以太坊Geth Trie源码解析
Posted 平平无奇的程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了以太坊Geth Trie源码解析相关的知识,希望对你有一定的参考价值。
引言
Merkle Patricia Trie 是一种经过改良的、融合了默克尔树(Merkle Trie)和前缀树(Patricia Trie)两种树结构优点的数据结构,是以太坊中用来存储键值数据对(Key, Value)的重要树形数据结构。
MPT树具有以下几个作用:
- 存储任意长度的 Key-Value 键值对数据;
- 提供了一种快速计算所维护数据集哈希标识的机制;
- 提供了快速状态回滚的机制;
- 提供了一种称为默克尔证明的证明方法,进行轻节点的扩展,实现简单支付验证;
由于MPT结合了默克尔树及前缀树的优势,因此,在对其进行介绍之前,我们会首先对这两种树进行简要的介绍,同时我们还会分析以太坊中需要借助到MPT进行存储管理的数据结构。
以太坊中的MPT
由于MPT可以存储任意的键值对数据,因此,在以太坊的实现过程中,它将会借助这棵树来记录世界状态,账户存储内容,交易以及交易收据。即以太坊中存在四种MPT,分别为:
- 世界状态树包括了从地址到账户状态之间的映射。 世界状态树的根节点哈希值由区块保存(stateRoot 字段),它标识了区块创建时的当前状态。整个网络中只有一个世界状态树。
- 账户存储树保存了与某一智能合约相关的数据信息。账户存储树的根节点由账户状态保存(storageRoot 字段)。每个账户都有一个账户存储树。
- 交易树记录了一个区块中的所有交易信息。交易树的根节点哈希值由区块保存(transactionsRoot 字段),它是当前区块内所有交易组成的树。每个区块都有一棵交易树。
- 交易收据树记录了一个区块中的所有交易收据信息。同样由区块保存(receiptsRoot 字段),它是当前区块内所有交易收据组成的树。每个区块都有一棵交易收据树。
我们可以用一张图来概括上面的四种MPT:

默克尔树
默克尔树(又叫哈希树)是一种典型的二叉树结构,由一个根节点、一组中间节点和一组叶节点组成。默克尔树最早由 Merkle Ralf 在 1980 年提出,曾广泛用于文件系统和 P2P 系统中。
其主要特点为:
- 最下面的叶节点包含存储数据或其哈希值。
- 非叶子节点(包括中间节点和根节点)都是它的两个孩子节点内容的哈希值。
进一步地,默克尔树可以推广到多叉树的情形,此时非叶子节点的内容为它所有的孩子节点的内容的哈希值。对于如下图所示的默克尔树:

它的典型应用包括如下几个场景:
- 快速比较大量数据
当两个默克尔树根相同时,则意味着所代表的两组数据必然相同。否则,必然不同。由于 Hash 计算的过程可以十分快速,预处理可以在短时间内完成。利用默克尔树结构能带来巨大的比较性能优势。 - 快速定位修改(错误)
如果 D1 中数据被修改,会影响到 N1,N4 和 Root。因此,一旦发现某个节点如 Root 的数值发生变化,沿着 Root --> N4 --> N1,最多通过 O(lgN) 时间即可快速定位到实际发生改变的数据块 D1。 - 证明某个集合中存在或不存在某个元素
假设我要验证 D0 在集合中,那么我只需要获得 N1 和 N5,再计算得到根节点的哈希。最后与公开的 Root 进行比较,我就可以知道 D0 是否包含在集合之中。
在以太坊中,利用默克尔树可以进行轻节点扩展,对于每个区块,仅仅需要存储约80个字节大小的区块头数据,而不存储交易列表,回执列表等数据,便可以验证一笔交易是否被包含在这个区块当中。同时利用默克尔树也可以实现快速重哈希,当树节点内容发生变化时,能够在前一次哈希计算的基础上,仅仅将被修改的树节点进行哈希重计算,便能得到一个新的根哈希用来代表整棵树的状态
前缀树
前缀树(又称字典树),用于保存关联数组,其键(Key)的内容通常为字符串。前缀树节点在树中的位置是由其键的内容所决定的,即前缀树的Key被编码在根节点到该节点的路径中。
如下图所示,图中共有4个叶子节点,其 Key 的值分别为 am,bad,be,so。

以太坊 MPT 设计原理
尽管前缀树可以起到维护 Key-Value 数据的目的,但是其具有十分明显的局限性。无论是查询操作,还是对数据的增删改,不仅效率低下,且存储空间浪费严重。因此,以太坊对其进行了改进,新增了几种不同类型的树节点,以尽量压缩整体的树高、降低操作的复杂度。
以太坊 MPT 节点分类
在以太坊的 MPT 树中,树节点可以分为以下四类:
- 空节点(nil)
- 分支节点(fullNode)
- 叶子节点(shortNode)
- 扩展节点(shortNode)
它们各自在以太坊客户端源码中的定义如下:
type (
fullNode struct {
Children [17]node // Actual trie node data to encode/decode (needs custom encoder)
flags nodeFlag
}
shortNode struct {
Key []byte
Val node
flags nodeFlag
}
hashNode []byte
valueNode []byte
)
// nilValueNode is used when collapsing internal trie nodes for hashing, since
// unset children need to serialize correctly.
