大数据Spark DStream
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Spark DStream相关的知识,希望对你有一定的参考价值。
1 DStream 是什么
SparkStreaming模块将流式数据封装的数据结构:DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种Spark算子操作后的结果数据流。离散数据流(DStream)是Spark Streaming最基本的抽象。它代表了一种连续的数据流,要么从某种数据源提取数据,要么从其他数据流映射转换而来。DStream内部是由一系列连续的RDD组成的,每个RDD都包含了特定时间隔内的一批数据,如下图所示:

DStream本质上是一个:一系列时间上连续的RDD(Seq[RDD]),DStream = Seq[RDD]。
DStream = Seq[RDD]
DStream相当于一个序列(集合),里面存储的数据类型为RDD(Streaming按照时间间隔划分流式数据)
对DStream的数据进行操作也是按照RDD为单位进行的。
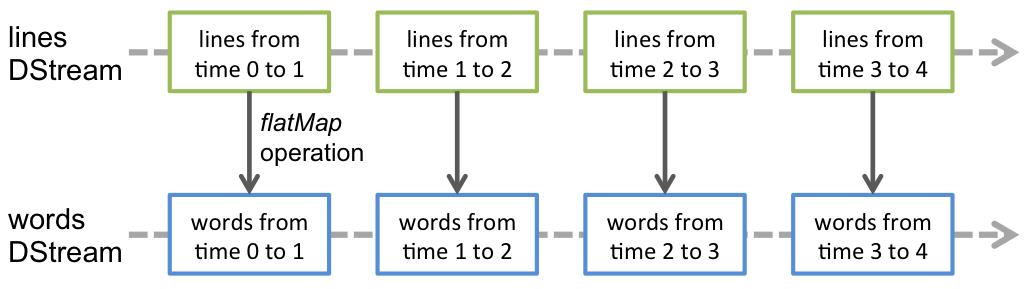
通过WEB UI界面可知,对DStream调用函数操作,底层就是对RDD进行操作,发现狠多时候DStream中函数与RDD中函数一样的。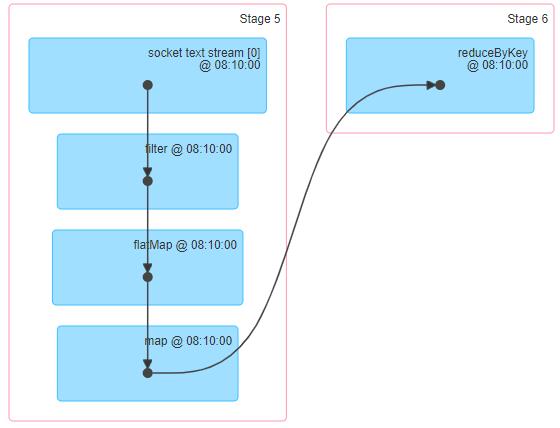
DStream中每批次数据RDD在处理时,各个RDD之间存在依赖关系,DStream直接也有依赖关系,RDD具有容错性,那么DStream也具有容错性。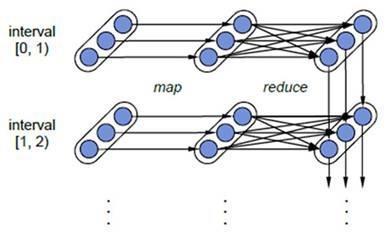
上图相关说明:
- 1)、每一个椭圆形表示一个RDD
- 2)、椭圆形中的每个圆形代表一个RDD中的一个Partition分区
- 3)、每一列的多个RDD表示一个DStream(图中有三列所以有三个DStream)
- 4)、每一行最后一个RDD则表示每一个Batch Size所产生的中间结果RDD
Spark Streaming将流式计算分解成多个Spark Job,对于每一时间段数据的处理都会经过Spark
DAG图分解以及Spark的任务集的调度过程。
2 DStream Operations
DStream类似RDD,里面包含很多函数,进行数据处理和输出操作,主要分为两大类:
- DStream#Transformations:将一个DStream转换为另一个DStream
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#transformations-on-dstreams - DStream#Output Operations:将DStream中每批次RDD处理结果resultRDD输出
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#output-operations-on-dstreams
2.1 函数概述
