Java基础-xml解析
Posted Ocean:)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java基础-xml解析相关的知识,希望对你有一定的参考价值。
XML
XML
概述
Exendsible Markup Language(XML)可扩展标记语言
用途:
- 数据存储,小型数据库,存在一定CRUD操作可行性
- 网络数据的传输
- JavaWEB项目配置文件
基本语法
- XML文件后缀名为.xml
- XML文件第一行是对于当前文件的定义声明
- XML文件中有且只有一个根标签
- 属性值必须使用引号包含,推荐使用双引号
- 标签必须正确匹配,即正确开始和关闭
- XML标签内严格区分大小写
<?xml version="1.0" encoding="utf-8"?>
<users>
<user id="1">
<name>ocean</name>
<age>18</age>
<gender>male</gender>
</user>
</users>
文档组成部分
1.文档声明
a.格式
<?xml 属性列表 ?>
<?xml version="1.0" encoding="utf-8"?>
version:当前的XML文件版本号
encoding:编码方式,这里建议XML文件的保存编码集和对应的解析编码集一致
standalone:是否依赖于其他文件[了解]
yes 不依赖 no 依赖
2.指令(了解即可)
可以导入css样式
3.标签内容自定义
规则:
a.自定义标签允许使用英文字母,数字和其他标点符号
b.不允许使用数字和标点开头,只能用英文字母
c.不允许在自定义标签内使用xml标记,XML也不行
d.名字不允许出现空格
4.属性
可以给标签一个属性,有时候要求ID属性是唯一的
5.文本(了解)
CDATA区,所见即所得
XML文件数据约束
-
DTD
简单的约束方法
存在一定的约束问题
-
Schema
复杂的XML文件约束方式
非常严谨
DTD实例:
student.dtd
<!-- students 根标签 要求根标签内存放student -->
<!ELEMENT students (student*) >
<!-- student标签包含子标签的内容 -->
<!ELEMENT student (name,age,sex)>
<!-- 所有子标签当前数据都都是文本形式 -->
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!-- ATTLIST Attribute List 属性列表 student id ID -->
<!ATTLIST student id ID #REQUIRED>
student.xml
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE students SYSTEM "D:\\NZ\\IEDA\\Day25_SL_IDEA\\src\\com\\qfedu\\b_dtd\\student.dtd">
<!--<!DOCTYPE students [-->
<!-- <!– students 根标签 要求根标签内存放student –>-->
<!-- <!ELEMENT students (student*) >-->
<!-- <!– student标签包含子标签的内容 –>-->
<!-- <!ELEMENT student (name,age,sex)>-->
<!-- <!– 所有子标签当前数据都都是文本形式 –>-->
<!-- <!ELEMENT name (#PCDATA)>-->
<!-- <!ELEMENT age (#PCDATA)>-->
<!-- <!ELEMENT sex (#PCDATA)>-->
<!-- <!– ATTLIST Attribute List 属性列表 student id ID –>-->
<!-- <!ATTLIST student id ID #REQUIRED>-->
<!-- ]>-->
<students>
<student id="qf1">
<name>骚磊</name>
<age>fdasfdsaf</age>
<sex>male</sex>
</student>
<student id="qf2">
<name>骚磊</name>
<age>16</age>
<sex>male</sex>
</student>
</students>
Schema实例:
student.xml
<?xml version="1.0" encoding="utf-8"?>
<!--
1. 填写根节点约束
2. 引入xsi前缀,xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3. 引入xsd文件命名空间 xsi:schemaLocation="http://www.qfedu.com/xml student.xsd"
4. 为xsd约束声明一个前缀,作为表示
-->
<students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.qfedu.com/xml"
xsi:schemaLocation="http://www.qfedu.com/xml student.xsd"
>