var nilValueNode = valueNode(nil)
// nodeFlag contains caching-related metadata about a node.
type nodeFlag struct {
hash hashNode // cached hash of the node (may be nil)
dirty bool // whether the node has changes that must be written to the database
}
注意到,叶子节点和扩展节点在源码实现中是由同一个数据结构表示的。如果一个节点是叶子节点,那么它的 Val 字段是一个 valueNode,即它表示相应键 Key 对应的 值 Value;如果一个节点是扩展节点,那么它的 Val 字段是 hashNode,即它表示下一个节点的哈希,类似于指针指向下一个节点。nodeFlag字段记录了当前节点的哈希以及当前节点是否被修改过的标志。注意到,hashNode存在的作用是为了当用户需要从数据库中加载MPT树时,不需要加载整颗完整的树,只需要加载用到的部分,剩下不需要加载的直接用它的哈希来代替即可。
MPT 同样把 Key-Value 数据项的 Key 编码在树的路径中,但是如果对 Key 以字节为单位进行拆分,那么就会导致分支节点产生的分支太多(极端情况下需要 256 个分支)。因此在以太坊中,在进行树操作之前,首先会进行一个 Key 编码的转换(后面会详述),主要是将一个字节的高低四位内容分拆成两个字节存储。此时,对于一个分支节点 fullNode,只需要存储 16 个分支,另外对于源码的 fullNode 中 Children 的最后一项,它可以是一个 valueNode。
另外,对于原始的前缀树,它会存在键 Key 的路径过长的问题,因此就会出现严重的存储空间浪费的情况。MPT利用shortNode 实现了编码路径的压缩。
下面给出了一个 MPT 的例子🌰:
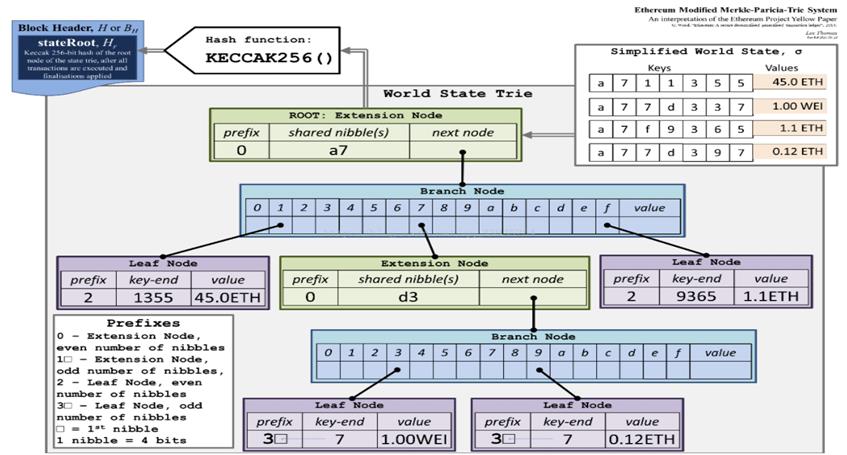
Key编码
在以太坊中,MPT 树的 Key 值共有三种不同的编码方式,以满足不同场景的不同需求,在这里单独作为一节进行介绍。
三种编码方式分别为:
- Raw编码(外部输入);
- Hex编码(内存);
- Hex-Prefix编码(磁盘);
Raw编码
Raw编码就是原生的 Key 值,不做任何改变。这种编码方式的 Key,是MPT对外提供接口的默认编码方式。
比如,外部输入的一个键值对为{“cat”: “dog”},那么这个数据 Key 值的编码为 [‘c’,‘a’,‘t’] ,转换成 ASCII 码的表示方式就是 [63,61,74]。
另外,需要注意的是,外部输入的数据通常不是简单的字符串形式,它可能是一个复杂的数据结构。因此,这些输入数据通常会经过 RLP 编码之后,才能作为传入 Hex 编码的键值对。举个例子,一个外部输入可能是{Address(0x123456):100},它的 Key 值为 Address(0x123456),假设它经过 RLP 编码后的结果为 0xC2123456,那么其实在将它传入 Hex 编码所用到的 Key 值为 0xC2123456 而不是 Address(0x123456)。同样地,不仅 Key 值的部分需要进行 RLP 编码,最终记录的 Value 值部分也需要进行 RLP 编码。
Hex编码
