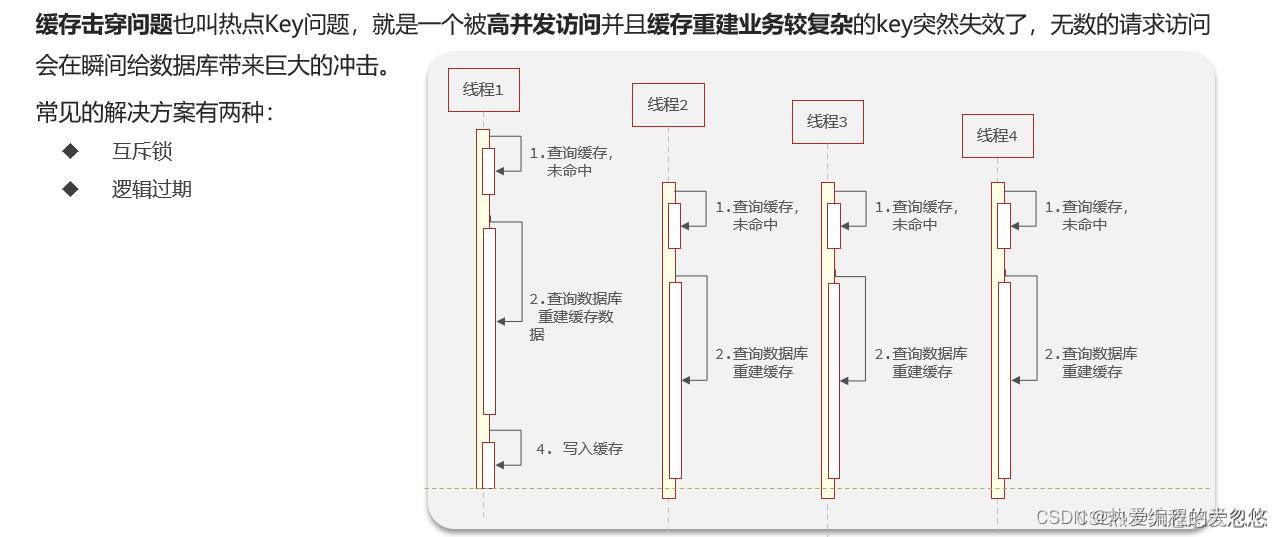
互斥锁和逻辑过期解决缓存击穿的思路
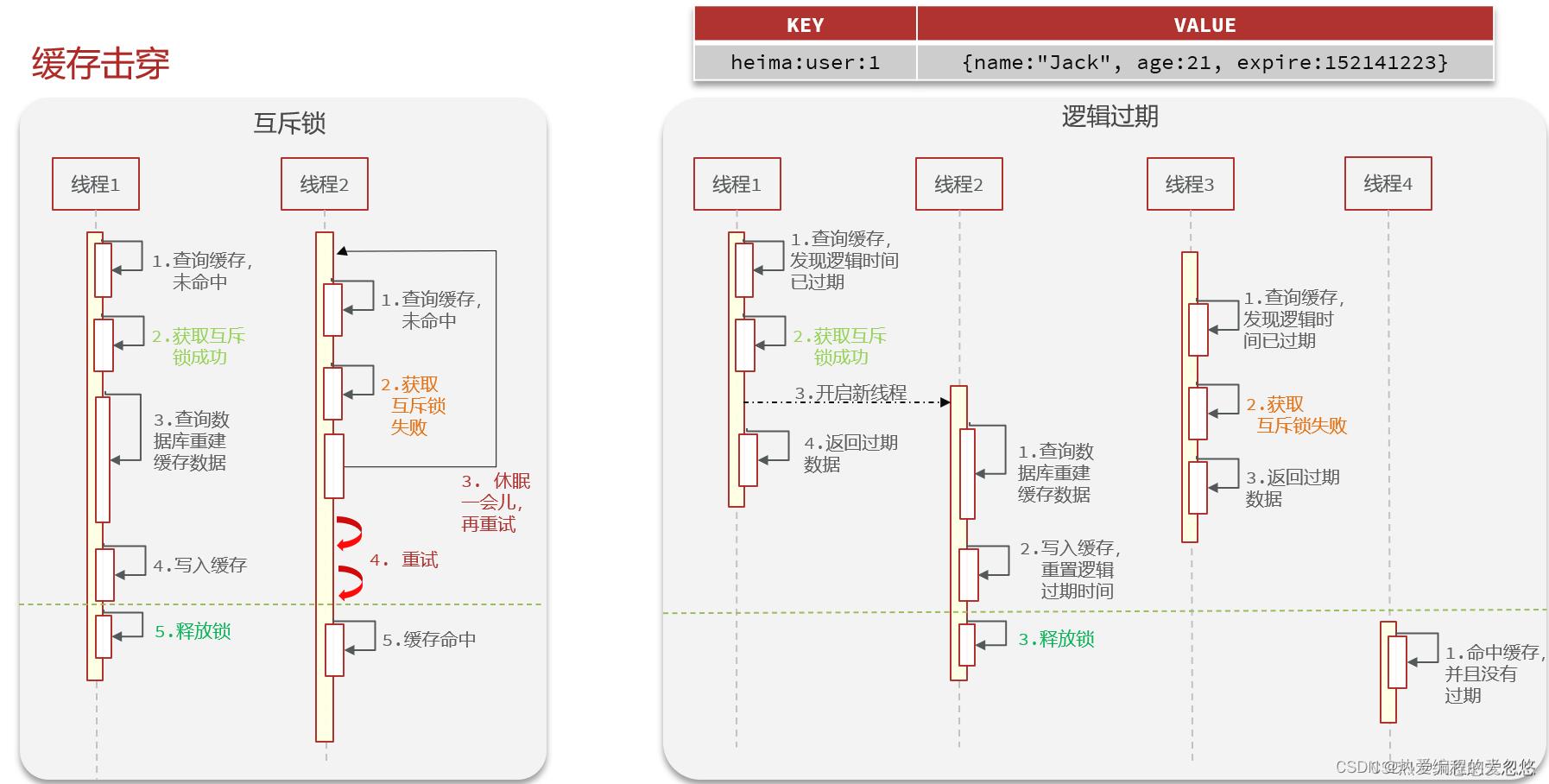
互斥锁的实现其实很简单,既然热点key过期失效了,并且同时有很多个请求打进来,尝试重构缓存,那么就用一把锁,只让第一个请求去重构缓存,其余的请求线程就等待加重试,直到缓存重构成功
而对于逻辑过期的思路来讲,既然是因为热点key过期导致的缓存击穿,那我我就让这些热点key不会真的过期,而通过增加一个逻辑过期字段,每一次获取的时候,先去判断是否过期,如果过期了,就按照上图的流程执行。
实际应用
超卖问题
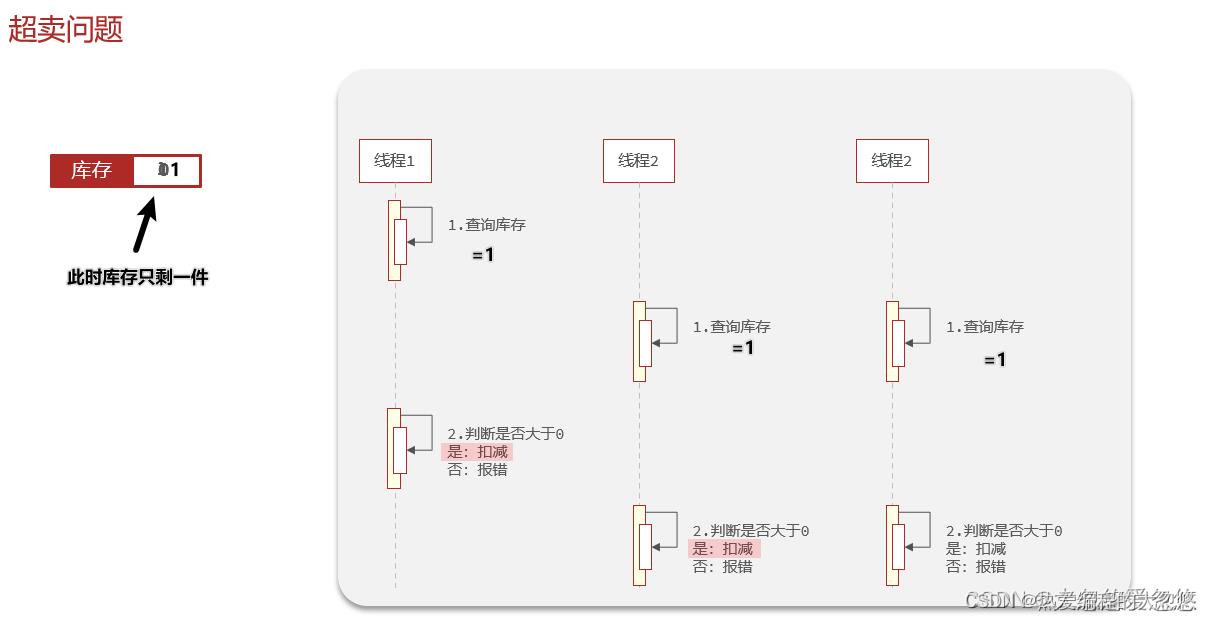
超卖问题实际是典型的 "查询-修改-写入"原子性问题。
- 乐观锁解决

