2021年8月上中旬好文收藏
Posted rtoax
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年8月上中旬好文收藏相关的知识,希望对你有一定的参考价值。
2021年8月25日22:23:16
目录
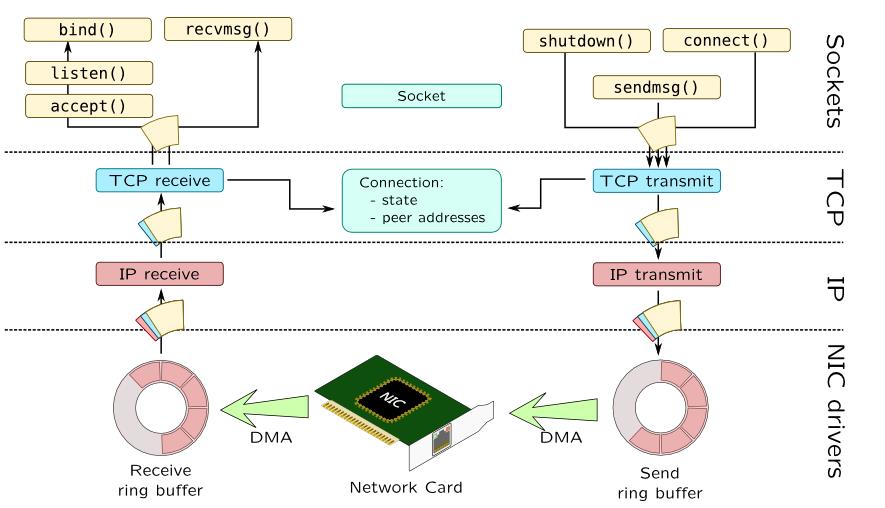
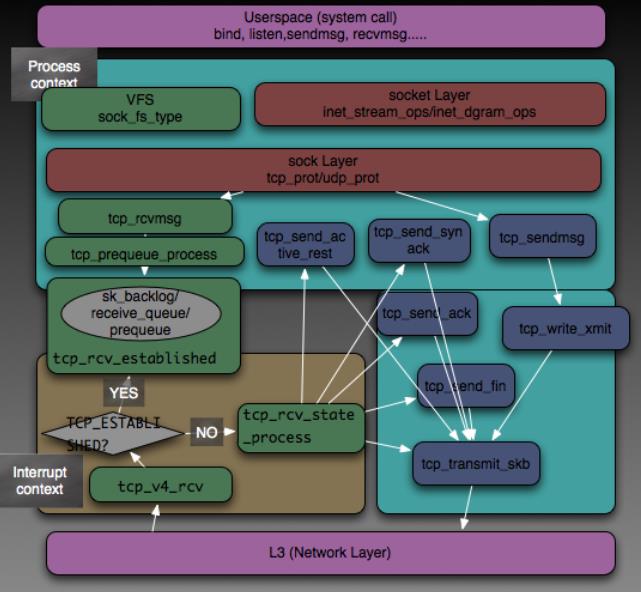
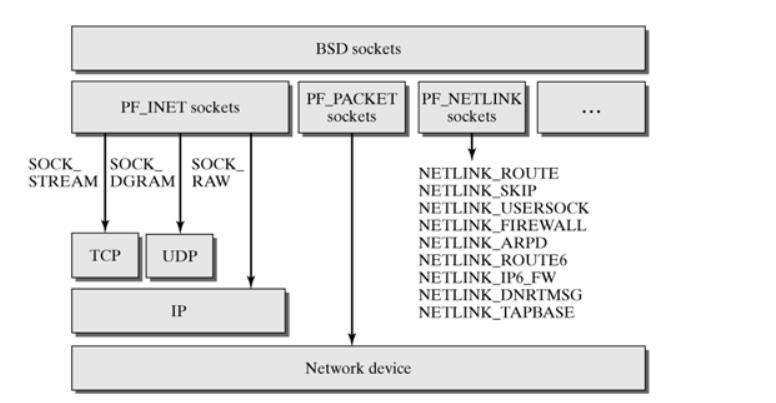
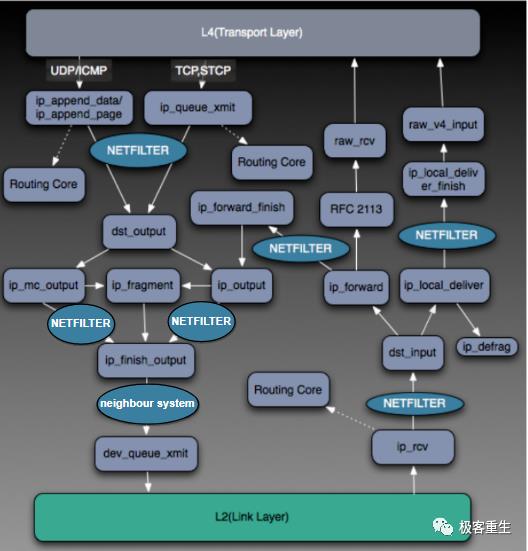
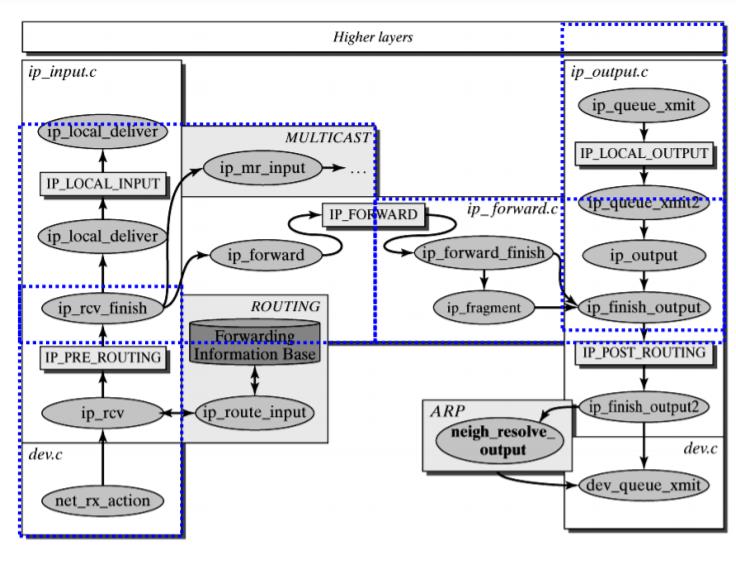
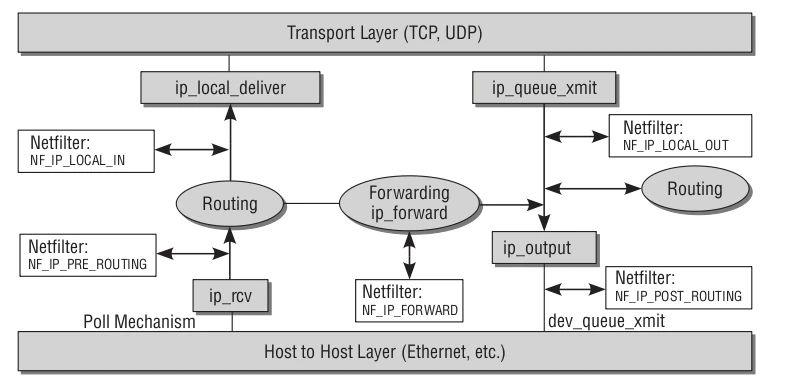
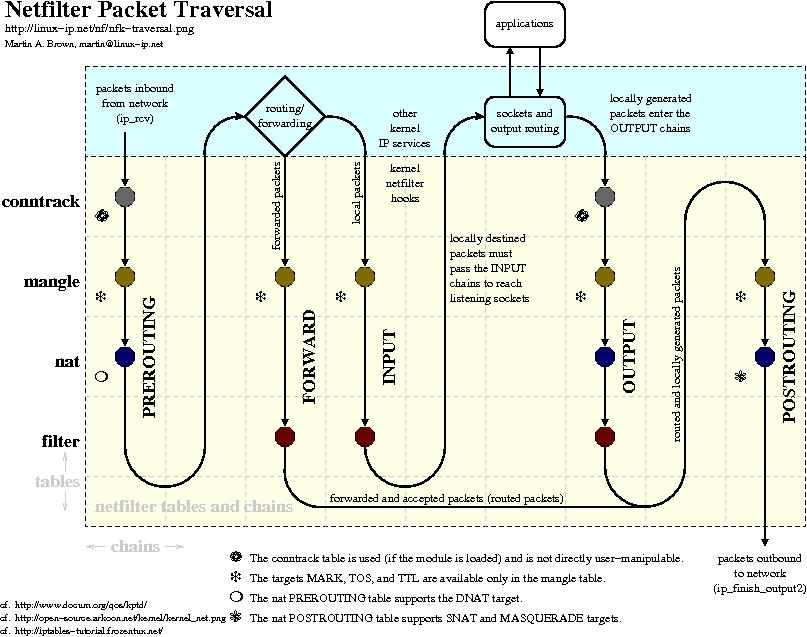
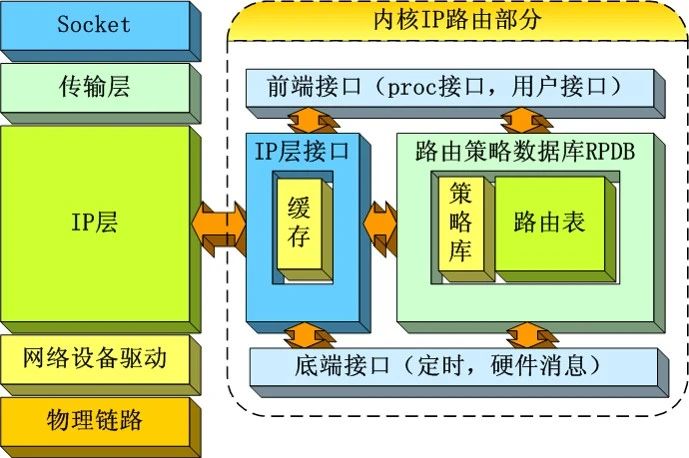
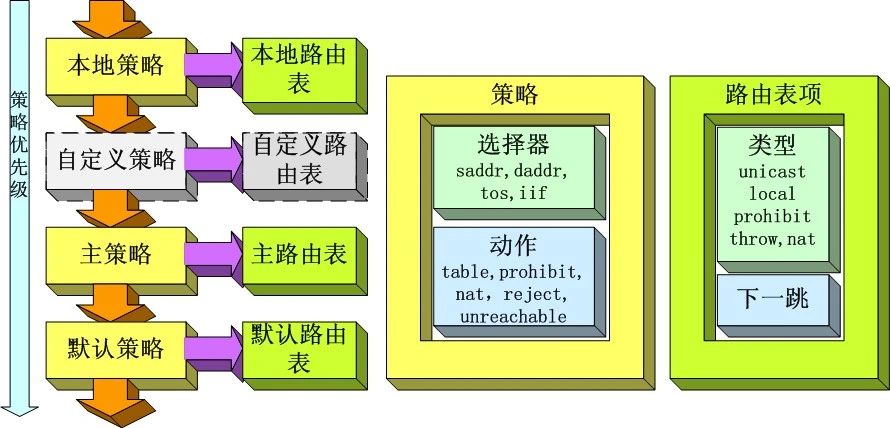
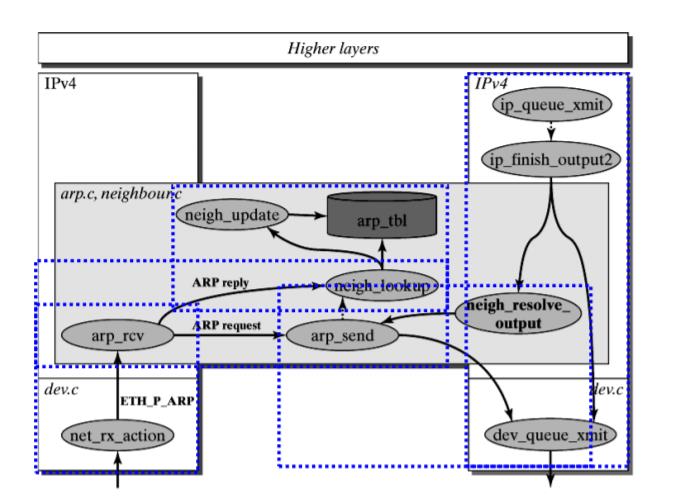
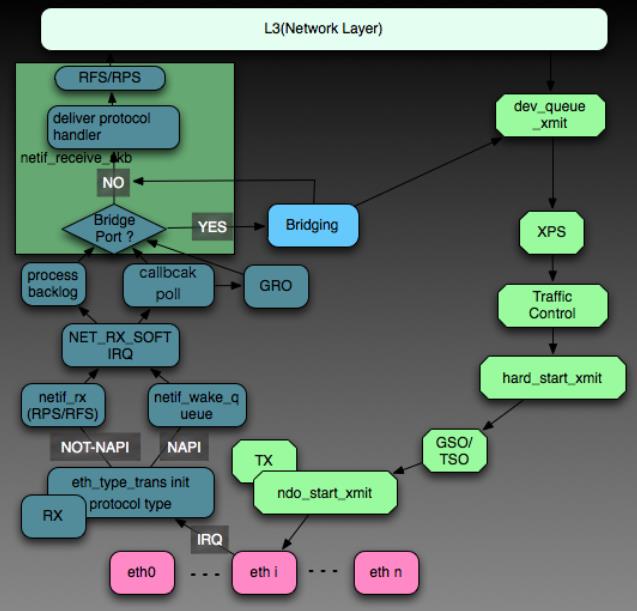
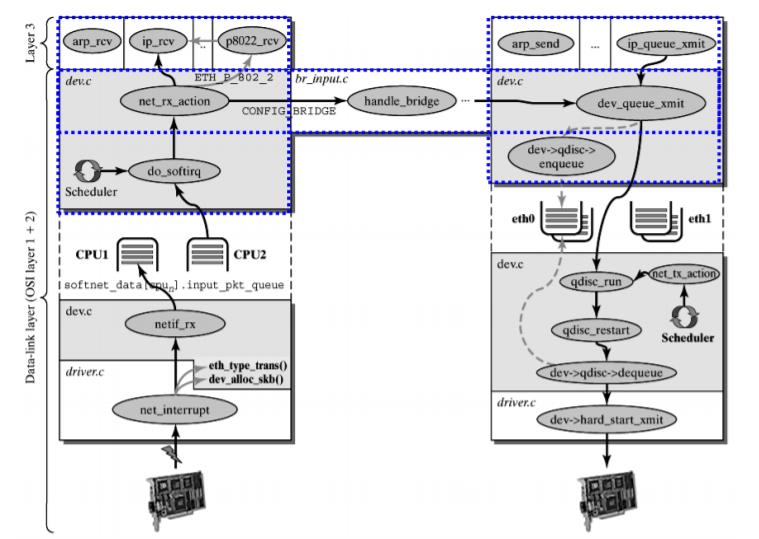
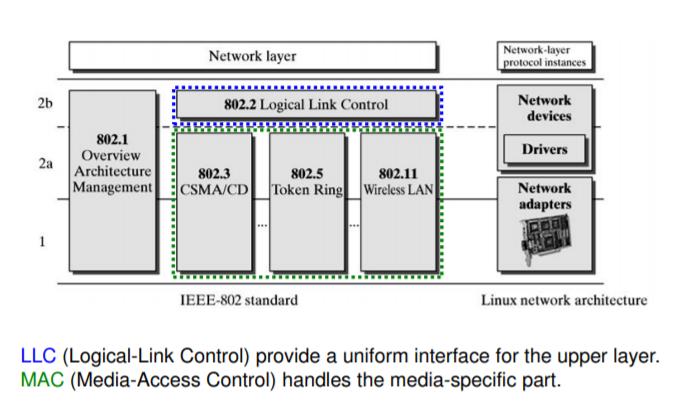
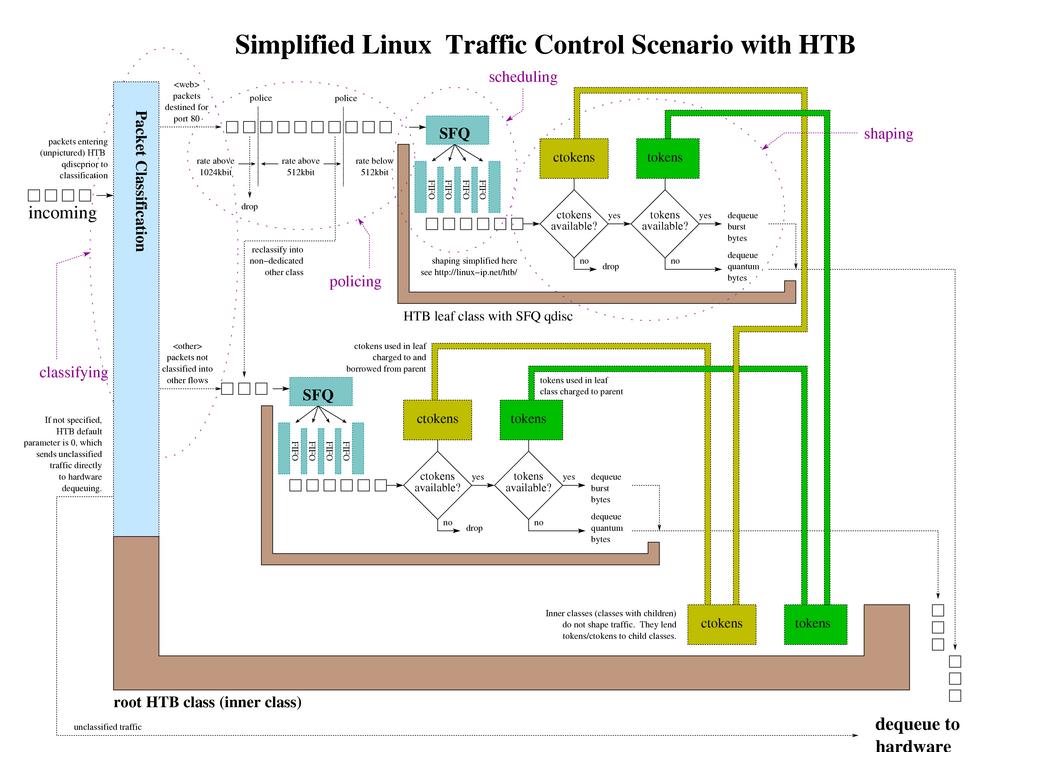
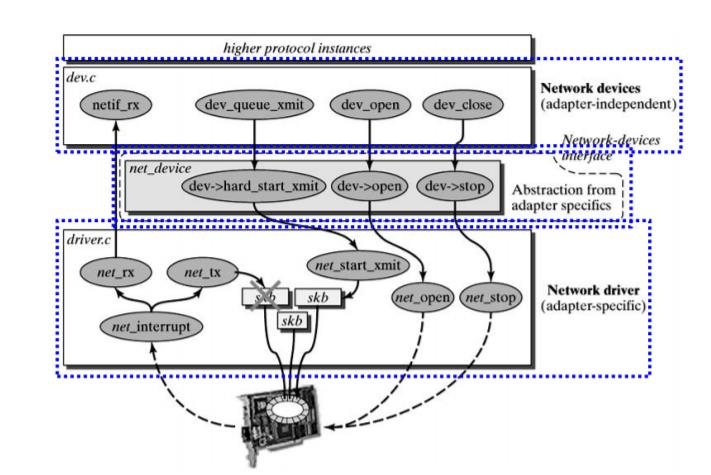
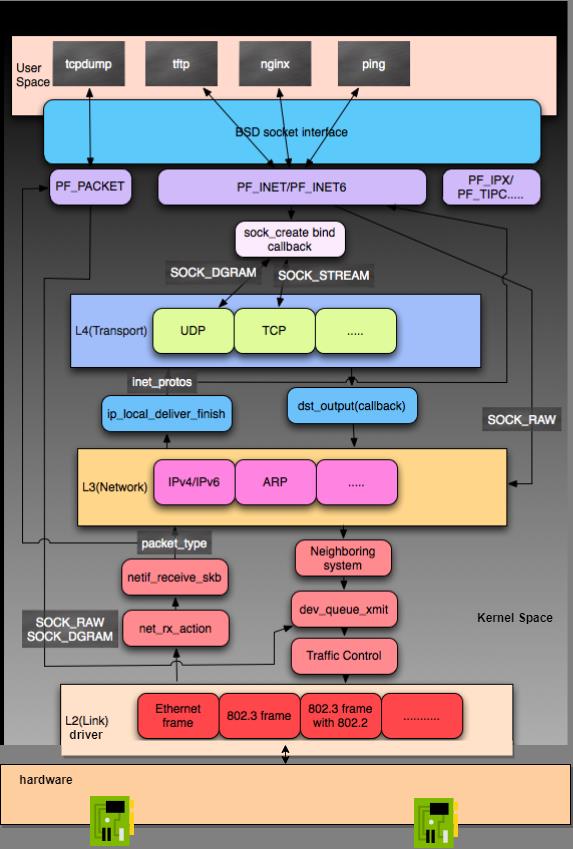
Linux Kernel TCP/IP Stack|Linux网络硬核系列
HTTPS 中的 TLS 握手过程可以同时进行三次握手」对不对
Linux Kernel TCP/IP Stack|Linux网络硬核系列
https://mp.weixin.qq.com/s/63HBz8DGPjLeNd43kaOunw
浅谈 Protobuf 编码
https://mp.weixin.qq.com/s/enDUynhZ1Pnzg_4xEjR21A