在介绍分支节点的时候,我们提到,为了减少分支节点孩子的个数,需要将 Key 的编码进行转换,将原 Key 的高低四位分拆成两个字节进行存储。这种转换后的 Key 的编码方式,就是 Hex 编码。Hex 编码是 Key 在内存中的存储形式。
Raw编码向Hex编码的转换规则如下:
- 将Raw编码的每个字符,根据高4位低4位拆成两个字节;
- 若该 Key 对应的节点存储的是真实的数据项内容(即该节点是叶子节点),则在末位添加一个ASCII值为16的字符作为终止标志符;
- 若该 Key 对应的节点存储的是另外一个节点的哈希索引(即该节点是扩展节点),则不加任何字符;
举个例子,Key为 [‘c’,‘a’,‘t’]([63,61,74]),Value为数据项,其Hex编码为[3, 15, 3, 13, 4, 10, 16];若 Value 为另一个节点的哈希索引,其Hex编码为[3, 15, 3, 13, 4, 10]。
在以太坊的Trie模块中,Key和Value都是 []byte 类型。如果要使用其它类型,需要将其转换成 []byte 类型(RLP编码进行转换)。但是,在内存中Key的最小单位不是 byte 而是 nibble,而 nibble 实际上就是一个4位的二进制数。因此,byte型的Key值当存储在内存中时,需要将其转变为nibble型,也就是上面说的Raw编码向Hex编码转换,即根据高4位低4位进行拆成。由于go语言中实际上是没有nibble 类型的,因此 niblle 实际上也是用 byte 进行表示,只不过它的高4位都为0。
HP编码
在介绍叶子节点和扩展节点时,我们介绍了这两种节点定义是共享的(它们是由同一个数据结构 shortNode 表示的),即便持久化到数据库中,存储的方式也是一致的。那么当节点加载到内存是,同样需要通过一种额外的机制来区分节点的类型。于是以太坊就提出了一种HP编码对存储在数据库中的叶子和扩展节点的 Key 进行编码区分。同时,将这两类节点从内存中持久化到磁盘中之前,需要进行相应的编码转换:
Hex编码向HP编码的转换规则如下:
- 若原Key的末尾字节的值为16(即该节点是叶子节点),去掉该字节;
- 在Key之前增加一个nibble(半字节),其中最低位用来编码原本Key长度的奇偶信息,Key长度为奇数,则该位为1;低2位中编码一个特殊的终止标记符,若该节点为叶子节点,则该位为1;具体内容如下:
| 比特 | 节点类型 | 奇偶|
| ---- | ---- | ----|
| 0000 | 扩展节点| 偶数|
| 0001 | 扩展节点| 奇数|
| 0010 | 叶子节点| 偶数|
| 0011 | 叶子节点| 奇数| - 若原本Key的长度为奇数(原本为奇数个nibble,那么去掉末尾 nibble 16 再增加一个 nibble 之后仍然是奇数个nibble,无法合并成byte,因此需要添加额外的半字节),则在Key之前再增加一个值为0x0的半字节;
- 最后将Key的内容作压缩,两个nibble合并为一个字节;
若Hex编码为 [3, 15, 3, 13, 4, 10, 16],则HP编码的值为 [32, 63, 61, 74]。
类似地,从磁盘中读取 Key 到内存中时,将HP编码转化为Hex编码的过程就是上面的反过程。
转换关系
这几种编码的转换关系如下图所示:

- Raw编码:这是外界输入的编码方式,通常对于一个复杂类型的变量,经过RLP编码后的结果便可以作为Raw编码输入。当其要被存储在内存中的MPT树上的时候,它将会被转化为Hex编码形式。
