Elasticsearch——创建/查看/删除索引创建/查看/修改/删除文档映射关系
Posted 张起灵-小哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch——创建/查看/删除索引创建/查看/修改/删除文档映射关系相关的知识,希望对你有一定的参考价值。
文章目录:
1.Elasticsearch中的数据格式
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 mysql 存储数据的概念进行一个类比。
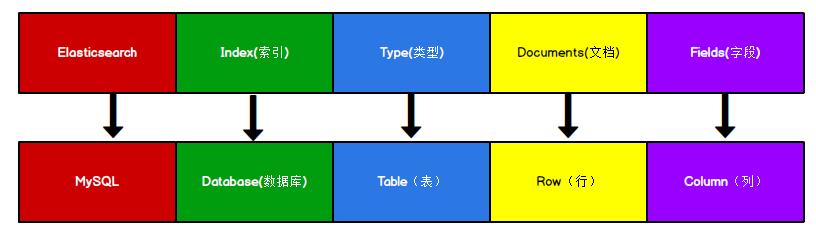
ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个 type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
2.索引操作
2.1 创建索引
在ES中创建一个索引,就相当于在mysql中创建了一个数据库,而mysql中的数据库肯定是不能重复的,也即ES中的索引也不能重复,所以这是一个幂等性操作,需要发送PUT请求(如果重复发送PUT请求、重复添加索引,会返回错误信息),这里不能发送POST请求。

2.2 查看指定索引
在 Postman 中,向 ES 服务器发 GET 请求。这里的路径和上面的创建索引是一样的,只是请求方式不一样。
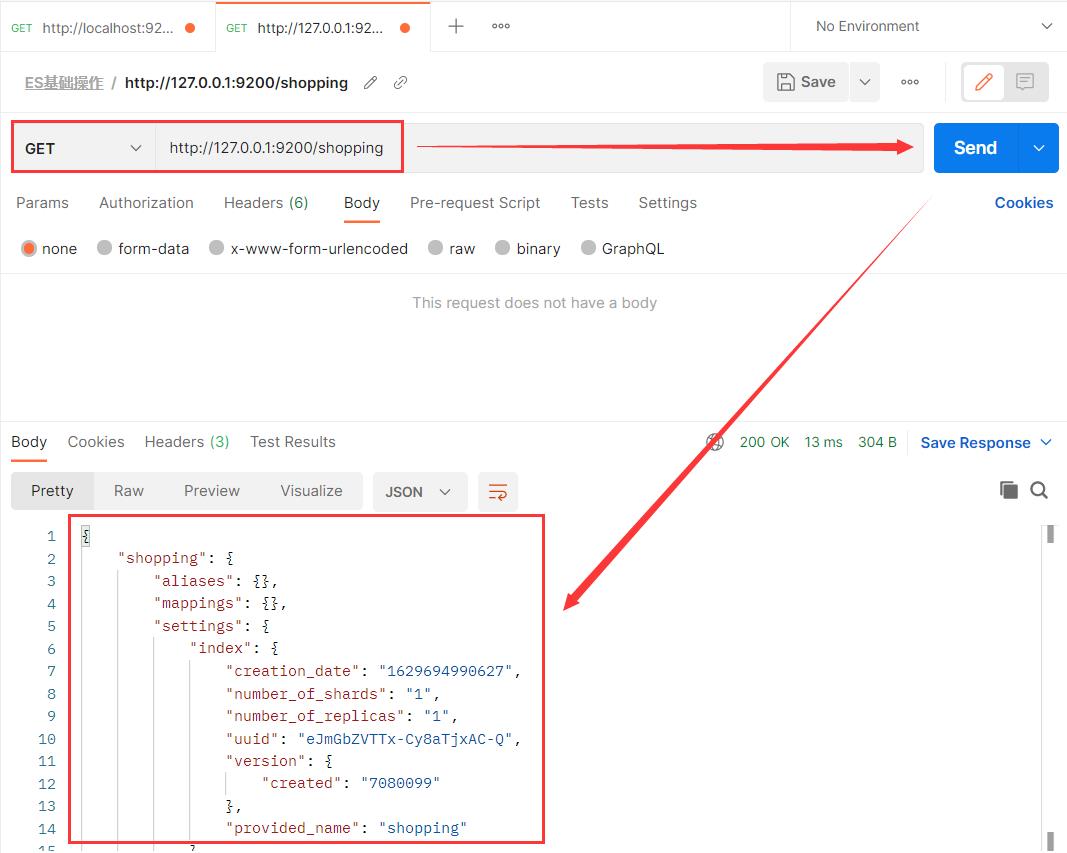
2.3 查看全部索引
在 Postman 中,向 ES 服务器发 GET 请求。
- health 当前服务器健康状态:green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