作者:SG4YK,腾讯 PCG 后台开发工程师
近日简单学习了 Protobuf 中的编码实现,总结并整理成文。本文结构总体与 Protobuf 官方文档相似,不少内容也来自官方文档,并在官方文档的基础上添加作者理解的内容,如有出入请以官方文档为准。作者水平有限,难免有疏漏之处,欢迎指正并分享您的意见。
0x00 Before you start
简单来说,Protobuf 的编码是基于变种的 Base128。在学习 Protobuf 编码或是 Base128 之前,先来了解下 Base64 编码。
0x01 Base 64
当我们在计算机之间传输数据时,数据本质上是一串字节流。TCP 协议可以保证被发送的字节流正确地达到目的地(至少在出错时有一定的纠错机制),所以本文不讨论因网络因素造成的数据损坏。但数据到达目标机器之后,由于不同机器采用的字符集不同等原因,我们并不能保证目标机器能够正确地“理解”字节流。
Base 64 最初被设计是用于在邮件中嵌入文件(作为 MIME 的一部分)。它可以将任何形式的字节流编码为“安全”的字节流。何为“安全“的字节?先来看看 Base 64 是如何工作的。
假设这里有四个字节,代表你要传输的二进制数据。

首先将这个字节流按每 6 个 bit 为一组进行分组,剩下少于 6 bits 的低位补 0。

然后在每一组 6 bits 的高位补两个 0。

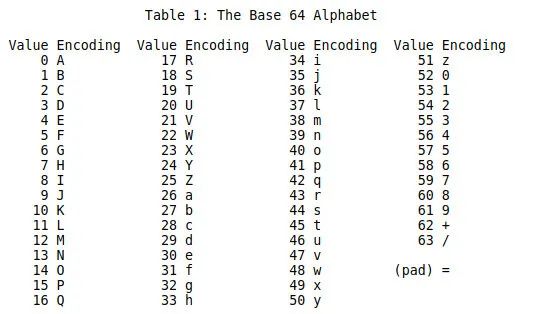
对照 Base 64 table,字节流可以用 ognC0w 来表示。另外,Base64 编码是按照 6 bits 为一组进行编码,每 3 个字节的原始数据要用 4 个字节来储存,编码后的长度要为 4 的整数倍,不足 4 字节的部分要使用 pad 补齐,所以最终的编码结果为ognC0w==。
任意的字节流均可以使用 Base 64 进行编码,编码之后所有字节均可以用数字、字母和 + / = 号进行表示,这些都是可以被正常显示的 ascii 字符,即“安全”的字节。绝大部分的计算机和操作系统都对 ascii 有着良好的支持,保证了编码之后的字节流能被正确地复制、传播、解析。
注:下文关于字节顺序内容均基于机器采用小端模式的前提进行讨论。
0x02 Base 128?