- Hex编码:这是数据被存储在内存中的MPT树上的编码方式,它以nibble为单位。当树节点要被持久化到磁盘中的时候,需要将Hex编码转化为HP编码。
- HP编码:这是数据被存储在磁盘中的编码方式,它以byte为单位。当树节点从磁盘中读入内存时,需要将HP编码转化为Hex编码。
以上所说的编码方式均是对 Key 值进行编码,而对 Value 值则直接采用它的RLP编码。
安全的MPT
以上介绍的MPT树,可以用来存储内容为任何长度的 Key-Value 数据项。倘若数据项的Key长度没有限制时,当树中维护的数据量较大时,仍然会造成整棵树的深度变得越来越深,会造成以下影响:
查询一个节点可能会需要许多次IO读取,效率低下;
- 系统易遭受Dos攻击,攻击者可以通过在合约中存储特定的数据,“构造”一棵拥有一条很长路径的树,然后不断地调用SLOAD指令读取该树节点的内容,造成系统执行效率极度下降;
- 所有的Key其实是一种明文的形式进行存储;
- 为了解决以上问题,在以太坊中对MPT再进行了一次封装,对数据项的Key进行了一次哈希计算,因此最终作为参数传入到MPT接口的数据项其实是(SHA3(Key), Value)
优势:
- 传入MPT接口的Key是固定长度的(32字节),可以避免出现树中出现长度很长的路径;
劣势:
- 每次树操作需要增加一次哈希计算;
- 需要在数据库中存储额外的SHA3(Key)与Key之间的对应关系;
状态提交(持久化存储)
对于被加载到内存中的MPT树,Geth客户端应该提供以下功能:
- Get:获取MPT树中相应Key对应的Value
- Insert:插入一个键值对到MPT树中,同时对修改节点的dirty位标记为true
- Delete:从MPT树1中删除一个键值对,同时对修改节点的dirty位标记为true
- Update:Insert和Delete操作的结合
除了上述操作之外,以太坊的MPT需要实现将存储到内存中的MPT树持久化到本地磁盘中的功能,即Commit。在提交完成后,所有变脏的树节点会重新进行哈希计算,并且将新内容写入数据库;最终新的根节点哈希将被作为MPT的最新状态被返回。
需要注意到的是,对一个节点进行提交是一个递归的操作,它会首先计算这个节点所有变脏的孩子节点的哈希,并将这些孩子节点进行提交,之后再修改该节点的 Value 字段指向新的孩子节点的哈希,最后计算当前节点的哈希值。同时,对孩子节点的哈希值计算过程中,可能需要计算孩子节点的孩子(如果存在且被修改的话)相应的哈希,因此这个过程是一个递归的过程。下图是一个例子:
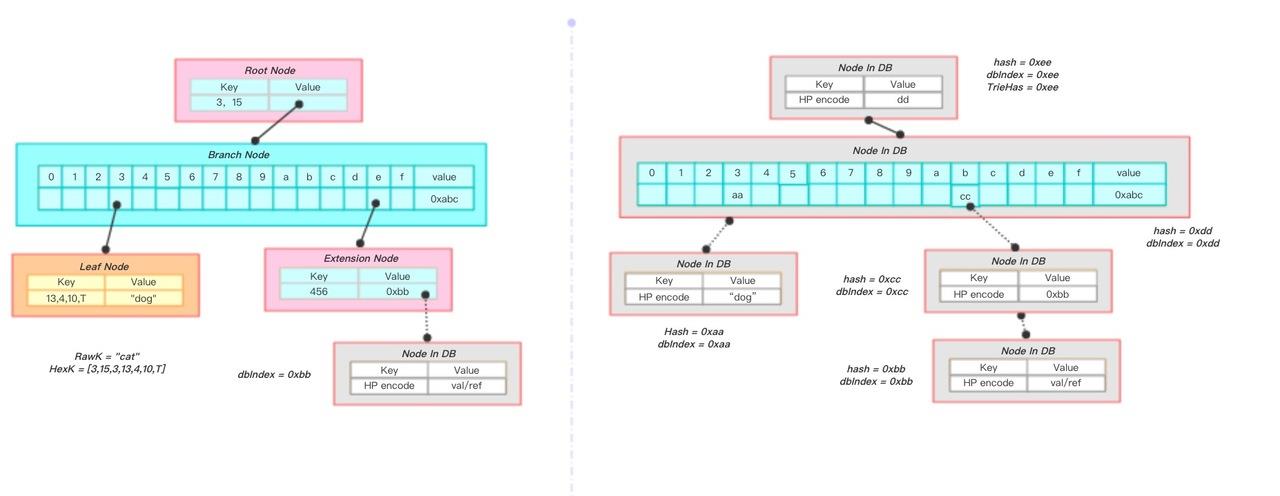
如果要将这棵树进行可持久化存储,需要首先计算得到左下角叶子节点的哈希 0xaa(这同样也是它存储在持久化数据库中的索引),再计算粉色节点的哈希 0xcc,然后由得到的这两个节点计算分支节点的哈希 0xdd,最后计算根节点的哈希 0xee。
节点过老的判断依据
Geth客户端会清除在内存中保留时间过长且未被使用到的的节点,在判断一个节点在内存中存在时间是否过长的依据是:
- 该节点未被修改;
- 当前MPT的计数器减去节点的诞生标志超过了固定的上限;
- 每当MPT调用一次Commit函数,MPT的计数器发生自增;
快速计算所维护数据集哈希标识