DStream中包含很多函数,大多数与RDD中函数类似,主要分为两种类型:
- 其一:转换函数【Transformation函数】
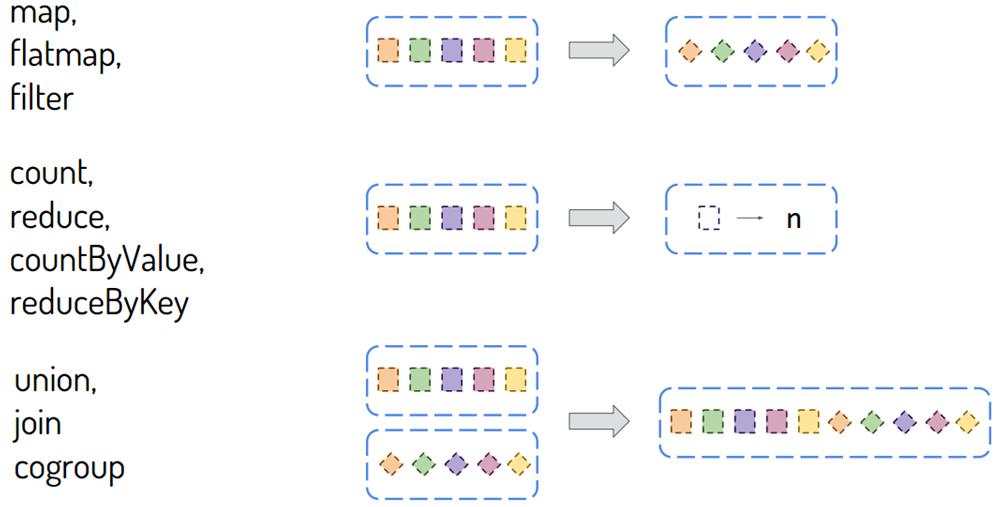
DStream中还有一些特殊函数,针对特定类型应用使用的函数,比如updateStateByKey状态函数、window窗口函数等,后续具体结合案例讲解。 - 其二:输出函数【Output函数】
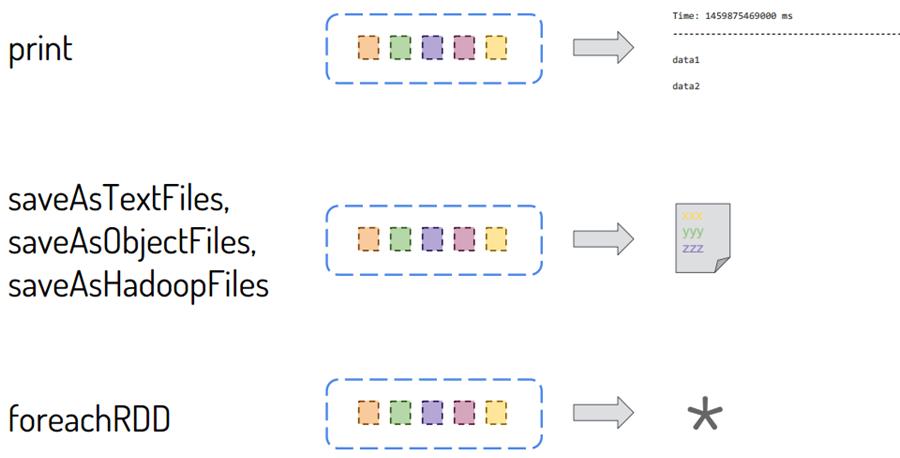
DStream中每批次结果RDD输出使用foreachRDD函数,前面使用的print函数底层也是调用
foreachRDD函数,截图如下所示: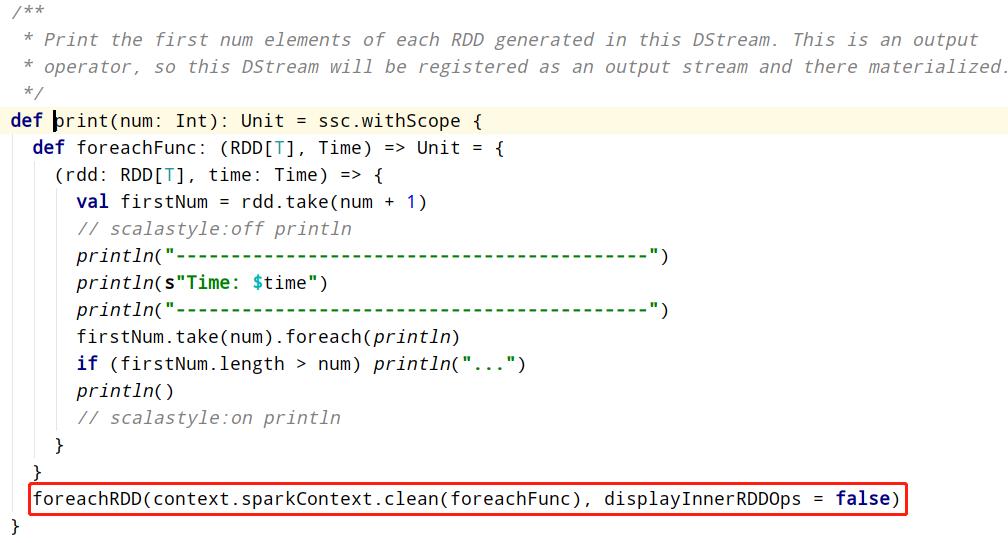
在DStream中有两个重要的函数,都是针对每批次数据RDD进行操作的,更加接近底层,性能更好,强烈推荐使用: - 转换函数transform:将一个DStream转换为另外一个DStream;
- 输出函数foreachRDD:将一个DStream输出到外部存储系统;
在SparkStreaming企业实际开发中,建议:能对RDD操作的就不要对DStream操作,当调用
DStream中某个函数在RDD中也存在,使用针对RDD操作。
2.2 转换函数:transform
通过源码认识transform函数,有两个方法重载,声明如下:
接下来使用transform函数,修改词频统计程序,具体代码如下:
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 基于IDEA集成开发环境,编程实现从TCP Socket实时读取流式数据,对每批次中数据进行词频统计。
*/
object StreamingTransformRDD {
def main(args: Array[String]): Unit = {
// 1. 构建StreamingContext流式上下文实例对象
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// b.创建流式上下文对象, 传递SparkConf对象,TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回
context
}
// 2. 从数据源端读取数据,此处是TCP Socket读取数据
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream(
"node1.itcast.cn", //
9999, //
// TODO: 设置Block存储级别为先内存,不足磁盘,副本为1
storageLevel = StorageLevel.MEMORY_AND_DISK
)
// TODO: 3. 对每批次的数据进行词频统计
/*
transform表示对DStream中每批次数据RDD进行操作
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// TODO: 在DStream中,能对RDD操作的不要对DStream操作。