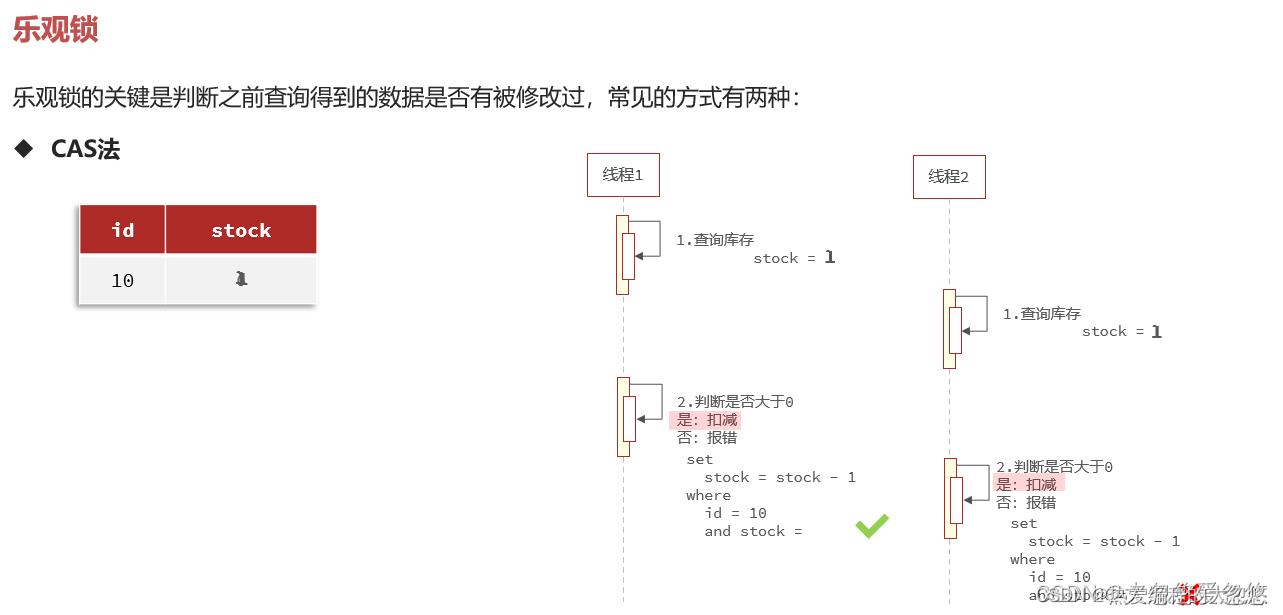
上面做法存在的问题在于多个线程同时购买商品时,只有一个线程能成功,即使在商品还剩余多份的情况下。
采用cas法时,可以stock=一开始查询出的stock值 改为 stock>0
分布式锁
超卖问题的悲观锁解法就是采用锁机制,而在分布式环境下肯定不能采用JVM级别的锁,需要采用分布式锁。
redis实现分布式锁最简单的方式就是采用setnx key val的方式 , 但是考虑到锁无法被释放的情况,需要给锁加上过期时间。
为了让获取锁和设置过期时间两个操作原子化执行,防止获取完锁后系统奔溃导致分布式锁无法被释放的情况发生,可以采用: set lock thread1 NX EX 10 的方式。
释放分布式锁时存在因为锁超时提前释放,导致锁被误删的情况发生, 解决这个问题的办法是给分布式锁加上标识, 可以是单个运行的程序实例通过一个特定的UUID加上当前线程ID作为锁标识进行区分,然后释放锁时判断当前锁是否还是自己持有,如果是才会进行释放。
释放锁时,判断标识和释放锁两个步骤如果不能原子化执行,也会存在锁被误删情况发生。
因此,最终我们采用lua脚本的方式,来确保释放锁的多条命令间的原子化执行。
在主从环境下,可能会因为主节点突然奔溃,导致分布式锁丢失情况发生,这样情况下可以考虑采用分片集群,通过联锁的方式解决上面的问题。
还包括锁重入问题,可以将存储锁的数据结构改为hash,从而可以额外存储一个锁计数,通过锁标识判断当前是否是锁重入,思路和jdk的可重入锁一致。
Redis进阶学习03—Redis完成秒杀和Redis分布式锁的应用
全局唯一ID
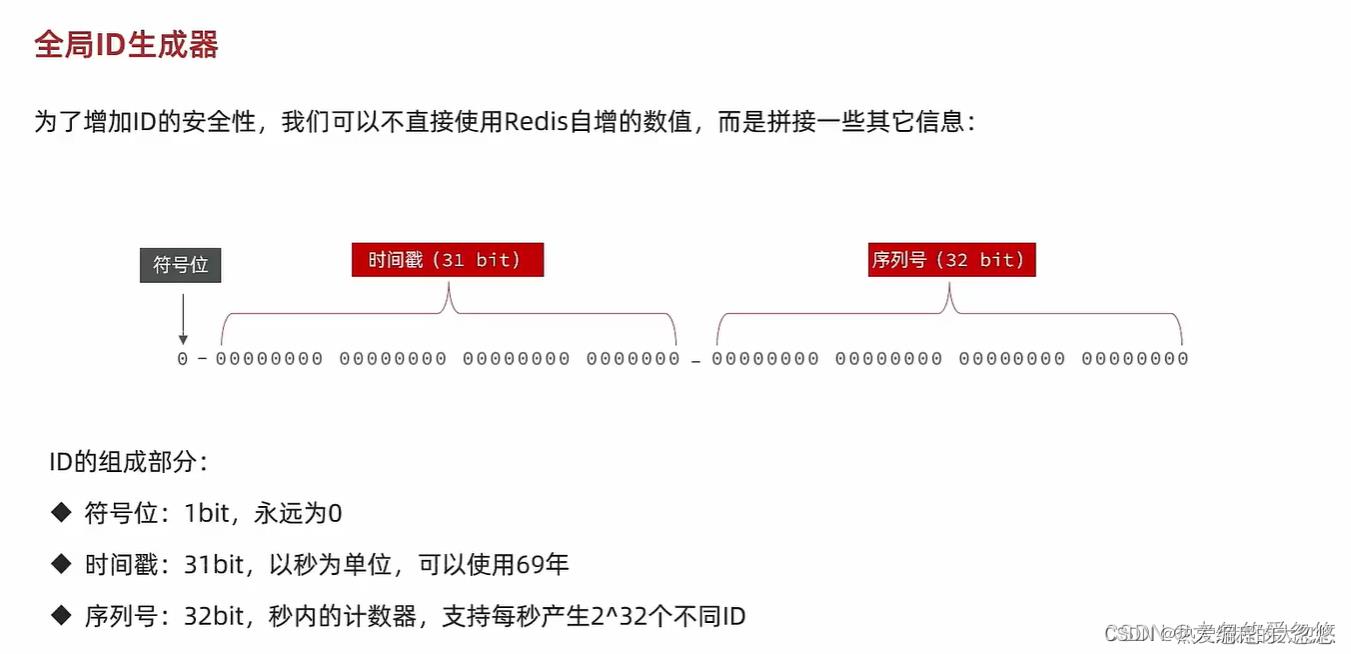
在分布式环境下,如果有需要生成全局唯一ID的需求,有下面几种解决办法:

使用Redis生成全局唯一ID可以采用下面的方法:
充当消息队列
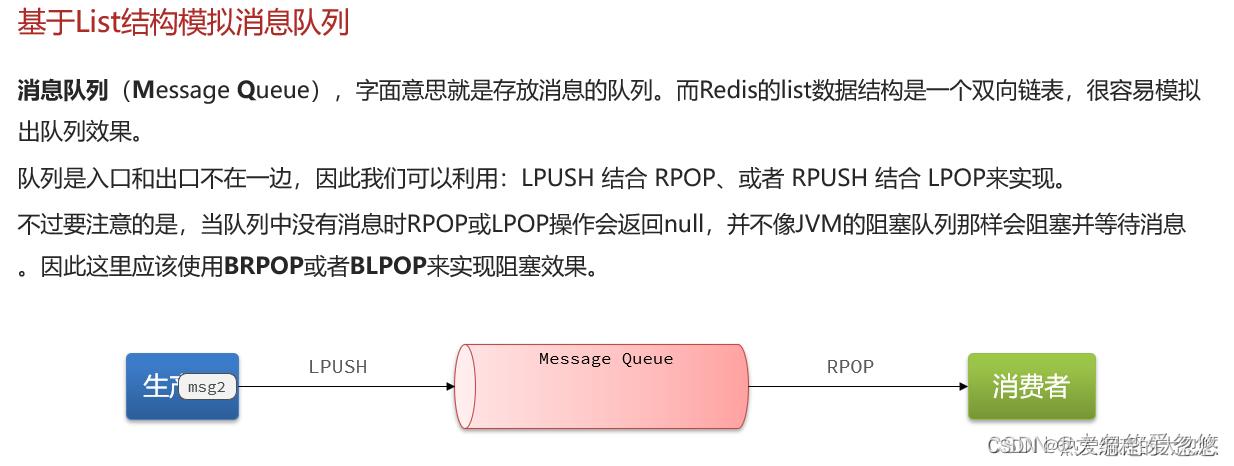
redis实现消息队列有三种方式:
- list列表