这个特点体现在单节点哈希计算的第一步,即在节点哈希计算之前会对该节点的状态进行判断,只有当该节点的内容变脏,才会进行哈希重计算、数据库持久化等操作。如此一来,在某一次事务操作中,对整棵MPT树的部分节点的内容产生了修改,那么一次哈希重计算,仅需对这些被修改的节点、以及从这些节点到根节点路径上的节点进行重计算,便能重新获得整棵树的新哈希。
快速状态回滚
在公链的环境下,采用POW算法是可能会造成分叉而导致区块链状态进行回滚的。在以太坊中,由于出块时间短,这种分叉的几率很大,区块链状态回滚的现象很频繁。如下图所示:

在上图中,一个节点的内容由27变为45,就需要新增4个节点而不会修改原来的节点(实际过程中可能不止4个),就对应成创建了一条由蓝线圈出的新路径。通过结合新增的节点以及橙色圈出的未被修改的节点,可以构造一棵新树,而旧路径依旧保留。因此,通过旧stateRoot,我们依旧能够查询到在过去区块上该节点的值为27。所以,在以太坊中,发生分叉而进行世界状态回滚时,仅需要用旧的MPT根节点作为入口,即可完成状态回滚。
修剪区块
上述提到的状态回滚,仅仅保留最近几个区块的历史状态,并不会保留所有的历史状态数据。试想,如果保留所有的历史状态数据,随着以太坊的长时间运行,以太坊数据将变得非常庞大。
为了减轻数据存储的压力,以太坊提出了修剪区块的概念,即利用trie模块中的trie.Database对缓存节点进行引用计数,并在blockchain模块中进行相应的引用和解引用操作(某个节点不再被其他节点引用时便直接从可持久化存储中释放该节点)。如此释放了大量不需要保存的历史数据的存储空间。
一般用户在full模式下运行geth客户端会默认进行修剪区块的操作,当然,用户也可以选择在archive模式下运行geth客户端,在这种情况下,geth客户端将会保存所有的历史状态数据,不会进行区块的修剪。我们可以利用archive模式下的数据,复现历史区块上的交易,但是需要注意的是,这个模式下,存储的数据量是相当庞大的。
轻节点扩展
MPT能够提供的一个重要功能 - 默克尔证明,使用默克尔证明能够实现轻节点的扩展。
什么是轻节点
在以太坊或比特币中,一个参与共识的全节点通常会维护整个区块链的数据,每个区块中的区块头信息,所有的交易,回执信息等。由于区块链的不可篡改性,这将导致随着时间的增加,整个区块链的数据体量会非常庞大。运行在个人PC或者移动终端的可能性显得微乎其微。为了解决这个问题,一种轻量级的,只存储区块头部信息的节点被提出。这种节点只需要维护链中所有的区块头信息(一个区块头的大小通常为几十个字节,普通的移动终端设备完全能够承受出)。
在公链的环境下,仅仅通过本地所维护的区块头信息,轻节点就能够证明某一笔交易是否存在与区块链中;某一个账户是否存在与区块链中,其余额是多少等功能。
什么是默克尔证明
默克尔证明指一个轻节点向一个全节点发起一次证明请求,询问全节点完整的默克尔树中,是否存在一个指定的节点;全节点向轻节点返回一个默克尔证明路径,由轻节点进行计算,验证存在性。
默克尔证明过程
如有棵如下图所示的默克尔树,如果某个轻节点想要验证 9Dog:64 这个树节点是否存在与默克尔树中,只需要向全节点发送该请求,全节点会返回一个 1FXq:18, ec20, 8f74 的一个路径。得到路径之后,轻节点利用 9Dog:64 与 1FXq:18 求哈希,在与 ec20 求哈希,最后与 8f74 求哈希,得到的结果与本地维护的根哈希相比,是否相等。若相等,则证明该树节点存在于默克尔树中;否则,不存在。


默克尔证明安全性
-
若全节点返回的是一条恶意的路径?