<student id="gp_0001">
<name>骚磊</name>
<age>5</age>
<sex>male</sex>
</student>
<student id="gp_0002">
<name>骚杰</name>
<age>17</age>
<sex>male</sex>
</student>
</students>
student.xsd
<?xml version="1.0"?>
<xsd:schema xmlns="http://www.qfedu.com/xml"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.qfedu.com/xml" elementFormDefault="qualified">
<!-- 根节点名字和包含的内容,内容是自定义studentType -->
<xsd:element name="students" type="studentsType"/>
<!-- studentType类型声明 -->
<xsd:complexType name="studentsType">
<xsd:sequence>
<!-- students根节点中存放的是student类型 type="studentType" 要求student的个数从0开始 个数不限制 -->
<xsd:element name="student" type="studentType" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<!-- studentType声明 -->
<xsd:complexType name="studentType">
<xsd:sequence>
<!-- 要求student标签内有name,age,sex子标签,并且要求对一个对应保存的数据类型是type指定 -->
<xsd:element name="name" type="xsd:string"/>
<!-- ageType 和 sexType 是自定义数据约束 -->
<xsd:element name="age" type="ageType" />
<xsd:element name="sex" type="sexType" />
</xsd:sequence>
<!-- 给予Student标签属性 属性为id,要声明idType, use="required"不可缺少的 -->
<xsd:attribute name="id" type="idType" use="required"/>
</xsd:complexType>
<!-- sexType性别类型声明 -->
<xsd:simpleType name="sexType">
<xsd:restriction base="xsd:string">
<!-- 有且只有两个数据 male female -->
<xsd:enumeration value="male"/>
<xsd:enumeration value="female"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="ageType">
<xsd:restriction base="xsd:integer">
<!-- 0 ~ 256 要求范围,是一个integer类型 -->
<xsd:minInclusive value="0"/>
<xsd:maxInclusive value="256"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="idType">
<xsd:restriction base="xsd:string">
<!-- ID类型,要求gp_xxxx(四位数字) -->
<xsd:pattern value="gp_\\d{4}"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:schema>
XML解析
XML解析思路
-
DOM解析
Document Object Model文档对象模型
把XML整个文件看作一个Document对象,把每一个节点看作一个Element,节点中有Attribute,或者当前节点中存在Text文本内容
DOM是将整个XML文件读取到计算机内存中,可以进行CRUC操作
缺点:占用了大量的内存空间
-
SAX解析
逐行读取,基于一定的事件操作
读取一行内容,释放上一行内容,可以有效节约内存空间
读取操作为主
使用的环境:
手机读取解析XML文件时采用的操作
DOM解析图示
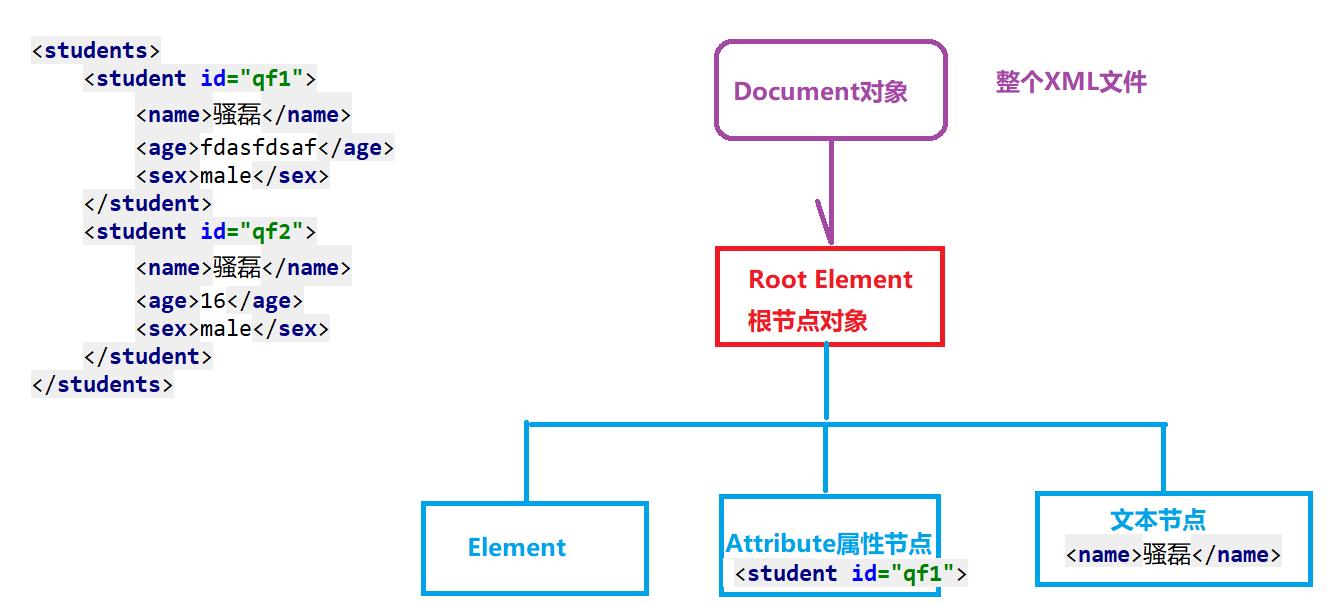
XML文件解析工具
-
JAXP:sun提供的基本的解析器,支持DOM和SAX两种解析方式,但是操作繁琐,不便于程序开发
-
Dom4j:DOM For Java
优秀的解析器
Spring, SpringMVC框架中集成的XML解析器
-
Jsoup:基于Java完成的对于html解析的工具,HTML和XML都是标记语言
给Jsoup一个URL,Java小爬虫,API较多,方便
-
PULL
android手机上集成的XML解析工具,SAX方式解析
Dom4j使用
-
导包
使用第三方工具,不是原生JDK,所以需要导入第三方jar包
IDEA导包方法
1.新建lib文件夹