Base 64 存在的问题就是,编码后的每一个字节的最高两位总是 0,在不考虑 pad 的情况下,有效 bit 只占 bit 总数的 75%,造成大量的空间浪费。是否可以进一步提高信息密度呢?
意识到这一点,你就很自然能想象出 Base 128 的大致实现思路了,将字节流按 7 bits 进行分组,然后低位补 0。
但问题来了,Base 64 实际上用了 64+1 个 ascii 字符,按照这个思路 Base 128 需要使用 128+1 个 ascii 个字符,但是 ascii 字符一共只有 128 个。另外,即使不考虑 pad,ascii 中包含了一些不可以正常打印的控制字符,编码之后的字符还可能包含会被不同操作系统转换的换行符号(10 和 13)。因此,Base 64 至今依然没有被 Base 128 替代。
Base 64 的规则因为上述限制不能完美地扩展到 Base 128,所以现有基于 Base 64 扩展而来的编码方式大部分都属于变种。如 LEB128(Little-Endian Base 128), Base 85 (Ascii 85),以及本文的主角:Base 128 Varints。
注:下文关于字节顺序内容均基于机器采用小端模式的前提进行讨论。
0x03 Base 128 Varints
Base 128 Varints 是 Google 开发的序列化库 Protocol Buffers 所用的编码方式。以下为 Protobuf 官方文档中对于 Varints 的解释:
Varints are a method of serializing integers using one or more bytes. Smaller numbers take a smaller number of bytes.
使用一个或多个字节对整数进行序列化。小的数字占用更少的字节。简单来说,就是尽量只储存整数的有效位,高位的 0 尽可能抛弃。
有两个需要注意的细节:
-
Base 128 Varints 只能对一部分数据结构进行编码,不适用于所有字节流(当然你可以把任意字节流转换为 string,但不是所有语言都支持这个 trick)。否则无法识别哪部分是无效的 bits。
-
Base 128 Varints 编码后的字节可以不存在于 Ascii 表中,因为和 Base 64 使用场景不同,不用考虑是否能正常打印。
下面以例子进行说明 Base 128 Varints 的编码实现。
对于编码后的每个字节,低 7 位用于储存数据,最高位用来标识当前字节是否是当前整数的最后一个字节,称为最高有效位(most significant bit, msb)。msb 为 1 时,代表着后面还有数据;msb 为 0 时代表着当前字节是当前整数的最后一个字节。
举个例子,下面是编码后的整数1。1 只需要用一个字节就能表示完全,所以 msb 为 0。
Linux 内核调试利器 | kprobe 的使用
https://mp.weixin.qq.com/s/ttRxAdhjHF24I0mQvekfJA
软件调试 是软件开发中一个必不可少的过程,通过软件调试可以排查系统中存在的 BUG。我们在开发应用层程序时,可以使用 GDB 对程序进行调试。但由于 GDB 只能调试应用层程序,并不能用于调试内核代码。
那么,如何调试内核代码呢?与调试应用层程序的 GDB 类似,调试内核代码也有个名叫 KGDB 的工具,但是使用起来比较繁琐。所以,本文将会介绍一个使用起来比较简单的内核调试工具:kprobe。
本篇文章主要介绍 kprobe 的使用,下篇文章将会介绍 kprobe 的实现原理。
回忆一下我们在开发应用程序时是怎样调试代码的?最原始的方法就是,在代码中使用 printf 这类打印函数把结果输出到屏幕或者日志中。当然在内核中有类似的打印函数:printk,但使用 printk 函数调试内核代码的话,必须要重新编译 Linux 内核代码,代价非常高。
所以,内核开发者们开发出一种不需要重新编译内核代码的调试工具:kprobe。
kprobe 可以让用户在内核几乎所有的地址空间或函数(某些函数是被能被探测的)中插入探测点,用户可以在这些探测点上通过定义自定义函数来调试内核代码。
用户可以对一个探测点进行执行前和执行后调试,在介绍 kprobe 的使用方式前,我们先来了解一下 struct kprobe 结构,其定义如下:
struct kprobe {
...
kprobe_opcode_t *addr;
const char *symbol_name;
unsigned int offset;
kprobe_pre_handler_t pre_handler;
kprobe_post_handler_t post_handler;
kprobe_fault_handler_t fault_handler;
...
};一个 struct kprobe 结构表示一个探测点,下面介绍一下其各个字段的作用:
-
addr:要探测的指令所在的内存地址(由于需要知道指令的内存地址,所以比较少使用)。 -
symbol_name:要探测的内核函数,symbol_name与addr只能选择一个进行探测。 -
offset:探测点在内核函数内的偏移量,用于探测内核函数内部的指令,如果该值为0表示函数的入口。 -
pre_handler:在探测点处的指令执行前,被调用的调试函数。 -
post_handler:在探测点处的指令执行后,被调用的调试函数。 -
fault_handler:在执行pre_handler、post_handler或单步执行被探测指令时出现内存异常,则会调用这个回调函数。
一个 kprobe 探测点的执行过程如下图所示:
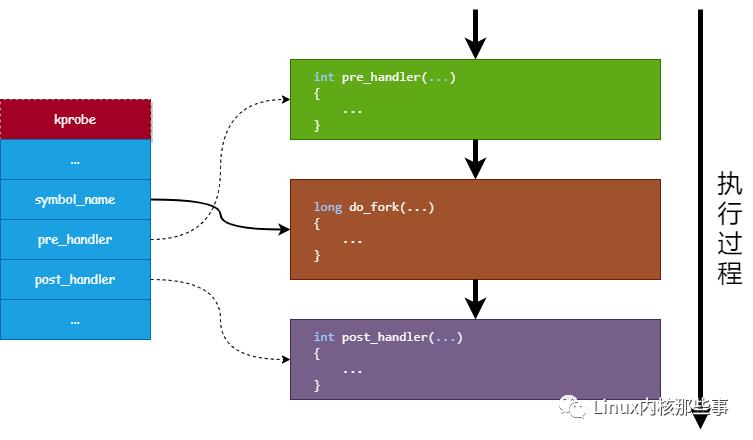
从上面的介绍可知,kprobe 一般用于调试内核函数。
kprobe 使用
接下来,我们介绍一下怎么使用 kprobe 来调试内核函数。
使用 kprobe 来进行内核调试的方式有两种:
-
第一种是通过编写内核模块,向内核注册探测点。探测函数可根据需要自行定制,使用灵活方便;
-
第二种方式是使用
kprobes on ftrace,这种方式是kprobe和ftrace结合使用,即可以通过kprobe来优化ftrace来跟踪函数的调用。
由于第一种方式灵活而且功能更为强大,所以本文主要介绍第一种使用方式。
要编写一个 kprobe 内核模块,可以按照以下步骤完成:
-
第一步:根据需要来编写探测函数,如
pre_handler和post_handler回调函数。 -
第二步:定义
struct kprobe结构并且填充其各个字段,如要探测的内核函数名和各个探测回调函数。 -
第三步:通过调用
register_kprobe函数注册一个探测点。 -
第四步:编写 Makefile 文件。
-
第五步:编译并安装内核模块。
接下来就按照上面的步骤来完成一个 kprobe 的内核模块。
1. 定义回调函数
第一步就是编写追踪的回调函数,一般来说只需要编写 pre_handler、post_handler 和 fault_handler 这三个回调函数,当然也可以只编写你想追踪的其中某一个回调函数。下面我们将会完成这三个追踪回调函数的编写:
pre_handler 回调函数
我们首先编写要追踪的内核函数被调用前的回调函数 pre_handler,代码如下:
static int pre_handler(struct kprobe *p, struct pt_regs *regs)
{
printk(KERN_INFO "pre_handler: p->addr = 0x%p, ip = %lx, flags = 0x%lx\\n",
p->addr, regs->ip, regs->flags);
return 0;
}上面的函数只是简单的打印了要追踪的内核函数的内存地址、ip 寄存器和 flags 寄存器的值,在函数的定义中可以发现有个类型为 pt_regs 结构的参数 ,其主要保存了 CPU 各个寄存器的值,不同 CPU 架构的定义不一样,例如 x86 CPU 架构的定义如下:
struct pt_regs {
long ebx; // ebx寄存器
long ecx; // ecx寄存器
long edx; // edx寄存器
long esi; // esi寄存器
long edi; // edi寄存器
long ebp; // ebp寄存器
long eax; // eax寄存器
int xds; // ds寄存器
int xes; // es寄存器
int xfs; // fs寄存器
long orig_eax; // ...