试图为一个不存在于区块链中的节点伪造一条合法的默克尔路径,使得最终的计算结果与区块头中的默克尔根哈希相同。由于哈希的计算具有不可预测性,使得一个恶意的全节点想要为一条不存在的节点伪造一条伪路径使得最终计算的根哈希与轻节点所维护的根哈希相同是不可能的。 -
为什么不直接向全节点请求该节点是否存在于区块链中?
由于在公链的环境中,无法判断请求的全节点是否为恶意节点,因此直接向某一个或者多个全节点请求得到的结果是无法得到保证的。但是轻节点本地维护的区块头信息,是经过工作量证明验证的,也就是经过共识一定正确的,若利用全节点提供的默克尔路径,与代验证的节点进行哈希计算,若最终结果与本地维护的区块头中根哈希一致,则能够证明该节点一定存在于默克尔树中。
简单支付验证
在以太坊中,利用默克尔证明在轻节点中实现简单支付验证,即在无需维护具体交易信息的前提下,证明某一笔交易是否存在于区块链中。
以太坊 MPT 源码解析
以太坊MPT树的实现源码位于 go-ethereum/trie 目录下,我们对其中的源码文件进行简单的说明。
- encoding.go
这个文件实现了Hex编码和HP编码之间的转换,即byte和nibble之间的转换。 - node.go
这个文件定义了以太坊MPT树中的所有的节点类型。同时,它也提供了从RLP编码解析整个MPT树的方法。 - hasher.go
这个文件中的代码实现了从某个结点开始计算子树的哈希的功能(计算这个节点以及所有子孙的哈希)。可以说这个文件里的代码实现了以太坊的Trie的默克尔树特性。 - trie.go
trie.go实现了Trie对象的主要逻辑功能。 - secure_trie.go
secure_trie.go中的代码实现了SecureTrie对象。 - sync.go
这个文件中的代码实现了SyncTrie对象的定义和所有方法。 - iterator.go
这个文件中的代码定义了所有枚举相关接口和实现。 - database.go
这个文件实现了Database对象的主要逻辑功能。 - commiter.go
这个文件实现了向内存数据库提交修改后的树节点的方法。 - errors.go
errors.go中只定义了一个结构体:MissingNodeError。当找不到相应的结点时,就会返回这个错误。 - proof.go
这个文件只包含了Prove和VerifyProof两个函数,它们只在轻量级以太坊子协议(LES)中被使用。这两个函数被用来提供自己拥有某一对(Key, Value)的证明数据,以及对数据进行验证。
节点分类
前面已经介绍过,以太坊的MPT树中,树节点可以分为四类,分别为空节点,分支节点,叶子节点以及扩展节点。其中空节点为nil,分支节点被定义为数据结构fullNode,叶子节点和扩展节点都被定义为shortNode,但是根据其中的Val字段的不同,当Val字段为hashNode时,这个节点为扩展节点,当Val字段为valueNode时,这个节点为叶子节点。它们各自在源码中的定义已经在前面给出,这里就不再过多说明。
它们的定义位于encoding.go文件中,这个文件除了对节点的类型进行定义之外,还给出这些类型拥有的方法,我们对其中的主要方法进行列举,并在代码注释中给出这些方法的用途。
// EncodeRLP encodes a full node into the consensus RLP format.