2.将jar文件拖入lib文件夹

3.设置关联


选中目录

点击ok
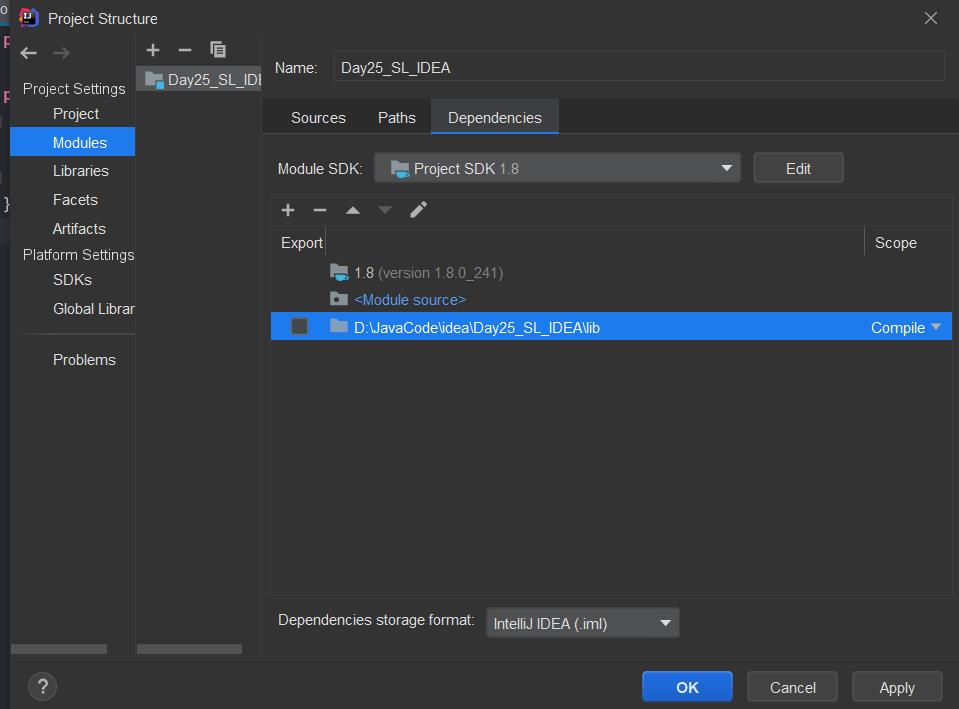
参与编译,点击ok
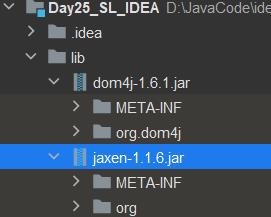
jar包处于可以打开状态,设置完毕
Dom4j解析方法:
SAXReader();
解析XML文件使用的核心类
read() --> XML文件Document对象
Document document = new SAXReader().read(new File("./path"));
Document对象中可以使用的方法:
Element getRootElement();
获取当前XML文件的根节点
Element对象中可以使用的方法:
List elements();
当前节点下的所有子节点
List elements(String name);
获取当前节点下所有指定名字的子节点
Element element()
获取当前节点下第一个子节点
Element element(String name)
获取当前节点下指定名字的第一个子节点
Attribute getAttribute(String name);
根据属性名获取对应的属性对象Attribute
Attribute节点中可以使用String getValue()来获取对应的节点数据
String getName();
获取当前节点的名字
String getText();
获取当前节点对应的文本数据
实例:
User.xml
<?xml version="1.0" encoding="utf-8"?>
<users>
<teacher id="1">
<name>ocean</name>
<age>19</age>
<gender>male</gender>
</teacher>
</users>
package cn.ocean888.a_xmlparse;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
public class Demo1 {
public static void main(String[] args) throws DocumentException {
File file = new File("./xml/User.xml");
// 创建一个SAXReader Dom4j操作XML文件的核心类
SAXReader saxReader = new SAXReader();
// 当前XML文件的Document对象
Document document = saxReader.read(file);
// 建议直接一步
// Document document = new SAXReader.read(new File("./xml/User.xml"));
// 获取根节点Root ELement
Element rootElement = document.getRootElement();
System.out.println(rootElement);
System.out.println("======================");
// 获取Root Element下子节点
List<Element> elementList = rootElement.elements();
for (Element element : elementList) {
System.out.println(element);
}
System.out.println("======================");
// 可以获取当前当前节点下所有子节点
Element teacher = rootElement.element("teacher");
System.out.println(teacher);
System.out.println("======================");
List<Element> elementList1 = teacher.elements();
for (Element element : elementList1) {
System.out.println(element.getName() + ":" + element.getText());
}
System.out.println("======================");
// 获取指定节点属性值
System.out.println(teacher.attribute("id").getValue());
}
}
运行结果:

Dom4j Xpath解析
- 创建Document对象
- 获取根节点
- 获取所需节点
package cn.ocean888.a_xmlparse;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
public class Demo2 {
public static void main(String[] args) throws DocumentException {
// 当前XML文件的Document对象
Document document = new SAXReader().read(new File("./xml/User.xml"));
// 获取根节点 Root Element
Element rootElement = document.getRootElement();
// 无视目录结构和解析状态,直接获取所有的user节点
List list = rootElement.selectNodes("//user");
for (Object o:list ) {
Element element = (Element) o;
int id = Integer.parseInt(element.attributeValue("id"));
String name = element.element("name").getText();
int age = Integer.parseInt(element.element("age").getText());
String gender = element.element("gender").getText();
System.out.println("User[id=" + id + ", name" + name + ", age" + age + ", gender" + gender + "]");
}
System.out.println("==================================");
System.out.println();
// //user[index] 不考虑路径关系,获取当前XML文件中单个指定的user节点
Node node = rootElement.selectSingleNode("//user[1]");
System.out.println(node);
System.out.println("==================================");
System.out.println();
// //user[@id=9] 不考虑路径
Node node1 = rootElement.selectSingleNode("//user[@id=9]");
System.out.println(node1);
System.out.println("==================================");
System.out.println();
// //user[gender='male'] 不考虑路径关系,获取当前XML文件中指定子文件为gender,对应子节点文本为male的节点
List list1 = rootElement.selectNodes("//user[gender='male']");
for (Object o:list1) {
System.out.println(o);
}
System.out.println("==================================");
System.out.println();
List list2 = rootElement.selectNodes("//user[age<20]");
for (Object o:list2) {
System.out.println(o);
}
}
}

public class Demo3 {
public static void main(String[] args) throws DocumentException {
Document read = new SAXReader().read(new File("./xml/User.xml"));
Element rootElement = read.getRootElement();
// //user[last()] 这里不是考虑路径关系,获取最后一个user节点
Node node = rootElement.selectSingleNode("//user[last()]");
System.out.println(node);
System.out.println("====================================");
System.out.println();
// //user[position()<3] 不考虑路径关系,获取前两个User节点
List list = rootElement.selectNodes("//user[position()<3]");
for (Object o:list) {
System.out.println(o);
}
System.out.println("====================================");
// //name | //age 无视路径关系,获取所有的name节点和age节点
List list1 = rootElement.selectNodes("//name | //age");
for (Object o:list1) {
// 允许强转
Element element = (Element) o;
System.out.println(element.getText());
}
}
}

XML文件保存
流程:
-
创建Document对象
-
通过Document对象来添加元素
addElement();
addAttribute();
以上是关于Java基础-xml解析的主要内容,如果未能解决你的问题,请参考以下文章
从 XML 声明片段获取 XML 编码:部分内容解析不支持 XmlDeclaration