long eip; // eip寄存器
int xcs; // cs寄存器
long eflags; // eflags寄存器
long esp; // esp寄存器
int xss; // ss寄存器
};
所以我们可以通过这个结构来获取 CPU 各个寄存器的值。
post_handler 回调函数
接着我们来编写要追踪的内核函数被调用后的回调函数 post_handler,其代码如下:
static void
post_handler(struct kprobe *p, struct pt_regs *regs, unsigned long flags)
{
printk(KERN_INFO "post_handler: p->addr = 0x%p, flags = 0x%lx\\n",
p->addr, regs->flags);
}
post_handler 回调函数也只是简单的打印了要追踪的内核函数的内存地址和 flags 寄存器的值。
fault_handler 回调函数
最后我们来编写当发生内存异常时的回调函数 fault_handler,其代码如下:
static int fault_handler(struct kprobe *p, struct pt_regs *regs, int trapnr)
{
printk(KERN_INFO "fault_handler: p->addr = 0x%p, trap #%dn",
p->addr, trapnr);
return 0;
}
fault_handler 回调函数打印了要追踪的内核函数的内存地址和发生异常时的异常编号。
2. 定义 kprobe 结构
接下来我们定义一个 struct kprobe 结构并且填充其各个字段值,代码如下:
static struct kprobe kp = {
.symbol_name = "do_fork", // 要追踪的内核函数为 do_fork
.pre_handler = pre_handler; // pre_handler 回调函数
.post_handler = post_handler; // post_handler 回调函数
.fault_handler = fault_handler; // fault_handler 回调函数
};
由于我们要追踪 do_fork 内核函数,所以在 kprobe 结构的 symbol_name 设置为 do_fork 字符串,然后设置各个回调函数即可。
3. 注册追踪点
最后通过调用 register_kprobe 函数来注册追踪点,代码如下:
static int __init kprobe_init(void)
{
int ret;
ret = register_kprobe(&kp); // 调用 register_kprobe 注册追踪点
if (ret < 0) {
printk(KERN_INFO "register_kprobe failed, returned %d\\n", ret);
return ret;
}
printk(KERN_INFO "planted kprobe at %p\\n", kp.addr);
return 0;
}
static void __exit kprobe_exit(void)
{
unregister_kprobe(&kp); // 调用 unregister_kprobe 注销追踪点
printk(KERN_INFO "kprobe at %p unregistered\\n", kp.addr);
}
module_init(kprobe_init) // 注册模块初始化函数
module_exit(kprobe_exit) // 注册模块退出函数
MODULE_LICENSE("GPL");
4. 编写 Makefile 文件
Makefile 文件用于编译内核模块时使用,一般来说编译内核模块的 Makefile 格式相对固定,如下:
obj-m := kprobe_example.o # 编译后的二进制文件名
CROSS_COMPILE=''
KDIR := /lib/modules/$(shell uname -r)/build
all:
make -C $(KDIR) M=$(PWD) modules
clean:
rm -f *.ko *.o *.mod.o *.mod.c .*.cmd *.symvers modul*
5. 编译并安装内核模块
最后,我们编译并且安装这个内核模块,命令如下:
$ make
$ sudo insmod kprobe_example.ko
安装完成后,随便敲入一个命令(如 ls),然后通过调用 dmesg 命令查看内核模块输出的结果,如下所示:
...
planted kprobe at ffffffff81076400
pre_handler: p->addr = 0xffffffff81076400, ip = ffffffff81076401, flags = 0x246
post_handler: p->addr = 0xffffffff81076400, flags = 0x246
pre_handler: p->addr = 0xffffffff81076400, ip = ffffffff81076401, flags = 0x246
post_handler: p->addr = 0xffffffff81076400, flags = 0x246
pre_handler: p->addr = 0xffffffff81076400, ip = ffffffff81076401, flags = 0x246
post_handler: p->addr = 0xffffffff81076400, flags = 0x246
可以看出,我们的调试模块已经正常工作,并且输出我们需要的信息。
总结
本文主要介绍了 kprobe 的使用方式,kprobe 的功能非常强大,可以帮助我们发现内核的一些 BUG。当然,本文也只是非常简单的介绍其使用,但有了这些基础就可以完成很多复杂的调试。
本文主要为了接下来的 kprobe 原理与实现打好基础,一下篇文章将会介绍 kprobe 的原理和实现,有兴趣的同学多多关注。
Linux内存管理:SPARSEMEM模型:
https://zhuanlan.zhihu.com/p/220068494
背景介绍:
内存对于OS来说就像我们生活中的水和电,这么重要的资源管理起来是很花心思的。我们知道Linux中的物理内存被按页框划分,每个页框都会对应一个struct page结构体存放元数据,也就是说每块页框大小的内存都要花费sizeof(struct page)个字节进行管理。
所以系统会有大量的struct page,在linux的历史上出现过三种内存模型去管理它们。依次是平坦内存模型(flat memory model)、不连续内存模型 (discontiguous memory model)和稀疏内存模型(sparse memory model)。新的内存模型的一次次被提出,无非因为是老的内存模型已不适应计算机硬件的新技术(例如:NUMA技术、内存热插拔等)。
内存模型的设计则主要是权衡以下两点(空间与时间):
1. 尽量少的消耗内存去管理众多的struct page
2. pfn_to_page和page_to_pfn的转换效率。
Tips: 老惯例,文章基于ARM64、Linux5.0的内核展开叙述。
三种内存模型:
- FLATMEM (flat memory model)
FLATMEM内存模型是Linux最早使用的内存模型,那时计算机的内存通常不大。Linux会使用一个struct page mem_map[x]的数组根据PFN去依次存放所有的strcut page,且mem_map也位于内核空间的线性映射区,所以根据PFN(页帧号)即可轻松的找到目标页帧的strcut page
- DISCONTIGMEM (discontiguous memory model)
对于物理地址空间不存在空洞(holes)的计算机来说,FLATMEM无疑是最优解。可物理地址中若是存在空洞的话,FLATMEM就显得格外的浪费内存,因为FLATMEM会在mem_map数组中为所有的物理地址都创建一个struct page,即使大块的物理地址是空洞,即不存在物理内存。可是为这些空洞这些struct page完全是没有必要的。为了解决空洞的问题,Linux社区提出了DISCONTIGMEM模型。
