web前端技术分享:详解模块化require 和 import的区别
Posted 程序员的小傲娇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了web前端技术分享:详解模块化require 和 import的区别相关的知识,希望对你有一定的参考价值。
在前端开发中,我们可以使用很多模块化的库来帮助我们更好的实现效果,有一些库的功能类似很多同学就不知道该如何选择,比如require和import,今天小千就给大家介绍一下两者的区别。
一、区别
1.require是commonjs的规范,在node中实现的api,import是es的语法,由编译器处理。所以import可以做模块依赖的静态分析,配合webpack、rollup等可以做treeshaking。
2.commonjs导出的值会复制一份,require引入的是复制之后的值(引用类型只复制引用),es module导出的值是同一份(不包括export default),不管是基础类型还是应用类型。
3.写法上有差别,import可以使用import * 引入全部的export,也可以使用import aaa, { bbb}的方式分别引入default和非default的export,相比require更灵活。
二、require和import会不会循环引用?
答案是不会,因为模块执行后会把导出的值缓存,下次再require或者import不会再次执行。这样也就不会循环引用了。比如a引入了b,b引入了a,如果a再次执行那么会再引入b,那就循环起来了,但实际上会做缓存,再次引入不会再执行。可以通过require.cache来查看缓存的模块,key为require.resolve(path)的结果。
三、模块中有定时器改变了导出的值,导出的值会不会变?
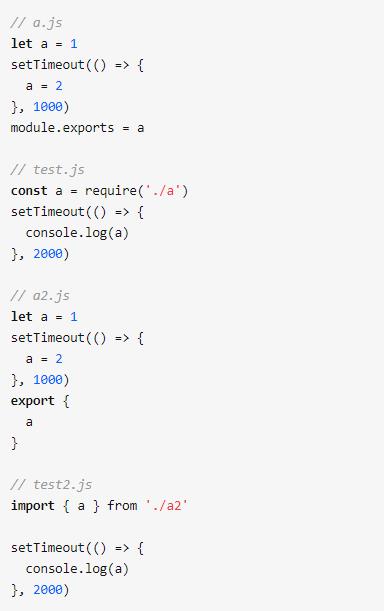
结果是import引入的值是2,而require引入的值一直是1,这也是require和imort很重要的一个区别,es module的export导出的值会静态的绑定,而commonjs exports导出的值是一个对象,会复制一份。这样也就出现了这样的现象。
四、总结
问 require和import的区别就是问commonjs和es module的区别,这两者一个是api的规范,一个是语言的语法,所以后者可以做静态分析,基于这个实现treeshaking,同时es module会静态的绑定导出的值,而commonjs会复制一份。但两者都会做缓存,所以不会有循环引用问题。
以上就是require和import的区别介绍了。最后欢迎对web前端感兴趣的小伙伴关注小千,后面会继续分享更多web前端知识。
本文来自千锋教育,转载请注明出处。
以上是关于web前端技术分享:详解模块化require 和 import的区别的主要内容,如果未能解决你的问题,请参考以下文章