- PubSub机制
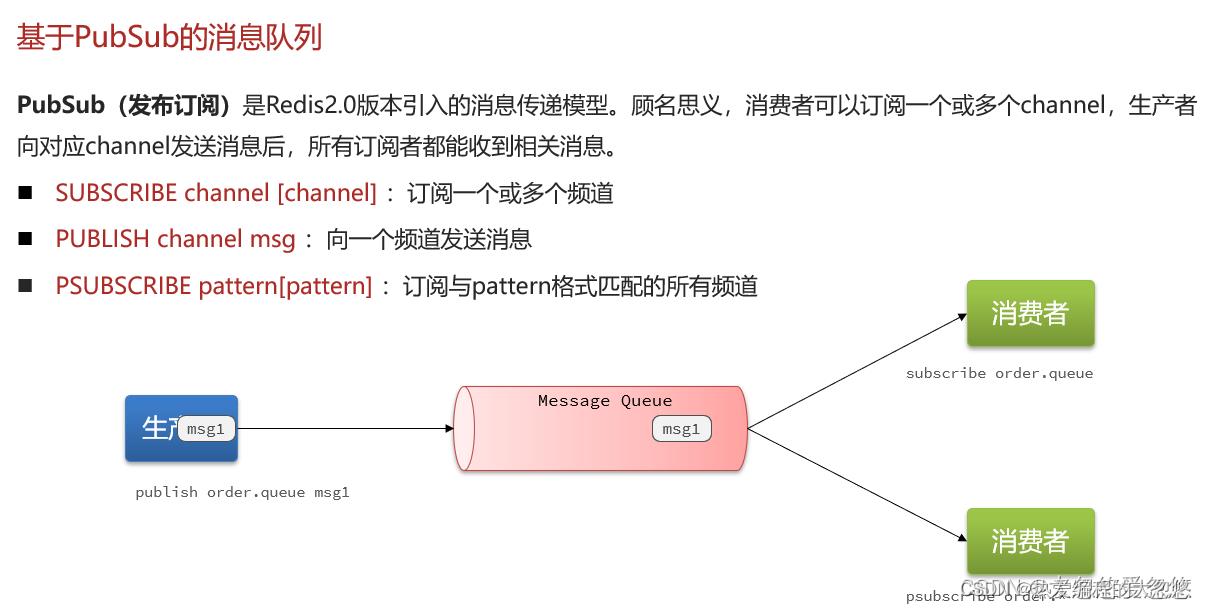

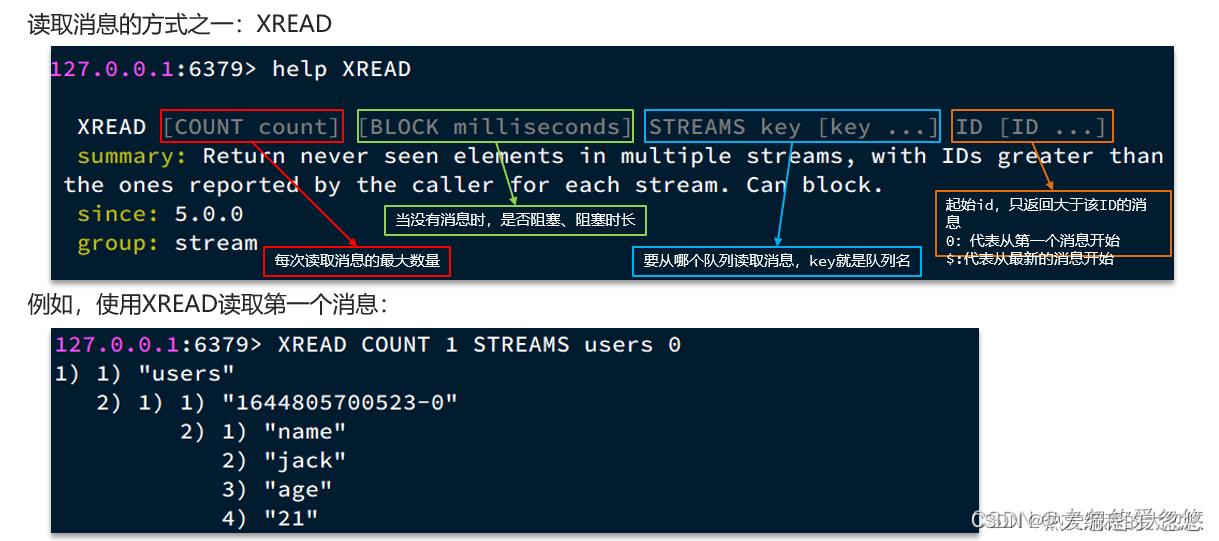
- stream实现消息队列


Feed流
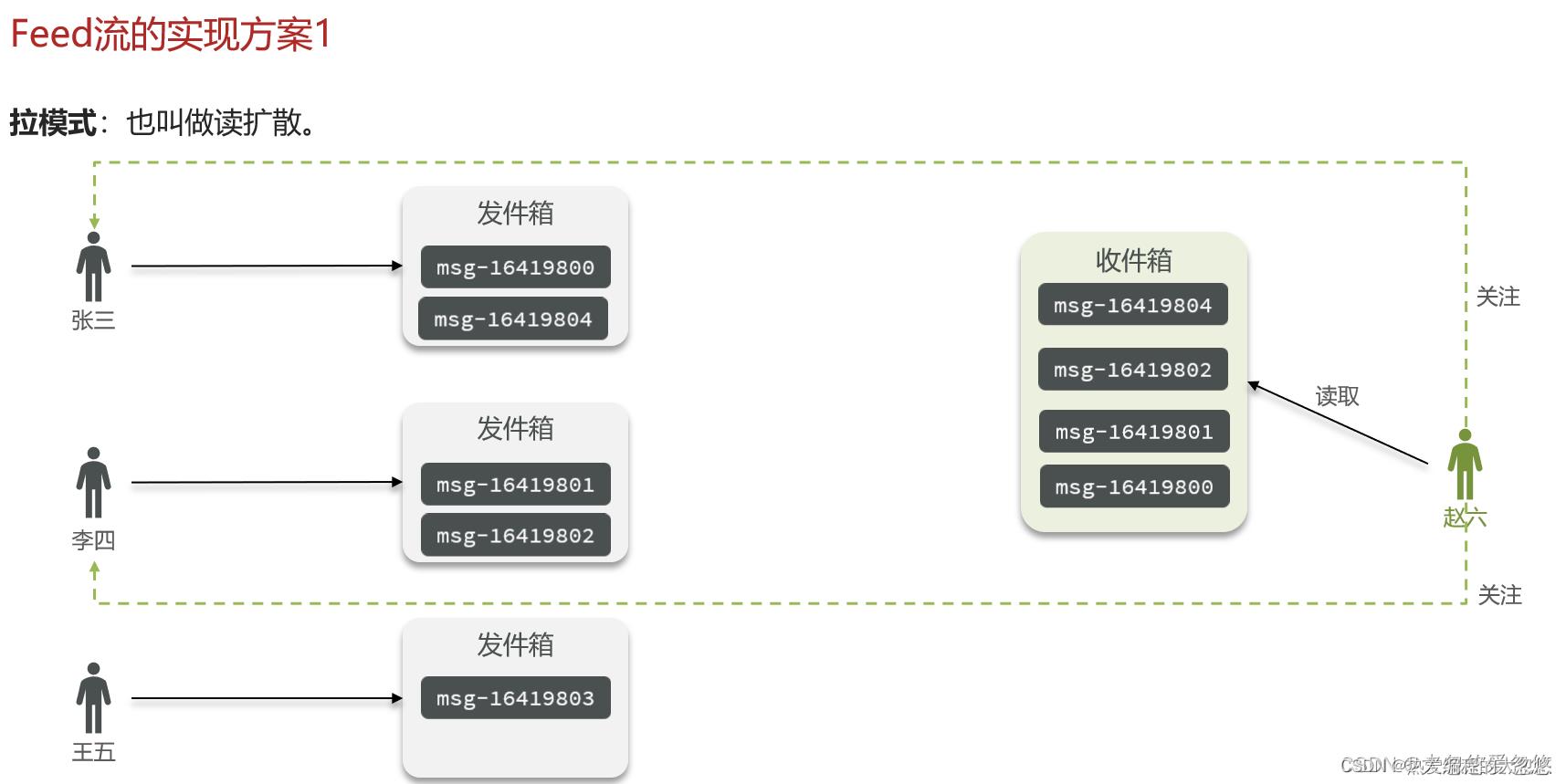
拉模式顾名思义就是用户主动去拉取他所关注的用户发布的信息,该模式最大缺点是延迟高,因为一下子需要去拉取大量的消息,优点是占用内存少,因为消息只需要存一份在发件箱
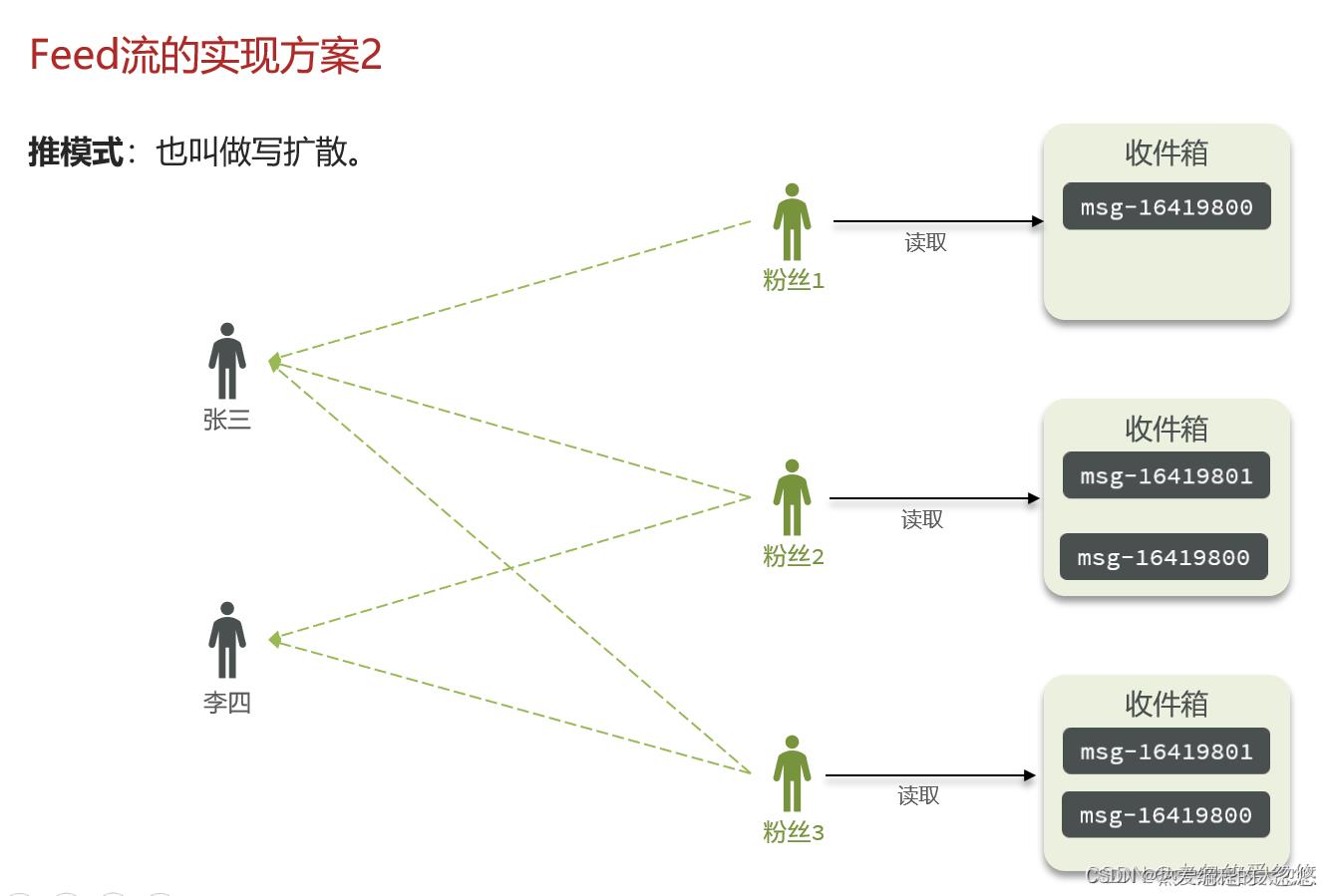
推模式就是用户在发消息的时候,不会先将消息放入收件箱等着粉丝来取,而是直接把这些消息发送给所有关注了他的粉丝们,这样粉丝读取消息的延迟低了,因为不需要再去拉取一遍了。最大的缺点是每一份消息都需要被赋值多份进行存储,对内存消耗大
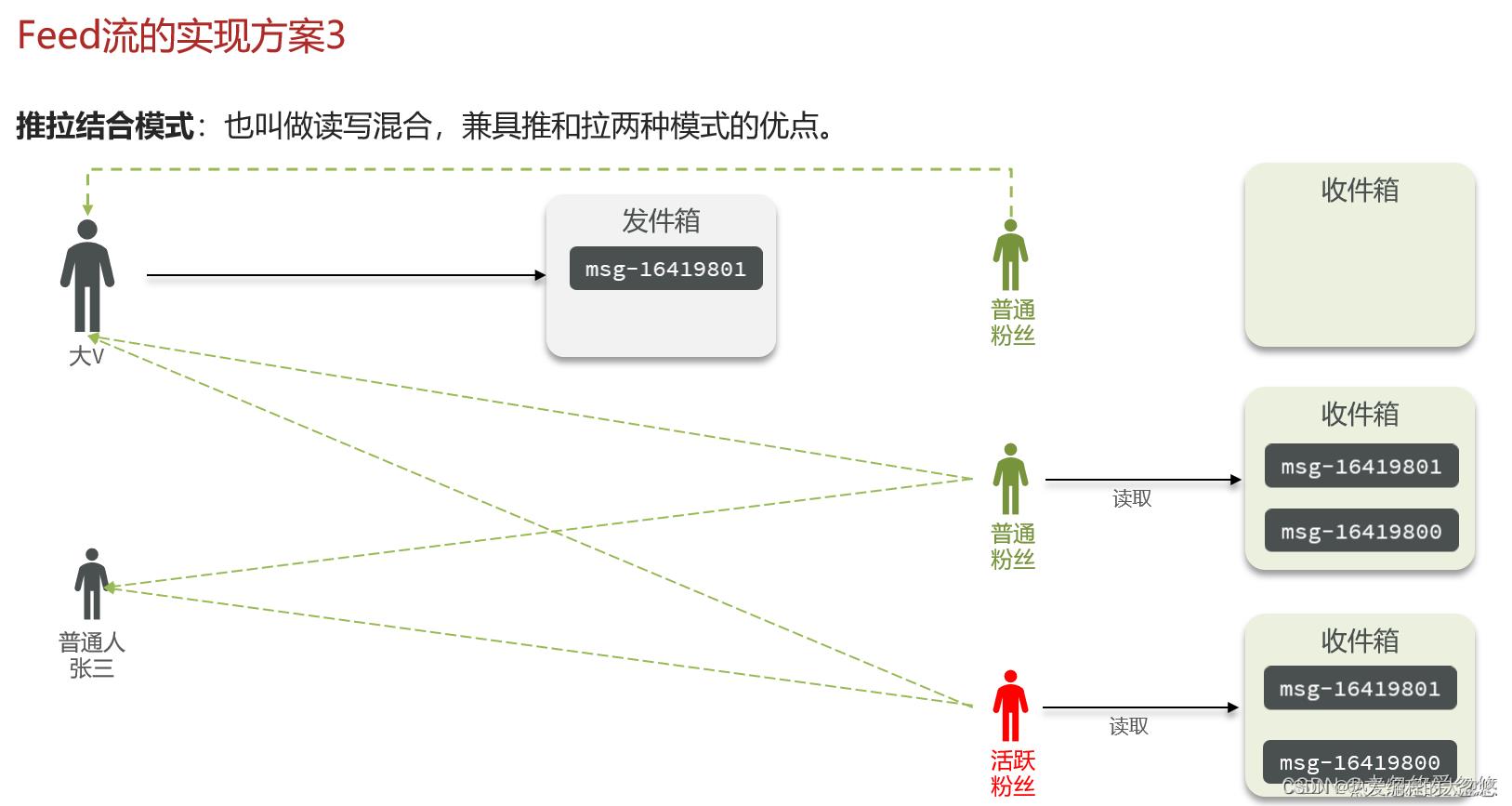
活跃用户可以采用推模式,减少每次获取消息的延迟。
不活跃用户可以采用拉模式,节约内存。
对于大V可以采用拉模式,避免同一份消息保存多份。
对于Feed流中涉及到的收件箱和发件箱可以采用redis进行实现,利用zset实现用户端分页下拉刷新。
附近商户

Geo底层采用zset进行存储。
可以在商户注册时,将对应实际物理店铺位置导入redis的geo数据结构保存,然后利用该数据结构完成附近商铺查询功能。
签到
可以利用bitmap完成签到,如果是按月统计签到信息,可以在每个用户初次登录时,在redis为该用户分配一个当前月大小的BitMap,然后设置当前天对应的位置为1。
利用bitmap相关命令可以统计本月签到的总天数,利用利用位运算可以快速计算出本月连续签到天数。
HyperLogLog实现UV统计