DISCONTIGMEM是个稍纵即逝的内存模型,在SPARSEMEM出现后即被完全替代,且当前的Linux kernel默认都是使用SPARSEMEM,所以介绍DISCONTIGMEM的意义不大,感兴趣可以看这篇文章:https://lwn.net/Articles/789304/
- SPARSEMEM (sparse memory model)
稀疏内存模型是当前内核默认的选择,从2005年被提出后沿用至今,但中间经过几次优化,包括:CONFIG_SPARSEMEM_VMEMMAP和CONFIG_SPARSEMEM_EXTREME的引入,这两个配置通常是被打开的,下面的原理介绍也会基于它们开启的情况。
首次引入SPARSEMEM时的commit。https://lwn.net/Articles/134804/ 原文中阐明了它的三个优点:
1. 可以解决内存空洞导致的内存浪费。
2. 支持内存的热插拔(memory hotplug)。
3. 支持nodes间的overlap。(我也不太清楚这是个啥...)
SPARSEMEM原理:
- section的概念:
SPARSEMEM内存模型引入了section的概念,可以简单将它理解为struct page的集合(数组)。内核使用struct mem_section去描述section,定义如下:
struct mem_section {
unsigned long section_mem_map;
/* See declaration of similar field in struct zone */
unsigned long *pageblock_flags;
};其中的section_mem_map成员存放的是struct page数组的地址,每个section可容纳PFN_SECTION_SHIFT个struct page,arm64地址位宽为48bit时定义了每个section可囊括的地址范围是1GB。
- 全局变量**mem_section
内核中用了一个二级指针struct mem_section **mem_section去管理section,我们可以简单理解为一个动态的二维数组。所谓二维即内核又将SECTIONS_PER_ROOT个section划分为一个ROOT,ROOT的个数不是固定的,根据系统实际的物理地址大小来分配。
- 物理页帧号PFN
SPARSEMEM将PFN差分成了三个level,每个level分别对应:ROOT编号、ROOT内的section偏移、section内的page偏移。(可以类比多级页表来理解)
- vmemmap区域
vmemmap区域是一块起始地址是VMEMMAP_START,范围是2TB的虚拟地址区域,位于kernel space。以section为单位来存放strcut page结构的虚拟地址空间,然后线性映射到物理内存。(关于虚拟地址空间,参考文章:Linux内存管理:虚拟地址空间)
- 内存热插拔
SPARSEMEM中section是最小管理单元。内存热插拔也是以section为单位,下图中画的热插拔单位是一个section(ARM64是1GB),通常会大于等于一个section。
通过下图来可以很好的串联上面几个概念:
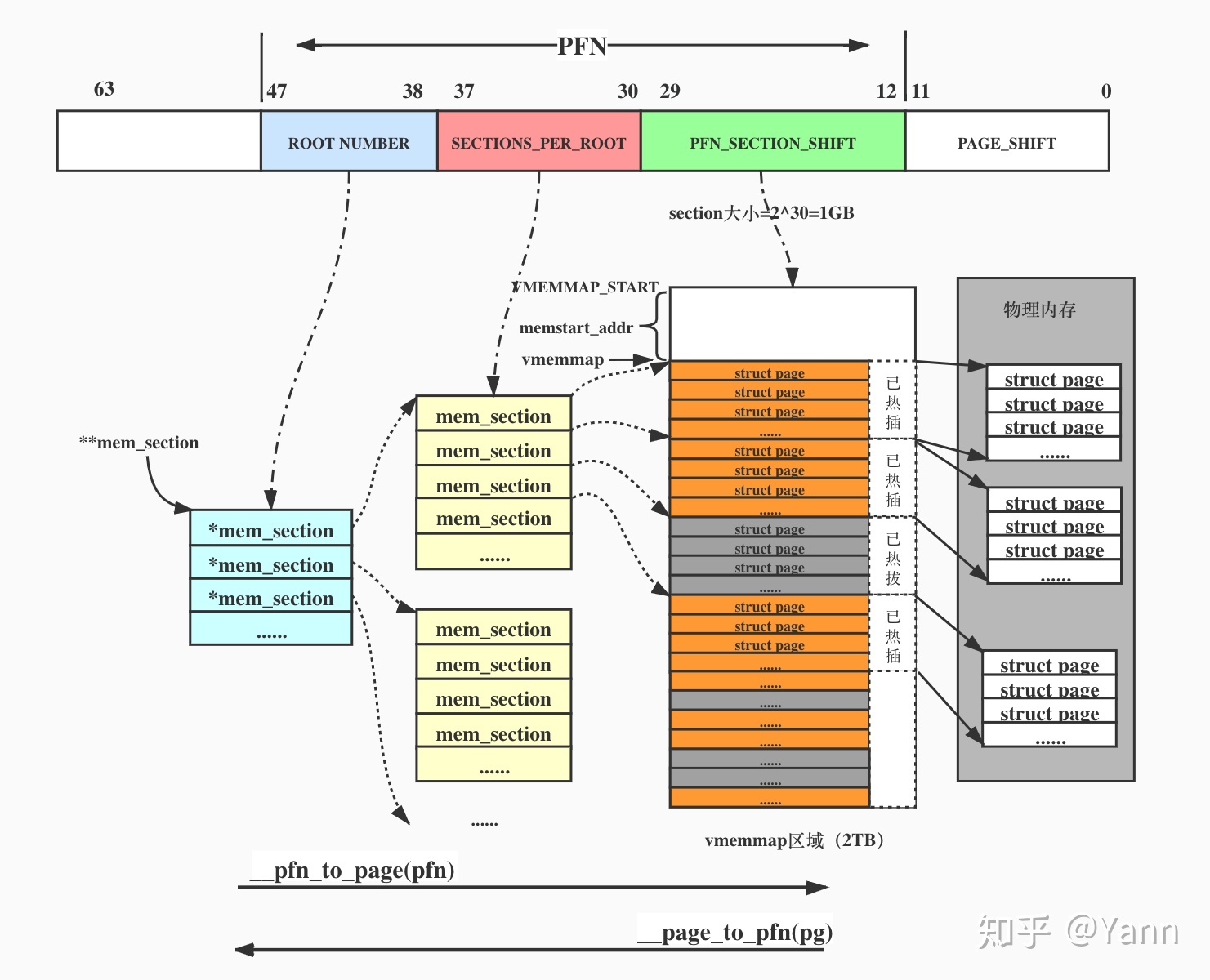
- PFN和struct page的转换:
SPARSEMEM中__pfn_to_page和__page_to_pfn的实现如下:
#define __pfn_to_page(pfn) (vmemmap + (pfn))
#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)
#define vmemmap ((struct page *)VMEMMAP_START - (memstart_addr >> PAGE_SHIFT))其中vmemmap指针指向VMEMMAP_START偏移memstart_addr的地址处,memstart_addr则是根据物理起始地址PHYS_OFFSET算出来的偏移,上图画出了三者之间的关系。
总结:
- 高效
通过上面__pfn_to_page的实现可以看出其仅用一步计算即可找到对应的struct page,十分高效,毫不逊色于flat memory model,很符合文章开始我们提到的高效的目标。
- 省内存
那另一个目标节省内存是如何做到的呢?答案就是按需分配,内存空洞或者被拔掉的内存条,我们不给它分配存放struct page的物理内存(只有虚拟内存)。
内存的多级页表也是利用了这个思想,通过将页表分成多级,未分配物理页帧的则不去为它建立PTE,上面将PFN拆成root、section是不是很像二级页表呢。
原创文章,转载和引用请注明出处。
作者:Yann Xu
一文说清OpenCL框架
https://mp.weixin.qq.com/s/XE-A4jnNJdjH_RyQb0ttzQ
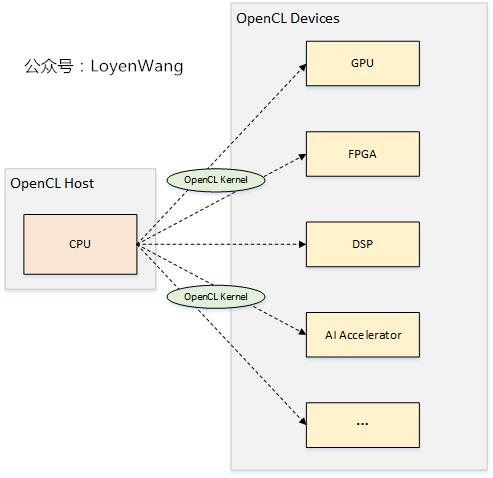
-
OpenCL(Open Computing Language,开放计算语言):从软件视角看,它是用于异构平台编程的框架;从规范视角看,它是异构并行计算的行业标准,由Khronos Group来维护;
-
异构平台包括了CPU、GPU、FPGA、DSP,以及最近几年流行的各类AI加速器等;
-
OpenCL包含两部分:
1)用于编写运行在OpenCL device上的kernels的语言(基于C99);
2)OpenCL API,至于Runtime的实现交由各个厂家,比如Intel发布的opencl_runtime_16.1.2_x64_rh_6.4.0.37.tgz
以人工智能场景为例来理解一下,假如在某个AI芯片上跑人脸识别应用,CPU擅长控制,AI processor擅长计算,软件的flow就可以进行拆分,用CPU来负责控制视频流输入输出前后处理,AI processor来完成深度学习模型运算完成识别,这就是一个典型的异构处理场景,如果该AI芯片的SDK支持OpenCL,那么上层的软件就可以基于OpenCL进行开发了。
话不多说,看看OpenCL的架构吧。
OpenCL架构,可以从平台模型、内存模型、执行模型、编程模型四个角度来展开。
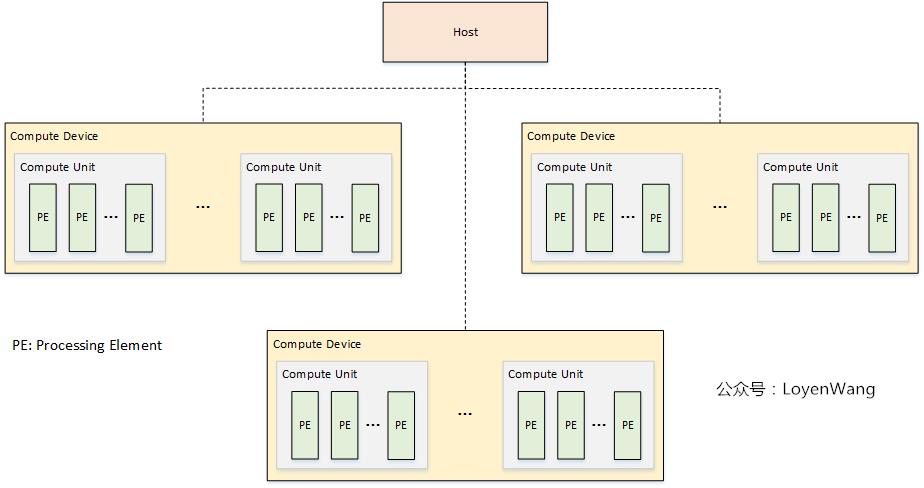
-
平台模型由一个Host连接一个或多个OpenCL Devices组成;
-
OpenCL Device,可以划分成一个或多个计算单元
Compute Unit(CU); -
CU可以进一步划分成一个或多个处理单元
Processing Unit(PE),最终的计算由PE来完成; -
OpenCL应用程序分成两部分:host代码和device kernel代码,其中Host运行host代码,并将kernel代码以命令的方式提交到OpenCL devices,由OpenCL device来运行kernel代码;
HTTPS 中的 TLS 握手过程可以同时进行三次握手」对不对
https://mp.weixin.qq.com/s/KA66YEj5erMWj-cRgY7fAQ

面试官跟他说 HTTPS 中的 TLS 握手过程可以同时进行三次握手,然后读者之前看我的文章是说「先进行 TCP 三次握手,再进行 TLS 四次握手」,他跟面试官说了这个,面试官说他不对,他就感到很困惑。
我们先不管面试官说的那句「HTTPS 中的 TLS 握手过程可以同时进行三次握手」对不对。
但是面试官说「HTTPS 建立连接的过程,先进行 TCP 三次握手,再进行 TLS 四次握手」是错的,这很明显面试官的水平有问题,这种公司不去也罢!
如果是我面试遇到这样的面试官,我直接当场给他抓 HTTPS 建立过程的网络包,然后给他看,啪啪啪啪啪的打他脸。
比如,下面这个 TLSv1.2 的 基于 RSA 算法的四次握手过程:
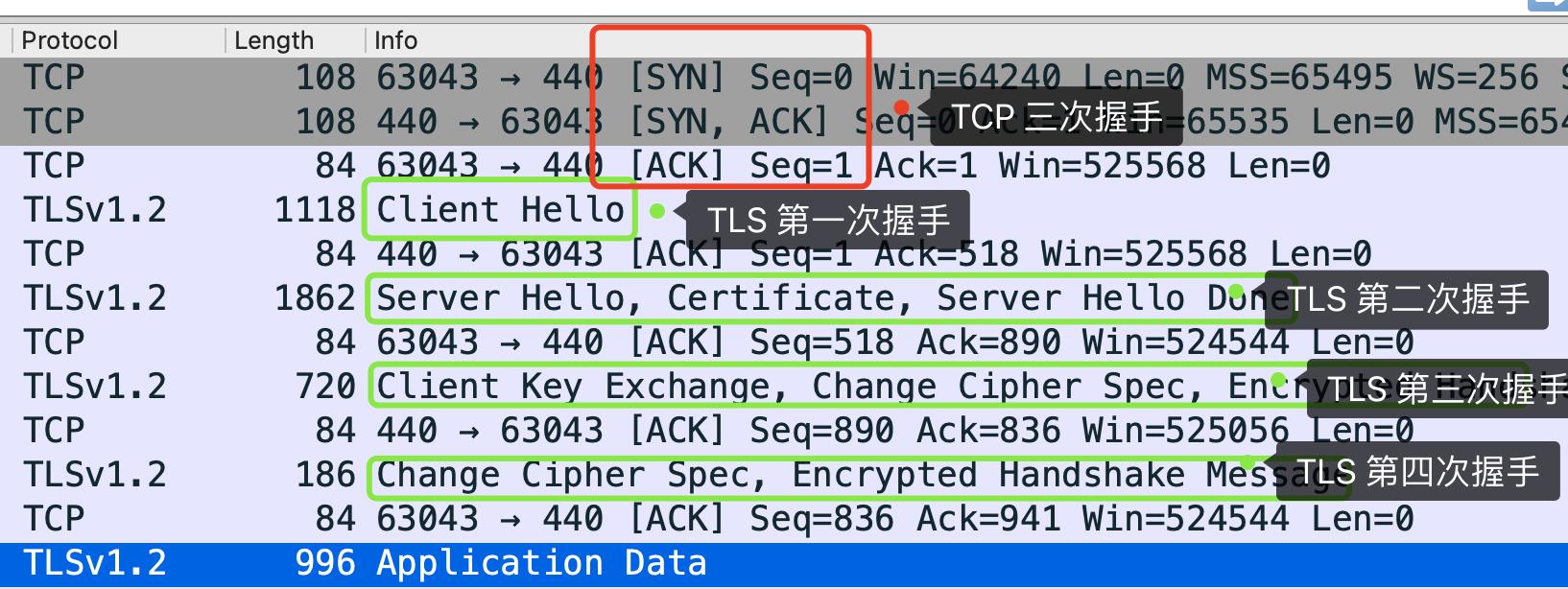
难道不是先三次握手,再进行 TLS 四次握手吗?面试官你脸疼吗?