- status 索引打开、关闭状态
- index 索引名
- uuid 索引统一编号
- pri 主分片数量
- rep 副本数量
- docs.count 可用文档数量
- docs.deleted 文档删除状态(逻辑删除)
- store.size 主分片和副分片整体占空间大小
- pri.store.size 主分片占空间大小

2.4 删除索引
在 Postman 中,向 ES 服务器发 DELETE 请求。

3.文档操作
3.1 创建文档
索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式
在 Postman 中,向 ES 服务器发 POST 请求。
{
"title":"小米手机",
"category":"小米",
"image":"http://www.szh.com/szh.jpg",
"price":3999.00
}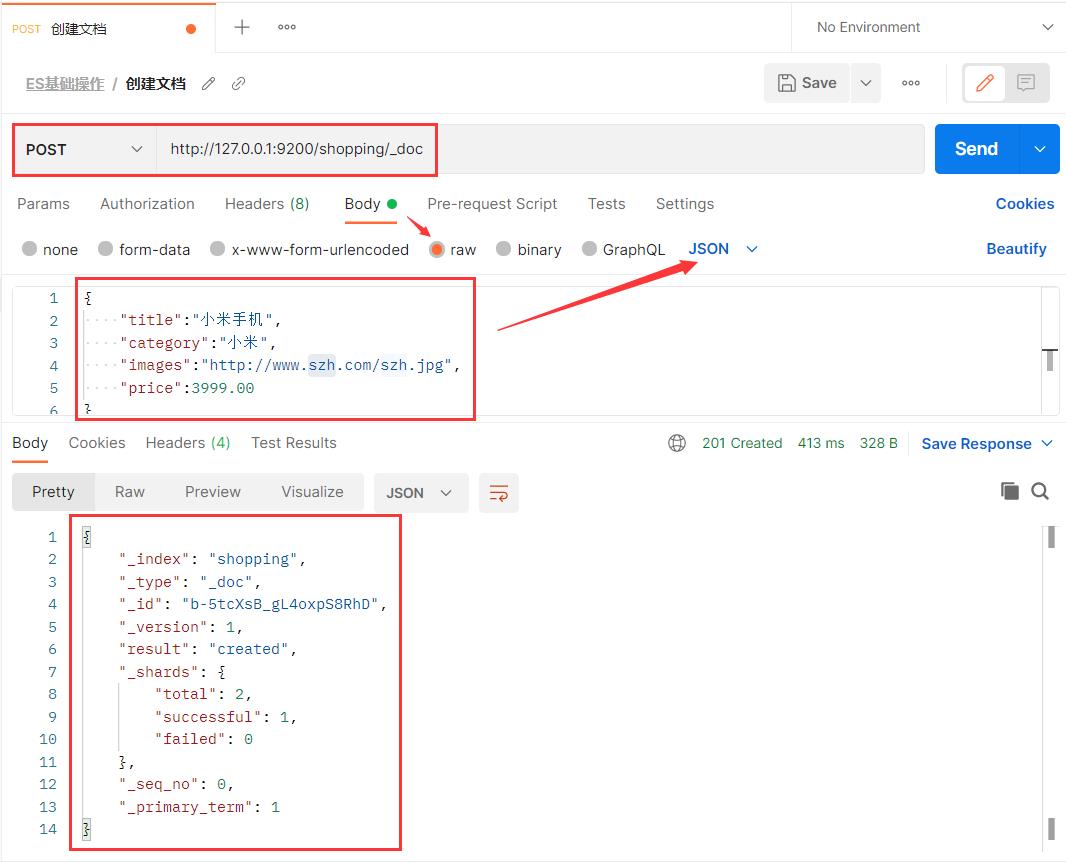
上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下,ES 服务器会随机生成一个。
如果想要自定义唯一性标识,需要在创建时指定。推荐使用下面这种方式创建文档。
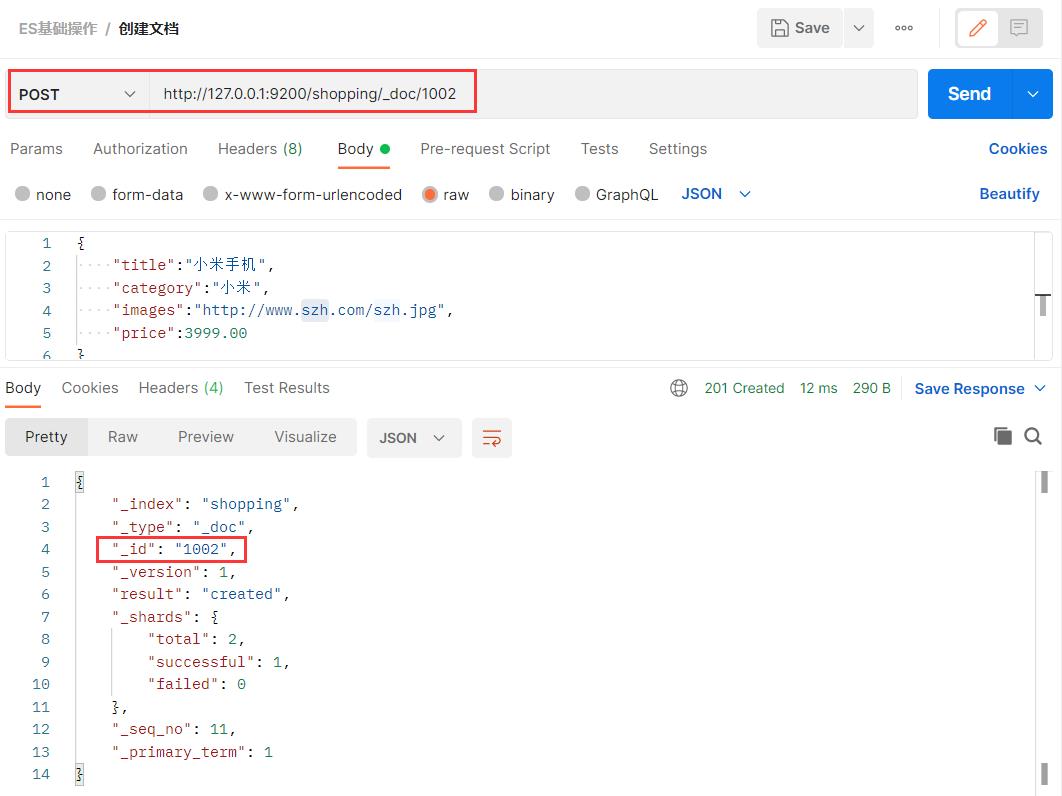
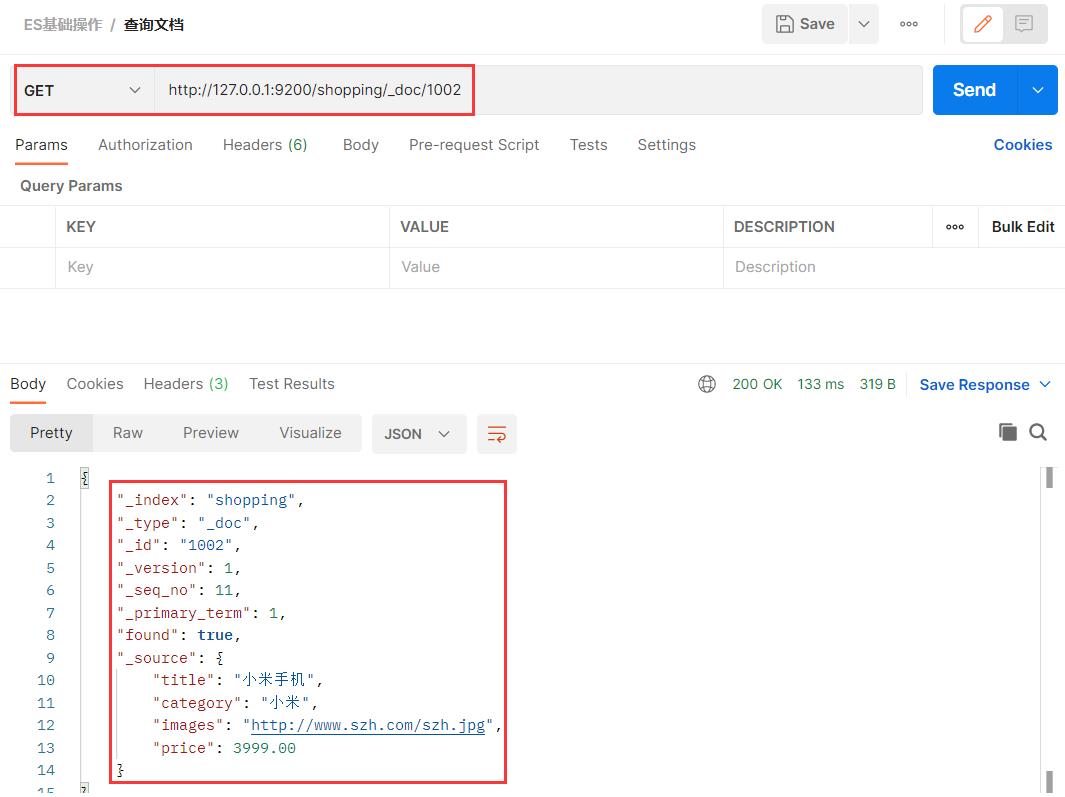
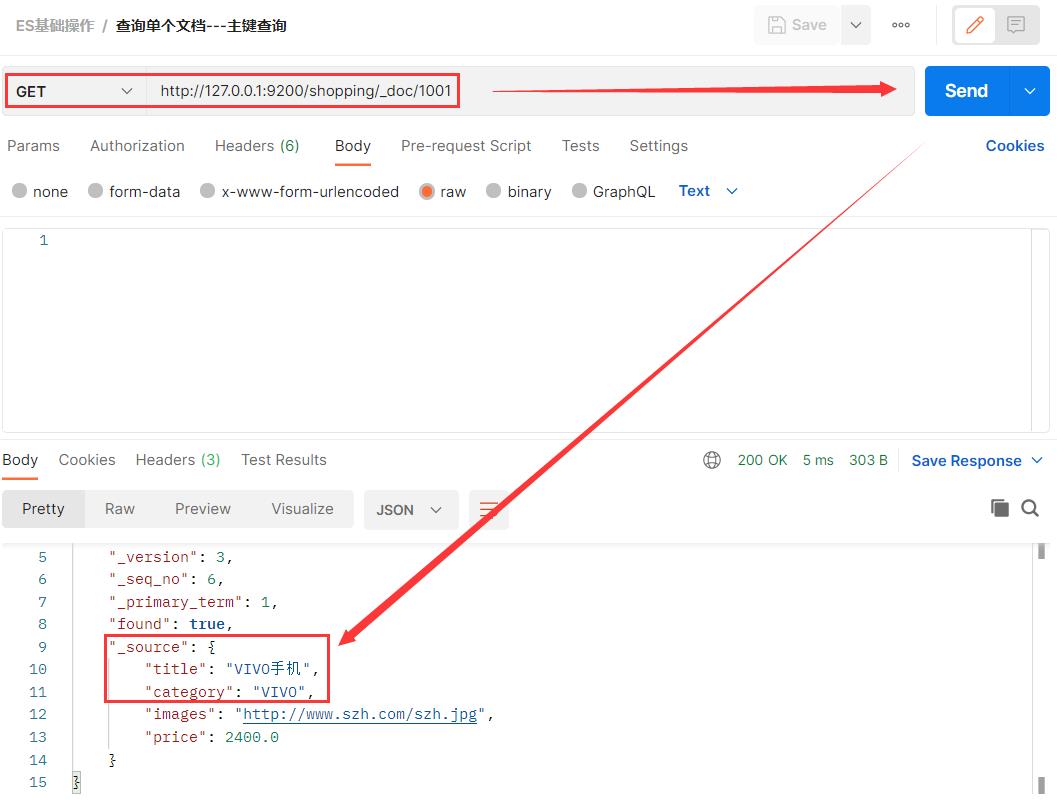
3.2 查看单个文档:主键查询
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询。在 Postman 中,向 ES 服务器发 GET 请求。