// 它将一个fullNode编码成RLP形式,需要注意的是这个编码过程是不会递归进行的,它只对当前节点进行编码。
func (n *fullNode) EncodeRLP(w io.Writer) error
// decodeNode parses the RLP encoding of a trie node.
// 它将一个RLP编码的字节串解析为一个MPT节点
func decodeNode(hash, buf []byte) (node, error) {
if len(buf) == 0 {
return nil, io.ErrUnexpectedEOF
}
elems, _, err := rlp.SplitList(buf)
if err != nil {
return nil, fmt.Errorf("decode error: %v", err)
}
switch c, _ := rlp.CountValues(elems); c {
case 2:
n, err := decodeShort(hash, elems)
return n, wrapError(err, "short")
case 17:
n, err := decodeFull(hash, elems)
return n, wrapError(err, "full")
default:
return nil, fmt.Errorf("invalid number of list elements: %v", c)
}
}
//解析一个RLP编码的shortNode
func decodeShort(hash, elems []byte) (node, error) {
...
r, _, err := decodeRef(rest)
...
}
//解析一个RLP编码的fullNode
func decodeFull(hash, elems []byte) (*fullNode, error) {
...
cld, rest, err := decodeRef(elems)
...
}
func decodeRef(buf []byte) (node, []byte, error)
其中,对RLP编码进行解码过程中用到的主要函数是decodeNode(),它会根据解析节点的类型,来分别调用decodeShort()或者decodeFull()。
Trie对象的实现
关于Trie对象的操作主要可以分为两类,一类是对内存中已经加载的Trie对象进行增删查改,另一类是计算内存中Trie对象的哈希值,以及将整个树写入数据库中。
你可以使用trie.New来创建或打开一个Trie对象。
其中对于Trie对象进行增删查改的操作如下:
// Get returns the value for key stored in the trie.
// The value bytes must not be modified by the caller.
func (t *Trie) Get(key []byte) []byte
// Update associates key with value in the trie. Subsequent calls to
// Get will return value. If value has length zero, any existing value
// is deleted from the trie and calls to Get will return nil.
//
// The value bytes must not be modified by the caller while they are
// stored in the trie.
func (t *Trie) Update(key, value []byte)
// Delete removes any existing value for key from the trie.
func (t *Trie) Delete(key []byte)
除此之外,还包含TryXXX等几个类似的方法。注意到,Update方法中就已经包含了插入节点以及删除节点的操作。
对于Trie对象哈希值计算以及数据库写入的操作如下:
// Hash returns the root hash of the trie. It does not write to the
// database and can be used even if the trie doesn't have one.
func (t *Trie) Hash() common.Hash
// Commit writes all nodes to the trie's memory database, tracking the internal
// and external (for account tries) references.
func (t *Trie) Commit(onleaf LeafCallback) (root common.Hash, err error)
增删查改
对于Trie对象的增删查改,其主要是对树的某一条路径上所有节点的访问。因此,我们对这一访问过程进行总结如下图所示:
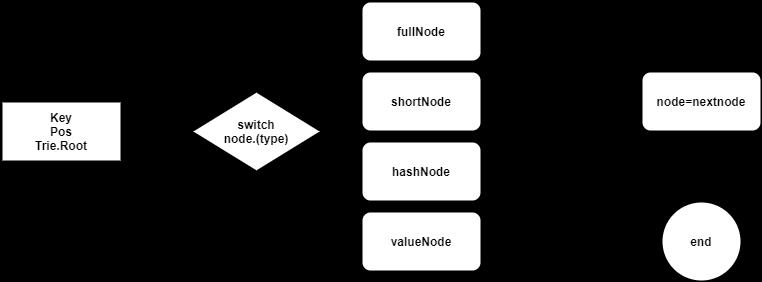
这里给出TryGet()函数的相关源码,主要为了解释对树上节点的访问过程,其他操作在访问时会涉及对树结构的修改等(如果修改发生,需要标记路径上的节点的dirty字段,这个在后面提交整颗树时会用到,它只会提交发生修改过的节点),相对复杂一点,但总体过程相似。
// TryGet returns the value for key stored in the trie.
// The value bytes must not be modified by the caller.