不过 TLS 握手过程的次数还得看版本。
TLSv1.2 握手过程基本都是需要四次,也就是需要经过 2-RTT 才能完成握手,然后才能发送请求,而 TLSv1.3 只需要 1-RTT 就能完成 TLS 握手,如下图。

一般情况下,不管 TLS 握手次数如何,都得先经过 TCP 三次握手后才能进行,因为 HTTPS 都是基于 TCP 传输协议实现的,得先建立完可靠的 TCP 连接才能做 TLS 握手的事情。
那面试官说的这句「HTTPS 中的 TLS 握手过程可以同时进行三次握手」对不对呢?
这个场景是可能发生的,但是需要在特定的条件下才可能发生,如果没有说任何前提条件,说这句话就是在耍流氓。
那到底什么条件下,这个场景才能发生呢?需要下面这两个条件同时满足才可以:
-
客户端和服务端都开启了 TCP Fast Open 功能,且 TLS 版本是 1.3;
-
客户端和服务端已经完成过一次通信。
那具体怎么做到的呢?我们先了解些 TCP Fast Open 功能和 TLSv1.3 的特性。
TCP Fast Open
我们先来了解下什么是 TCP Fast Open?
常规的情况下,如果要使用 TCP 传输协议进行通信,则客户端和服务端通信之前,先要经过 TCP 三次握手后,建立完可靠的 TCP 连接后,客户端才能将数据发送给服务端。
其中,TCP 的第一次和第二次握手是不能够携带数据的,而 TCP 的第三次握手是可以携带数据的,因为这时候客户端的 TCP 连接状态已经是 ESTABLISHED,表明客户端这一方已经完成了 TCP 连接建立。
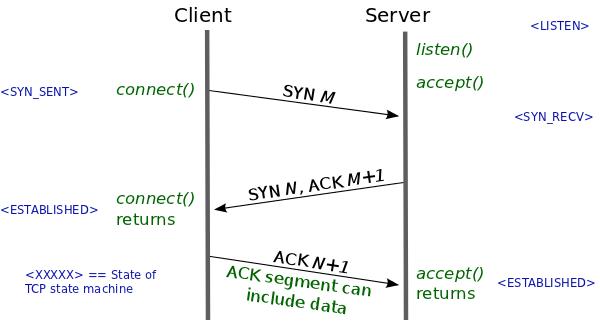
就算客户端携带数据的第三次握手在网络中丢失了,客户端在一定时间内没有收到服务端对该数据的应答报文,就会触发超时重传机制,然后客户端重传该携带数据的第三次握手的报文,直到重传次数达到系统的阈值,客户端就会销毁该 TCP 连接。
说完常规的 TCP 连接后,我们再来看看 TCP Fast Open。
TCP Fast Open 是为了绕过 TCP 三次握手发送数据,在 Linux 3.7 内核版本之后,提供了 TCP Fast Open 功能,这个功能可以减少 TCP 连接建立的时延。
要使用 TCP Fast Open 功能,客户端和服务端都要同时支持才会生效。
不过,开启了 TCP Fast Open 功能,想要绕过 TCP 三次握手发送数据,得建立第二次以后的通信过程。
在客户端首次建立连接时的过程,如下图:
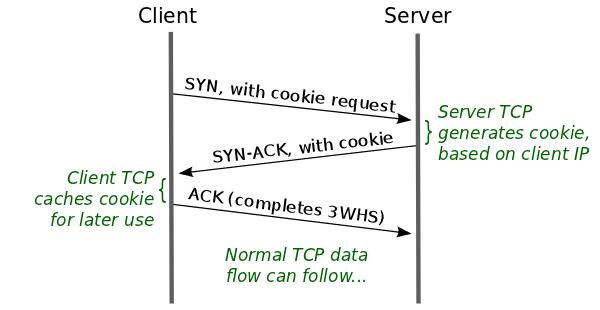
具体介绍:
-
客户端发送 SYN 报文,该报文包含 Fast Open 选项,且该选项的 Cookie 为空,这表明客户端请求 Fast Open Cookie;
-
支持 TCP Fast Open 的服务器生成 Cookie,并将其置于 SYN-ACK 报文中的 Fast Open 选项以发回客户端;
-
客户端收到 SYN-ACK 后,本地缓存 Fast Open 选项中的 Cookie。
所以,第一次客户端和服务端通信的时候,还是需要正常的三次握手流程。随后,客户端就有了 Cookie 这个东西,它可以用来向服务器 TCP 证明先前与客户端 IP 地址的三向握手已成功完成。
对于客户端与服务端的后续通信,客户端可以在第一次握手的时候携带应用数据,从而达到绕过三次握手发送数据的效果,整个过程如下图:
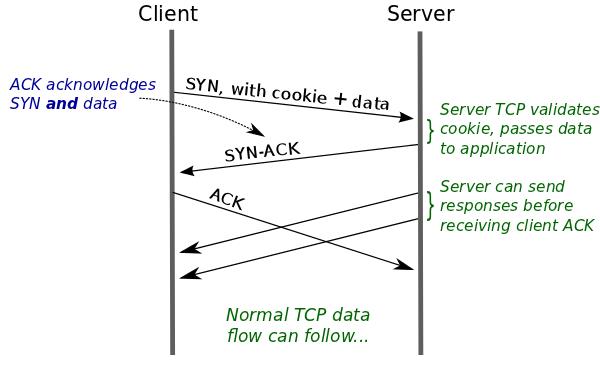
我详细介绍下这个过程:
-
客户端发送 SYN 报文,该报文可以携带「应用数据」以及此前记录的 Cookie;
-
支持 TCP Fast Open 的服务器会对收到 Cookie 进行校验:如果 Cookie 有效,服务器将在 SYN-ACK 报文中对 SYN 和「数据」进行确认,服务器随后将「应用数据」递送给对应的应用程序;如果 Cookie 无效,服务器将丢弃 SYN 报文中包含的「应用数据」,且其随后发出的 SYN-ACK 报文将只确认 SYN 的对应序列号;
-
如果服务器接受了 SYN 报文中的「应用数据」,服务器可在握手完成之前发送「响应数据」,这就减少了握手带来的 1 个 RTT 的时间消耗;
-
客户端将发送 ACK 确认服务器发回的 SYN 以及「应用数据」,但如果客户端在初始的 SYN 报文中发送的「应用数据」没有被确认,则客户端将重新发送「应用数据」;
-
此后的 TCP 连接的数据传输过程和非 TCP Fast Open 的正常情况一致。
所以,如果客户端和服务端同时支持 TCP Fast Open 功能,那么在完成首次通信过程后,后续客户端与服务端 的通信则可以绕过三次握手发送数据,这就减少了握手带来的 1 个 RTT 的时间消耗。
TLSv1.3
说完 TCP Fast Open,再来看看 TLSv1.3。
在最开始的时候,我也提到 TLSv1.3 握手过程只需 1-RTT 的时间,它到整个握手过程,如下图:
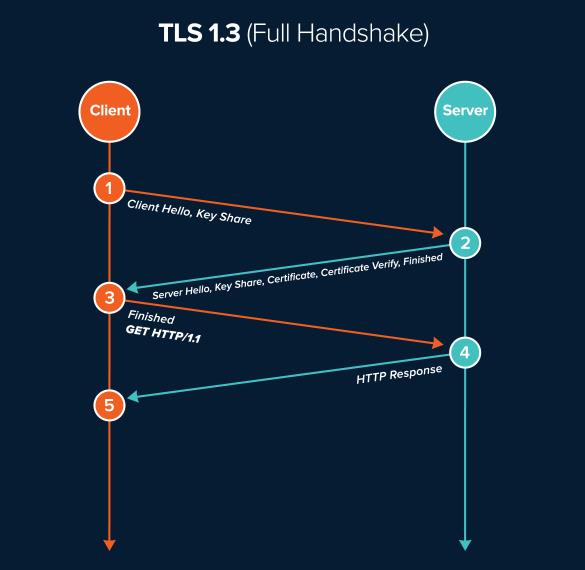
TCP 连接的第三次握手是可以携带数据的,如果客户端在第三次握手发送了 TLSv1.3 第一次握手数据,是不是就表示「HTTPS 中的 TLS 握手过程可以同时进行三次握手」?。
不是的,因为服务端只有在收到客户端的 TCP 的第三次握手后,才能和客户端进行后续 TLSv1.3 握手。
TLSv1.3 还有个更厉害到地方在于会话恢复机制,在重连 TLvS1.3 只需要 0-RTT,用“pre_shared_key”和“early_data”扩展,在 TCP 连接后立即就建立安全连接发送加密消息,过程如下图:
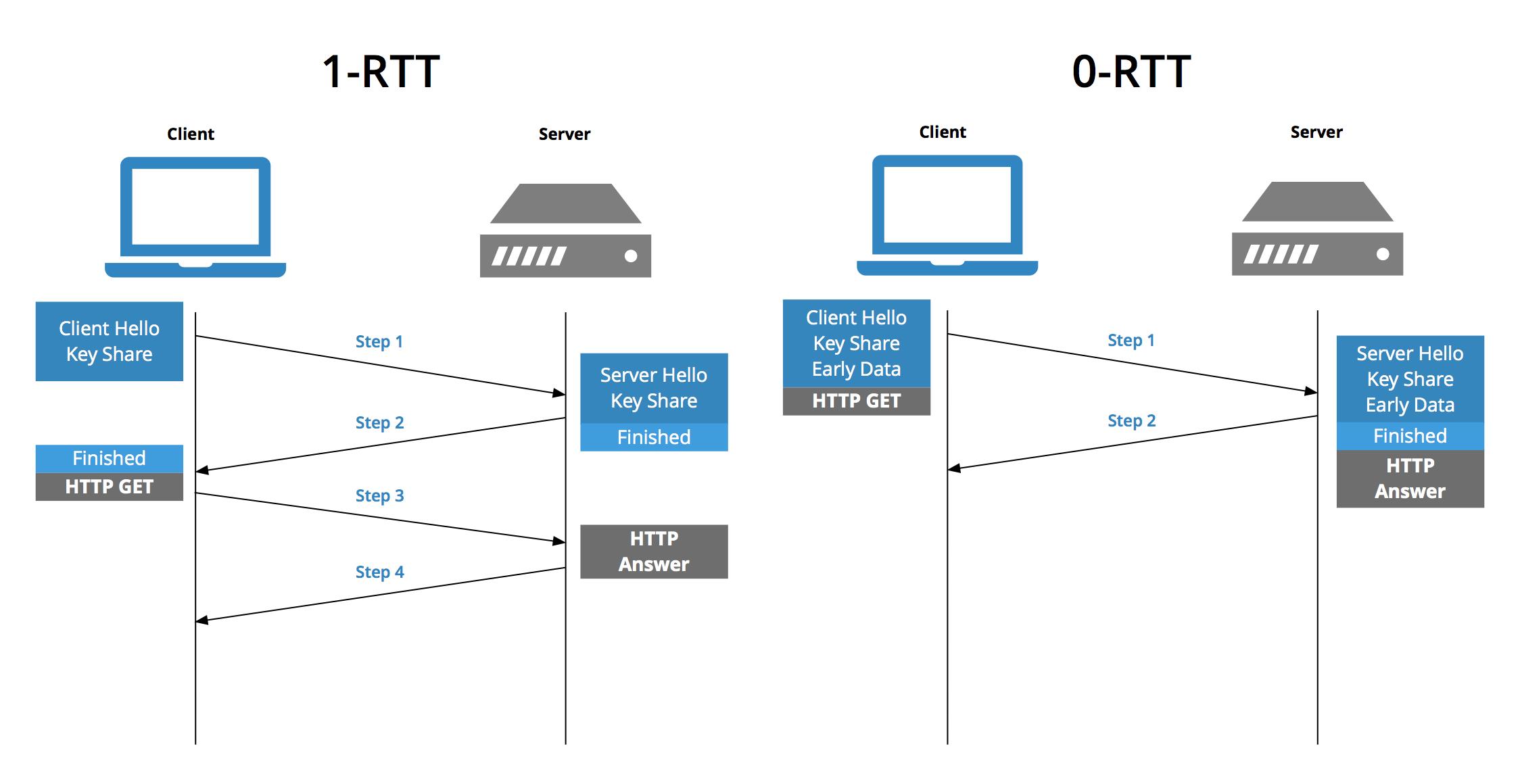
TCP Fast Open + TLSv1.3
在前面我们知道,客户端和服务端同时支持 TCP Fast Open 功能的情况下,在第二次以后到通信过程中,客户端可以绕过三次握手直接发送数据,而且服务端也不需要等收到第三次握手后才发送数据。
如果 HTTPS 的 TLS 版本是 1.3,那么 TLS 过程只需要 1-RTT。
因此如果「TCP Fast Open + TLSv1.3」情况下,在第二次以后的通信过程中,TLS 和 TCP 的握手过程是可以同时进行的。
如果基于 TCP Fast Open 场景下的 TLSv1.3 0-RTT 会话恢复过程,不仅 TLS 和 TCP 的握手过程是可以同时进行的,而且 HTTP 请求也可以在这期间内一同完成。
总结
最后做个总结。
「HTTPS 是先进行 TCP 三次握手,再进行 TLSv1.2 四次握手」,这句话一点问题都没有,怀疑这句话是错的人,才有问题。
「HTTPS 中的 TLS 握手过程可以同时进行三次握手」,这个场景是可能存在到,但是在没有说任何前提条件,而说这句话就等于耍流氓。需要下面这两个条件同时满足才可以:
-
客户端和服务端都开启了 TCP Fast Open 功能,且 TLS 版本是 1.3;
-
客户端和服务端已经完成过一次通信;
怎么样,那位“面试官”学废了吗?