3.3 查看所有文档:全查询
# "query":这里的 query 代表一个查询对象,里面可以有不同的查询属性
# "match_all":查询类型,例如:match_all(代表查询所有), match,term , range 等等
# {查询条件}:查询条件会根据类型的不同,写法也有差异

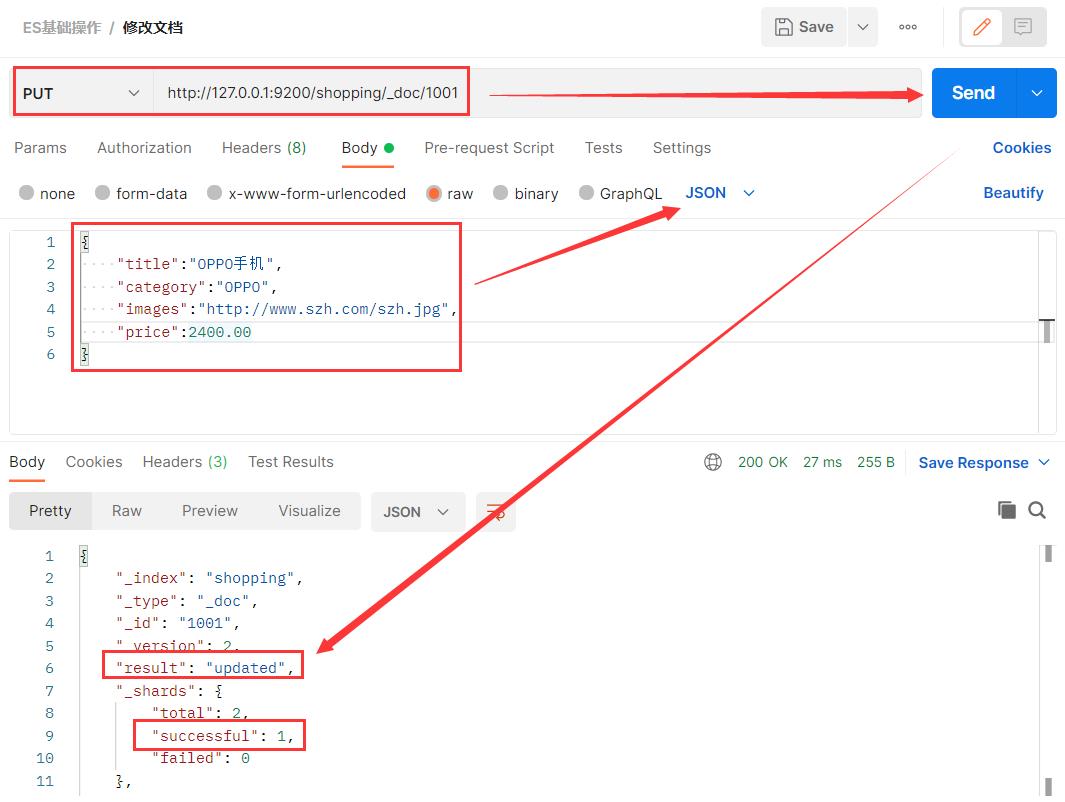
3.4 修改文档中的全部字段
修改数据时,也可以只修改某一给条数据的局部信息,也可以修改所有字段信息。
修完完之后,再次发送GET请求,查看修改后的文档内容。
{
"title":"OPPO手机",
"category":"OPPO",
"images":"http://www.szh.com/szh.jpg",
"price":2400.00
}

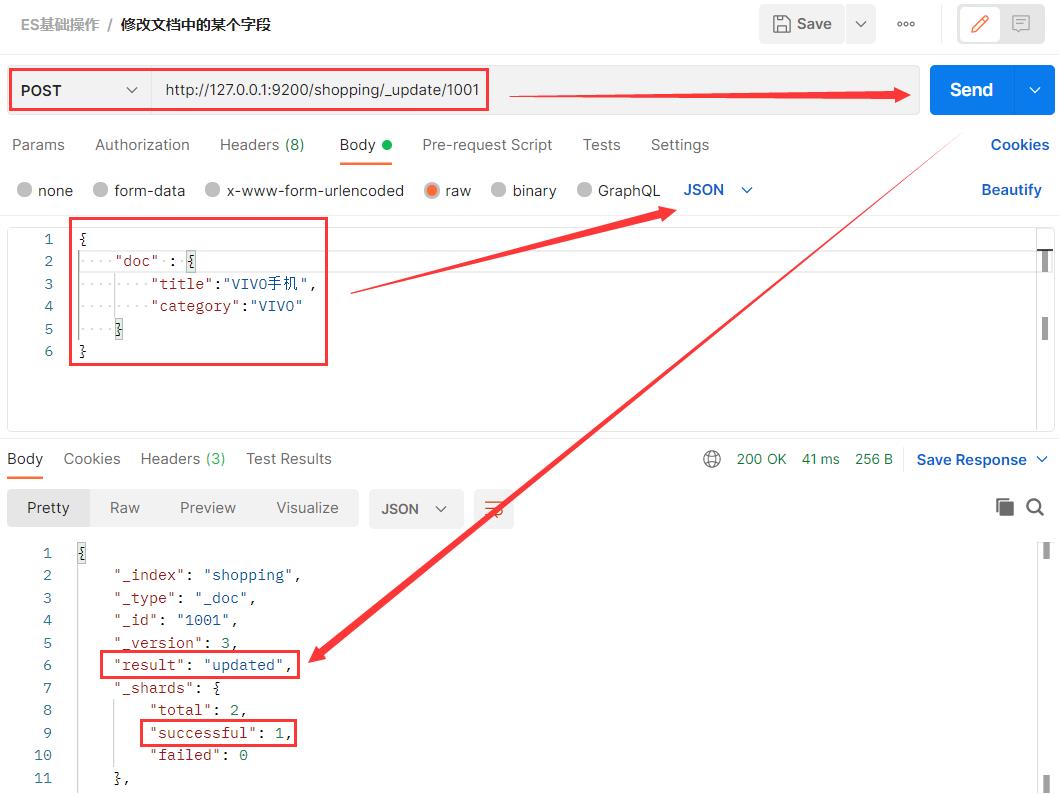
3.5 修改文档中的某个字段
{
"doc" : {
"title":"VIVO手机",
"category":"VIVO"
}
}
3.6 删除文档
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。在 Postman 中,向 ES 服务器发 DELETE 请求。

3.7 条件查询文档内容
match 匹配类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是 or 的关系。
在 Postman 中,向 ES 服务器发 GET 请求。
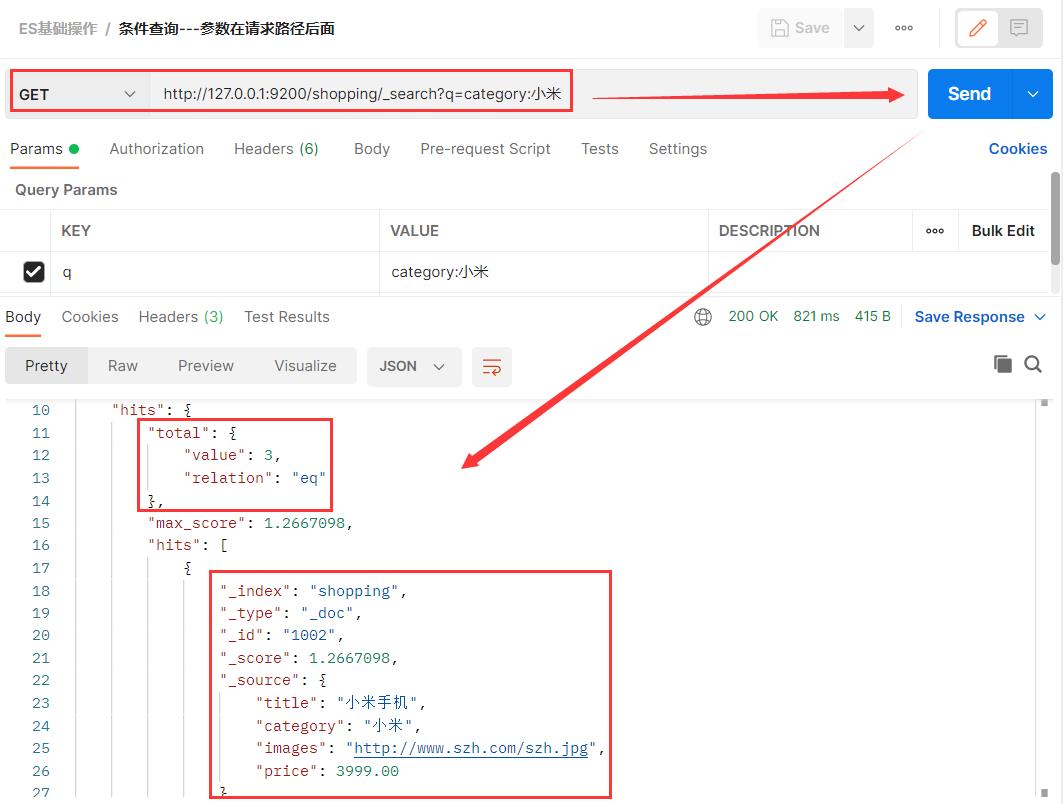
上面这种查询方式的请求参数是直接跟在请求路径之后的,这种方式不太好,因为有可能造成乱码问题。