val resultDStream: DStream[(String, Int)] = inputDStream.transform(rdd => {
val resultRDD: RDD[(String, Int)] = rdd
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
resultRDD
})
// 4. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.print(10)
// 5. 对于流式应用来说,需要启动应用
ssc.start()
// 流式应用启动以后,正常情况一直运行(接收数据、处理数据和输出数据),除非人为终止程序或者程序异常停止
ssc.awaitTermination()
// 关闭流式应用(参数一:是否关闭SparkContext,参数二:是否优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
查看WEB UI监控中每批次Batch数据执行Job的DAG图,直接显示针对RDD进行操作。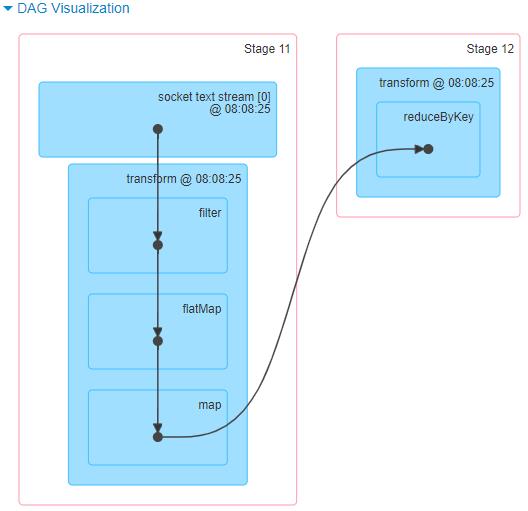
2.3 输出函数:foreachRDD
foreachRDD函数属于将DStream中结果数据RDD输出的操作,类似transform函数,针对每批
次RDD数据操作,源码声明如下:

继续修改词频统计代码,自定义输出数据,具体代码如下:
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
/**
* 基于IDEA集成开发环境,编程实现从TCP Socket实时读取流式数据,对每批次中数据进行词频统计。
*/
object StreamingOutputRDD {
def main(args: Array[String]): Unit = {
// 1. 构建StreamingContext流式上下文实例对象
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// TODO:设置数据输出文件系统的算法版本为2
.set("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2")
// b.创建流式上下文对象, 传递SparkConf对象,TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回
context
}
// 2. 从数据源端读取数据,此处是TCP Socket读取数据
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream(
"node1.itcast.cn", //
9999, //
// TODO: 设置Block存储级别为先内存,不足磁盘,副本为1
storageLevel = StorageLevel.MEMORY_AND_DISK
)
// 3. 对每批次的数据进行词频统计