// If a node was not found in the database, a MissingNodeError is returned.
func (t *Trie) TryGet(key []byte) ([]byte, error) {
value, newroot, didResolve, err := t.tryGet(t.root, keybytesToHex(key), 0)
if err == nil && didResolve {
t.root = newroot
}
return value, err
}
func (t *Trie) tryGet(origNode node, key []byte, pos int) (value []byte, newnode node, didResolve bool, err error) {
switch n := (origNode).(type) {
case nil:
return nil, nil, false, nil
case valueNode:
return n, n, false, nil
case *shortNode:
if len(key)-pos < len(n.Key) || !bytes.Equal(n.Key, key[pos:pos+len(n.Key)]) {
// key not found in trie
return nil, n, false, nil
}
value, newnode, didResolve, err = t.tryGet(n.Val, key, pos+len(n.Key))
if err == nil && didResolve {
n = n.copy()
n.Val = newnode
}
return value, n, didResolve, err
case *fullNode:
value, newnode, didResolve, err = t.tryGet(n.Children[key[pos]], key, pos+1)
if err == nil && didResolve {
n = n.copy()
n.Children[key[pos]] = newnode
}
return value, n, didResolve, err
case hashNode:
child, err := t.resolveHash(n, key[:pos])
if err != nil {
return nil, n, true, err
}
value, newnode, _, err := t.tryGet(child, key, pos)
return value, newnode, true, err
default:
panic(fmt.Sprintf("%T: invalid node: %v", origNode, origNode))
}
}
其中tryGet()方法的返回参数value表示相应Key所对应的Value值,didResolve表示当遇到hashNode时需要从数据库中加载相应的shortNode节点或者fullNode节点,如果加载成功,则该字段为true。在这之后,则要修改所有这个hashNode之前节点的指针,即Val字段,因为在没有加载之前hashNode的父节点的Val字段是指向一个hashNode节点的,而在加载之后它会被更新为其他节点,因此需要依次地修改这条路上所有节点的指针,其中newnode就是为这个步骤准备的。
tryGet()方法是递归调用的,如果该方法执行成功,则会返回查询结果value。如果在该方法的调用过程中,需要从数据库中加载新的节点,那么从根节点到这条节点路径上的所有节点都会被修改,最终Trie对象的root也会被修。
哈希计算及提交
Trie对象中计算哈希的方法如下所示,它会对那些树上修改过的节点(dirty字段为true)重新计算哈希值:
// Hash returns the root hash of the trie. It does not write to the
// database and can be used even if the trie doesn't have one.
func (t *Trie) Hash() common.Hash {
hash, cached, _ := t.hashRoot(nil)
t.root = cached
return common.BytesToHash(hash.(hashNode))
}
// hashRoot calculates the root hash of the given trie
func (t *Trie) hashRoot(db *Database) (node, node, error) {
...
h := newHasher(t.unhashed >= 100)
defer returnHasherToPool(h)
hashed, cached := h.hash(t.root, true)
...
}
其中完成主要功能的函数为hash(),这个函数的定义位于hasher.go文件中,我们会在后续进行介绍。
Trie对象中将MPT树提交到数据库的方法如下所示:
// Commit writes all nodes to the trie's memory database, tracking the internal
// and external (for account tries) references.
func (t *Trie) Commit(onleaf LeafCallback) (root common.Hash, err error) {
...
rootHash := t.Hash()
h := newCommitter()
defer returnCommitterToPool(h)
// Do a quick check if we really need to commit, before we spin
// up goroutines. This can happen e.g. if we load a trie for reading storage
// values, but don't write to it.
if _, dirty := t.root.cache(); !dirty {
return rootHash, nil
}
...
var newRoot hashNode
newRoot, err = h.Commit(t.root, t.db)
...
t.root = newRoot
return rootHash, nil
}
其中完成主要功能的函数为Commit(),这个函数的定义位于commiter.go文件中,我们会在后续进行介绍。
hasher.go
该文件提供了计算一个节点及其所有子孙节点哈希值的方法,最终计算的哈希值存放在节点的nodeflag字段中,它的主要函数内容如下:
// hash collapses a node down into a hash node, also returning a copy of the
// original node initialized with the computed hash to replace the original one.
func (h *hasher) hash(n node, force bool) (hashed node, cached node) {
// Return the cached hash if it's available
if hash, _ := n.cache(); hash !=