Redis进阶学习05—Feed流,GEO地理坐标的应用,bitmap的应用,HyperLogLog实现
持久化
RDB
tips: RDB全称为 Redis Database Backup file
rdb持久化会在以下四种情况下执行:
- 执行save命令(由服务器进程执行,会阻塞服务器)
- 执行bgsave命令(由fork出的子进程执行)
- redis停机时
- 触发RDB条件时
# redis默认开启RDB持久化,默认配置如下
# 900秒内,如果至少有1个key被修改,则执行bgsave , 如果是save "" 则表示禁用RDB
save 900 1
save 300 10
save 60 10000
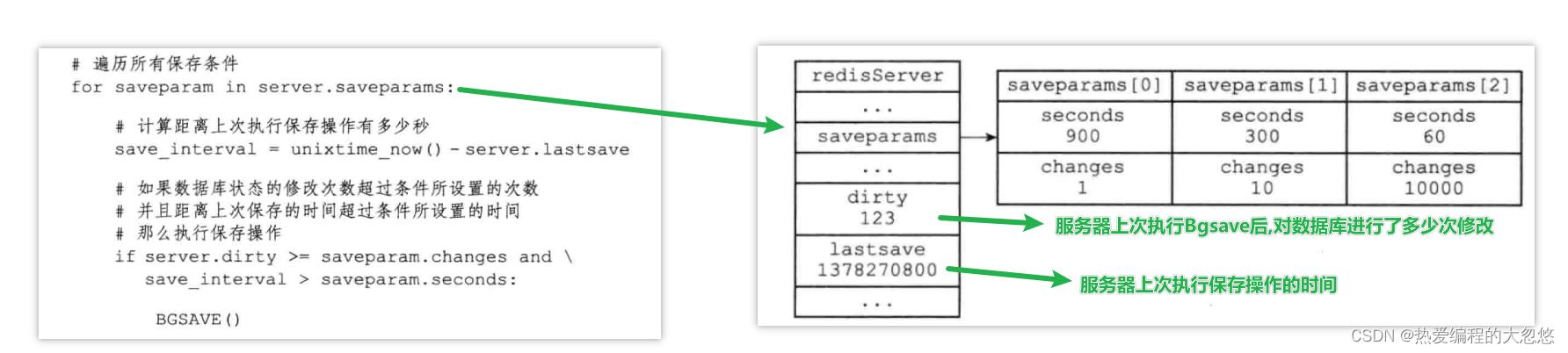
tips: 因为BGSAVE命令不会阻塞服务器进程执行,因此Redis允许用户通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令
Redis服务器周期性操作函数serverCron默认每隔100毫秒执行一次,该函数用于对正在运行的服务器进行维护,它其中一项工作就是检查save选项设置的保存条件是否满足,如果满足的话,就执行BGSAVE命令:
RDB文件载入时机 : Redis服务器在启动时如果检测到RDB文件存在,它就会自动载入RDB文件。
RDB文件是一个经过压缩的二进制文件,生成RDB文件的过程就是遍历redis数据库中所有key,然后根据key代表的不同数据类型,将其序列化为不同格式的二进制数据,最终用新生成的RDB文件替换旧的RDB文件。
缺点:
- RDB是间隔执行的,存在数据丢失风险
- fork子进程、压缩、写出RDB文件都比较耗时
AOF
AOF全称为Append Only File ,采用追加的方式,将redis执行的所有命令都记录在AOF文件中。
AOF默认是关闭的,我们可以通过修改配置开启:
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
AOF的命令记录的频率也可以通过redis.conf文件来配:
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
tips: 与RDB将键值对按照指定格式序列化保存为二进制文件不同,AOF是将每次执行的命令按照redis通信协议格式简单记录到命令日志文件中保存的
AOF原理:
- 服务器每执行完一个写命令,会以命令请求协议格式将被执行的写命令追加到服务器的aof_buf缓冲区的末尾

- Redis服务器进程就是一个事件循环,这个循环中文件事件负责接收客户端命令请求,然后进行命令回复,而时间事件负责执行像serverCron函数这样需要定时运行的函数。因为服务器处理文本事件时会产生写命令,使得一些内容被追加到aof_buf缓冲区,因此在服务器每次结束一个事件循环前,都会调用相关函数检查是否需要将aof_buf缓冲区内容同步到AOF文件里面。

flushAppendOnlyFile判断是否同步的依旧结束我们在配置文件中配置的appendfsync选项的值:

tips:

AOF还原过程:
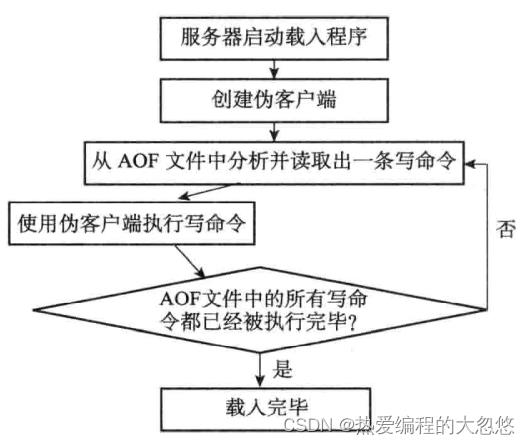
tips: redis命令只能在客户端上下文中执行,命令通常来自网络连接,此处来自AOF文件
AOF重写机制:
- 为了避免AOF文件因为大量冗余命令占据存储空间,可以采用redis提供的AOF重写机制解决冗余命令重复存储。
AOF重写机制是通过遍历数据库当前所有键,然后用一条命令去记录键值对代替之前记录这个键值对的多条命令:


因为aof_rewrite函数生成的新的AOF文件只包含还原当前数据库状态所必须的命令,所以新的AOF文件不会浪费任何磁盘存储空间。
aof_rewrite函数中涉及大量写入操作,如果放在redis主进程执行会阻塞客户端命令处理,因此redis是将aof执行过程放到子进程中完成的。
aof后台重写过程中,主进程处理的客户端写请求命令会被保存到aof重写缓冲区中,当子进程完成AOF重写工作后,通过向父进程发出一个信号,父进程收到后,会调用一个信号处理函数,并执行以下工作:
- 将aof重写缓冲区中的内容写入到新的aof文件
- 对新的aof文件进行改名,原子地替换现有的aof文件
tips: aof重写过程中只有信号处理函数执行时会阻塞redis主进程执行
Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
持久化小结
因为AOF更新频率通常比RDB文件更高,因此如果服务器开启了AOF持久化功能,那么会优先使用AOF文件还原数据库状态。
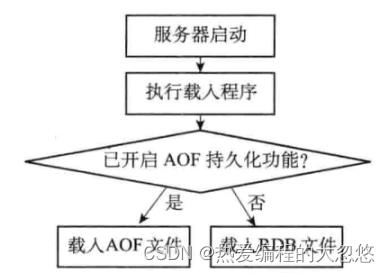
事件循环
过期键
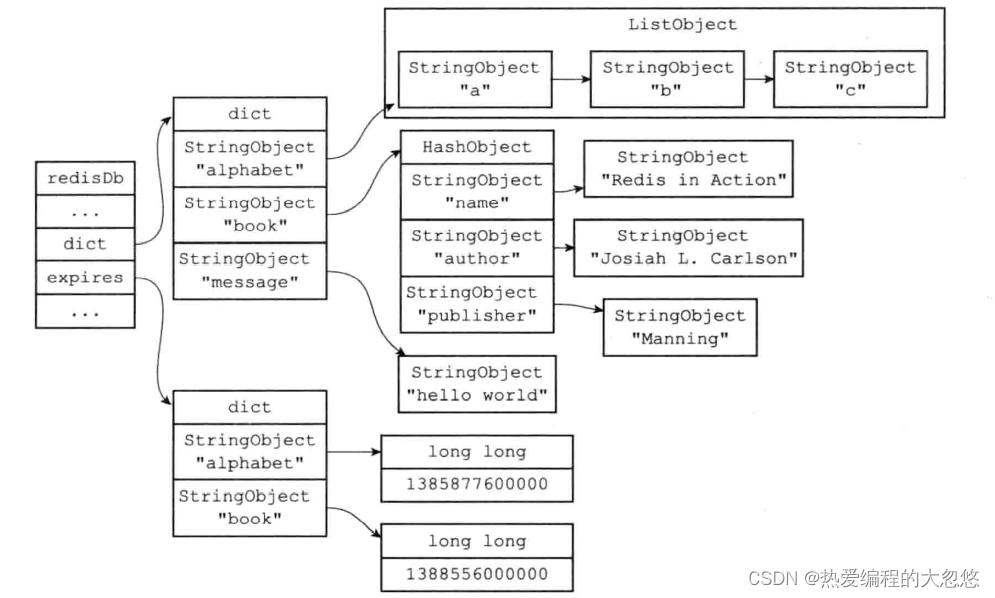
数据库
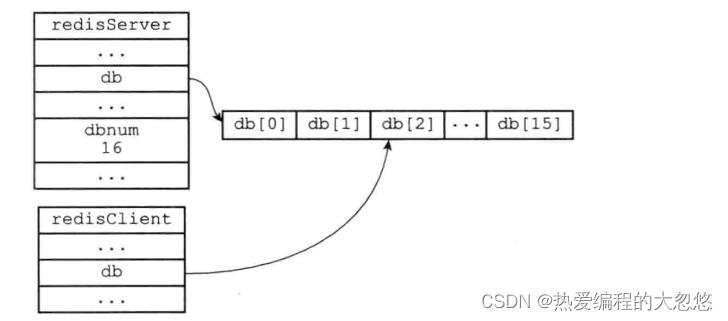
- redisServer记录redis服务器全局状态,其中db是redis管理的数据库列表,默认创建16个,一般只使用0号数据库
- redisClient记录redis客户端状态
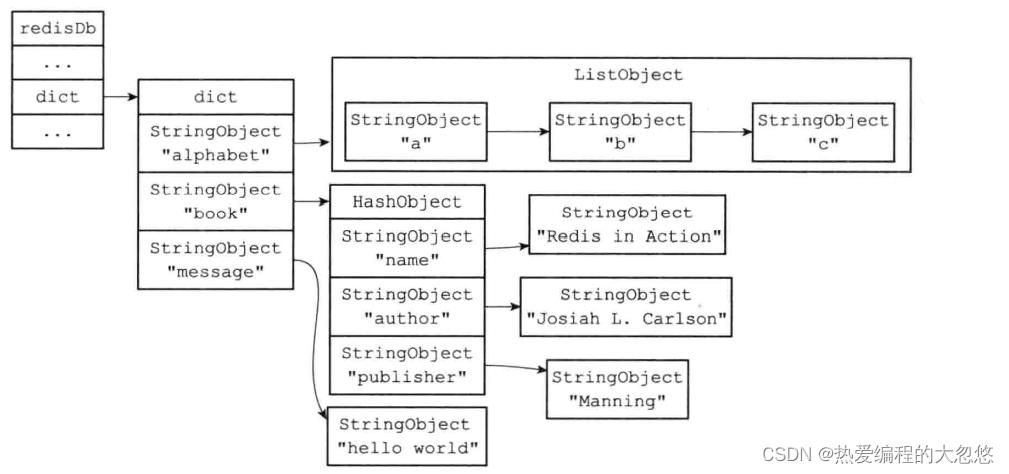
- redisDb记录redis单个数据库的状态,其中的dict字典记录当前数据库所有键值对
过期键保存
-
过期时间命令内部转换关系如下,最终都会通过pexpireat来生成当前键的毫秒级过期时间戳
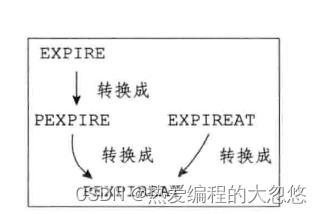
-
过期键由redisDb中的expires过期字典进行保存
删除策略
redis采用定期删除和惰性删除两种策略结合完成过期键的清理。
-
惰性删除策略
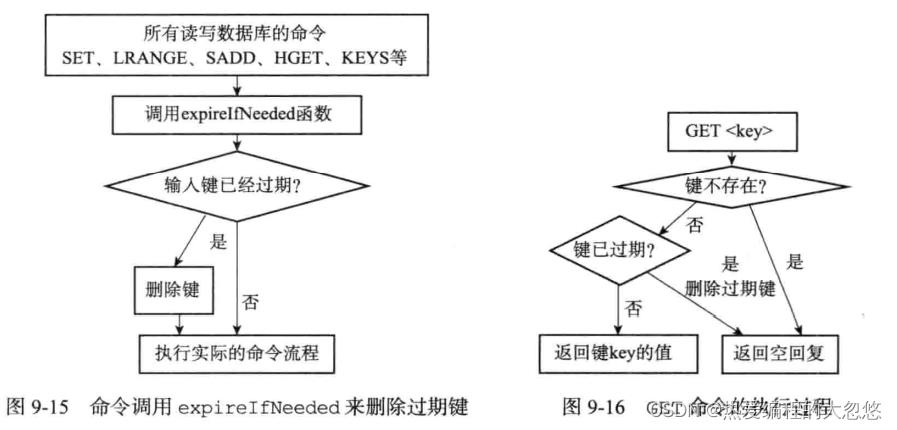
-
定期删除策略: serverCron周期性时间事件每次执行时,会调用activeExpireCycle函数进行一波定期删除