Linux 信号处理原理与实现
https://mp.weixin.qq.com/s/8qQq_HXgT3MULbAbgBXWkg
信号本质上是在软件层次上对中断机制的一种模拟,其主要有以下几种来源:
-
程序错误:除零,非法内存访问等。
-
外部信号:终端
Ctrl-C产生SGINT信号,定时器到期产生SIGALRM等。 -
显式请求:kill函数允许进程发送任何信号给其他进程或进程组。
目前 Linux 支持64种信号。信号分为非实时信号(不可靠信号)和实时信号(可靠信号)两种类型,对应于 Linux 的信号值为 1-31 和 34-64。
信号是异步的,一个进程不必通过任何操作来等待信号的到达。事实上,进程也不知道信号到底什么时候到达。一般来说,我们只需要在进程中设置信号相应的处理函数,当有信号到达的时候,由系统异步触发相应的处理函数即可。如下代码:
#include <signal.h>
#include <unistd.h>
#include <stdio.h>
void sigcb(int signo) {
switch (signo) {
case SIGHUP:
printf("Get a signal -- SIGHUP\\n");
break;
case SIGINT:
printf("Get a signal -- SIGINT\\n");
break;
case SIGQUIT:
printf("Get a signal -- SIGQUIT\\n");
break;
}
return;
}
int main() {
signal(SIGHUP, sigcb);
signal(SIGINT, sigcb);
signal(SIGQUIT, sigcb);
for (;;) {
sleep(1);
}
}
运行程序后,当我们按下 Ctrl+C 后,屏幕上将会打印 Get a signal -- SIGINT。当然我们可以使用 kill -s SIGINT pid 命令来发送一个信号给进程,屏幕同样打印出 Get a signal -- SIGINT 的信息。
信号实现原理
接下来我们分析一下Linux对信号处理机制的实现原理。
信号处理相关的数据结构
在进程管理结构 task_struct 中有几个与信号处理相关的字段,如下:
struct task_struct {
...
int sigpending;
...
struct signal_struct *sig;
sigset_t blocked;
struct sigpending pending;
...
}
成员 sigpending 表示进程是否有信号需要处理(1表示有,0表示没有)。成员 blocked 表示被屏蔽的信息,每个位代表一个被屏蔽的信号。成员 sig 表示信号相应的处理方法,其类型是 struct signal_struct,定义如下:
#define _NSIG 64
struct signal_struct {
atomic_t count;
struct k_sigaction action[_NSIG];
spinlock_t siglock;
};
typedef void (*__sighandler_t)(int);
struct sigaction {
__sighandler_t sa_handler;
unsigned long sa_flags;
void (*sa_restorer)(void);
sigset_t sa_mask;
};
struct k_sigaction {
struct sigaction sa;
};
可以看出,struct signal_struct 是个比较复杂的结构,其 action 成员是个 struct k_sigaction 结构的数组,数组中的每个成员代表着相应信号的处理信息,而 struct k_sigaction 结构其实是 struct sigaction 的简单封装。
我们再来看看 struct sigaction 这个结构,其中 sa_handler 成员是类型为 __sighandler_t 的函数指针,代表着信号处理的方法。
最后我们来看看 struct task_struct 结构的 pending 成员,其类型为 struct sigpending,存储着进程接收到的信号队列,struct sigpending 的定义如下:
struct sigqueue {
struct sigqueue *next;
siginfo_t info;
};
struct sigpending {
struct sigqueue *head, **tail;
sigset_t signal;
};
当进程接收到一个信号时,就需要把接收到的信号添加 pending 这个队列中。
发送信号
可以通过 kill() 系统调用发送一个信号给指定的进程,其原型如下:
int kill(pid_t pid, int sig);
参数 pid 指定要接收信号进程的ID,而参数 sig 是要发送的信号。kill() 系统调用最终会进入内核态,并且调用内核函数 sys_kill(),代码如下:
asmlinkage long
sys_kill(int pid, int sig)
{
struct siginfo info;
info.si_signo = sig;
info.si_errno = 0;
info.si_code = SI_USER;
info.si_pid = current->pid;
info.si_uid = current->uid;
return kill_something_info(sig, &info, pid);
}
sys_kill() 的代码比较简单,首先初始化 info 变量的成员,接着调用 kill_something_info() 函数来处理发送信号的操作。kill_something_info() 函数的代码如下:
static int kill_something_info(int sig, struct siginfo *info, int pid)
{
if (!pid) {
return kill_pg_info(sig, info, current->pgrp);
} else if (pid == -1) {
int retval = 0, count = 0;
struct task_struct * p;
read_lock(&tasklist_lock);
for_each_task(p) {
if (p->pid > 1 && p != current) {
int err = send_sig_info(sig, info, p);
++count;
if (err != -EPERM)
retval = err;
}
}
read_unlock(&tasklist_lock);
return count ? retval : -ESRCH;
} else if (pid < 0) {
return kill_pg_info(sig, info, -pid);
} else {
return kill_proc_info(sig, info, pid);
}
}
kill_something_info() 函数根据传入pid 的不同来进行不同的操作,有如下4种可能:
-
pid等于0时,表示信号将送往所有与调用kill()的那个进程属同一个使用组的进程。 -
pid大于零时,pid是信号要送往的进程ID。 -
pid等于-1时,信号将送往调用进程有权给其发送信号的所有进程,除了进程1(init)。 -
pid小于-1时,信号将送往以-pid为组标识的进程。
我们这里只分析 pid 大于0的情况,从上面的代码可以知道,当 pid 大于0时,会调用 kill_proc_info() 函数来处理信号发送操作,其代码如下:
inline int
kill_proc_info(int sig, struct siginfo *info, pid_t pid)
{
int error;
struct task_struct *p;
read_lock(&tasklist_lock);
p = find_task_by_pid(pid);
error = -ESRCH;
if (p)
error = send_sig_info(sig, info, p);
read_unlock(&tasklist_lock);
return error;
}
kill_proc_info() 首先通过调用 find_task_by_pid() 函数来获得 pid 对应的进程管理结构,然后通过 send_sig_info() 函数来发送信号给此进程,send_sig_info() 函数代码如下:
int
send_sig_info(int sig, struct siginfo *info, struct task_struct *t)
{
unsigned long flags;
int ret;
ret = -EINVAL;
if (sig < 0 || sig > _NSIG)
goto out_nolock;
ret = -EPERM;
if (bad_signal(sig, info, t))
goto out_nolock;
ret = 0;
if (!sig || !t->sig)
goto out_nolock;
spin_lock_irqsave(&t->sigmask_lock, flags);
handle_stop_signal(sig, t);
if (ignored_signal(sig, t))
goto out;
if (sig < SIGRTMIN && sigismember(&t->pending.signal, sig))
goto out;
ret = deliver_signal(sig, info, t);
out:
spin_unlock_irqrestore(&t->sigmask_lock, flags);
if ((t->state & TASK_INTERRUPTIBLE) && signal_pending(t))
wake_up_process(t);
out_nolock:
return ret;
}
send_sig_info() 首先调用 bad_signal() 函数来检查是否有权发送信号给进程,然后调用 ignored_signal() 函数来检查信号是否被忽略,接着调用 deliver_signal() 函数开始发送信号,最后如果进程是睡眠状态就唤醒进程。我们接着来分析 deliver_signal() 函数:
static int deliver_signal(int sig, struct siginfo *info, struct task_struct *t)
{
int retval = send_signal(sig, info, &t->pending);
if (!retval && !sigismember(&t->blocked, sig))
signal_wake_up(t);
return retval;
}
deliver_signal() 首先调用 send_signal() 函数进行信号的发送,然后调用 signal_wake_up() 函数唤醒进程。我们来分析一下最重要的函数 send_signal():
static int send_signal(int sig, struct siginfo *info, struct sigpending *signals)
{
struct sigqueue * q = NULL;
if (atomic_read(&nr_queued_signals) < max_queued_signals) {
q = kmem_cache_alloc(sigqueue_cachep, GFP_ATOMIC);
}
if (q) {
atomic_inc(&nr_queued_signals);
q->next = NULL;
*signals->tail = q;
signals->tail = &q->next;
switch ((unsigned long) info) {
case 0:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_USER;
q->info.si_pid = current->pid;
q->info.si_uid = current->uid;
break;
case 1:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_KERNEL;
q->info.si_pid = 0;
q->info.si_uid = 0;
break;
default:
copy_siginfo(&q->info, info);
break;
}
} else if (sig >= SIGRTMIN && info && (unsigned long)info != 1
&& info->si_code != SI_USER) {
return -EAGAIN;
}
sigaddset(&signals->signal, sig);
return 0;
}
send_signal() 函数虽然比较长,但逻辑还是比较简单的。在 信号处理相关的数据结构 一节我们介绍过进程管理结构 task_struct 有个 pending 的成员变量,其用于保存接收到的信号队列。send_signal() 函数的第三个参数就是进程管理结构的 pending 成员变量。
send_signal() 首先调用 kmem_cache_alloc() 函数来申请一个类型为 struct sigqueue 的队列节点,然后把节点添加到 pending 队列中,接着根据参数 info 的值来进行不同的操作,最后通过 sigaddset() 函数来设置信号对应的标志位,表示进程接收到该信号。
signal_wake_up() 函数会把进程的 sigpending 成员变量设置为1,表示有信号需要处理,如果进程是睡眠可中断状态还会唤醒进程。
至此,发送信号的流程已经完成,我们可以通过下面的调用链来更加直观的理解此过程:
kill()
| User Space
=========================================================
| Kernel Space
sys_kill()
└→ kill_something_info()
└→ kill_proc_info()
└→ find_task_by_pid()
└→ send_sig_info()
└→ bad_signal()
└→ handle_stop_signal()
└→ ignored_signal()
└→ deliver_signal()
└→ send_signal()
| └→ kmem_cache_alloc()
| └→ sigaddset()
└→ signal_wake_up()
内核触发信号处理函数
上面介绍了怎么发生一个信号给指定的进程,但是什么时候会触发信号相应的处理函数呢?为了尽快让信号得到处理,Linux把信号处理过程放置在进程从内核态返回到用户态前,也就是在 ret_from_sys_call 处:
// arch/i386/kernel/entry.S
ENTRY(ret_from_sys_call)
...