/*
transform表示对DStream中每批次数据RDD进行操作
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// TODO: 在DStream中,能对RDD操作的不要对DStream操作。
val resultDStream: DStream[(String, Int)] = inputDStream.transform(rdd => {
val resultRDD: RDD[(String, Int)] = rdd
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
resultRDD
})
// TODO: 4. 将结果数据输出 -> 将每批次的数据处理以后输出
/*
对DStream中每批次结果RDD数据进行输出操作
def foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit
其中Time就是每批次BatchTime,Long类型数据, 转换格式:2020/05/10 16:53:25
*/
resultDStream.foreachRDD{ (rdd, time) =>
// 使用lang3包下FastDateFormat日期格式类,属于线程安全的
val batchTime: String = FastDateFormat.getInstance("yyyyMMddHHmmss")
.format(new Date(time.milliseconds))
println("-------------------------------------------")
println(s"Time: $batchTime")
println("-------------------------------------------")
// TODO: 先判断RDD是否有数据,有数据在输出
if(!rdd.isEmpty()){
// 对于结果RDD输出,需要考虑降低分区数目
val resultRDD = rdd.coalesce(1)
/ 对分区数据操作
resultRDD.foreachPartition{iter =>iter.foreach(item => println(item))}
// 保存数据至HDFS文件
resultRDD.saveAsTextFile(s"datas/streaming/wc-output-${batchTime}")
}
}
// 5. 对于流式应用来说,需要启动应用
ssc.start()
// 流式应用启动以后,正常情况一直运行(接收数据、处理数据和输出数据),除非人为终止程序或者程序异常停止
ssc.awaitTermination()
// 关闭流式应用(参数一:是否关闭SparkContext,参数二:是否优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
将SparkStreaming处理结果RDD数据保存到mysql数据库或者HBase表中,代码该如何编写呢?