RDB和AOF
save,bgsave和aof文件重写时都会忽略数据库中已经过期的键。
当某个键被惰性删除或者定期删除时,会向aof文件写入一个DEL命令,来显示删除该键。
复制

主从复制
通过执行slaveof命令或者在配置文件中配置slaveof让一个服务器去复制另一个服务器:
slaveof masterIp masterPort
Redis复制过程分为同步和命令传播两步:
同步

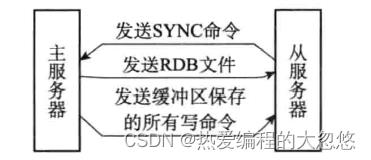
命令传播
在初次复制完毕后,后续每当主服务器接收到客户端的写命令时,都需要将命令传播给从服务器。
复制分为两种情况:

2.8版本之前的redis在断线后重复制时会通过发送SYNC命令进行完全同步复制,而不是进行增量同步。
新版本redis实现: 使用PSYNC命令替代SYNC命令来执行复制时的同步操作。

部分重同步实现
部分重同步需要用到三个值:

- 复制偏移量: 主服务器每次向从服务器传播N字节数据时,就将自己的复制偏移量加上N,从服务器每次收到主服务器传播的N个字节数据时,就将自己的复制偏移量加上N。
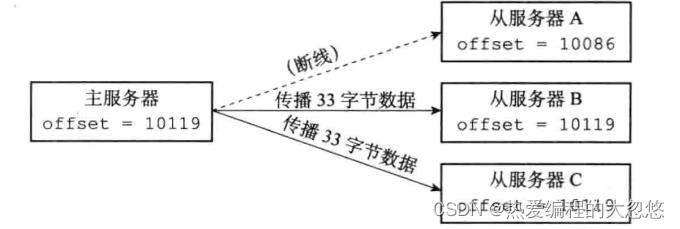
- 复制积压缓冲区: 固定大小的先进先出队列,默认大小为1MB,主服务器进行命令传播时,会将命令同时记录一份到复制积压缓冲区中保存。
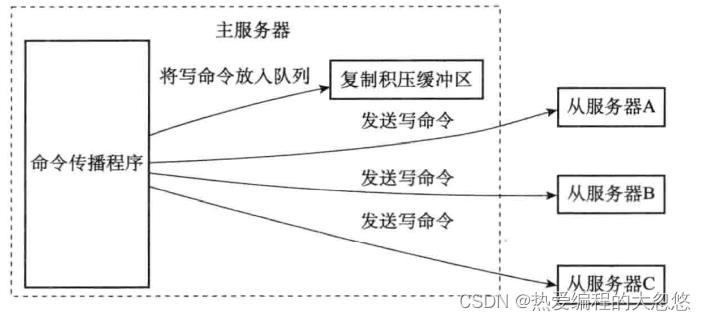
复制积压缓冲区保存最近最近一部分传播的写命令,并且复制积压缓冲区会为队列中每个字节记录相应的复制偏移量:
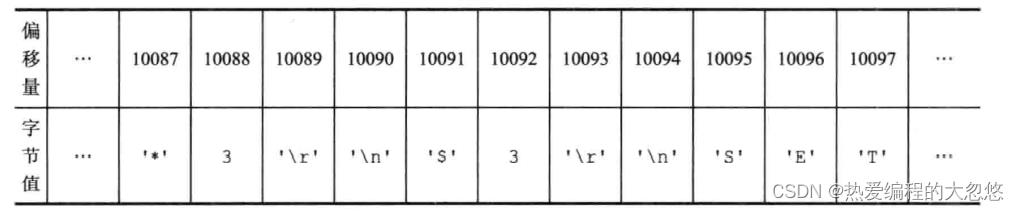

- 服务器运行ID

PSYNC命令
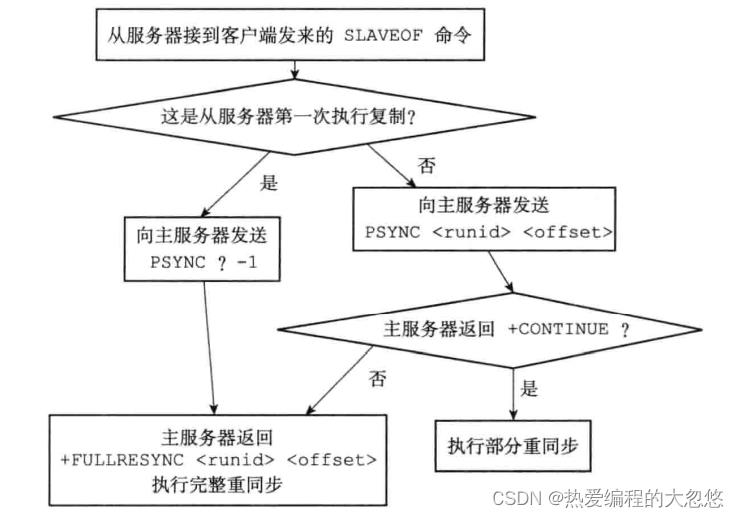
完整复制过程
- 从服务器发出slaveof命令,同时在从服务器会记录下主服务器的ip和port

-
建立套接字连接成功后,从服务器会为该套接字关联一个文本事件处理器,专门处理后续复制工作,如: 接收RDB文件和传播的命令。
-
主服务器在建立套接字成功后,会为该套接字创建对应的客户端状态,即主服务器会将从服务器看做是一个特殊的客户端。
-
从服务器发送ping命令,验证连接可用性
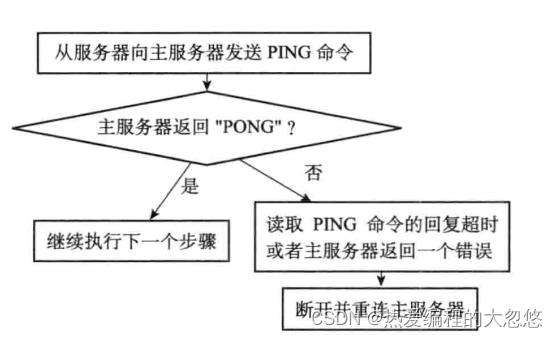
-
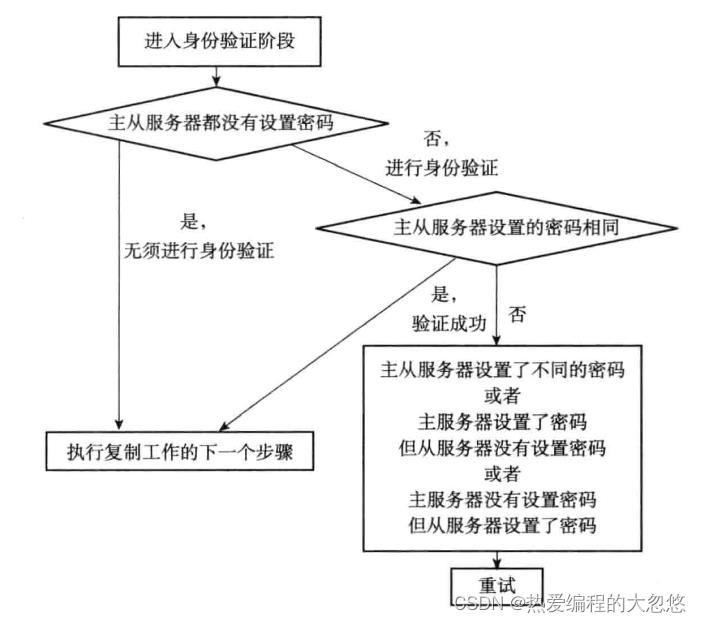
身份验证: 如果主服务器需要密码验证,从服务器需要配置masterauth选项
- 从服务器向主服务器发送自己监听的端口号,主服务器会在对应的从服务器客户端中保存该端口号

- 同步

tips: 只有通过客户端方式才能发送命令,redis也可以进行统一处理,而无须特殊对待
-
不断进行命令传播
-
心跳检测

- 通过Info replication命令,可以通过lag选项看到距离从服务器最后一次发送心跳包过去了多久


优化
- repl-diskless-sync启用无磁盘复制,避免全量同步时的磁盘IO,不通过先写RDB文件,再发送该文件到网络IO的方式,而是直接将数据发送到网络IO。
- 可以提高复制积压缓冲区大小,减少slave故障恢复进行全量同步的概率。
哨兵
redis设计与实现第16章 Sentinel
分片集群
多级缓存
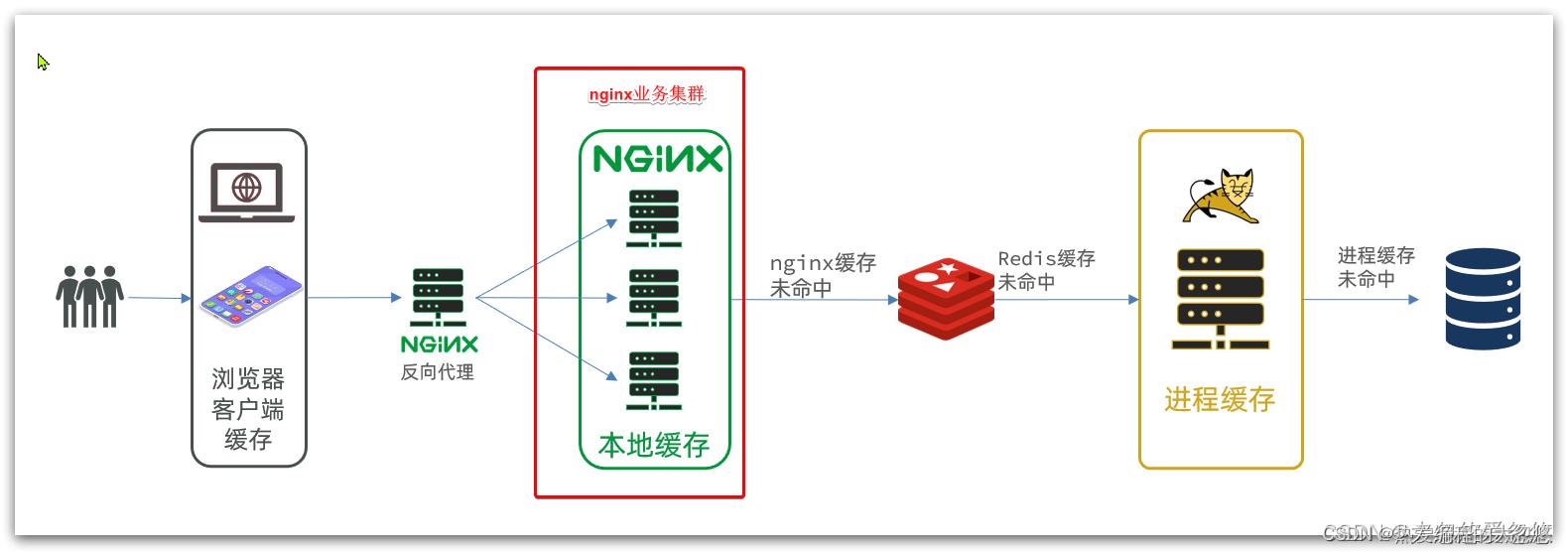
-
nginx做反向代理和静态资源缓存
-
Nginx结合OpenResty完成对redis的操作,通过nginx查询redis,并且结果缓存在本地
-
tomcat利用caffeine完成本地进程缓存
-
以上缓存均未命中,最终请求打到数据库
缓存同步
底层数据结构
SDS(简单动态字符串)
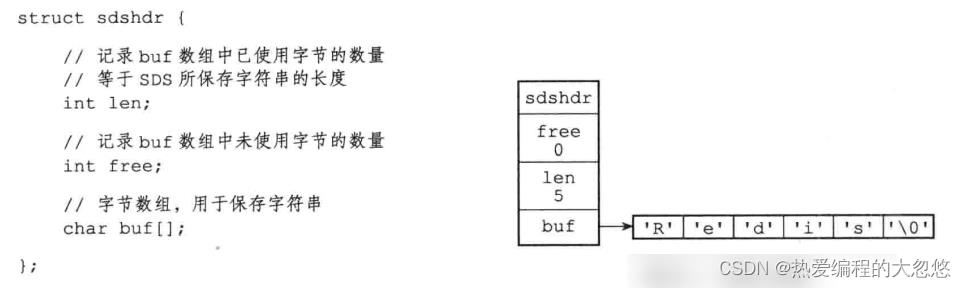
- 常数复杂度获取字符串长度
- 杜绝缓冲区溢出
- 通过内存预分配,惰性空间释放来减少修改字符串长度时所需内存重分配次数
- 二进制安全 , SDS使用len而非’\\0’判断字符串是否结束
- 兼容部分C字符串函数
IntSet(整数集合)
IntSet是vlaue集合的底层实现之一,当一个集合只包含整数值元素,并且这个集合元素数量不多的情况下,Redis就会使用IntSet作为该value集合的底层实现。
typedef struct intset
//编码方式,支持存放16位,32位,64位整数
uint32_t encoding;
//元素个数
uint32_t length;
//整数数组,保存集合数据
int8_t contents[];
intset;
如果插入的新元素大小比当前编码大小大,那么会进行升级,即选取适合当前新元素大小的编码,并将数组进行扩容,每个元素都按照该编码大小进行存储。
redis整数集合不支持降级,因为会产生内存碎片,当然可以考虑采用free字段标记空闲空间,但是redis没有这样做
intset具备以下特点:
- Redis会确保intset中的元素唯一,有序
- 具备类型升级机制,可以节约内存空间
- 底层采用二分查找方式来查询
Dict(字典)
//字典
typedef struct dict
//dict类型,内置不同的hash函数
dictType *type;
//私有数据,在做特殊运算时使用
void *privdata;
//一个Dict包含两个哈希表,其中一个是当前数据,另一个一般为空,rehash时使用
dictht ht[2];
//rehash的进度,-1表示未开始
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
//rehash是否暂停,1则暂停,0则继续
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
dict;
结构:
- 数组加链表
- Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash
伸缩过程:


zipList(压缩列表)
压缩列表是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis底层就会使用ziplist存储存储结构。