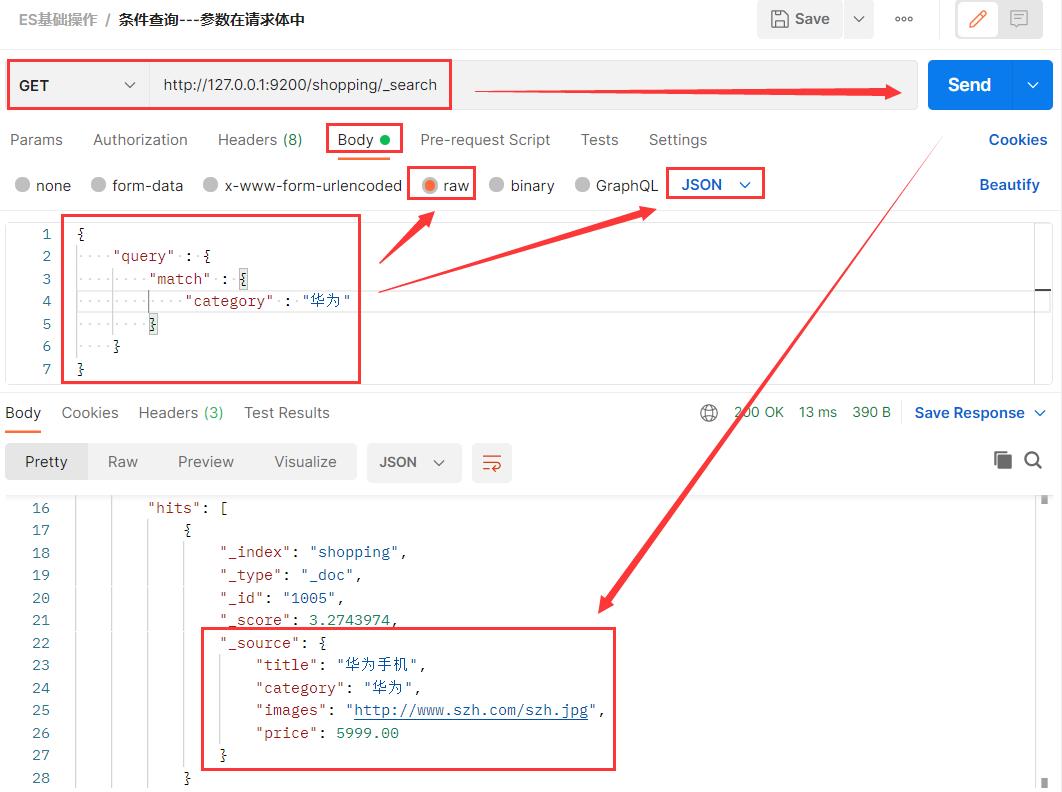
所以一般采用下面这种方式,将请求参数存放在请求体中。
{
"query" : {
"match" : {
"category" : "华为"
}
}
}
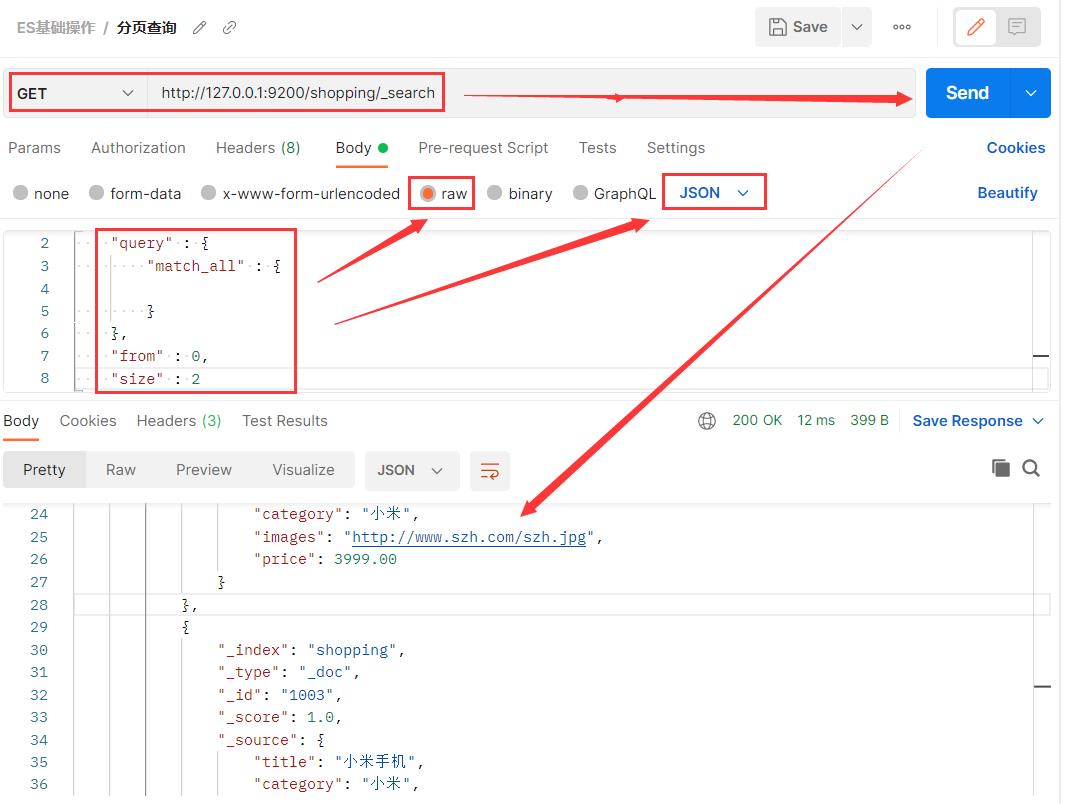
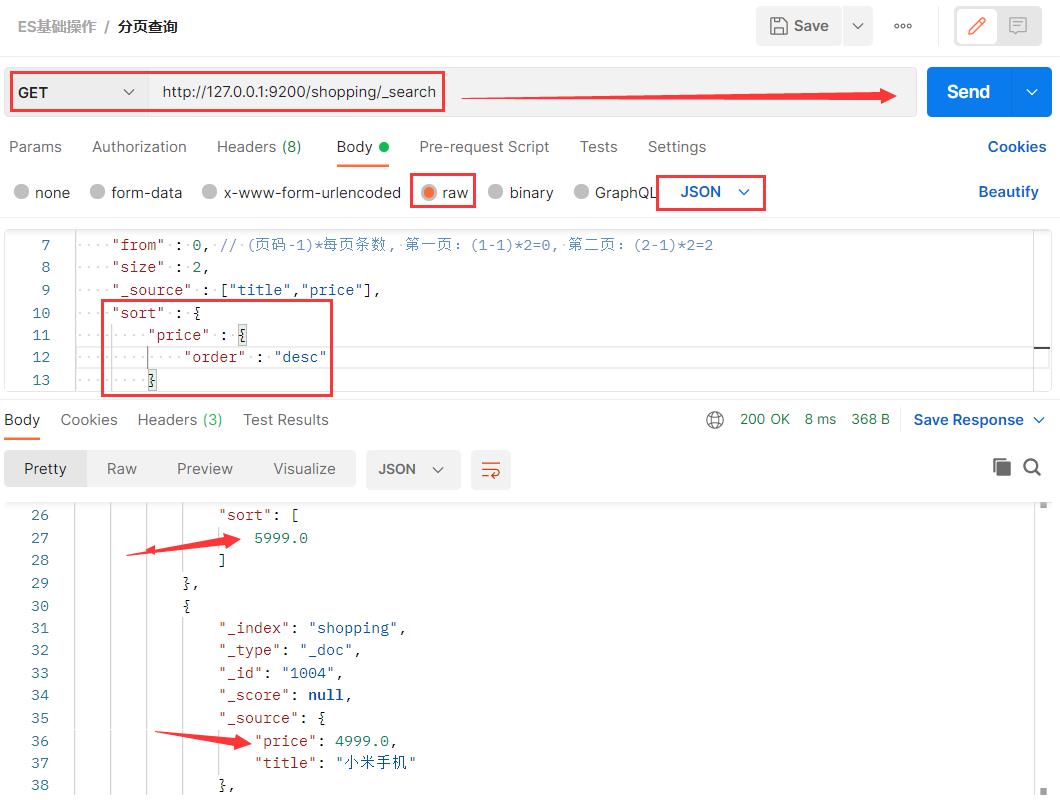
3.8 分页查询 + 排序文档内容
默认情况下,Elasticsearch 在搜索的结果中,会把文档中保存在_source 的所有字段都返回。如果我们只想获取其中的部分字段,我们可以添加_source 的过滤
sort 可以让我们按照不同的字段进行排序,并且通过 order 指定排序的方式。desc 降序,asc 升序。
from:当前页的起始索引,默认从 0 开始。 from = (pageNum - 1) * size。
size:每页显示多少条。
{
"query" : {
"match_all" : {
}
},
"from" : 0, // (页码-1)*每页条数, 第一页:(1-1)*2=0, 第二页:(2-1)*2=2
"size" : 2,
"_source" : ["title","price"],
"sort" : {
"price" : {
"order" : "desc"
}
}
}

3.9 多条件查询:and
`bool`把各种其它查询通过`must`(必须 and )、`must_not`(必须不)、`should`(应该 or)的方式进行组合 。
{
"query" : {
"bool" : {
"must" : [
{
"match" : {
"category" : "小米"
}
},
{
"match" : {