ret_with_reschedule:
...
cmpl $0, sigpending(%ebx) // 检查进程的sigpending成员是否等于1
jne signal_return // 如果是就跳转到 signal_return 处执行
restore_all:
RESTORE_ALL
ALIGN
signal_return:
sti // 开启硬件中断
testl $(VM_MASK),EFLAGS(%esp)
movl %esp,%eax
jne v86_signal_return
xorl %edx,%edx
call SYMBOL_NAME(do_signal) // 调用do_signal()函数进行处理
jmp restore_all
由于这是一段汇编代码,有点不太直观(大概知道意思就可以了),所以我在代码中进行了注释。主要的逻辑就是首先检查进程的 sigpending 成员是否等于1,如果是调用 do_signal() 函数进行处理,由于 do_signal() 函数代码比较长,所以我们分段来说明,如下:
int do_signal(struct pt_regs *regs, sigset_t *oldset)
{
siginfo_t info;
struct k_sigaction *ka;
if ((regs->xcs & 3) != 3)
return 1;
if (!oldset)
oldset = ¤t->blocked;
for (;;) {
unsigned long signr;
spin_lock_irq(¤t->sigmask_lock);
signr = dequeue_signal(¤t->blocked, &info);
spin_unlock_irq(¤t->sigmask_lock);
if (!signr)
break;
上面这段代码的主要逻辑是通过 dequeue_signal() 函数获取到进程接收队列中的一个信号,如果没有信号,那么就跳出循环。我们接着来分析:
ka = ¤t->sig->action[signr-1];
if (ka->sa.sa_handler == SIG_IGN) {
if (signr != SIGCHLD)
continue;
/* Check for SIGCHLD: it's special. */
while (sys_wait4(-1, NULL, WNOHANG, NULL) > 0)
/* nothing */;
continue;
}
上面这段代码首先获取到信号对应的处理方法,如果对此信号的处理是忽略的话,那么就直接跳过。
if (ka->sa.sa_handler == SIG_DFL) {
int exit_code = signr;
/* Init gets no signals it doesn't want. */
if (current->pid == 1)
continue;
switch (signr) {
case SIGCONT: case SIGCHLD: case SIGWINCH:
continue;
case SIGTSTP: case SIGTTIN: case SIGTTOU:
if (is_orphaned_pgrp(current->pgrp))
continue;
/* FALLTHRU */
case SIGSTOP:
current->state = TASK_STOPPED;
current->exit_code = signr;
if (!(current->p_pptr->sig->action[SIGCHLD-1].sa.sa_flags & SA_NOCLDSTOP))
notify_parent(current, SIGCHLD);
schedule();
continue;
case SIGQUIT: case SIGILL: case SIGTRAP:
case SIGABRT: case SIGFPE: case SIGSEGV:
case SIGBUS: case SIGSYS: case SIGXCPU: case SIGXFSZ:
if (do_coredump(signr, regs))
exit_code |= 0x80;
/* FALLTHRU */
default:
sigaddset(¤t->pending.signal, signr);
recalc_sigpending(current);
current->flags |= PF_SIGNALED;
do_exit(exit_code);
/* NOTREACHED */
}
}
...
handle_signal(signr, ka, &info, oldset, regs);
return 1;
}
...
return 0;
}
上面的代码表示,如果指定为默认的处理方法,那么就使用系统的默认处理方法去处理信号,比如 SIGSEGV 信号的默认处理方法就是使用 do_coredump() 函数来生成一个 core dump 文件,并且通过调用 do_exit() 函数退出进程。
如果指定了自定义的处理方法,那么就通过 handle_signal() 函数去进行处理,handle_signal() 函数代码如下:
static void
handle_signal(unsigned long sig, struct k_sigaction *ka,
siginfo_t *info, sigset_t *oldset, struct pt_regs * regs)
{
...
if (ka->sa.sa_flags & SA_SIGINFO)
setup_rt_frame(sig, ka, info, oldset, regs);
else
setup_frame(sig, ka, oldset, regs);
if (ka->sa.sa_flags & SA_ONESHOT)
ka->sa.sa_handler = SIG_DFL;
if (!(ka->sa.sa_flags & SA_NODEFER)) {
spin_lock_irq(¤t->sigmask_lock);
sigorsets(¤t->blocked,¤t->blocked,&ka->sa.sa_mask);
sigaddset(¤t->blocked,sig);
recalc_sigpending(current);
spin_unlock_irq(¤t->sigmask_lock);
}
}
由于信号处理程序是由用户提供的,所以信号处理程序的代码是在用户态的。而从系统调用返回到用户态前还是属于内核态,CPU是禁止内核态执行用户态代码的,那么怎么办?
答案先返回到用户态执行信号处理程序,执行完信号处理程序后再返回到内核态,再在内核态完成收尾工作。听起来有点绕,事实也的确是这样。下面通过一副图片来直观的展示这个过程(图片来源网络):
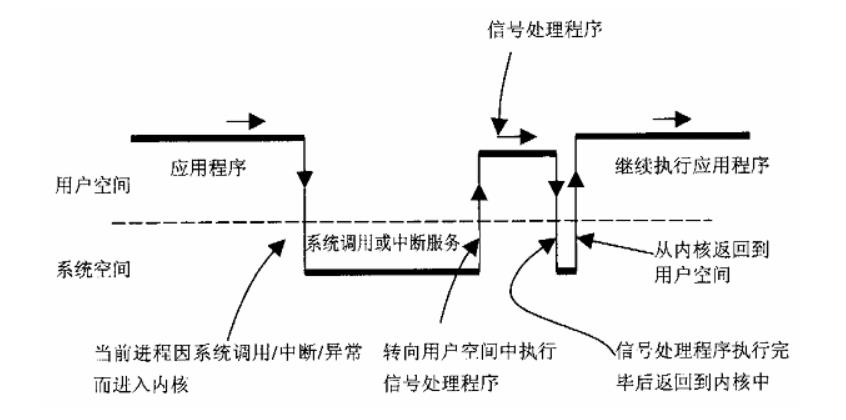
为了达到这个目的,Linux经历了一个十分崎岖的过程。我们知道,从内核态返回到用户态时,CPU要从内核栈中找到返回到用户态的地址(就是调用系统调用的下一条代码指令地址),Linux为了先让信号处理程序执行,所以就需要把这个返回地址修改为信号处理程序的入口,这样当从系统调用返回到用户态时,就可以执行信号处理程序了。
所以,handle_signal() 调用了 setup_frame() 函数来构建这个过程的运行环境(其实就是修改内核栈和用户栈相应的数据来完成)。我们先来看看内核栈的内存布局图:
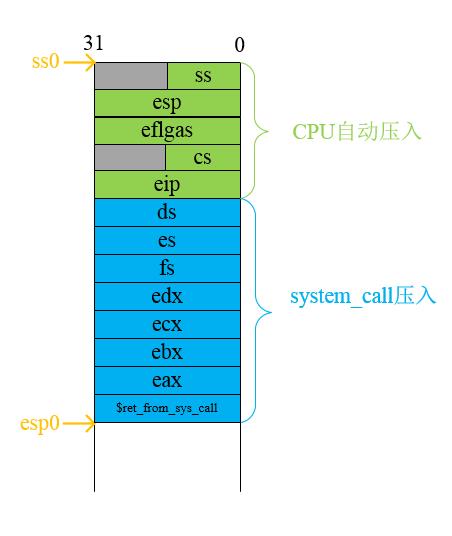
图中的 eip 就是内核态返回到用户态后开始执行的第一条指令地址,所以把 eip 改成信号处理程序的地址就可以在内核态返回到用户态的时候自动执行信号处理程序了。我们看看 setup_frame() 函数其中有一行代码就是修改 eip 的值,如下:
static void setup_frame(int sig, struct k_sigaction *ka,
sigset_t *set, struct pt_regs * regs)
{
...
regs->eip = (unsigned long) ka->sa.sa_handler; // regs是内核栈中保存的寄存器集合
...
}
现在可以在内核态返回到用户态时自动执行信号处理程序了,但是当信号处理程序执行完怎么返回到内核态呢?Linux的做法就是在用户态栈空间构建一个 Frame(帧)(我也不知道为什么要这样叫),构建这个帧的目的就是为了执行完信号处理程序后返回到内核态,并恢复原来内核
以上是关于2021年8月上中旬好文收藏的主要内容,如果未能解决你的问题,请参考以下文章