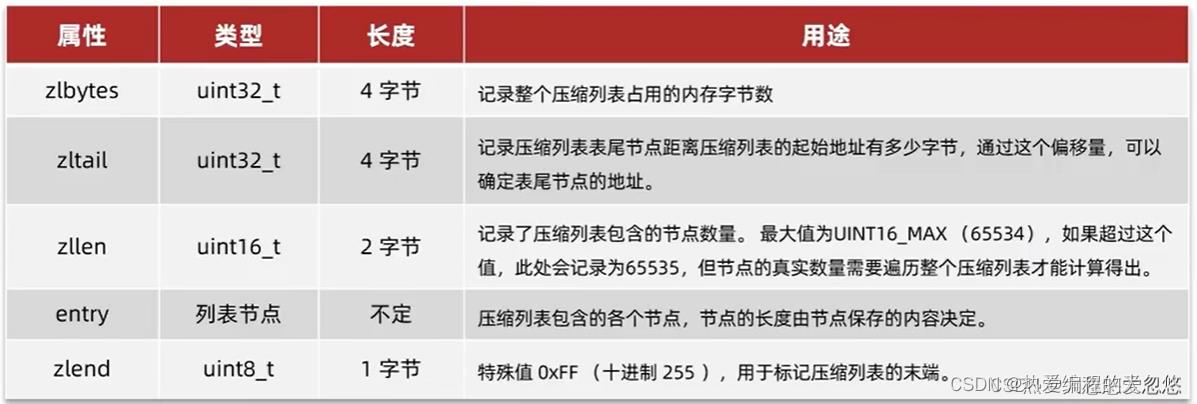
entry构成:
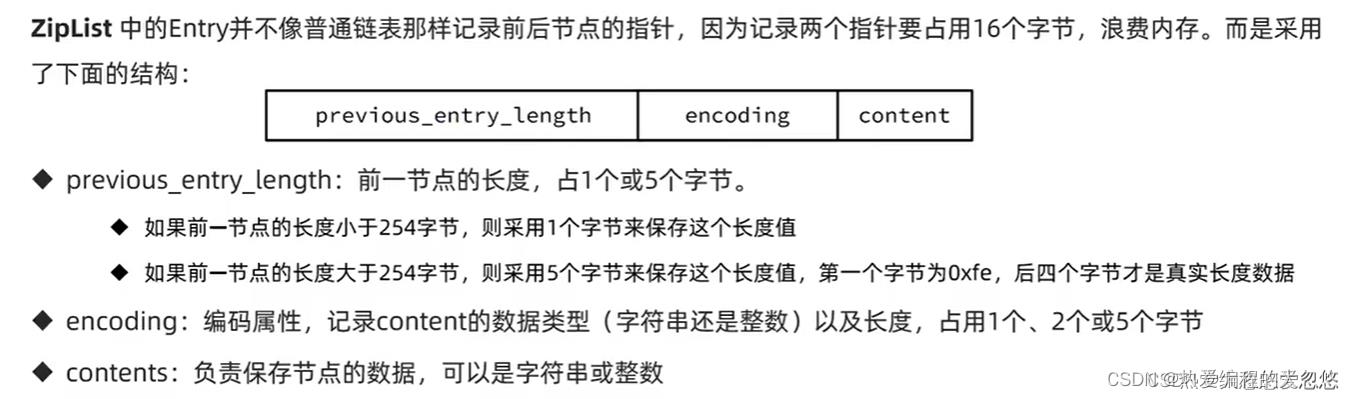
连锁更新问题:


- 此时,如果我们将一个长度大于254字节的新节点设置插入进来,称为压缩列表头节点,那么旧头节点的pre_entry_len需要扩展到5字节表示新节点的大小.
- 旧节点加上4字节后变成了254,那么后面的节点需要再次扩展…直到某个节点pre_entry_len扩展到5字节后长度并没有超过254为止

新增,删除都可能导致连锁更新的发生。
连锁更新虽然复杂度高,会大大降低性能,但是由于产生概率较低,并且及时出现了,只要被更新节点数量不多,性能上不会有太大影响。
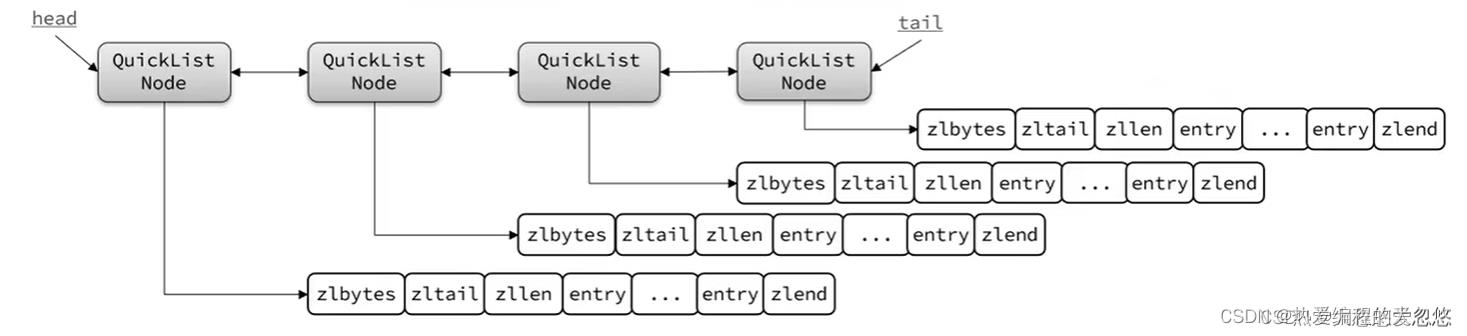
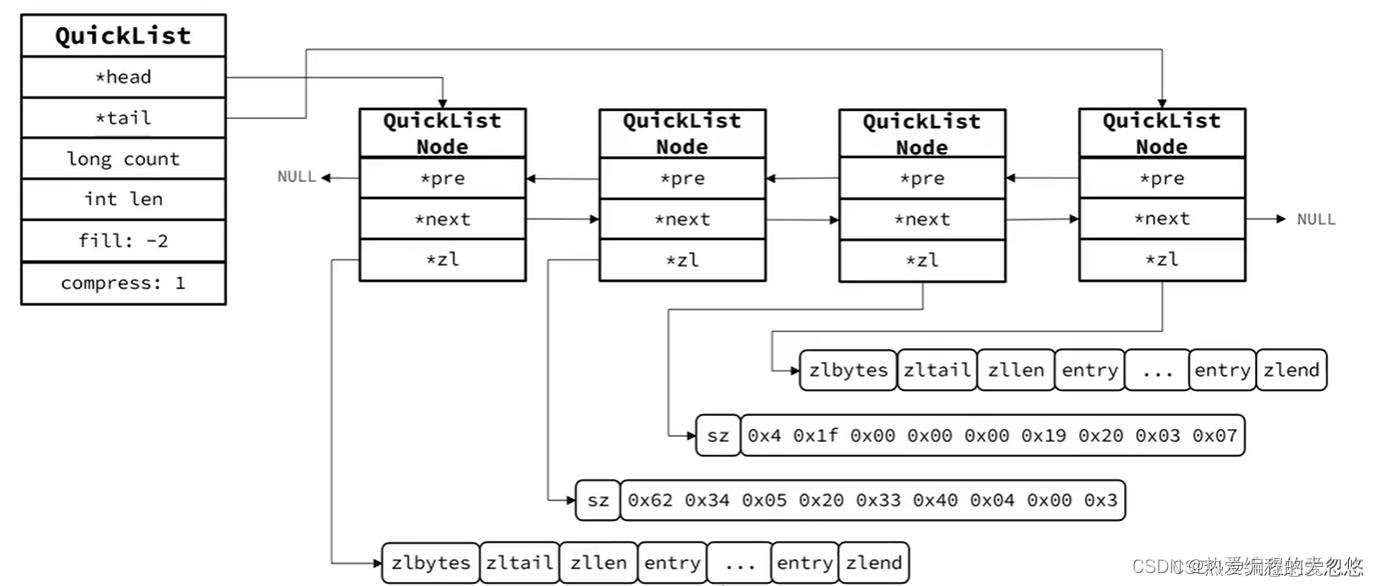
quickList(快速链表)