"price" : 3999.00
}
}
]
}
}
}
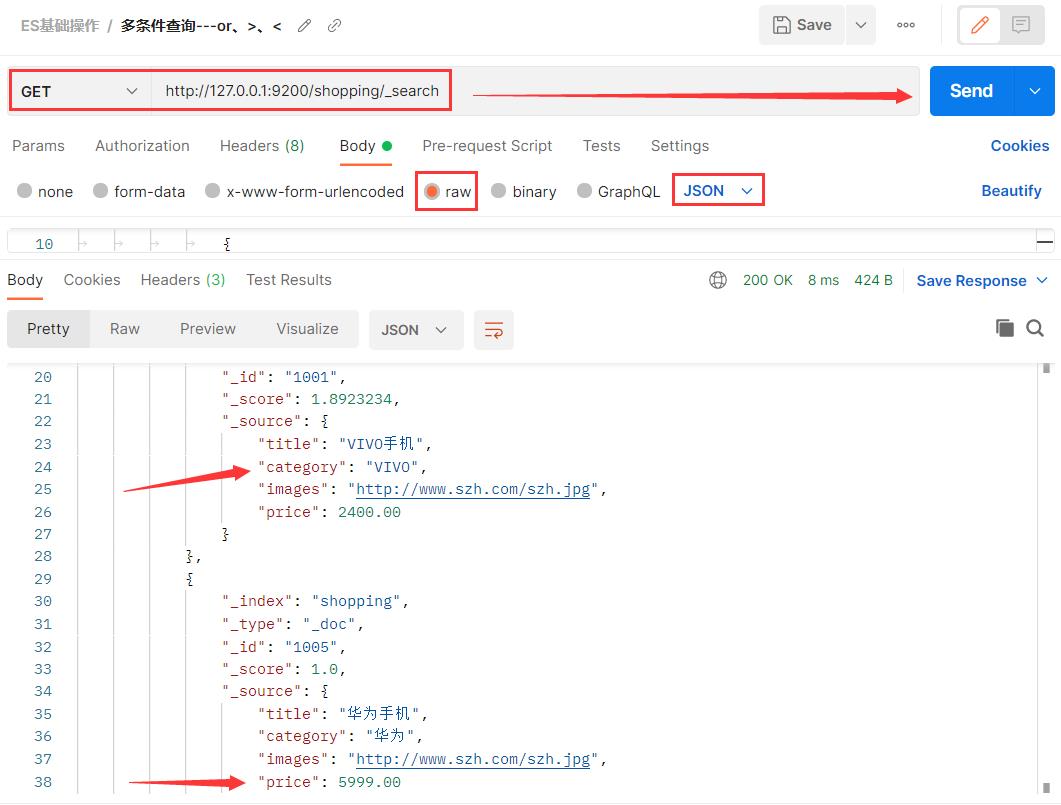
3.10 多条件查询:or
`bool`把各种其它查询通过`must`(必须 and )、`must_not`(必须不)、`should`(应该 or)的方式进行组合 。
{
"query" : {
"bool" : {
"should" : [
{
"match" : {
"category" : "VIVO"
}
},
{
"match" : {
"price" : 5999.00
}
}
]
}
}
}
3.11 多条件查询:大于、小于
range 查询找出那些落在指定区间内的数字或者时间。range 查询允许以下字符:
gt 大于> gte 大于等于>= lt 小于< lte 小于等于<=
{
"query" : {
"bool" : {
"must" : [
{
"match" : {
"category" : "小米"
}
}
],
"filter" : {
"range" : {
"price" : {
"gt" : 3000.00,
"lt" : 4000.00
}
}
}
}
}
}
3.12 全文查询 + 高亮显示
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮。
在使用 match 查询的同时,加上一个 highlight 属性:
- pre_tags:前置标签
- post_tags:后置标签
- fields:需要高亮的字段
- title:这里声明 title 字段需要高亮,后面可以为这个字段设置特有配置,也可以空
{
"query" : {
"match_phrase" : {
"category" : "小"
}
},