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#design-patterns-for-using-foreachrdd
伪代码如下所示:
// 数据输出,将分析处理结果数据输出到MySQL表
resultDStream.foreachRDD{(rdd, time) =>
// 将BatchTime转换:2019/10/10 14:59:35
val batchTime = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss").format(time.milliseconds)
println("-------------------------------------------")
println(s"Time: $batchTime")
println("-------------------------------------------")
// TODO:首先判断每批次结果RDD是否有值,有值才输出, 必须判断,提升性能
if(!rdd.isEmpty()){
rdd.foreachPartition{iter =>
// 第一步、获取连接:从数据库连接池中获取连接
val conn: Connection = null
// 第二步、保存分区数据到MySQL表
iter.foreach{item =>
// TODO: 使用conn将数据保存到MySQL表中
}
// 第三步、关闭连接:将连接放入到连接池中
if(null != conn) conn.close()
}
}
}
将每批次数据统计结果RDD保存到HDFS文件中,代码如下:
resultDStream.foreachRDD{(rdd, time) =>
// 将BatchTime转换:2019/10/10 14:59:35
val batchTime = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss").format(time.milliseconds)
println("-------------------------------------------")
println(s"Time: $batchTime")
println("-------------------------------------------")
// TODO:首先判断每批次结果RDD是否有值,有值才输出, 必须判断,提升性能
if(!rdd.isEmpty()){
// 注意:将Streaming结果数据RDD保存文件中时,最好考虑降低分区数目
rdd.coalesce(1).saveAsTextFile(s"datas/spark/streaming/wc-${time.milliseconds}")
}
}
3 流式应用状态
使用SparkStreaming处理实际实时应用业务时,针对不同业务需求,需要使用不同的函数。SparkStreaming流式计算框架,针对具体业务主要分为三类,使用不同函数进行处理:
- 业务一:无状态Stateless
- 使用transform和foreacRDD函数
- 比如实时增量数据ETL:实时从Kafka Topic中获取数据,经过初步转换操作,存储到
Elasticsearch索引或HBase表中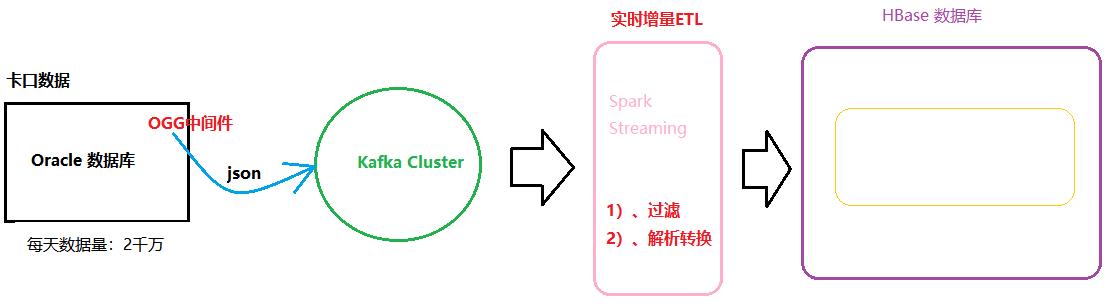
- 业务二:有状态State
- 双十一大屏幕所有实时累加统计数字(比如销售额和销售量等),比如销售额、网站PV、UV等等;
- 函数:updateStateByKey、mapWithState
- 业务三:窗口统计
- 每隔多久时间统计最近一段时间内数据,比如饿了么后台报表,每隔5分钟统计最近20分钟订单数。
- 苏宁搜索推荐时:
- 数据分析:统计搜索行为时间跨度,86%的搜索行为在5分钟内完成、90%的在10分钟内完成(从搜索开始到最后一次点击结果列表时间间隔);
- NDCG实时计算时间范围设定在15分钟,时间窗口为 15 分钟,步进 5 分钟,意味着每 5 分钟计算一次。每次计算,只对在区间[15 分钟前, 10 分钟前]发起的搜索行为进行 NDCG 计算,这样就不会造成重复计算。
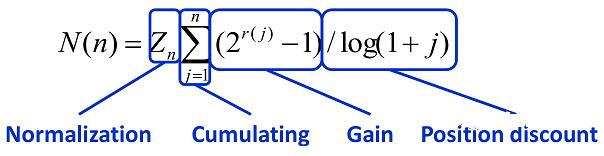
Normalized Discounted Cumulative Gain,即 NDCG,常用作搜索排序的评价指标,理想情况下排序越靠前的搜索结果,点击概率越大,即得分越高 (gain)。CG = 排序结果的得分求和, discounted 是根据排名,对每个结果得分 * 排名权重,权重 = 1/ log(1 + 排名) , 排名越靠前的权重越高。首先我们计算理想 DCG(称之为 IDCG),再根据用户点击结果, 计算真实的 DCG, NDCG = DCG / IDCG,值越接近 1, 则代表搜索结果越好。
以上是关于大数据Spark DStream的主要内容,如果未能解决你的问题,请参考以下文章