skipList(跳跃表)
SkipList首先是链表,但与传统链表相比有几点差异:
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同
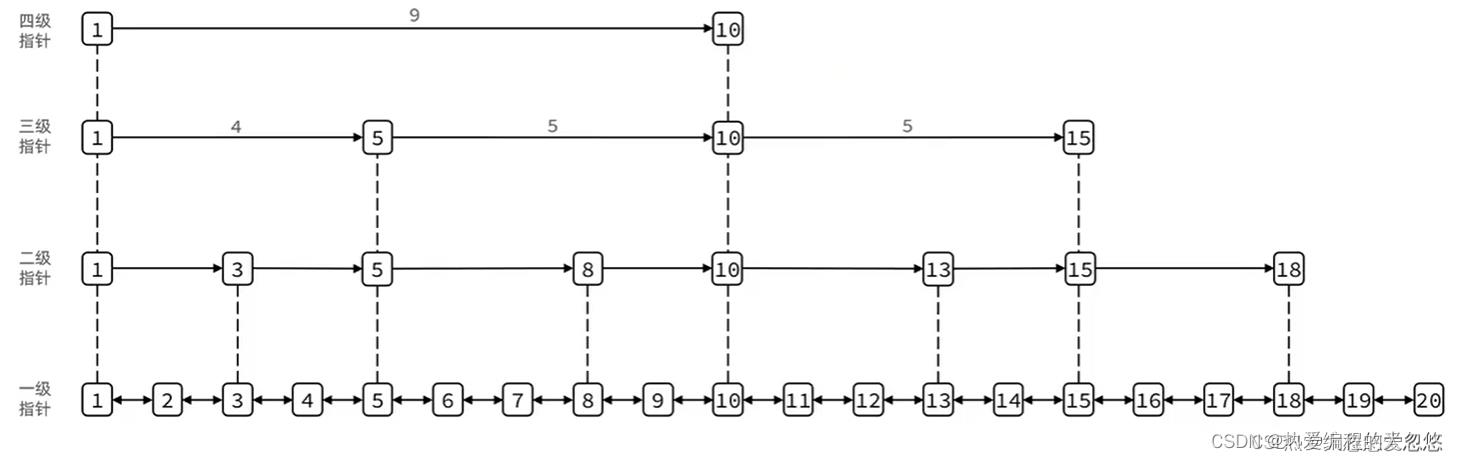
Redis目前只在两处地方使用到了SkipList,分别是 :
-
实现有序集合键
-
在集群节点中用作内部数据结构
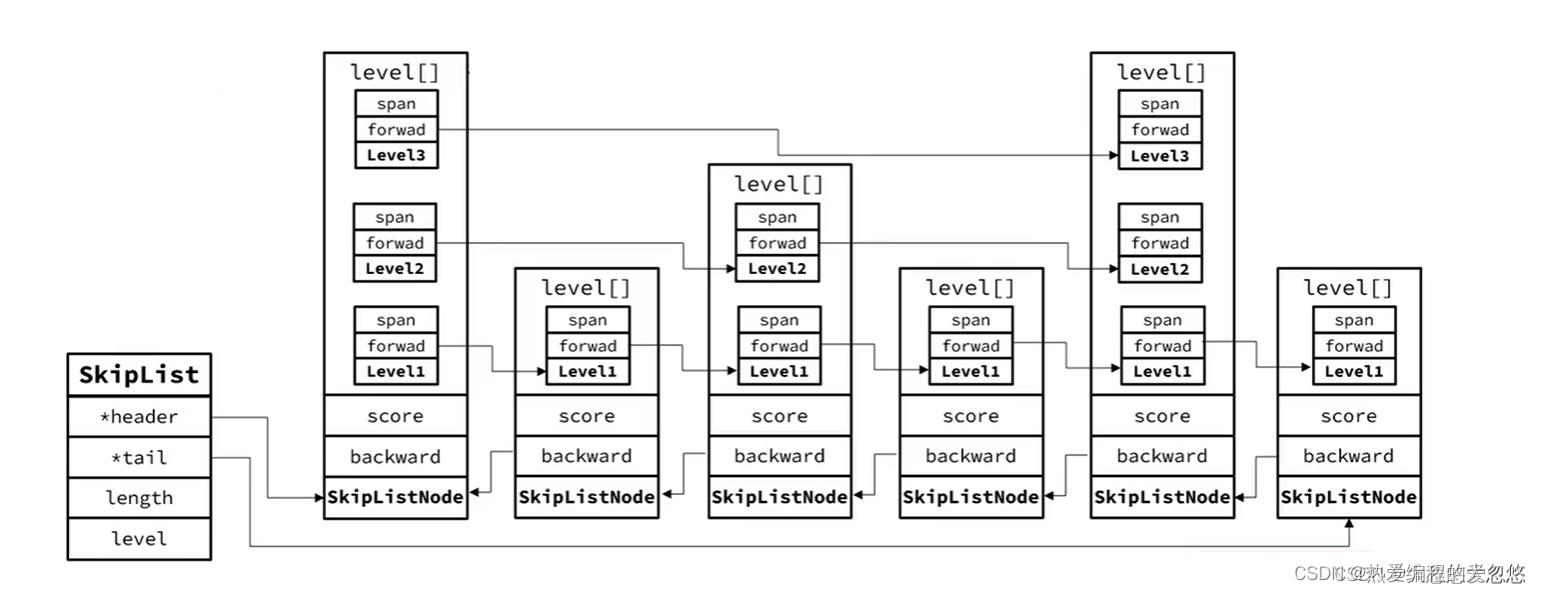
-
跳跃表是一个双向链表,每个节点都包含score和ele值
-
节点按照score排序
-
每个节点都可以包含多层指针,层数是1到32之间的随机数
-
不同层指针到下一个节点的跨度不同,层级越高,跨度越大
-
增删改成效率与红黑树基本一致,实现却更为简单
Redis对象系统

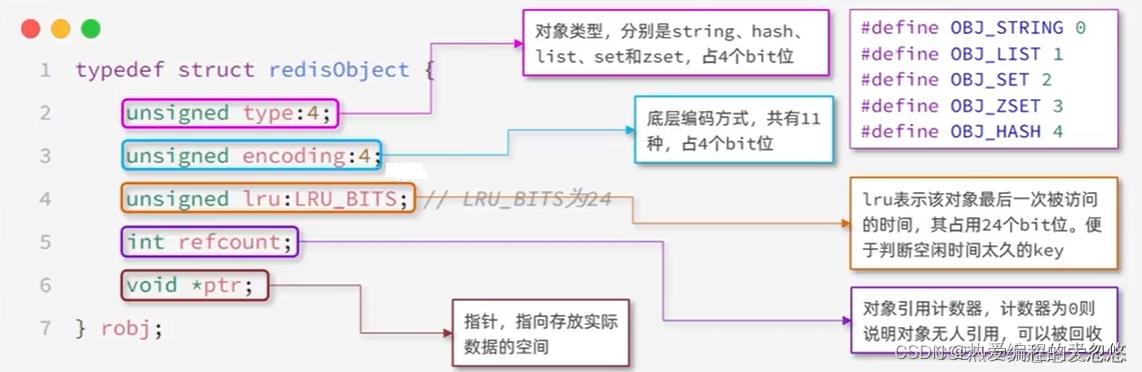
Reids中会根据存储的数据类型不同,选择不同的编码方式,功包含11种不同的类型:
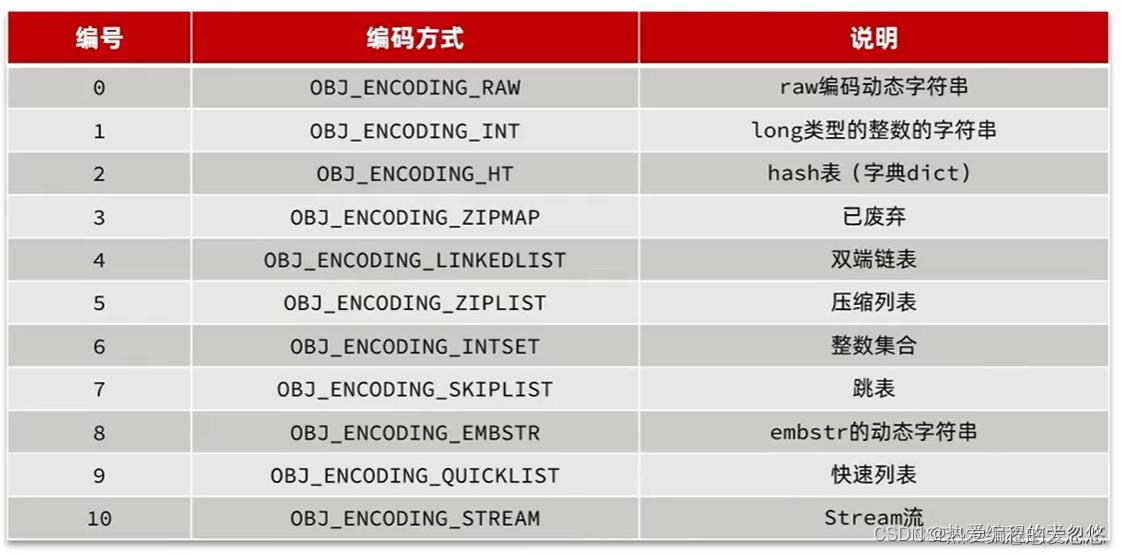
每种数据类型使用的编码方式如下:
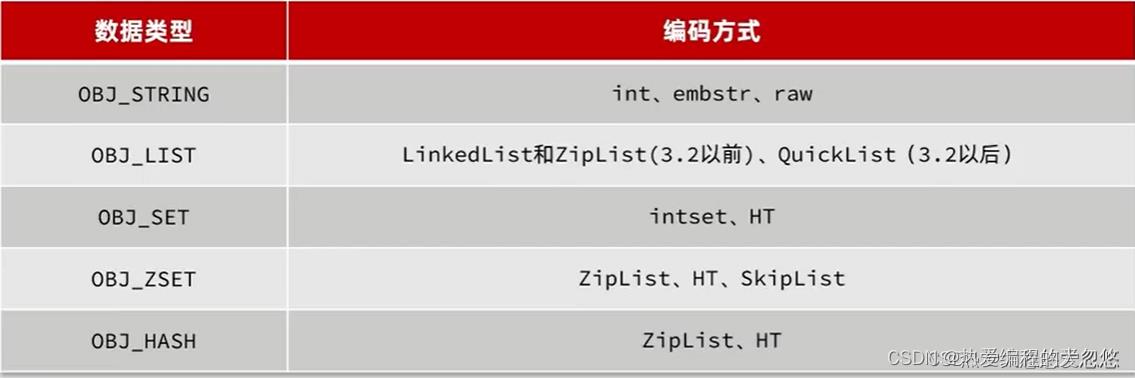
String对象
- 如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时Object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。

- 如果存储的字符串是整数值,并且大小在LONG—MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了

- 其基本编码方式是RAW,基于简单动态字符串SDS实现,存储上限为512mb.
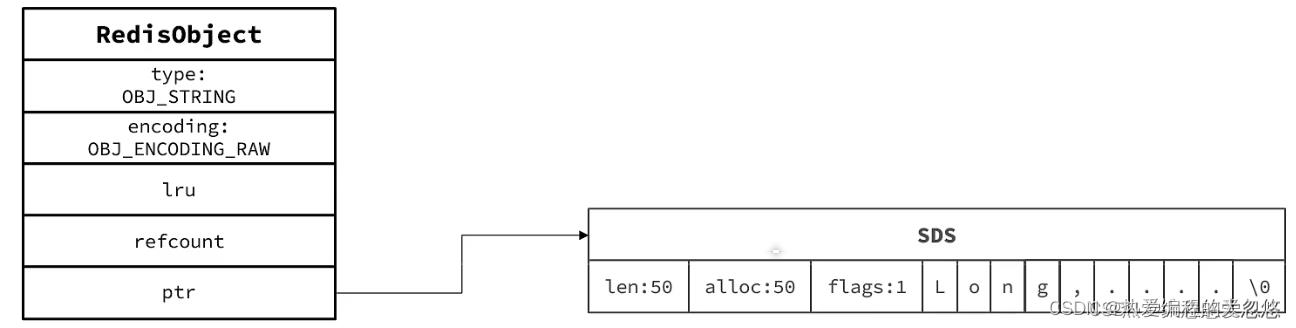
列表对象