"highlight" : {
"fields" : {
"category" : {}
}
}
}
当我们将查询条件中的 match_phrase 改为 match 之后,再次查询,结果仍然是有的。这就很奇怪了,我文档中分类信息只有 小米 、没有 小 啊,为什么还能查询到结果呢? 这是因为ES在保存文档数据时,会将数据进行分词、拆解操作,并将拆解后的数据保存到倒排索引中,这样即使使用文字的一部分(小米可以查询到、小也可以查询到)也能查询到数据,这种方式就称为 全文检索。 也就是说文档中的category是小米,通过 小、米、小米 均可以查询到。
如果我们写的是 小华,则ES会帮我们查询出:%小%、%华% 相关的所有数据,这里就是进行了数据分词、拆解,进而采用倒排索引的方式查询。
假如说,我不想采用采用这种全文检索的匹配模式,需要将 match 改为 match_phrase。

3.13 聚合查询:根据价格分组、对价格求平均值
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值、平均值等等。
- 对某个字段取最大值 max
- 对某个字段取最小值 min
- 对某个字段求和 sum
- 对某个字段取平均值 avg
- 对某个字段的值进行去重之后再取总数 distinct
{
"aggs" : { //聚合操作
"price_group" : { //名称,自定义
"terms" : { //分组
"field" : "price" //分组字段
}
}
},
"size" : 0
}
{
"aggs" : { //聚合操作
"price_avg" : { //名称,自定义
"avg" : { //分组
"field" : "price" //分组字段
}
}
},
"size" : 0
}
4.映射操作
有了索引库,等于有了数据库中的 database。
接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
映射数据说明:
- 字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
- type:类型,Elasticsearch 中支持的数据类型非常丰富,说几个关键的:
String 类型,又分两种:
text:可分词keyword:不可分词,数据会作为完整字段进行匹配
Numerical:数值类型,分两类
基本数据类型:long、integer、short、byte、double、float、half_float
浮点数的高精度类型:scaled_float
Date:日期类型
Array:数组类型
Object:对象
- index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。
true:字段会被索引,则可以用来进行搜索
false:字段不会被索引,不能用来搜索
- store:是否将数据进行独立存储,默认为 false
原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置
- analyzer:分词器,这里的 ik_max_word 即使用 ik 分词器
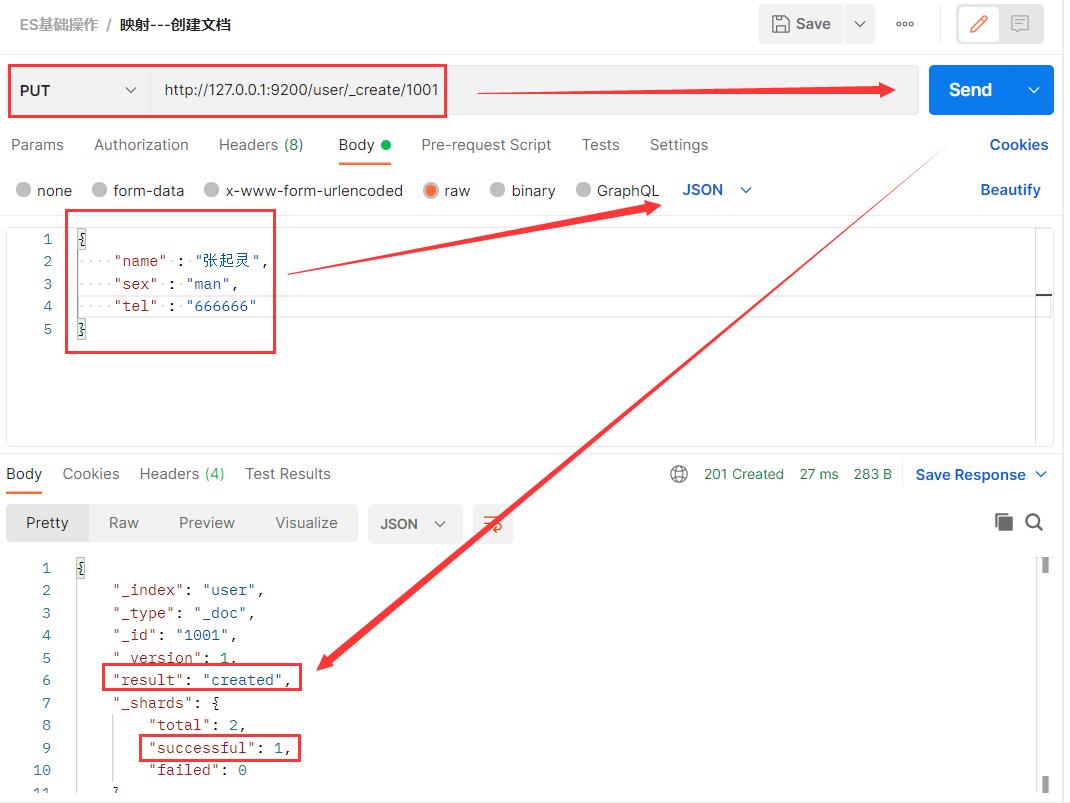
首先是 http://127.0.0.1:9200/user ,发送PUT请求,创建一个user索引,然后在这个索引下创建一个映射。
就类似于在mysql中创建一个名为 user 的数据库,在这个数据库中定义一张表的结构如下:👇👇👇