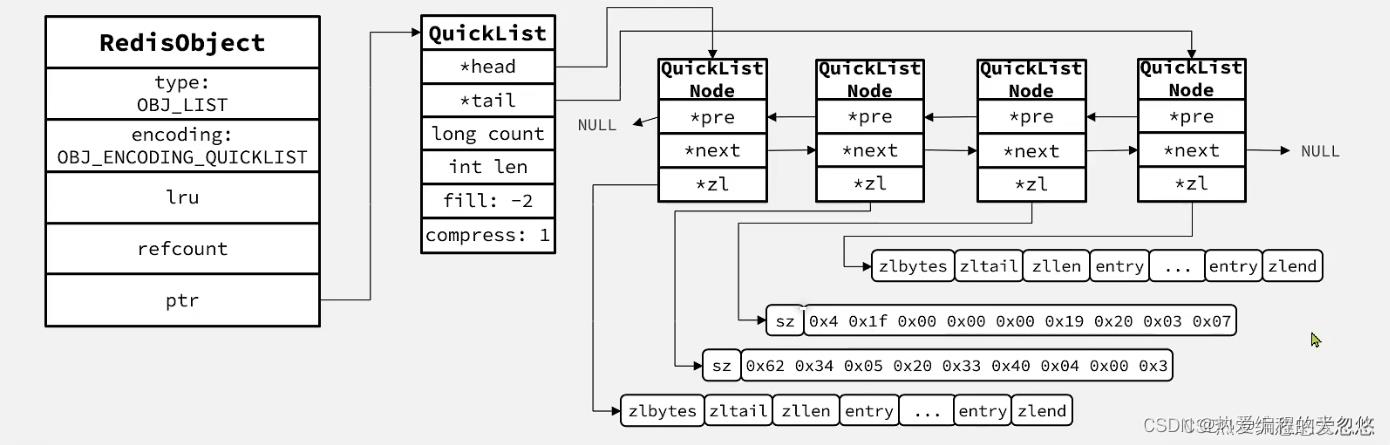
集合对象

编码转换:
有序集合

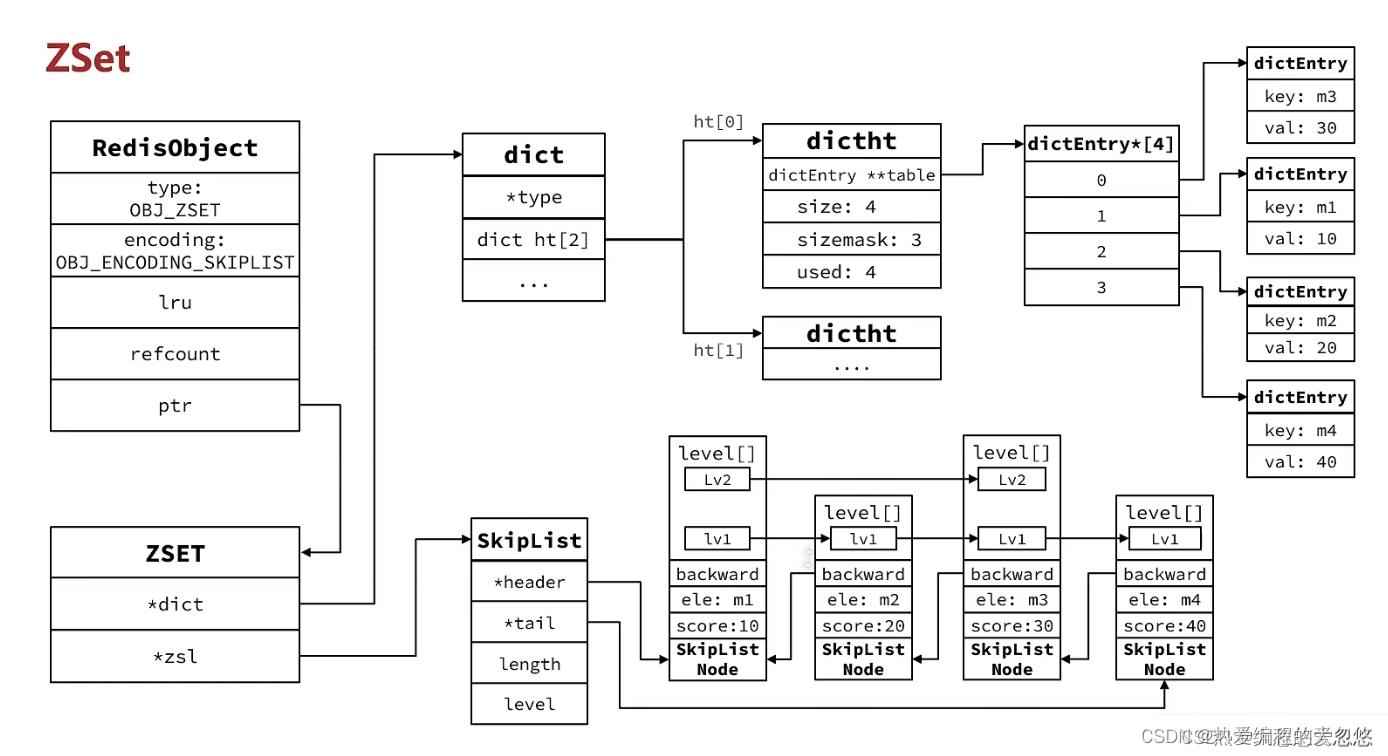

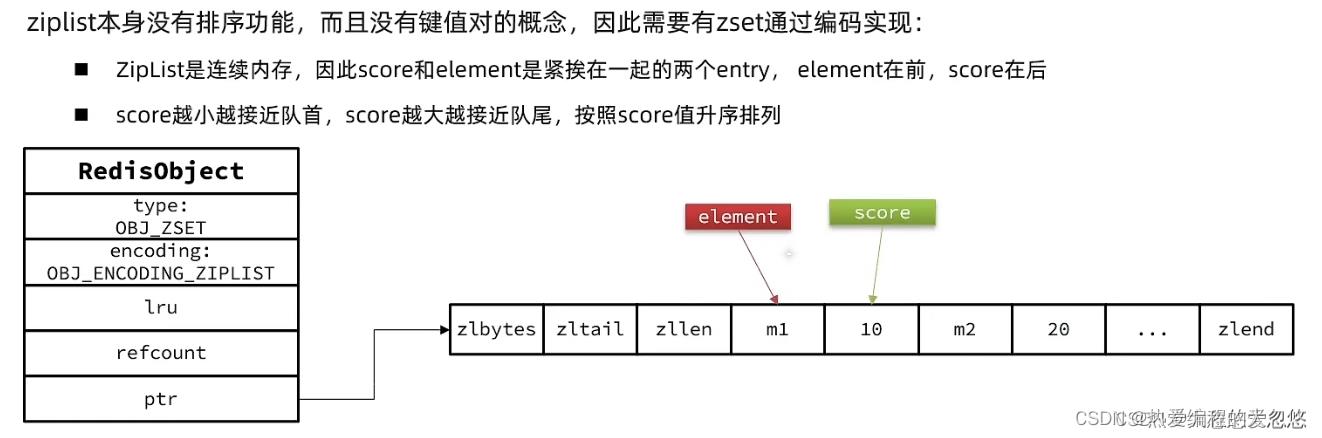
当数据量比较小的时候,ZSet采用ziplist作为底层结构

hash对象
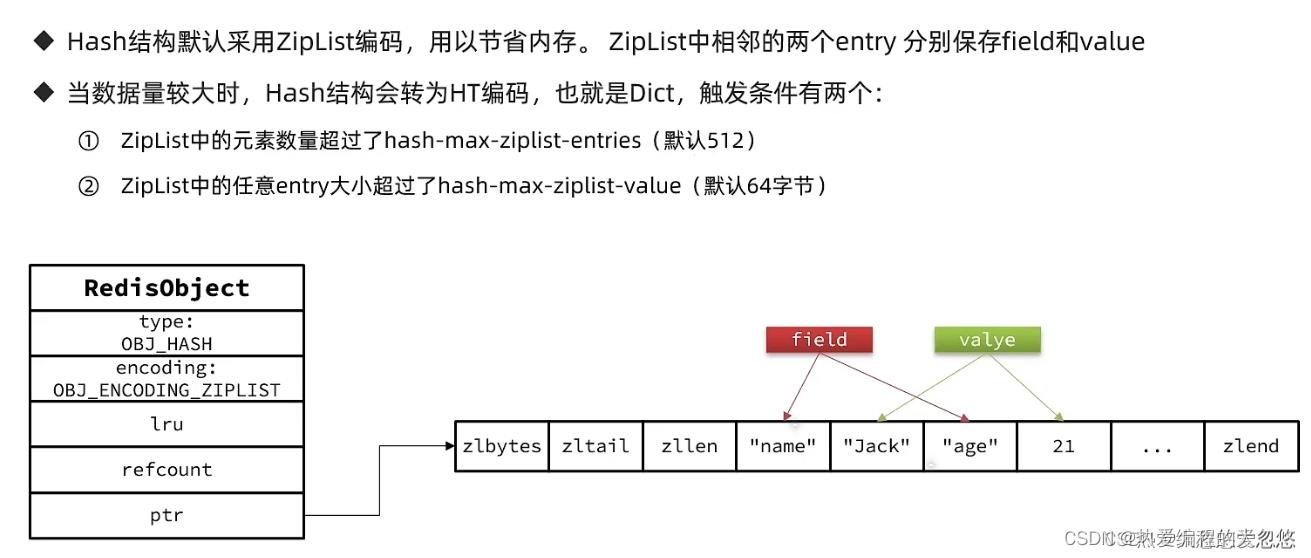
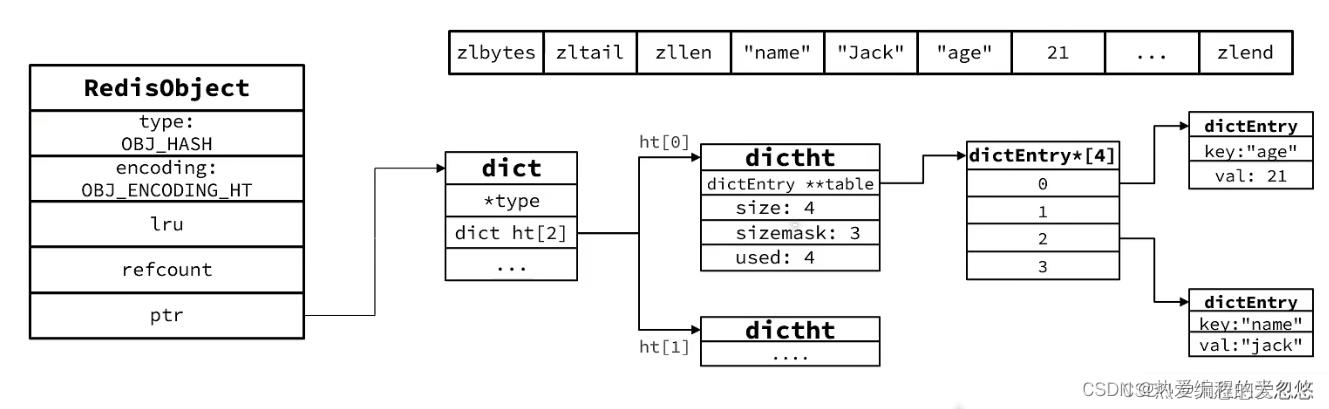
当超过限制后,底层编码会变成HT
Redis最佳实践
bigKey问题
Key的最佳实践:
- 固定格式:[业务名]:[数据名]:[id]
- 足够简短:不超过44字节
- 不包含特殊字符
Value的最佳实践:
- 合理的拆分数据,拒绝BigKey
- 选择合适数据结构
- Hash结构的entry数量不要超过1000
- 设置合理的超时时间
tips: 字符串对象尽量底层采用embstr编码 , 哈希对象底层尽量采用ziplist编码
批处理
批量处理的方案:
- 原生的M操作
- Pipeline批处理
注意事项:
- 批处理时不建议一次携带太多命令
- Pipeline的多个命令之间不具备原子性
分片集群下的批处理:
如MSET或Pipeline这样的批处理需要在一次请求中携带多条命令,而此时如果Redis是一个集群,那批处理命令的多个key必须落在一个插槽中,否则就会导致执行失败。
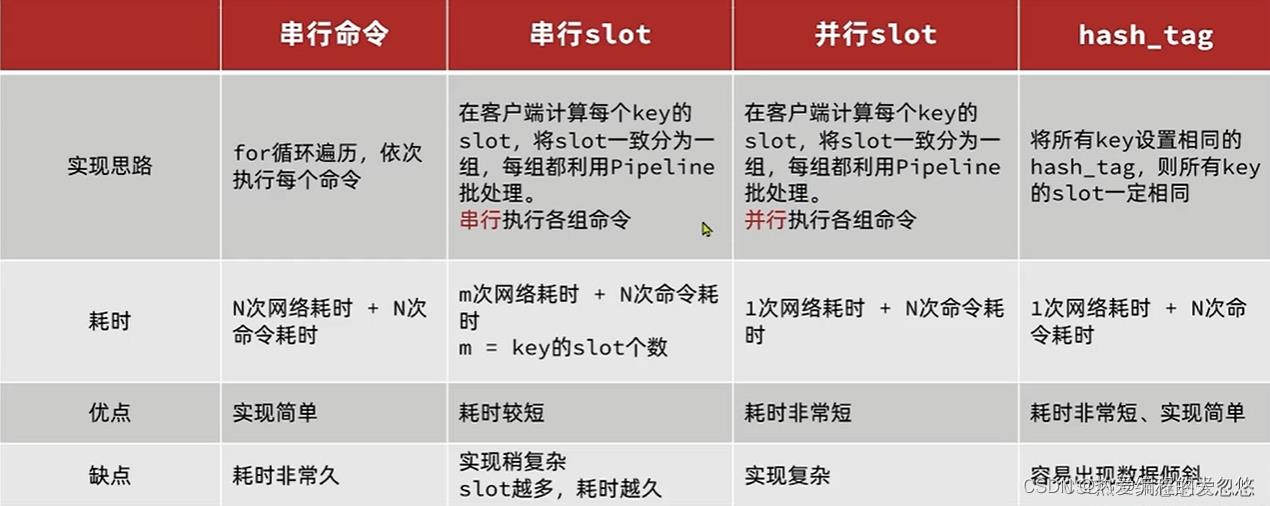
内存淘汰策略

LRU和LFU是通过redisObject对象中的lru属性进行判断完成key淘汰的。
发布订阅和事务
以上是关于Redis核心知识点的主要内容,如果未能解决你的问题,请参考以下文章