text 类型为true表示 name 字段可以支持 分词、拆解 操作的查询;而 keyword 类型为true表示 sex 字段仅支持完全匹配的模式;最后 keyword 类型为false表示 tel 字段不支持查询。
{
"properties" : {
"name" : {
"type" : "text",
"index" : true
},
"sex" : {
"type" : "keyword",
"index" : true
},
"tel" : {
"type" : "keyword",
"index" : false
}
}
}
索引有了,映射也有了(数据库有了、表结构有了,就差向表中添加数据了),也就是需要添加文档内容。
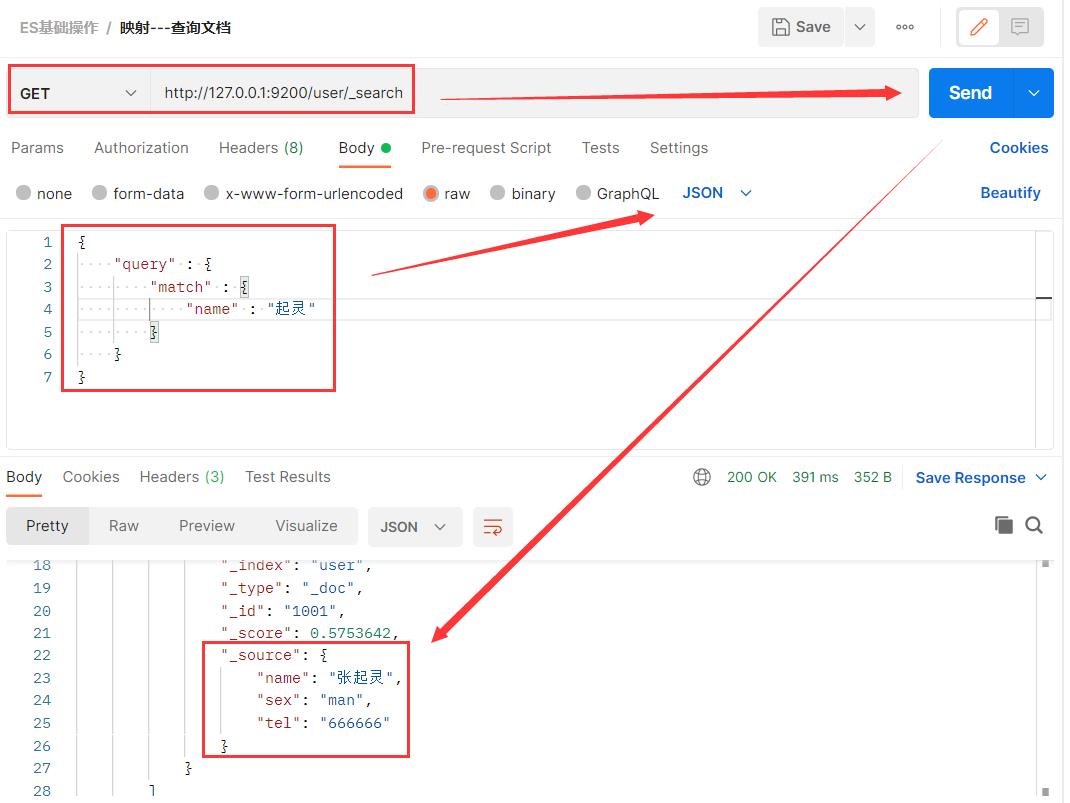
因为name字段是 支持 text 模式查询,即支持 分词、拆解 操作,做倒排索引,所以虽然文档中的name字段为张起灵,但是经过分词拆解,name为 张、起、灵、起灵 这几种都可以查询出数据。
由于 sex 字段不支持text分词拆解,仅支持keyword完全匹配的模式,所以源文档数据中 sex 为 man,这里只写个 m 是查询不到的。
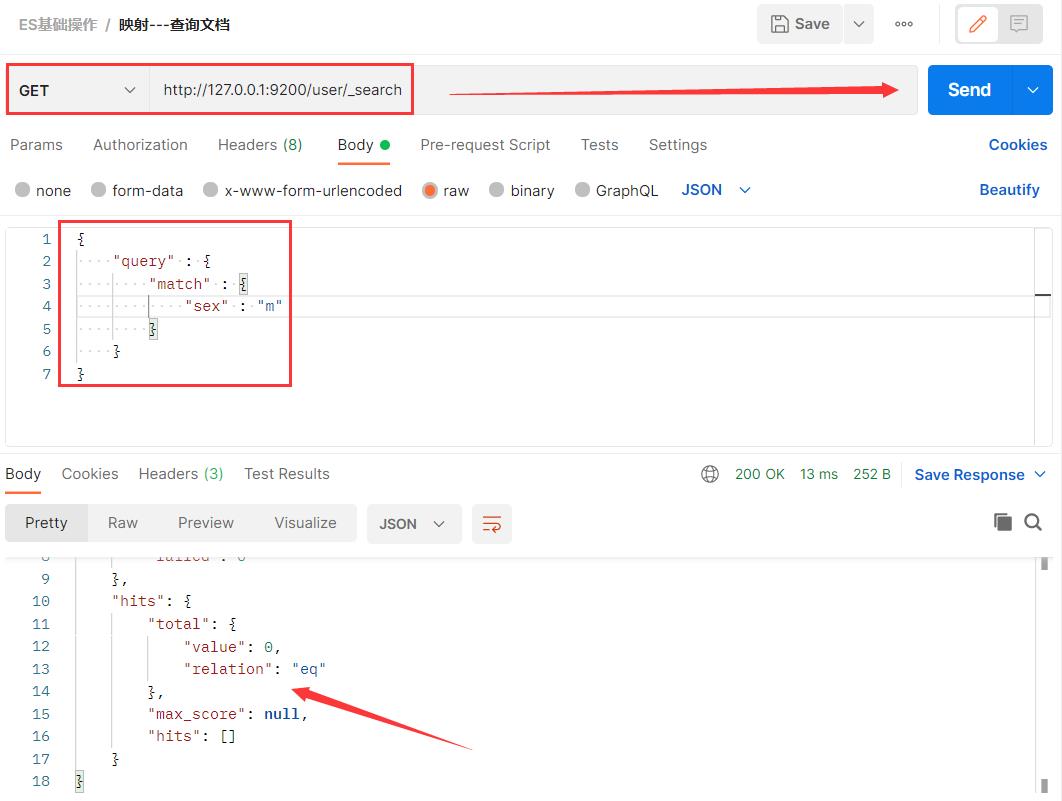
最后的 tel 字段是最苛刻的,压根不支持 text、keyword 两种查询模式,所以这里就算是写成和文档中的 tel 一样,也查询不到,因为 tel 字段不支持查询。

以上是关于Elasticsearch——创建/查看/删除索引创建/查看/修改/删除文档映射关系的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch入门—— Elasticsearch7.8.0版本索引操作